,有趣實用的分散式架構頻道。
本次是 SOFAChannel 第二期,主要分享 SOFARPC 在效能上做的一些最佳化,這個系列會分成上下兩部分進行分享,今天是 SOFARPC 效能最佳化(上),也會對本次分享中的一些結論,提供部分程式碼 Demo,供大家瞭解驗證。
歡迎加入直播互動釘釘群:23127468,不錯過我們每場直播。
 大家好,今天是我們 SOFAChannel 第二期。歡迎大家觀看。
大家好,今天是我們 SOFAChannel 第二期。歡迎大家觀看。
我是來自螞蟻金服中介軟體的雷志遠,花名碧遠,目前在負責 SOFARPC 框架相關工作。
去年的時候,我們和外部的愛好者們一起,做了一個基於 SOFARPC 的原始碼解析系列,我同事已經發到群裡了,大家可以儲存,直播之後檢視。
SOFARPC 原始碼解析系列:(點選【剖析 | SOFARPC 框架】即可檢視)
https://www.sofastack.tech/posts
今年,基於原始碼解析的基礎,我們來多講講實踐,如何應用到大家的業務,來幫助大家解決實際問題。在直播過程中有相關的問題想提問,可以在釘釘群互動。
前言
在上一期中,餘淮分享了《從螞蟻金服微服務實踐談起》。介紹了螞蟻微服務的起源,以及之後服務化,單元化的情況。同時介紹了 SOFAStack 目前開源的情況。最後也分享了一下整個微服務中 SOFARPC 的設計與實現。
本期,我們主要分享 SOFARPC 在效能上做的一些最佳化。這個系列會分成上下兩部分進行分享,今天是 SOFARPC 效能最佳化(上),也會對本次分享中的一些結論,提供部分程式碼 Demo,供大家瞭解驗證。
我們先簡要介紹一下 SOFARPC 的框架分層。這個在上次的分享中已經進行了介紹。

下層是網路傳輸層,依次是協議,序列化,服務發現和 Filter 等。
Transport 主要負責資料傳輸,可以是 Http2Transport,也可以是 BoltTransport,還有可能是其他。
Protocol 層是協議,是 Rest 還是 Bolt ,或是 Dubbo 。
Serialization 是序列化,對於每種協議,可以是用不同的序列化方式,比如 hessian,pb,json 等。
Filter 是通用的過濾器層,主要是為了留出一些擴充套件,完成一些其他擴充套件功能,比如 Tracer 的埋點等。
Router 是路由層,主要是做定址,這裡可能是 Zk,也可能是 LVS,也可能是直連。
Cluster 是客戶端叢集方式的表示。
自定義通訊協議使用
首先我想介紹一下自定義通訊協議。
在說明自定義通訊協議之前,我先簡單介紹一下通訊協議。在TCP之上,RPC框架通常還需要將請求和響應資料進行一定的封裝,組裝成 Packet,然後發送出去。這樣,服務端收到之後,才能正確識別整個 TCP 發過來的位元組流中,哪一部分是我們可以進行處理的一個完整單位。反之,客戶端收到服務端的TCP 資料流也是如此。
有了上面的共識之後,我們要回答下麵兩個問題:
-
為什麼要自定義,不使用
Http2/Dubbo/Rest/Grpc?
-
自定義之後,帶來了什麼好處呢?
