(給演演算法愛好者加星標,修煉程式設計內功)
轉自:知乎/杜博亞
本文的目的,是務實、簡潔地盤點一番當前機器學習演演算法。文中內容結合了個人在查閱資料過程中收集到的前人總結,同時添加了部分自身總結,在這裡,依據實際使用中的經驗,將對此類模型優缺點及選擇詳加討論
主要回顧下幾個常用演演算法的適應場景及其優缺點!
機器學習演演算法太多了,分類、回歸、聚類、推薦、影象識別領域等等,要想找到一個合適演演算法真的不容易,所以在實際應用中,我們一般都是採用啟髮式學習方式來實驗。通常最開始我們都會選擇大家普遍認同的演演算法,諸如SVM,GBDT,Adaboost,現在深度學習很火熱,神經網路也是一個不錯的選擇。
假如你在乎精度(accuracy)的話,最好的方法就是透過交叉驗證(cross-validation)對各個演演算法一個個地進行測試,進行比較,然後調整引數確保每個演演算法達到最優解,最後選擇最好的一個。但是如果你只是在尋找一個“足夠好”的演演算法來解決你的問題,或者這裡有些技巧可以參考,下麵來分析下各個演演算法的優缺點,基於演演算法的優缺點,更易於我們去選擇它。
1.天下沒有免費的午餐
在機器學習領域,一個基本的定理就是“沒有免費的午餐”。換言之,就是沒有演演算法能完美地解決所有問題,尤其是對監督學習而言(例如預測建模)。
舉例來說,你不能去說神經網路任何情況下都能比決策樹更有優勢,反之亦然。它們要受很多因素的影響,比如你的資料集的規模或結構。
其結果是,在用給定的測試集來評估效能並挑選演演算法時,你應當根據具體的問題來採用不同的演演算法。
當然,所選的演演算法必須要適用於你自己的問題,這就要求選擇正確的機器學習任務。作為類比,如果你需要打掃房子,你可能會用到吸塵器、掃帚或是拖把,但你絕對不該掏出鏟子來挖地。
2. 偏差&方差
在統計學中,一個模型好壞,是根據偏差和方差來衡量的,所以我們先來普及一下偏差(bias)和方差(variance):
1. 偏差:描述的是預測值(估計值)的期望E’與真實值Y之間的差距。偏差越大,越偏離真實資料。

2. 方差:描述的是預測值P的變化範圍,離散程度,是預測值的方差,也就是離其期望值E的距離。方差越大,資料的分佈越分散。
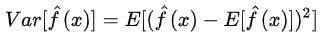
模型的真實誤差是兩者之和,如公式:

通常情況下,如果是小訓練集,高偏差/低方差的分類器(例如,樸素貝葉斯NB)要比低偏差/高方差大分類的優勢大(例如,KNN),因為後者會發生過擬合(overfiting)。然而,隨著你訓練集的增長,模型對於原資料的預測能力就越好,偏差就會降低,此時低偏差/高方差的分類器就會漸漸的表現其優勢(因為它們有較低的漸近誤差),而高偏差分類器這時已經不足以提供準確的模型了。
為什麼說樸素貝葉斯是高偏差低方差?
首先,假設你知道訓練集和測試集的關係。簡單來講是我們要在訓練集上學習一個模型,然後拿到測試集去用,效果好不好要根據測試集的錯誤率來衡量。但很多時候,我們只能假設測試集和訓練集的是符合同一個資料分佈的,但卻拿不到真正的測試資料。這時候怎麼在只看到訓練錯誤率的情況下,去衡量測試錯誤率呢?
由於訓練樣本很少(至少不足夠多),所以透過訓練集得到的模型,總不是真正正確的。(就算在訓練集上正確率100%,也不能說明它刻畫了真實的資料分佈,要知道刻畫真實的資料分佈才是我們的目的,而不是隻刻畫訓練集的有限的資料點)。
而且,實際中,訓練樣本往往還有一定的噪音誤差,所以如果太追求在訓練集上的完美而採用一個很複雜的模型,會使得模型把訓練集裡面的誤差都當成了真實的資料分佈特徵,從而得到錯誤的資料分佈估計。這樣的話,到了真正的測試集上就錯的一塌糊塗了(這種現象叫過擬合)。但是也不能用太簡單的模型,否則在資料分佈比較複雜的時候,模型就不足以刻畫資料分佈了(體現為連在訓練集上的錯誤率都很高,這種現象較欠擬合)。過擬合表明採用的模型比真實的資料分佈更複雜,而欠擬合表示採用的模型比真實的資料分佈要簡單。
在統計學習框架下,大家刻畫模型複雜度的時候,有這麼個觀點,認為Error = Bias + Variance。這裡的Error大概可以理解為模型的預測錯誤率,是有兩部分組成的,一部分是由於模型太簡單而帶來的估計不準確的部分(Bias),另一部分是由於模型太複雜而帶來的更大的變化空間和不確定性(Variance)。
所以,這樣就容易分析樸素貝葉斯了。它簡單的假設了各個資料之間是無關的,是一個被嚴重簡化了的模型。所以,對於這樣一個簡單模型,大部分場合都會Bias部分大於Variance部分,也就是說高偏差而低方差。
在實際中,為了讓Error儘量小,我們在選擇模型的時候需要平衡Bias和Variance所佔的比例,也就是平衡over-fitting和under-fitting。
當模型複雜度上升的時候,偏差會逐漸變小,而方差會逐漸變大。
3. 常見演演算法優缺點
3.1 樸素貝葉斯
樸素貝葉斯屬於生成式模型(關於生成模型和判別式模型,主要還是在於是否需要求聯合分佈),比較簡單,你只需做一堆計數即可。如果註有條件獨立性假設(一個比較嚴格的條件),樸素貝葉斯分類器的收斂速度將快於判別模型,比如邏輯回歸,所以你只需要較少的訓練資料即可。即使NB條件獨立假設不成立,NB分類器在實踐中仍然表現的很出色。它的主要缺點是它不能學習特徵間的相互作用,用mRMR中R來講,就是特徵冗餘。取用一個比較經典的例子,比如,雖然你喜歡Brad Pitt和Tom Cruise的電影,但是它不能學習出你不喜歡他們在一起演的電影。
優點:
1. 樸素貝葉斯模型發源於古典數學理論,有著堅實的數學基礎,以及穩定的分類效率;
2. 對大數量訓練和查詢時具有較高的速度。即使使用超大規模的訓練集,針對每個專案通常也只會有相對較少的特徵數,並且對專案的訓練和分類也僅僅是特徵機率的數學運算而已;
3. 對小規模的資料表現很好,能個處理多分類任務,適合增量式訓練(即可以實時的對新增的樣本進行訓練);
4. 對缺失資料不太敏感,演演算法也比較簡單,常用於文字分類;
5. 樸素貝葉斯對結果解釋容易理解。
缺點:
1. 需要計算先驗機率;
2. 分類決策存在錯誤率;
3. 對輸入資料的表達形式很敏感;
4. 由於使用了樣本屬性獨立性的假設,所以如果樣本屬性有關聯時其效果不好。
樸素貝葉斯應用領域
1. 欺詐檢測中使用較多;
2. 一封電子郵件是否是垃圾郵件;
3. 一篇文章應該分到科技、政治,還是體育類;
4. 一段文字表達的是積極的情緒還是消極的情緒;
5. 人臉識別。
3.2 Logistic Regression(邏輯回歸)
邏輯回歸屬於判別式模型,同時伴有很多模型正則化的方法(L0, L1,L2,etc),而且你不必像在用樸素貝葉斯那樣擔心你的特徵是否相關。與決策樹、SVM相比,你還會得到一個不錯的機率解釋,你甚至可以輕鬆地利用新資料來更新模型(使用線上梯度下降演演算法-online gradient descent)。如果你需要一個機率架構(比如,簡單地調節分類閾值,指明不確定性,或者是要獲得置信區間),或者你希望以後將更多的訓練資料快速整合到模型中去,那麼使用它吧。
Sigmoid函式:運算式如下:
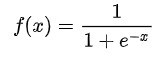
優點:
1. 實現簡單,廣泛的應用於工業問題上;
2. 分類時計算量非常小,速度很快,儲存資源低;
3. 便利的觀測樣本機率分數;
4. 對邏輯回歸而言,多重共線性並不是問題,它可以結合L2正則化來解決該問題;
5. 計算代價不高,易於理解和實現。
缺點:
1. 當特徵空間很大時,邏輯回歸的效能不是很好;
2. 容易欠擬合,一般準確度不太高;
3. 不能很好地處理大量多類特徵或變數;
4. 只能處理兩分類問題(在此基礎上衍生出來的softmax可以用於多分類),且必須線性可分;
5. 對於非線性特徵,需要進行轉換。
logistic回歸應用領域:
1. 用於二分類領域,可以得出機率值,適用於根據分類機率排名的領域,如搜尋排名等;
2. Logistic回歸的擴充套件softmax可以應用於多分類領域,如手寫字識別等;
3. 信用評估;
4. 測量市場營銷的成功度;
5. 預測某個產品的收益;
6. 特定的某天是否會發生地震。
3.3 線性回歸
線性回歸是用於回歸的,它不像Logistic回歸那樣用於分類,其基本思想是用梯度下降法對最小二乘法形式的誤差函式進行最佳化,當然也可以用normal equation直接求得引數的解,結果為:

而在LWLR(區域性加權線性回歸)中,引數的計算運算式為:
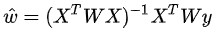
由此可見LWLR與LR不同,LWLR是一個非引數模型,因為每次進行回歸計算都要遍歷訓練樣本至少一次。
優點: 實現簡單,計算簡單。
缺點: 不能擬合非線性資料。
3.4 最近鄰演演算法——KNN
KNN即最近鄰演演算法,其主要過程為:
1. 計算訓練樣本和測試樣本中每個樣本點的距離(常見的距離度量有歐式距離,馬氏距離等);
2. 對上面所有的距離值進行排序(升序);
3. 選前k個最小距離的樣本;
4. 根據這k個樣本的標簽進行投票,得到最後的分類類別。
如何選擇一個最佳的K值,這取決於資料。一般情況下,在分類時較大的K值能夠減小噪聲的影響,但會使類別之間的界限變得模糊。一個較好的K值可透過各種啟髮式技術來獲取,比如,交叉驗證。另外噪聲和非相關性特徵向量的存在會使K近鄰演演算法的準確性減小。近鄰演演算法具有較強的一致性結果,隨著資料趨於無限,演演算法保證錯誤率不會超過貝葉斯演演算法錯誤率的兩倍。對於一些好的K值,K近鄰保證錯誤率不會超過貝葉斯理論誤差率。
KNN演演算法的優點
1. 理論成熟,思想簡單,既可以用來做分類也可以用來做回歸;
2. 可用於非線性分類;
3. 訓練時間複雜度為O(n);
4. 對資料沒有假設,準確度高,對outlier不敏感;
5. KNN是一種線上技術,新資料可以直接加入資料集而不必進行重新訓練;
6. KNN理論簡單,容易實現。
缺點
1. 樣本不平衡問題(即有些類別的樣本數量很多,而其它樣本的數量很少)效果差;
2. 需要大量記憶體;
3. 對於樣本容量大的資料集計算量比較大(體現在距離計算上);
4. 樣本不平衡時,預測偏差比較大。如:某一類的樣本比較少,而其它類樣本比較多;
5. KNN每一次分類都會重新進行一次全域性運算;
6. k值大小的選擇沒有理論選擇最優,往往是結合K-折交叉驗證得到最優k值選擇。
KNN演演算法應用領域
文字分類、樣式識別、聚類分析,多分類領域
3.5 決策樹
決策樹的一大優勢就是易於解釋。它可以毫無壓力地處理特徵間的互動關係並且是非引數化的,因此你不必擔心異常值或者資料是否線性可分(舉個例子,決策樹能輕鬆處理好類別A在某個特徵維度x的末端,類別B在中間,然後類別A又出現在特徵維度x前端的情況)。它的缺點之一就是不支援線上學習,於是在新樣本到來後,決策樹需要全部重建。另一個缺點就是容易出現過擬合,但這也就是諸如隨機森林RF(或提升樹boosted tree)之類的整合方法的切入點。另外,隨機森林經常是很多分類問題的贏家(通常比支援向量機好上那麼一丁點),它訓練快速並且可調,同時你無須擔心要像支援向量機那樣調一大堆引數,所以在以前都一直很受歡迎。
決策樹中很重要的一點就是選擇一個屬性進行分枝,因此要註意一下資訊增益的計算公式,並深入理解它。
資訊熵的計算公式如下:

其中的n代表有n個分類類別(比如假設是二類問題,那麼n=2)。分別計算這2類樣本在總樣本中出現的機率

和

,這樣就可以計算出未選中屬性分枝前的資訊熵。
現在選中一個屬性

用來進行分枝,此時分枝規則是:如果

的話,將樣本分到樹的一個分支;如果不相等則進入另一個分支。很顯然,分支中的樣本很有可能包括2個類別,分別計算這2個分支的熵

和
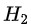
,計算出分枝後的總資訊熵

,則此時的資訊增益

。以資訊增益為原則,把所有的屬性都測試一邊,選擇一個使增益最大的屬性作為本次分枝屬性。
決策樹自身的優點
1. 決策樹易於理解和解釋,可以視覺化分析,容易提取出規則;
2. 可以同時處理標稱型和數值型資料;
3. 比較適合處理有缺失屬性的樣本;
4. 能夠處理不相關的特徵;
5. 測試資料集時,執行速度比較快;
6. 在相對短的時間內能夠對大型資料源做出可行且效果良好的結果。
缺點
1. 容易發生過擬合(隨機森林可以很大程度上減少過擬合);
2. 容易忽略資料集中屬性的相互關聯;
3. 對於那些各類別樣本數量不一致的資料,在決策樹中,進行屬性劃分時,不同的判定準則會帶來不同的屬性選擇傾向;資訊增益準則對可取數目較多的屬性有所偏好(典型代表ID3演演算法),而增益率準則(CART)則對可取數目較少的屬性有所偏好,但CART進行屬性劃分時候不再簡單地直接利用增益率盡心劃分,而是採用一種啟髮式規則)(只要是使用了資訊增益,都有這個缺點,如RF)。
4. ID3演演算法計算資訊增益時結果偏向數值比較多的特徵。
改進措施
1. 對決策樹進行剪枝。可以採用交叉驗證法和加入正則化的方法;
2. 使用基於決策樹的combination演演算法,如bagging演演算法,randomforest演演算法,可以解決過擬合的問題。
應用領域
企業管理實踐,企業投資決策,由於決策樹很好的分析能力,在決策過程應用較多。
3.5.1 ID3、C4.5演演算法
ID3演演算法是以資訊理論為基礎,以資訊熵和資訊增益度為衡量標準,從而實現對資料的歸納分類。ID3演演算法計算每個屬性的資訊增益,並選取具有最高增益的屬性作為給定的測試屬性。C4.5演演算法核心思想是ID3演演算法,是ID3演演算法的改進,改進方面有: – 用資訊增益率來選擇屬性,剋服了用資訊增益選擇屬性時偏向選擇取值多的屬性的不足; – 在樹構造過程中進行剪枝; – 能處理非離散的資料; – 能處理不完整的資料。
優點
產生的分類規則易於理解,準確率較高。
缺點
1. 在構造樹的過程中,需要對資料集進行多次的順序掃描和排序,因而導致演演算法的低效;
2. C4.5只適合於能夠駐留於記憶體的資料集,當訓練集大得無法在記憶體容納時程式無法執行。
3.5.2 CART分類與回歸樹
是一種決策樹分類方法,採用基於最小距離的基尼指數估計函式,用來決定由該子資料集生成的決策樹的拓展形。如果標的變數是標稱的,稱為分類樹;如果標的變數是連續的,稱為回歸樹。分類樹是使用樹結構演演算法將資料分成離散類的方法。
優點
1. 非常靈活,可以允許有部分錯分成本,還可指定先驗機率分佈,可使用自動的成本複雜性剪枝來得到歸納性更強的樹;
2. 在面對諸如存在缺失值、變數數多等問題時CART 顯得非常穩健。
3.6 Adaboosting
Adaboost是一種加和模型,每個模型都是基於上一次模型的錯誤率來建立的,過分關註分錯的樣本,而對正確分類的樣本減少關註度,逐次迭代之後,可以得到一個相對較好的模型。該演演算法是一種典型的boosting演演算法,其加和理論的優勢可以使用Hoeffding不等式得以解釋。
優點
1. Adaboost是一種有很高精度的分類器;
