微服務是否適合小團隊是個見仁見智的問題。回歸現象看本質,隨著業務複雜度的提高,單體應用越來越龐大,就好像一個類的程式碼行越來越多,分而治之,切成多個類應該是更好的解決方法,所以一個龐大的單體應用分出多個小應用也更符合這種分治的思想。當然微服務架構不應該是一個小團隊一開始就該考慮的問題,而是慢慢演化的結果,謹慎過度設計尤為重要。
公司的背景是提供SaaS服務,對於大客戶也會有定製開發以及私有化部署。經過2年不到的時間,技術架構經歷了從單體到微服務再到容器化的過程。

早期開發只有兩個人,考慮微服務之類的都是多餘。不過由於受前公司影響,最初就決定了前後端分離的路線,因為不需要考慮SEO的問題,索性就做成了SPA單頁應用。多說一句,前後端分離也不一定就不能服務端渲染,例如電商系統或者一些匿名即可訪問的系統,加一層薄薄的View層,無論是PHP還是用Thymeleaf都是不錯的選擇。
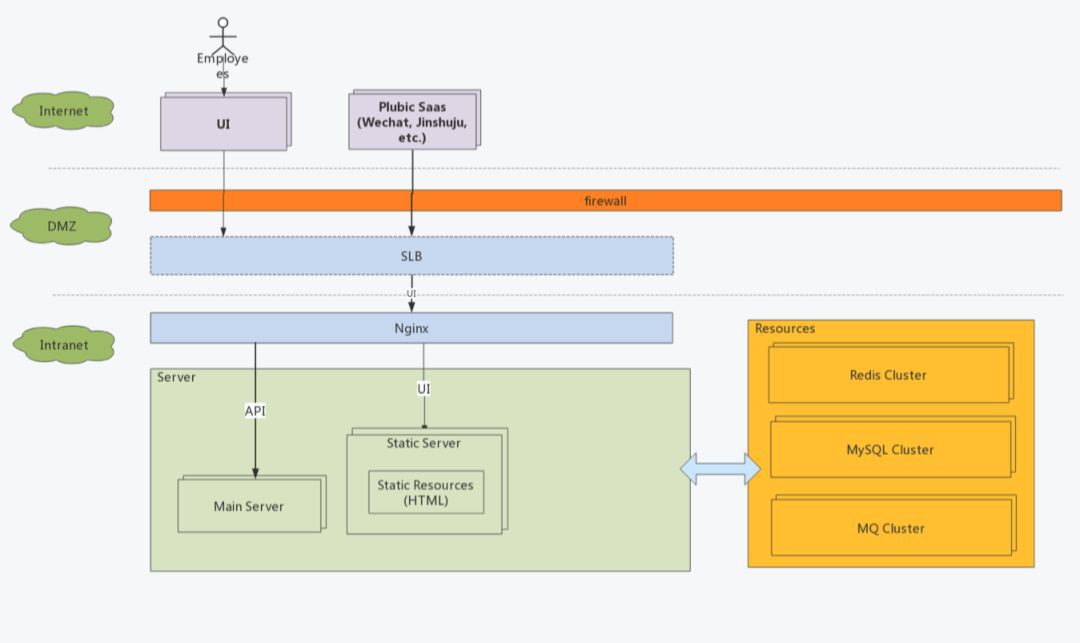
部署架構上,我們使用Nginx代理前端HTML資源,在接收請求時根據路徑反向代理到server的8080埠實現業務。
-
版本,統一跟在 /api/後面,例如 /api/v2
-
以資源為中心,使用複數表述,例如/api/contacts,也可以巢狀,如/api/groups/1/contacts/100
-
url中儘量不使用動詞,實踐中發現做到這一點真的比較難,每個研發人員的思路不一致,起的名字也千奇百怪,都需要在程式碼Review中改寫。
-
動作支援,POST / PUT / DELELE / GET ,這裡有一個坑,PUT和PATCH都是更新,但是PUT是全量更新而PATCH是部分更新,前者如果傳入的欄位是空(未傳也視為空)那麼也會被更新到資料庫中。目前我們雖然是使用PUT但是忽略空欄位和未傳欄位,本質上是一種部分更新,這也帶來了一些問題,比如確有置空的業務需要特殊處理。
-
介面透過swagger生成檔案供前端同事使用。
團隊初始成員之前都有在大團隊共事的經歷,所以對於質量管控和流程管理都有一些共同的要求。因此在開發之初就引入了整合測試的體系,可以直接開髮針對介面的測試用例,統一執行並計算改寫率。
一般來說程式碼自動執行的都是單元測試(Unit Test),我們之所以叫整合測試是因為測試用例是針對API的,並且包含了資料庫的讀寫,MQ的操作等等,除了外部服務的依賴基本都是符合真實生產場景,相當於把Jmeter的事情直接在Java層面做掉了。這在開發初期為我們提供了非常大的便利性。但值得註意的是,由於資料庫以及其他資源的引入,資料準備以及資料清理時要考慮的問題就會更多,例如如何控制並行任務之間的測試資料互不影響等等。