Http2 雖然更為通用,但是一方面,出現較晚,遷移轉換成本高,並且通用則意味著傳輸的輔助資料會變多,會有一些額外的資訊需要傳遞或者判斷。對於序列化反序列化的控制上,也不是很好擴充套件操作。
而 Dubbo,協議簡單強大。但是一些元資訊需要解析,Header 中傳輸的資料太少,很多都需要依賴 body 中的資料反序列化完成後才能使用,頭部的資訊太少。

而使用了自研的協議之後,Header 中可自定義傳輸更多的元資訊,序列化方式,Server Fail Fast,服務端執行緒隔離等也都成為可能。甚至螞蟻在 ServiceMesh 的場景下,Mesh 本身也能利用 Bolt 的協議,進行部分資料的讀取,而不依賴具體的序列化實現。

BOLT 協議圖
經過我們的實踐,大致來看,目前給我們帶來的好處主要有以下的能力:
-
Server Fast 的支援
-
Header 和 Body 的分開序列化
-
Crc 校驗的支援
-
版本的支援,預防未來可能出現更好的設計方案
-
多種序列化方式的支援
-
安全認證,Mesh 路由
如果你要自己設計一個通訊協議。可以考慮使用 BOLT 協議,或者參考進行更好的設計和最佳化。
關於 SOFABolt 相關的原始碼解析,也可以透過這個系列來瞭解。
SOFABolt 原始碼解析系列:(點選【剖析 | SOFABOLT 框架】即可檢視)
https://www.sofastack.tech/posts
Netty 效能引數最佳化
在介紹了自定義通訊協議之後,也就是確定好了怎麼封包解包之後,還需要確定傳輸層的開發。一個 RPC 框架從現在的情況來看,一般不太可能完全基於 JAVA 的 NIO 或者其他 IO 進行直接的開發,主要是一些 NIO 原生的問題和使用難度,而成熟的,目前可選的不多。基本上,大家都會基於 Netty 進行開發,HSF/Dubbo/Motan 等都是這樣。
直接使用是比較簡單的。在 Netty 的 Bootstrap 的設定中,有一些可選的最佳化項,有必要跟大家分享一下。
1、SO_REUSEPORT/SO_REUSEADDR – 埠復用(允許多個 socket 監聽同一個IP+埠)
SOREUSEPORT 支援多個行程或者執行緒系結到同一埠,提高伺服器的接收連結的併發能力,由核心層面實現對埠資料的分發的負載均衡,在伺服器 socket 上沒有了鎖的競爭。
同時 SOREUSEADDR也要開啟,這樣針對 time-wait 連結 ,可以確保 server 重啟成功。在一些服務端啟動很快的情況下,可以防止啟動失敗。
2、TCP_FASTOPEN – 3次握手時也用來交換資料
三次握手的過程中,當使用者首次訪問服務端時,傳送 syn 包,server 根據客戶端 IP 生成 cookie ,並與 syn+ack 一同發回客戶端;客戶端再次訪問服務端時,在 syn 包攜帶 TCP cookie;如果服務端校驗合法,則在使用者回覆 ack 前就可以直接傳送資料;否則按照正常三次握手進行。也就是說,如果客戶端中途斷開,再建聯的時候,會同時傳送資料,會有一定的效能提升。
TFO 提高效能的關鍵是省去了熱請求的三次握手,這在小物件傳輸較多的移動應用場景中,能夠極大提升效能。
Netty 中僅在 Epoll 的時候可用 Linux特性,不能在 Mac/Windows 上使用,SOFARPC 未開啟。
3、TCP_NODELAY-關閉 (納格) Nagle 演演算法,再小的包也傳送,而不是等待