2. 可以使用各種方法構建子分類器,Adaboost演演算法提供的是框架;
3. 當使用簡單分類器時,計算出的結果是可以理解的,並且弱分類器的構造極其簡單;
4. 簡單,不用做特徵篩選;
5. 不易發生overfitting。
缺點
對outlier比較敏感。
3.7 SVM支援向量機
支援向量機,一個經久不衰的演演算法,高準確率,為避免過擬合提供了很好的理論保證,而且就算資料在原特徵空間線性不可分,只要給個合適的核函式,它就能執行得很好。在動輒超高維的文字分類問題中特別受歡迎。可惜記憶體消耗大,難以解釋,執行和調參也有些煩人,而隨機森林卻剛好避開了這些缺點,比較實用。
優點
1. 可以解決高維問題,即大型特徵空間;
2. 解決小樣本下機器學習問題;
3. 能夠處理非線性特徵的相互作用;
4. 無區域性極小值問題;(相對於神經網路等演演算法)
5. 無需依賴整個資料;
6. 泛化能力比較強。
缺點
1. 當觀測樣本很多時,效率並不是很高;
2. 對非線性問題沒有通用解決方案,有時候很難找到一個合適的核函式;
3. 對於核函式的高維對映解釋力不強,尤其是徑向基函式;
4. 常規SVM只支援二分類;
5. 對缺失資料敏感。
對於核的選擇也是有技巧的(libsvm中自帶了四種核函式:線性核、多項式核、RBF以及sigmoid核):
第一,如果樣本數量小於特徵數,那麼就沒必要選擇非線性核,簡單的使用線性核就可以了;
第二,如果樣本數量大於特徵數目,這時可以使用非線性核,將樣本對映到更高維度,一般可以得到更好的結果;
第三,如果樣本數目和特徵數目相等,該情況可以使用非線性核,原理和第二種一樣。
對於第一種情況,也可以先對資料進行降維,然後使用非線性核,這也是一種方法。
SVM應用領域
文字分類、影象識別(主要二分類領域,畢竟常規SVM只能解決二分類問題)
3.8 人工神經網路的優缺點
人工神經網路的優點:
1. 分類的準確度高;
2. 並行分佈處理能力強,分佈儲存及學習能力強;
3. 對噪聲神經有較強的魯棒性和容錯能力;
4. 具備聯想記憶的功能,能充分逼近複雜的非線性關係。
人工神經網路的缺點:
1. 神經網路需要大量的引數,如網路拓撲結構、權值和閾值的初始值;
2. 黑盒過程,不能觀察之間的學習過程,輸出結果難以解釋,會影響到結果的可信度和可接受程度;
3. 學習時間過長,有可能陷入區域性極小值,甚至可能達不到學習的目的。
人工神經網路應用領域:
目前深度神經網路已經應用與計算機視覺,自然語言處理,語音識別等領域並取得很好的效果。
3.9 K-Means聚類
是一個簡單的聚類演演算法,把n的物件根據他們的屬性分為k個分割,k< n。 演演算法的核心就是要最佳化失真函式J,使其收斂到區域性最小值但不是全域性最小值。
關於K-Means聚類的文章,參見機器學習演演算法-K-means聚類。關於K-Means的推導,裡面可是有大學問的,蘊含著強大的EM思想。
優點
1. 演演算法簡單,容易實現 ;
2. 演演算法速度很快;
3. 對處理大資料集,該演演算法是相對可伸縮的和高效率的,因為它的複雜度大約是O(nkt),其中n是所有物件的數目,k是簇的數目,t是迭代的次數。通常k<
4. 演演算法嘗試找出使平方誤差函式值最小的k個劃分。當簇是密集的、球狀或團狀的,且簇與簇之間區別明顯時,聚類效果較好。
缺點
1. 對資料型別要求較高,適合數值型資料;
2. 可能收斂到區域性最小值,在大規模資料上收斂較慢;
3. 分組的數目k是一個輸入引數,不合適的k可能傳回較差的結果;
4. 對初值的簇心值敏感,對於不同的初始值,可能會導致不同的聚類結果;
5. 不適合於發現非凸面形狀的簇,或者大小差別很大的簇;
6. 對於”噪聲”和孤立點資料敏感,少量的該類資料能夠對平均值產生極大影響。
