精選 5 篇來自 ICLR 2019、WSDM 2019、EMNLP 2018、CIKM 2018和IJCAI 2018 的知識圖譜相關工作,帶你快速瞭解知識圖譜領域最新研究進展。
本期內容選編自微信公眾號「開放知識圖譜」。


■ 論文解讀 | 張文,浙江大學在讀博士,研究方向為知識圖譜的表示學習,推理和可解釋
本文是我們與蘇黎世大學合作的工作,將發表於 WSDM 2019,這篇工作在知識圖譜的表示學習中考慮了物體和關係的交叉互動,並且從預測準確性和可解釋性兩個方面評估了表示學習結果的好壞。
模型
給定知識圖譜和一個要預測的三元組的頭物體和關係,在預測尾物體的過程中,頭物體和關係之間是有交叉互動的 crossover interaction,即關係決定了在預測的過程中哪些頭物體的資訊是有用的,而對預測有用的頭物體的資訊又決定了採用什麼邏輯去推理出尾物體。
文中透過一個模擬的知識圖譜進行了說明,如下圖所示:
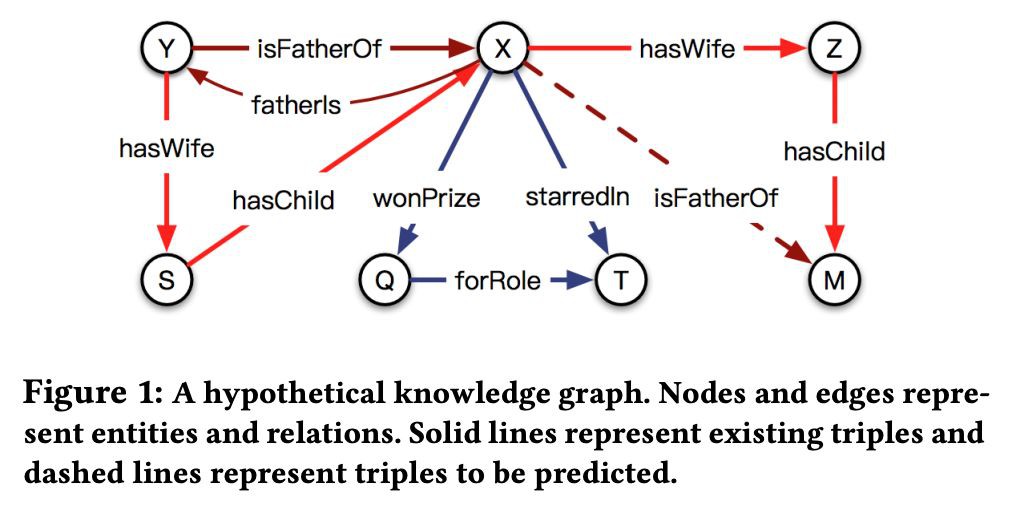
基於對頭物體和關係之間交叉互動的觀察,本文提出了一個新的知識圖譜表示學習模型 CrossE。CrossE 除了學習物體和關係的向量表示,同時還學習了一個互動矩陣 C,C 與關係相關,並且用於生成物體和關係經過互動之後的向量表示,所以在 CrossE 中物體和關係不僅僅有通用向量表示,同時還有很多交互向量表示。
CrossE 核心想法如下圖:

在 CrossE 中,頭物體的向量首先和互動矩陣作用生成頭物體的互動表示,然後頭物體的互動表示和關係作用生成關係的互動表示,最後頭物體的互動表示和關係的互動表示參與到具體的三元組計算過程。
對於一個三元組的計算過程展開如下:
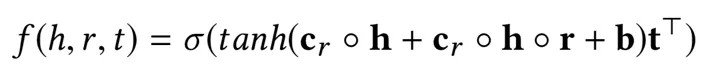
實驗
實驗中本文首先用連結預測的效果衡量了表示學習的效果,實驗採用了三個資料集 WN18、FB15k 和 FB15k-237,實驗結果如下:


從實驗結果中我們可以看出,CrossE 實現了較好的連結預測結果。我們去除 CrossE 中的頭物體和關係的交叉互動,構造了模型 CrossES,CrossE 和 CrossES 的比較說明瞭交叉互動的有效性。
除了連結預測,我們還從一個新的角度評估了表示學習的效果,即可解釋性。我們提出了一種基於相似結構透過知識圖譜的表示學習結果生成預測結果解釋的方法,並提出了兩種衡量解釋結果的指標,AvgSupport 和 Recall。
Recall 是指模型能給出解釋的預測結果的佔比,其介於 0 和 1 之間且值越大越好;AvgSupport 是模型能給出解釋的預測結果的平均 support 個數,AvgSupport 是一個大於 0 的數且越大越好。可解釋的評估結果如下:
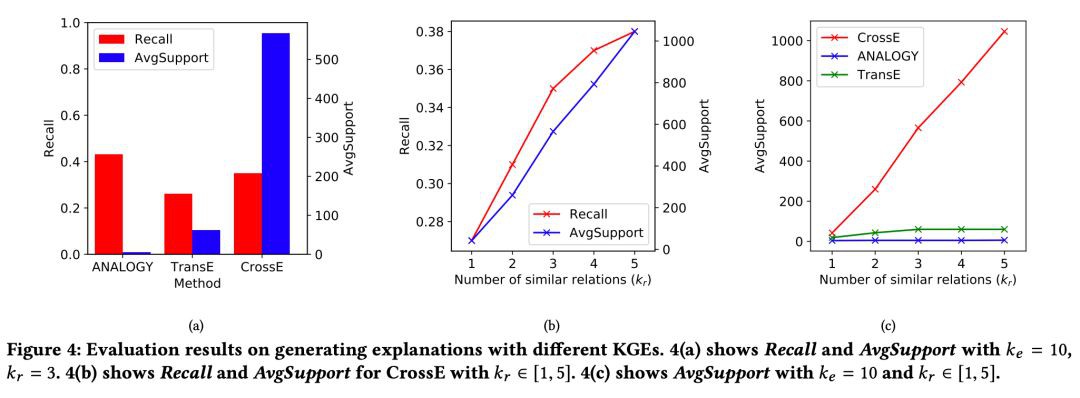
從實驗結果中我們可以看出,整體來說 CrossE 能夠更好地對預測結果生成解釋。
連結預測和可解釋的實驗從兩個不同的方面評估了知識圖譜表示學習的效果,同時也說明瞭連結預測的準確性和可解釋性沒有必然聯絡,連結預測效果好的模型並不一定能夠更好地提供解釋,反之亦然。


■ 論文解讀 | 王梁,浙江大學碩士,研究方向為知識圖譜,自然語言處理
論文動機
傳統的機器閱讀理解的模型都是給定 context 和 question,找出最有可能回答該 question 的 answer,用機率表示為 p(a|q,c),這其實是一個判別模型。判別模型在大多數任務上可以取得比生成模型更好的準確率,但問題在於判別模型會利用一切能提升準確率的資料特徵來做預測,這在機器閱讀中會造成模型並未完全理解 question 和 context,而是利用訓練集中的一些資料漏洞來預測。
如下圖所示,模型只需要 question 中有下劃線的詞即可預測出正確答案,無須完全理解問題。

在 SQuAD 中另一個典型的情況是:問題的疑問詞是 when 或者 who,而 context 中只有一個日期或者人名,這時模型只需要根據 question 的疑問詞,context 中的日期或人名即可回答問題,不用完全理解 question 和 context。
模型
因此,本文的作者提出基於生成模型架構的機器閱讀模型,其最佳化的標的是:給定 context,最大化 question 和 answer 的聯合機率,用機率表示為 p(a,q|c)。該機率可以分解為 p(a|c)p(q|a,c)。對於這兩部分,分別訓練兩個模型,最後在預測時,遍歷所有候選的 answer 選出最大化聯合機率 p(a,q|c) 的 answer 作為預測結果。
首先訓練 p(a|c) 部分,即給定 context,選出最有可能出現的候選的 answer。根據 context 的不同,採用不同的方式。
1. 如果 context 是檔案,例如 SQuAD 資料集,那麼用 ELMo 得到 context 的表示後,該表示經過全連線層對映得到一個 score(記為),該 score 在和候選 answer 的長度指標 (),這兩個 score 按如下公式得到每個候選 answer 的機率。
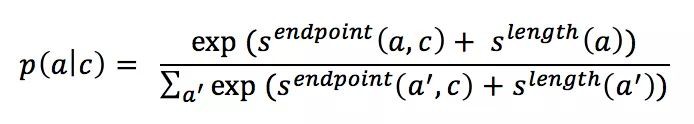
2. 如果 context 是圖片,例如 CLEVR 資料集,那麼在預訓練的 RESNet 上 fine tuning 得到圖片的表示,對所有候選 answer 分類得到每個 answer 出現的機率。
其次是 p(q|a,c) 部分,本文將其看做是文字生成問題,即採用 Encoder-Decoder 架構,根據 answer, context 的 encoding 結果,採用 decoder 生成 question。模型採用的 Decoder 的架構為:

其主要包含一個迴圈 N 詞的 decoder block,每個 block 內部 t 時刻生成的詞的 embedding 會先經過 self-attention 和 attention 計算,得到的結果再經過一個 LSTM 單元,如此重覆 N 次並最終依存 t+1 時刻的詞。
為瞭解決稀疏詞的問題,在預測每個詞被生成的機率時採用了 character 級別的 embedding 和 pointer-generator 機制。
到這裡模型已經介紹完畢。但是論文中提到了按照上述標的函式和模型結構訓練完後,還有一個 fine-tuning 的步驟,這一步的標的是透過人為構造 question 和 answer 的負組合,來強化模型生成 question 時和 answer 的關聯。
Fine-tuning 的標的函式是最小化如下式子:
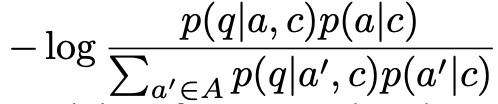
其中 A 是由 p(a|c) 選出的在當前 context 下最有可能的 top k 個候選 answer。
實驗
模型的實驗結果如下所示,在 SQuAD 和 CLEVR 上都取得了僅次於當前 state-of-the-art 的判別式機器閱讀模型的效果:


可以看到生成模型的效果要比效果最好的判別模型略差,但是本文的論點在於生成模型對 question 和 context 有更全面的理解,從而讓模型有更好的泛化能力和應對對抗樣本的能力。
為了驗證模型的泛化能力,本文作者構建了一個 SQuAD 的子集,該子集中訓練樣本中的 context 都只包含一個日期,數字或者人名類物體,但是在測試樣本中有多個。如果模型在訓練時僅依賴 context 中特殊型別的物體作為答案的資料特徵,那麼在測試集上就會表現很差。
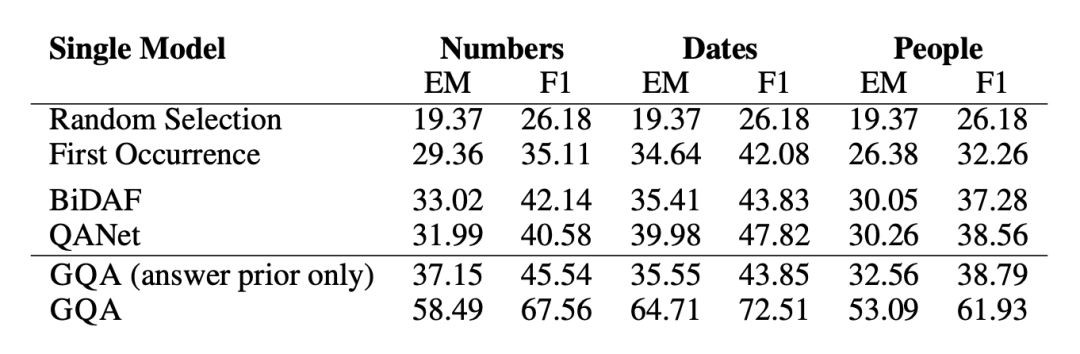
可以看到在該資料集上生成模型有很大的優勢。
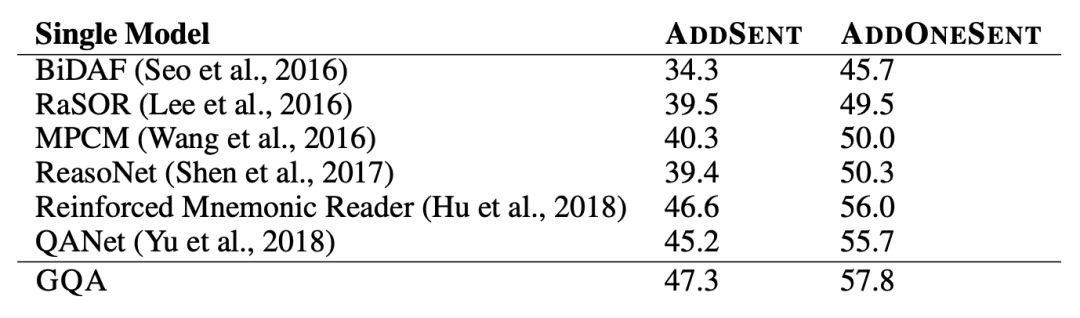
在包含對抗樣本的資料集 Adversarial SQuAD 上的表現也好過判別模型。


■ 論文解讀 | 張良,東南大學博士,研究方向為知識圖譜,自然語言處理
知識圖譜的表示學習最近幾年被廣泛研究,表示學習的結果對知識圖譜補全和資訊抽取都有很大幫助。本文提出了一種新的區分概念和實體的知識圖譜表示學習方法,將上下位關係與普通的關係做了區分,可以很好的解決上下位關係的傳遞性問題,並且能夠表示概念在空間中的層次與包含關係。
本文的主要貢獻有三點:
1. 第一次提出並形式化了知識圖譜嵌入過程中概念與實體區分的問題
2. 提出了一個新的嵌入模型 TransC 模型,該模型區分了概念與實體,並能處理 isA 關係的傳遞性;
3. 基於 YAGO 新建了一個用於評估的資料集。
論文動機
傳統的表示學習方法沒能區分概念(concept)和實體(instance)之間的區別,而是多數統一看作物體(entity),而概念顯然和實體不是同一個層次的,統一的表示是有欠缺的。更重要的是,之前的方法多數無法解決上下位關係傳遞性的問題,這是不區分概念和實體表示的弊端。
本文創造性地將概念表示為空間中的一個球體,實體為空間中的點,透過點和球體的空間包含關係和球體間的包含關係來表示上下位關係,這種表示可以很自然地解決上下位關係傳遞性的問題。下圖是一個區分了概念,實體的層次關係圖。