TCP/IP 協議中針對 TCP 預設開啟了 Nagle 演演算法。Nagle 演演算法透過減少需要傳輸的資料包個數,來最佳化網路。但是現在的環境下,網路頻寬足夠,需要進行關閉。這樣,對於傳輸資料量小的場景,能很好的提高效能,不至於出現資料包等待。
4、SO_KEEPALIVE –開啟 TCP 層面的 Keep Alive 能力
這個不多說,開啟一下 TCP 層面的 Keep Alive 的能力。
5、WRITE_BUFFER_WATER_MARK 設定
透過 WRITEBUFFERWATERMARK 設定某個連線上可以暫存的最大最小 Buffer 之後,如果該連線的等待傳送的資料量大於設定的值時,則 isWritable 會傳回不可寫。這樣,客戶端可以不再傳送,防止這個量不斷的積壓,最終可能讓客戶端掛掉。如果發生這種情況,一般是服務端處理緩慢導致。這個值可以有效的保護客戶端。此時資料並沒有發送出去。
6、workerGroup
worker 執行緒數設定處理器+1,Netty 預設是執行緒數*2,可以根據自己的壓測情況來判斷。Boss Group 用於服務端處理建立連線的請求,WorkGroup 用於處理 I/O。為了避免執行緒背景關係切換,只要能滿足要求,這個值一般越少越好。
7、ioRadio 設定
EventLoop#ioRatio 的設定(預設50), 這是 EventLoop 執行 IO 任務和非 IO 任務的一個時間比例上的控制,BOLT 最佳實踐是70,表示70%的時間在執行 IO 任務。
8、SO_BACKLOG 設定
在 Linux 系統核心中維護了兩個佇列:syns queue 和 accept queue。第一個是半連線佇列,儲存收到客戶端 syn 之後,進入 synrecv 狀態的這些連線,預設 netty 中是128, io.netty.util.NetUtil#SOMAXCONN ,然後讀取 /proc/sys/net/core/somaxconn 來繼續確定,之後還有一些系統級別的改寫邏輯。
在一些場景下,如果客戶端遠遠多餘服務端,併發建聯,可能不夠。這個值也不能太大,否則會無法防止 SYN-Flood 攻擊。Bolt 中目前這個值修改成了1024。透過設定之後,由於自己設定的和系統的取小,所以自己設定的值相當於設定了上限。如果 Linux 系統運維某些設定錯誤,也能透過程式碼層面進行避免。
目前我們的 Linux 層面,通常設定的是 128,最終經過計算會設定為 128。
SOFARPC 連線保持
Netty 設定基本 ok,協議也確定之後,連線的保持就比較重要,否則,第一次傳送或者每次傳送都要走一次建聯的過程。雖然有 FAST OPEN 的加持,還是有一些損失。
說到這裡, 可能有些同學有疑問:
-
Keep Alive 不夠嗎?
-
Bolt 的連線管理怎麼做的?
-
如何解決初次建聯的問題?
-
心跳是單向還是雙向?
前面我們說過了,Keep Alive 已經開啟了。不過,Keep Alive 還不夠,主要是經過很多網路裝置之後,Keep Alive可能失效,另外 Keep Alive 是一個 Linux 層面的設定,有時候整個系統並未開啟。這些不可控的因素都會導致我們的連線管理失效。
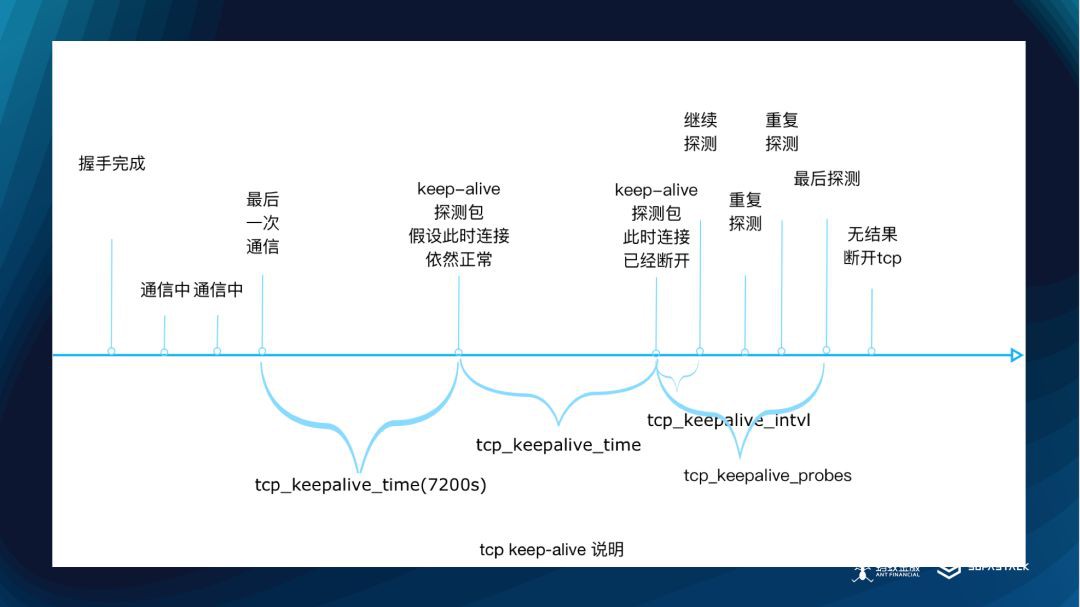
Keep Alive 圖
上面是 Keep Alive 的處理,主要是在沒有讀寫事件一段時間後,進行資料包的傳送來保活。