3.10 EM最大期望演演算法
EM演演算法是基於模型的聚類方法,是在機率模型中尋找引數最大似然估計的演演算法,其中機率模型依賴於無法觀測的隱藏變數。E步估計隱含變數,M步估計其他引數,交替將極值推向最大。
EM演演算法比K-means演演算法計算複雜,收斂也較慢,不適於大規模資料集和高維資料,但比K-means演演算法計算結果穩定、準確。EM經常用在機器學習和計算機視覺的資料集聚(Data Clustering)領域。
3.11 整合演演算法(AdaBoost演演算法)
AdaBoost演演算法優點:
1. 很好的利用了弱分類器進行級聯;
2. 可以將不同的分類演演算法作為弱分類器;
3. AdaBoost具有很高的精度;
4. 相對於bagging演演算法和Random Forest演演算法,AdaBoost充分考慮的每個分類器的權重。
Adaboost演演算法缺點:
1. AdaBoost迭代次數也就是弱分類器數目不太好設定,可以使用交叉驗證來進行確定;
2. 資料不平衡導致分類精度下降;
3. 訓練比較耗時,每次重新選擇當前分類器最好切分點。
AdaBoost應用領域:
樣式識別、計算機視覺領域,用於二分類和多分類場景
3.12 排序演演算法(PageRank)
PageRank是google的頁面排序演演算法,是基於從許多優質的網頁連結過來的網頁,必定還是優質網頁的回歸關係,來判定所有網頁的重要性。(也就是說,一個人有著越多牛X朋友的人,他是牛X的機率就越大。)
PageRank優點
完全獨立於查詢,只依賴於網頁連結結構,可以離線計算。
PageRank缺點
1. PageRank演演算法忽略了網頁搜尋的時效性;
2. 舊網頁排序很高,存在時間長,積累了大量的in-links,擁有最新資訊的新網頁排名卻很低,因為它們幾乎沒有in-links。
3.13 關聯規則演演算法(Apriori演演算法)
Apriori演演算法是一種挖掘關聯規則的演演算法,用於挖掘其內含的、未知的卻又實際存在的資料關係,其核心是基於兩階段頻集思想的遞推演演算法 。
Apriori演演算法分為兩個階段:
1. 尋找頻繁項集;
2. 由頻繁項集找關聯規則。
演演算法缺點:
1. 在每一步產生侯選專案集時迴圈產生的組合過多,沒有排除不應該參與組合的元素;
2. 每次計算項集的支援度時,都對資料庫中 的全部記錄進行了一遍掃描比較,需要很大的I/O負載。
4. 演演算法選擇參考
之前筆者翻譯過一些國外的文章,其中有一篇文章中給出了一個簡單的演演算法選擇技巧:
1. 首當其衝應該選擇的就是邏輯回歸,如果它的效果不怎麼樣,那麼可以將它的結果作為基準來參考,在基礎上與其他演演算法進行比較;
2. 然後試試決策樹(隨機森林)看看是否可以大幅度提升你的模型效能。即便最後你並沒有把它當做為最終模型,你也可以使用隨機森林來移除噪聲變數,做特徵選擇;
3. 如果特徵的數量和觀測樣本特別多,那麼當資源和時間充足時(這個前提很重要),使用SVM不失為一種選擇。
通常情況下:【GBDT>=SVM>=RF>=Adaboost>=Other…】,現在深度學習很熱門,很多領域都用到,它是以神經網路為基礎的,目前筆者自己也在學習,只是理論知識不扎實,理解的不夠深入,這裡就不做介紹了,希望以後可以寫一片拋磚引玉的文章。
演演算法固然重要,但好的資料卻要優於好的演演算法,設計優良特徵是大有裨益的。假如你有一個超大資料集,那麼無論你使用哪種演演算法可能對分類效能都沒太大影響(此時就可以根據速度和易用性來進行抉擇)。
推薦閱讀 (點選標題可跳轉閱讀)
覺得本文有幫助?請分享給更多人
關註「演演算法愛好者」加星標,修煉程式設計內功

喜歡就點一下「好看」唄~