為了讓這一套流程可以自動化的運作起來, 引入Jenkins也是理所當然的事情了。
開發人員提交程式碼進入gerrit中,Jenkins被觸發開始編譯程式碼並執行整合測試,完成後生成測試報告,測試透過再由reviewer進行程式碼Review。在單體應用時代這樣的CI架構已經足夠好用,由於有整合測試的改寫,在保持API相容性的前提下進行程式碼重構都會變得更有信心。
從資料層面看,最簡單的方式就是看資料庫的表之間是否有比較少的關聯。例如最容易分離的一般來說都是使用者管理模組。如果從領域驅動設計(DDD)看,其實一個服務就是一個或幾個相關聯的領域模型,透過少量資料冗餘劃清服務邊界。單個服務內透過領域服務完成多個領域物件協作。當然DDD比較複雜,要求領域物件設計上是充血模型而非貧血模型。從實踐角度講,充血模型對於大部分開發人員來說難度非常高,什麼程式碼應該屬於行為,什麼屬於領域服務,很多時候非常考驗人員水平。
服務拆分是一個大工程,往往需要幾個對業務以及資料最熟悉的人一起討論,甚至要考慮到團隊結構,最終的效果是服務邊界清晰, 沒有環形依賴和避免雙向依賴。
由於之前的單體服務使用的是Spring Boot,所以框架自然而的選擇了Spring Cloud。其實個人認為微服務框架不應該限制技術與語言,但生產實踐中發現無論Dubbo還是Spring Cloud都具有侵入性,我們在將Node.js應用融入Spring Cloud體系時就發現了許多問題。也許未來的Service Mesh才是更合理的發展道路。
-
Zuul作為Gateway,分發不同客戶端的請求到具體Service
-
Erueka作為註冊中心,完成了服務發現和服務註冊
-
每個Service包括Gateway都自帶了Hystrix提供的限流和熔斷功能
-
Service之間透過Feign和Ribbon互相呼叫,Feign實際上是遮蔽了Service對Erueka的操作
上文說的一旦要融入異構語言的Service,那麼服務註冊,服務發現,服務呼叫,熔斷和限流都需要自己處理。再有關於Zuul要多說幾句,Spring Cloud提供的Zuul對Netflix版本的做了裁剪,去掉了動態路由功能(Groovy實現),另外一點就是Zuul的效能一般,由於採用同步程式設計模型,對於IO密集型等後臺處理時間長的鏈路非常容易將servlet的執行緒池佔滿,所以如果將Zuul與主要Service放置在同一臺物理機上,在流量大的情況下,Zuul的資源消耗非常大。