因為我們需要更通用的連線保持方案。連線管理核心的基於 Netty 的 Idle 事件來做。BOLT 的設定為單向心跳,客戶端發,服務端收,減少心跳資料在網路上的傳輸量。有些 RPC 框架會使用雙向心跳,同時,BOLT 在連線管理上,也允許一個地址,建立多個連線,這樣可以在傳送時,最大限度的利用網絡卡。預設為1,連線數在滿足傳輸吞吐量的情況下越少越好。
但是這裡要註意,如果你的場景是有大量的服務端,那麼這個資料不建議進行擴大。因為 tcp 連線會成倍增長,反而帶來效能下降。目前螞蟻這邊大部分也多為1。

RPC 連線管理
在 BOLT 連線管理的基礎上,RPC 為了避免第一次使用者請求,進行建聯併傳送的延遲,RPC 還有一個連線管理的執行緒,會非同步的進行連線初始化。這樣,當真正的請求發起的時候,連線已經準備好了,可以減少一次建聯的耗時對業務的影響。
對於 LVS 和 VIP 的場景下,由於長連線的特性,即使後端有 100個 IP,對客戶端來說,也只能和一個 IP 進行通訊,因為這些裝置是建聯層面的,並非通訊層面的。所以對這種情況,一個 RPC 框架也要考慮支援定時斷鏈和重連。
序列化選擇
以上都準備好了之後,序列化方式的選擇決定了業務傳輸物件能夠有多小,也決定了在傳輸之前,序列化和反序列化的時候能有多快或者有多佔用 CPU 。

序列化圖
螞蟻這邊長期使用 hessian 作為序列化方式,在出現跨語言需求後,同時支援 pb 。如果你還有考慮其他的序列化方式,可以參考附錄中的序列化框架效能測試套件來進行選擇。
需要註意的是,在 RPC 場景的序列化中,一定要考慮介面變更,欄位新增的相容性。因為一旦一個介面被客戶 A 和 B 取用,此時 C 要升級 facade 介面,能否相容 A 和 B 的情況就很重要。
基於我們自己的情況,在序列化方式的選擇上:
-
如果很長時間內,不存在跨語言的情況,hessian 是相容性和效能的綜合考慮
-
如果考慮跨語言,並且對效能要求很高,Pb 可作為跨語言的情況下的選擇。
-
在選型時也要考慮序列化框架的社群情況。切勿選擇看上去效能高,但是已經不再維護的庫,或者使用者量非常少的庫,一旦出現問題,比較難解決。
IO 執行緒池批次解包

批次解包圖
Netty 提供了一個方便的解碼工具類 ByteToMessageDecoder ,如圖上半部分所示,這個類具備 accumulate 批次解包能力,可以盡可能的從 socket 裡讀取位元組,然後同步呼叫 decode 方法,解碼出業務物件,並組成一個 List 。最後再迴圈遍歷該 List ,依次提交到 ChannelPipeline 進行處理。改動後,如圖下半部分所示,即將提交的內容從單個 command ,改為整個 List 一起提交,如此能減少 pipeline 的執行次數,同時提升吞吐量。這個樣式在低併發場景下不明顯,但是在高併發場景下對吞吐量有不小的效能提升。
這一段是我改成開關方式的,方便大家理解改動點。
-
if (batchSwitch) {
-
ArrayList<Object> ret = new ArrayList<Object>(size);
-
for (int i = 0; i < size; i++) {
-
ret.add(out.get(i)); }
-
ctx.fireChannelRead(ret); }else{
-
for (int i = 0; i < size; i++) {
-
ctx.fireChannelRead(out.get(i)); } }