模型
通常在人們的腦海裡,概念都是透過層級的方式組織起來的,而實體也應歸屬於與它們各自對應的概念。受此啟發,本文提出了 TransC 模型來處理概念和實體區分的問題。
在 TransC 模型裡,每一個概念都被表示成一個球體,而每一個實體都被表示到與對應概念相同的語意空間中。概念與實體以及概念與概念之間的相對位置分別透過 instanceOf 關係與 subClassOf 關係來刻畫。
InstanceOf 關係用來表示某個實體是否在概念所表示的球體中,subClassOf 關係用來表示兩個概念之間的相對位置,文中提出了四種可能的相對位置:

如上圖所示,(a)、(b)、(c)、(d)分別表示兩個概念所表示球體的相對位置,其中 m 為球體半徑,d 為兩個球體中心的距離,Si 與 Sj 分別表示概念 i 與概念 j 所表示成的球體。
對於 instanceOf 關係與 subClassOf 關係,文中有比較巧妙的設計以便保留 isA 關係的傳遞性,即 instanceOf-subClassOf 的傳遞性透過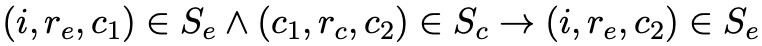 來體現。
來體現。
而 subClassOf-subClassOf 的傳遞性透過 來體現,其中 (i, r_e, c) 表示 InstanceOf 三元組,(c_i, r_c, c_j) 表示 SubClassOf 三元組。
來體現,其中 (i, r_e, c) 表示 InstanceOf 三元組,(c_i, r_c, c_j) 表示 SubClassOf 三元組。
文中設計了不同的損失函式去度量 embedding 空間中的相對位置,然後用基於翻譯的模型將概念,實體以及關係聯合起來進行學習。在文中主要有三類 triple,所以分別定義了不同的損失函式。
InstanceOf Triple表示:對於一個給定的 instanceOf triple,如果它是正確的,那麼 i 就應該被包含在概念 c 所表示的球體 s 裡。而實際上,除了被包含以外,很顯然還有一種相對位置就是實體 i 在球體 s(P,m)之外,損失函式設計為 。
。
SubClassOf Triple表示:對於一個給定的 subClassOf triple (c_i, r_c, c_j) ,首先定義兩個球中心之間的距離 ,按照圖 1 所示的四種關係,還有另外三種損失函式需要定義。
,按照圖 1 所示的四種關係,還有另外三種損失函式需要定義。
1. 按照圖 1 中(b)表示的相對位置,兩個球是分開的,損失函式表示為 。
。
2. 兩個球相交,如圖 1 中(c)所示,損失函式表示為,與(1)類似。
3. 完全包含關係,如圖 1 中(d)所示,損失函式表示為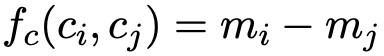 (減小mj,增大mi)。
(減小mj,增大mi)。
Relational Triple 表示:對於一個 relational triple (h, r, t),TransC 利用 TransE 模型的訓練方式來得到物體和關係的向量,所以損失函式定義為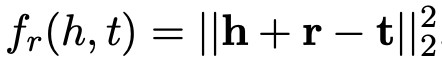 。
。
對於模型的訓練,分別用 ξ 和 ξ’ 來表示正確和錯誤的三元組,根據以上幾類損失函式,可以對應得到以下幾類損失:
對於 instanceOf triples,損失表示為:

對於 subClassOf triples,損失表示為:
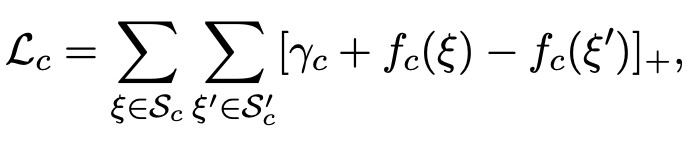
對於 relational triples,損失表示為:
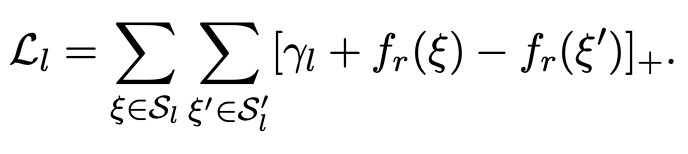
最後,模型的最終損失函式為以上幾類損失的線性組合,即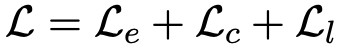 。
。
實驗
以往的大多數模型都用 FB15K 和 WN18 來作為評估的資料集,但這兩個資料集並不很適合文中的模型,而 YAGO 資料集不僅含了許多概念而且還有不少實體,所以作者構建了一個 YAGO 資料集的子集 YAGO39K 來用作試驗評估。
實驗分別在連結預測,三元組分類以及 instanceOf 與 subClassOf 關係的三元組分類這幾項任務上進行,實驗結果如下:
連結預測與三元組分類結果:

instanceOf triple 分類結果:

subClassOf triple 分類結果:
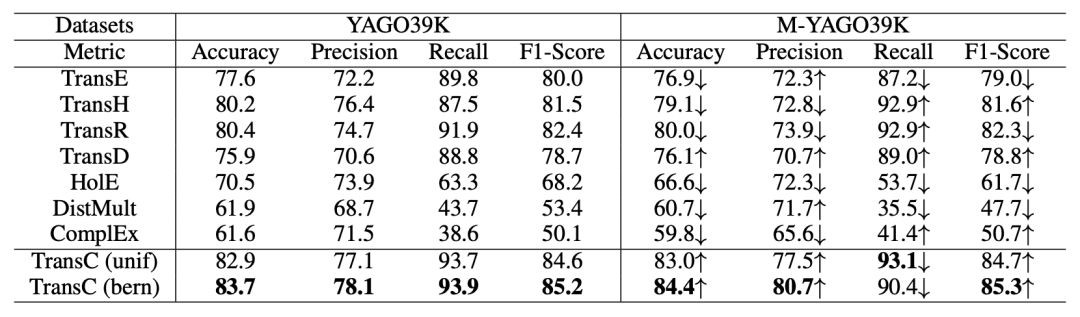
實驗結果表明,TransC 模型在相關任務上與其它模型相比有較為顯著的提升。
總結
本文從 Ontology 層面對知識表示學習進行了較為深入的研究,提出了新的知識圖譜嵌入模型 TransC 模型,該模型將實體、概念以及關係嵌入到同一個空間中以便用來處理 isA 關係的傳遞性。
在實驗部分,作者還建立了一個用來評估模型的新資料集 YAGO39K。實驗結果表明 TransC 模型在大多數任務上要優於傳統的翻譯模型。
對於文中將概念表示成球體的想法似乎還可以繼續探討,作者將會繼續尋找適合表示概念的方式。另外,每個概念在不同的三元組裡可能會有不同的表示,如何進一步地將概念的多意性表達出來也是一個值得探究的方向。
在傳統的知識工程領域,知識是透過 schema 組織起來的,有較強的邏輯性,但在語意計算層面相比向量來說沒有優勢,最近有不少將二者相結合的工作(給語意的向量計算披上邏輯的外衣)值得關註一下。


■ 解讀 | 譚亦鳴,東南大學博士生,研究興趣:知識問答,自然語言處理,機器翻譯
本文是發表在 CIKM 2018 的短文,關註有時間資訊的複雜知識庫問答工作。文章提出使用 TimeML(一種時間相關的標註語言)對問題進行標註,在識別時間相關問題後,根據時間特徵將複雜問題改寫為多個時序相關的子問題,透過與現有的知識問答系統相關聯,實現帶有時間資訊的複雜問答。
論文動機
與簡單問題的處理方式不同,複雜問答一般會將原問題劃分為多個子問題,而後合併問題答案。作者發現,複雜問題中一個需要解決的重要問題是時間資訊的獲取。以下麵三個問題為例:
Q1: “Which teams did Neymar play for before joiningPSG?”
Q2: “Under which coaches did Neymar play inBarcelona?”
Q3: “After whom did Neymar’s sister choose her lastname?”
在 Q1 中,沒有明確的日期或者時間被提到,我們可以識別“joining PSG”代表了一個事件,然後透過它轉換為一個標準的時間資訊。而句子中的“before”則提供了另一個時間相關的線索,但是類似於“before, after”這樣的詞並不總是在句子中承擔這樣的角色,比如 Q3 中的“after”。
在 Q2 中,我們看不到類似 Q1 的時間依賴表達,但是“Neymar play in Barcelona”中依然包含了時間資訊。
因此可以發現,處理帶有時序資訊的複雜問題面對的第一個挑戰就是:如何從問句中識別時間資訊; 隨之產生的第二個挑戰則是:如何根據時間資訊將問題分解為時序相關的子問題。
方法
本文方法的關鍵過程是:1)分解問題;2)重寫子問題。
大體的標的如下:
還是以前面的問句為例,Q1: “Which teams did Neymar play for before joiningPSG” 改寫得到子問題 Q2.1, Q2.2。
Q1.1: “Which teams did Neymar play for?”
Q1.2: “When did Neymar join PSG?”
而後在問答過程中,透過 Q2.1,從知識庫中得到答案及時間範圍,再與 Q2.2 得到的時間相匹配,從而找到 Q2 的答案。
為了達到上述目的,本文提出一種基於規則的四步框架:
-
識別包含時間資訊的問題
-
分解問題並重寫子問題
-
獲取子問題答案
-
根據時間證據自合子問題答案
規則設計
本文構建的規則以 TimeML(一種標註語言)為理論基礎,用於識別句子及文字中的時間資訊。
標簽提供了以下資訊:
TIMEX3 tag,反映四類時間表達;
SIGNAL tag,反映時間表達標簽之間的關係(用於切分子問題)。
規則定義
包含時間資訊的問題:即出現了時間資訊表達或時間資訊關係的問句(標簽能在問句中標出內容)。
時間關係:Allen (J. F.Allen. 1990. Maintaining knowledge about temporal intervals. In Readings inqualitative reasoning about physical systems. Elsevier) 定義了 13 種時間關係,EQUAL, BEFORE, MEETS, OVERLAPS, DURING, STARTS, FINISHES。