我們的 DEMO 提供了一個驗證的方式,如果有相關的壓測環境,可以參考進行多併發的驗證。
DEMO 連結:
https://github.com/leizhiyuan/rpcchannel
客戶端 Proxy 的效能最佳化
作為一個 RPC 框架,最後,我們還有給使用者的介面生成代理。目前一般大家都是要用動態代理來做。動態代理的效能有不同,使用上也有一定的差別。各個版本之間,也會有一定的差異。在選擇上,需要大家根據實際情況,進行測試驗證。
我們自己的測試資料顯示 Javassist Bytecode 的方式是除了 Asm 之外,效能最好的。Asm 由於使用寫法非常反人類,所以我們目前還是使用的 Javassist Bytecode 的方式。
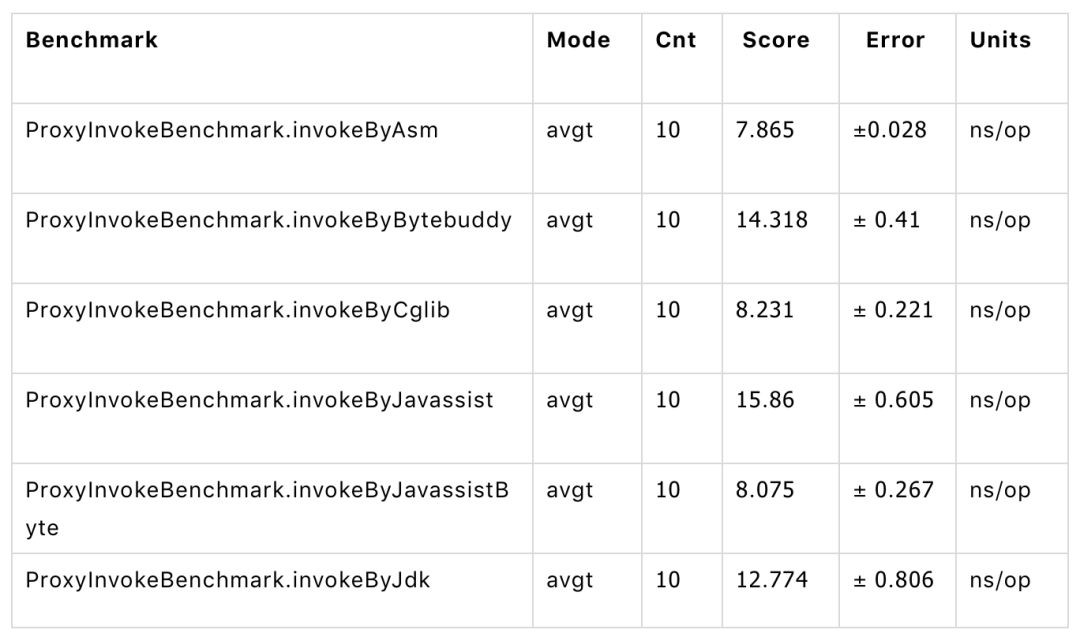
可優先選擇 javassist bytecode,有一定的效能優勢,效能測試可以根據自己的情況,使用 JMH 進行測試。測試程式碼和版本在 DEMO 中提供。
總結
得益於 Java 社群的發展以及前輩們的貢獻,目前寫一個 RPC 框架並不是很難。但是作為一個 RPC 框架,需要在可維護性的基礎上,盡可能提高自身效能,將在實際過程中遇到的一些場景和異常情況進行修複和最佳化,併進行更好的程式碼設計和實現。對於效能上的資料,可以多使用 JMH 並結合實際業務場景,進行相應的測試。
最後感謝大家,今天的 SOFA Channel 直播到此結束。下期我們將在本月28號與大家見面, SOFARPC 效能最佳化(下),我們會帶來關於執行緒池隔離,Server Fail Fast,記憶體操作最佳化,使用者可調節引數等方面的介紹。
大家可以點選閱讀原文或者連結進行報名。
https://tech.antfin.com/activities/245?chInfo=wx
相關連結
影片回放也給你準備好啦:
https://tech.antfin.com/activities/244
相關參考連結:
-
DEMO 連結:
https://github.com/leizhiyuan/rpcchannel
- SOFARPC:
https://github.com/alipay/sofa-rpc
-
SOFARPC 原始碼解析系列 (點選【剖析 | SOFARPC 框架】即可檢視)
https://www.sofastack.tech/posts
-
SOFABolt 原始碼解析系列 (點選【剖析 | SOFABOLT 框架】即可檢視)
https://www.sofastack.tech/posts
-
TCP man:
https://linux.die.net/man/7/tcp
-
FAST OPEN :
https://tools.ietf.org/html/rfc7413
-
netty :
https://netty.io/news/2015/09/30/4-0-32-Final.html
-
jvm-serializers:
https://github.com/eishay/jvm-serializers/wiki
-
半連線 :
https://www.cnxct.com/something-about-phpfpm-s-backlog/
-
SYN Flood :
https://zh.wikipedia.org/wiki/SYN_flood
講師觀點


長按關註,不錯過每一場技術直播
歡迎大家共同打造 SOFAStack https://github.com/alipay