表 1 列舉了子問題重寫規則。回答子問題時,對於包含時間資訊的子問題需要檢索可能的時間範圍。
實驗
本文實驗評估基於 TempQuestions benchmark,其中包含 1271 個時間相關問題,並使用三個目前最好的 KBQA 系統作為 baseline:AQQU, QUINT 和 Bao et al。在實驗中,作者將框架與問答系統整合到一起,構成對比模型。
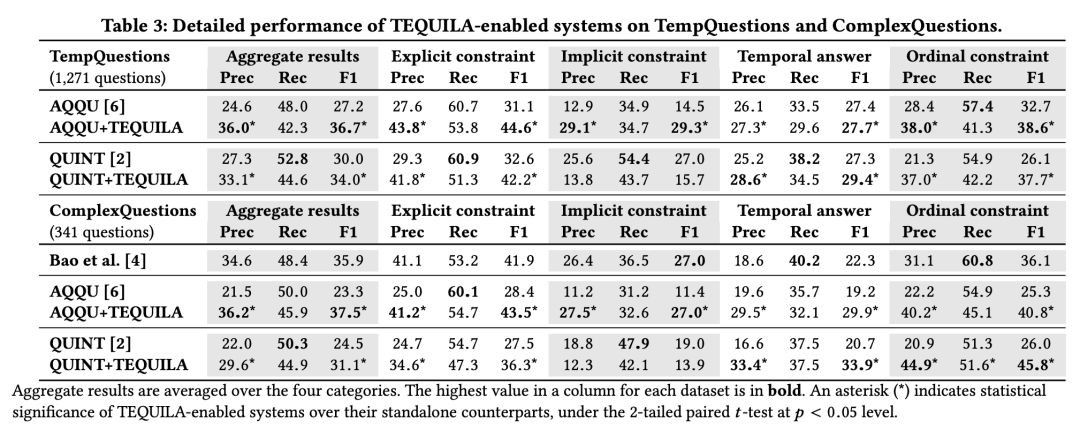
實驗結果反映出新增框架的問答系統的提升主要表現為 F1 與準確率的上升。
總結
本文提出了一種基於時間資訊標註的規則型時序複雜問答框架,主要以時間資訊的規則標註概念為基礎,將複雜問題的切分過程轉換為序列標註問題,並對已有人工規則加以利用,構建時序資訊間的關係。框架整體比較簡明,從規則角度看,還需要做部分深入閱讀方能較好理解該方法是否具有較好的泛化性。


■ 論文解讀 | 花雲程,東南大學博士,研究方向為知識圖譜問答、自然語言處理
論文動機
在以前的工作中,對話生成的資訊源是文字與對話記錄。但是這樣一來,如果遇到 OOV 的詞,模型往往難以生成合適的、有資訊量的回覆,而會產生一些低質量的、模稜兩可的回覆,這種回覆往往質量不高。
為瞭解決這個問題,有一些利用常識知識圖譜生成對話的模型被陸續提出。當使用常識性知識圖譜時,由於具備背景知識,模型更加可能理解使用者的輸入,這樣就能生成更加合適的回覆。但是,這些結合了文字、對話記錄、常識知識圖譜的方法,往往只使用了單一三元組,而忽略了一個子圖的整體語意,會導致得到的資訊不夠豐富。
為瞭解決這些問題,文章提出了一種基於常識知識圖譜的對話模型(commonsense knowledge aware conversational model,CCM)來理解對話,並且產生資訊豐富且合適的回覆。
本文提出的方法利用了大規模的常識性知識圖譜。首先是理解使用者請求,找到可能相關的知識圖譜子圖;再利用靜態圖註意力(static graphattention)機制,結合子圖來理解使用者請求;最後使用動態圖註意力(dynamic graph attention)機制來讀取子圖,並產生合適的回覆。
透過這樣的方法,本文提出的模型可以生成合適的、有豐富資訊的對話,提高對話系統的質量。
貢獻
文章的貢獻有:
1. 首次嘗試使用大規模常識性知識圖譜來處理對話生成問題;
2. 對知識圖譜子圖,提出了靜態/動態圖註意力機制來吸收常識知識,利於理解使用者請求與生成對話;
3. 對比於其他系統,目前的模型生成的回覆是最合適的、語法最正確的、資訊最豐富的。
方法
1. Encoder-Decoder模型
經典的 Encoder-Decoder 模型是基於 sequence-to-sequence(seq2seq)的。encoder 模型將使用者輸入(user post)X=x_1 x_2…x_n 用隱狀態 H=h_1 h_2…h_n 來表示。而 decoder 模型使用另一個 GRU 來迴圈生成每一個階段的隱狀態,即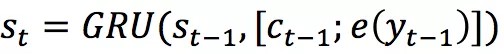 。在解碼過程中利用了註意力機制。
。在解碼過程中利用了註意力機制。
當 decoder 模型根據機率分佈生成了輸出狀態後,可以由這個狀態經過 softmax 操作得到最終的輸出 。可以看到,在這個經典的 encoder-decoder 模型中,並沒有圖的參與。
。可以看到,在這個經典的 encoder-decoder 模型中,並沒有圖的參與。
2. 模型框架
如下圖 1 所示為本文提出的 CCM 模型框架。
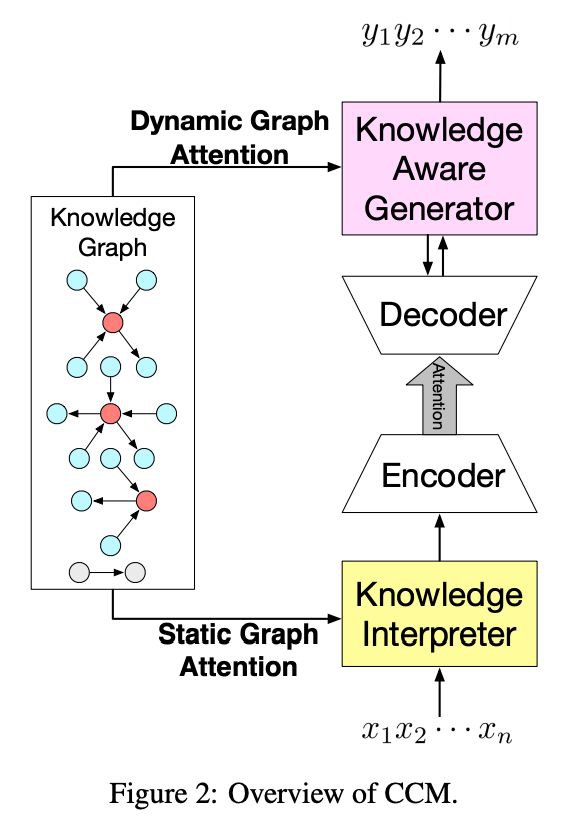
如圖 1 所示,基於 n 個詞輸入,會輸出 n 個詞作為回覆,模型的目的就是預估這麼一個機率分佈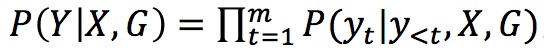 ,即將圖資訊 G 加入到機率分佈的計算中。
,即將圖資訊 G 加入到機率分佈的計算中。
在資訊讀取時,根據每個輸入的詞 x,找到常識知識圖譜中對應的子圖(若沒有對應的子圖,則會生成一個特殊的圖 Not_A_Fact),每個子圖又包含若干三元組。
⒊ 知識編譯模組
如圖 2 所示,為如何利用圖資訊編譯 post 的示意圖。
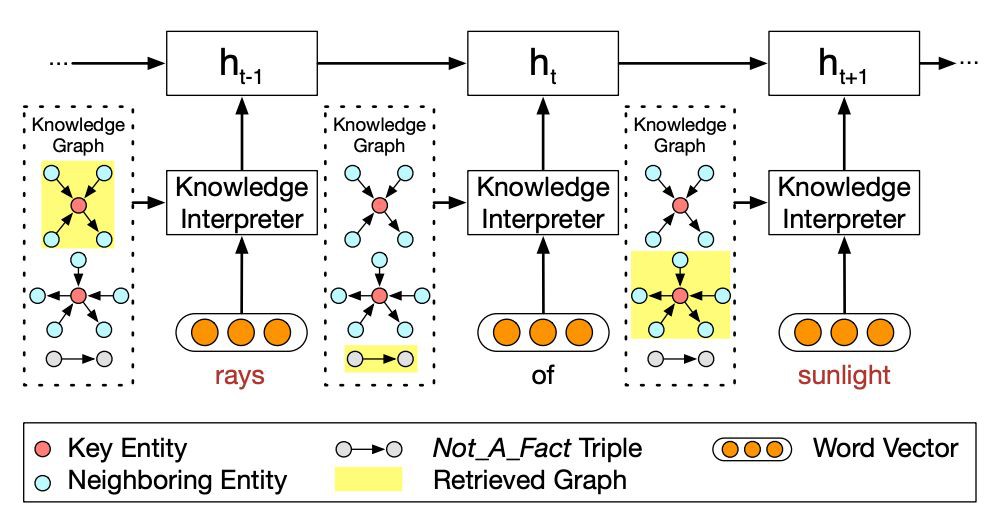
如圖所示,當編譯到“rays”時,會把這個詞在知識圖譜中相關的子圖得到(圖 2 最上的黃色高兩部分),並生成子圖的向量。每一個子圖都包含了 key entity(即這裡的 rays),以及這個“rays”的鄰居物體和相連關係。
對於詞“of”,由於無法找到對應的子圖,所以就採用特殊子圖 Not_A_Fact 來編譯。之後,採用基於靜態註意力機制,CCM 會將子圖對映為向量,然後把詞向量 w(x_t) 和 g_i 拼接為,並將這個替換傳統 encoder-decoder 中的 e(x_t) 進行 GRU 計算。
對於靜態圖註意力機制,CCM 是將子圖中所有的三元組都考慮進來,而不是隻計算一個三元組,這也是該模型的一個創新點。
⒋ 知識生成模組
如下圖 3 所示,為如何利用圖資訊生成回覆的示意圖。

在生成時,不同於靜態圖註意力機制,模型會讀取所有相關的子圖,而不是當前詞對應的子圖,而在讀取時,讀取註意力最大的就是圖中粉色高亮的部分。生成時,會根據計算結果,來選擇是生成通用字(generic word)還是子圖中的物體。
⒌ 損失函式
損失函式為預期輸出與實際輸出的交叉熵,除此之外,為了監控選擇通用詞還是物體的機率,又增加了一個交叉熵。
實驗
實驗相關細節
常識性知識圖譜選用了 ConceptNet,對話資料集選用了 reddit 的一千萬條資料集,如果一個 post-response 不能以一個三元組表示(一個物體出現於 post,另一個出現於 response),就將這個資料去除。
然後對剩下的對話資料,分為四類,一類是高頻詞,即每一個 post 的每一個詞,都是最高頻的 25% 的詞;一類是中頻詞,即 25%-75% 的詞;一類是低頻詞,即 75%-100% 的詞;最後一類是 OOV 詞,每一個 post 包含了 OOV 的詞。
而基線系統選擇瞭如下三個:只從對話資料中生成 response 的 seq2seq 模型、儲存了以 TransE 形式表示知識圖譜的 MemNet 模型、從三元組中 copy 一個詞或生成通用詞的 CopyNet 模型。
而選用 metric 的時候,採用了刻畫回覆內容是否語法正確且貼近主題的 perplexity,以及有多少個知識圖譜物體被生成的 entity score。
實驗結果
如下圖 4 所示,為根據 perplexity 和 entity score 進行的效能比較,可見 CCM 的 perplexity 最低,且選取 entity 的數量最多。並且,在低頻詞時,選用的 entity 更多。這表示在訓練時比較罕見的詞(物體)會需要更多的背景知識來生成答覆。

另外,作者還採用眾包的方式,來人為審核 response 的質量,並採用了兩種度量值 appropriateness(內容是否語法正確,是否與主題相關,是否有邏輯)與 informativeness(內容是否提供了 post 之外的新資訊)。
如下圖所示,為基於眾包的效能比較結果。

從上圖可見,CCM 對於三個基線系統來說,都有將近 60% 的回覆是更優的。並且,在 OOV 的資料集上,CCM 比 seq2seq 高出很多,這是由於 CCM 對於這些低頻詞或未登入詞,可以用知識圖譜去補全,而 seq2seq 沒有這樣的知識來源。
如下圖所示,當在 post 中遇到未登入詞“breakable”時,seq2seq 和 MemNet 都只能輸出一些通用的、模稜兩可的、毫無資訊量的回覆。CopyNet 能夠利用知識圖譜輸出一些東西,但是並不合適。而 CCM 卻可以輸出一個合理的回覆。

總結
本文提出了一種結合知識圖譜資訊的 encoder-decoder 方法,引入靜態/動態圖註意力機制有效地改善了對話系統中 response 的質量。透過自動的和基於眾包的形式進行效能對比,CCM 模型都是優於基線系統的。