實際測試也發現經過Zuul與直接呼叫Service的效能損失在30%左右,併發壓力大時更為明顯。現在Spring Cloud Gateway是Pivotal主推的,支援非同步程式設計模型,後續架構最佳化也許會採用,或是直接使用Kong這種基於Nginx的閘道器來提供效能。當然同步模型也有優點,編碼更簡單,後文將會提到使用ThreadLocal如何建立鏈路跟蹤。
經過大半年的改造以及新需求的加入,單體服務被不斷拆分,最終形成了10餘個微服務,並且搭建了Spark用於BI。初步形成兩大體系,微服務架構的線上業務系統(OLTP) + Spark大資料分析系統(OLAP)。資料源從只有MySQL增加到了ES和Hive。多資料源之間的資料同步也是值得一說的話題,但內容太多不在此文贅述。
服務拆分我們採用直接割接的方式,資料表也是整體遷移。因為幾次大改造的升級申請了停服,所以步驟相對簡單。如果需要不停服升級,那麼應該採用先雙寫再逐步切換的方式保證業務不受影響。
與CI比起來,持續交付(CD)實現更為複雜,在資源不足的情況我們尚未實現CD,只是實現執行了自動化部署。
由於生產環境需要透過跳板機操作,所以我們透過Jenkins生成jar包傳輸到跳板機,之後再透過Ansible部署到叢集。
簡單粗暴的部署方式在小規模團隊開發時還是夠用的,只是需要在部署前保證測試(人工測試 + 自動化測試)到位。
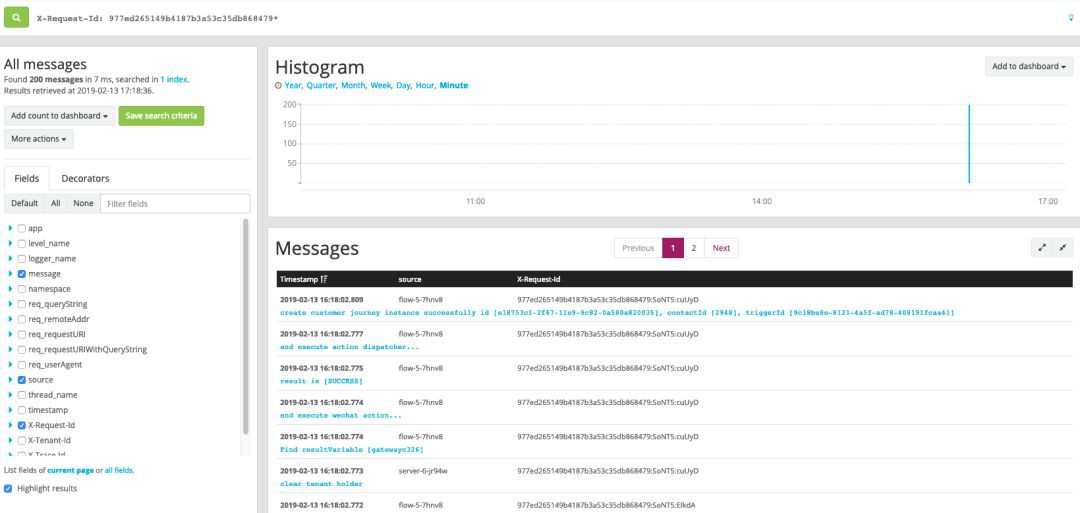
開源的全鏈路跟蹤很多,比如Spring Cloud Sleuth + Zipkin,國內有美團的CAT等等。其目的就是當一個請求經過多個服務時,可以透過一個固定值獲取整條請求鏈路的行為日誌,基於此可以再進行耗時分析等,衍生出一些效能診斷的功能。不過對於我們而言,首要目的就是trouble shooting,出了問題需要快速定位異常出現在什麼服務,整個請求的鏈路是怎樣的。
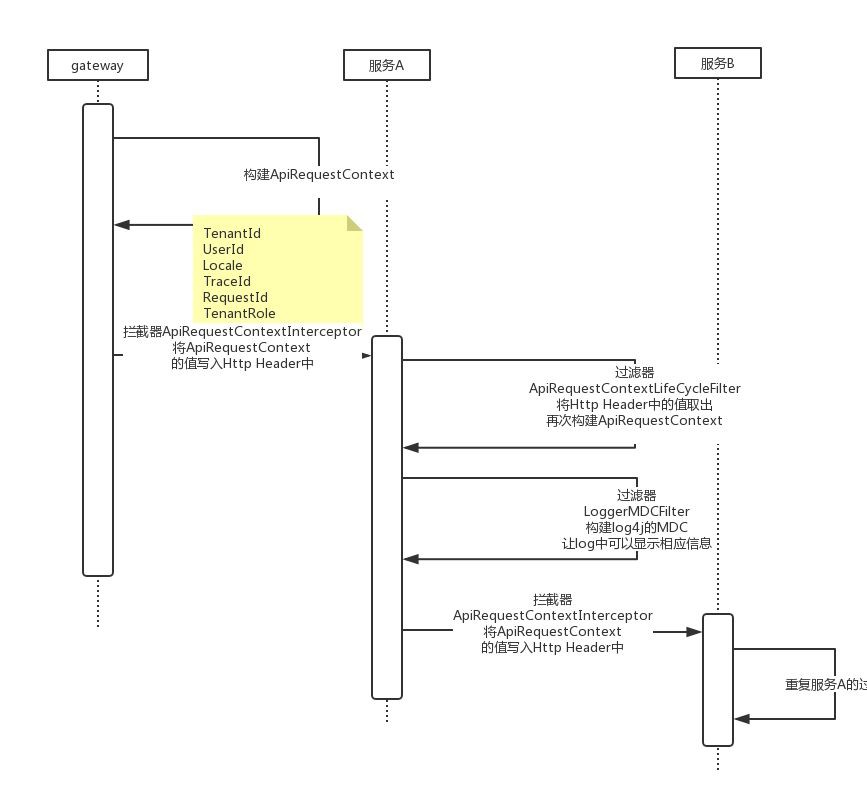
為了讓解決方案輕量,我們在日誌中列印RequestId以及TraceId來標記鏈路。RequestId在Gateway生成表示唯一一次請求,TraceId相當於二級路徑,一開始與RequestId一樣,但進入執行緒池或者訊息佇列後,TraceId會增加標記來標識唯一條路徑。舉個例子,當一次請求會向MQ傳送一個訊息,那麼這個訊息可能會被多個消費者消費,此時每個消費執行緒都會自己生成一個TraceId來標記消費鏈路。加入TraceId的目的就是為了避免只用RequestId過濾出太多日誌。實現如圖所示:
簡單的說,透過ThreadLocal存放APIRequestContext串聯單服務內的所有呼叫,當跨服務呼叫時,將APIRequestContext資訊轉化為Http Header,被呼叫方獲取到Http Header後再次構建APIRequestContext放入ThreadLocal,重覆迴圈保證RequestId和TraceId不丟失即可。如果進入MQ,那麼APIRequestContext資訊轉化為Message Header即可(基於Rabbitmq實現)。
當日誌彙總到日誌系統後,如果出現問題,只需要捕獲發生異常的RequestId或是TraceId即可進行問題定位。
經過一年來的使用,基本可以滿足絕大多數trouble shooting的場景,一般半小時內即可定位到具體業務。
在容器化之前,採用Telegraf + InfluxDB + Grafana的方案。Telegraf作為探針收集JVM,System,MySQL等資源的資訊,寫入InfluxDB,最終透過Grafana做資料視覺化。Spring Boot Actuator可以配合Jolokia暴露JVM的Endpoint。整個方案零編碼,只需要花時間配置。
因為在做微服務之初就計劃了容器化,所以架構並未大動,只是每個服務都會建立一個Dockerfile用於建立docker image。
-
CI中多了構建docker image的步驟
-
自動化測試過程中將資料庫升級從應用中剝離單獨做成docker image
-
生產中用Kubernetes自帶的Service替代了Eruka
Spring Cloud與Kubernetes的融合
我們使用的是Redhat的OpenShift,可以認為是Kubernetes企業版,其本身就有Service的概念。一個Service下有多個Pod,Pod內即是一個可服務單元。Service之間互相呼叫時Kubernetes會提供預設的負載均衡控制,發起呼叫方只需要寫被呼叫方的ServiceId即可。這一點和Spring Cloud Fegin使用Ribbon提供的功能如出一轍。也就是說服務治理可以透過Kubernetes來解決,那麼為什麼要替換呢?其實上文提到了,Spring Cloud技術棧對於異構語言的支援問題,我們有許多BFF(Backend for Frontend)是使用Node.js實現的,這些服務要想融合到Spring Cloud中,服務註冊,負載均衡,心跳檢查等等都要自己實現。如果以後還有其他語言架構的服務加入進來,這些輪子又要重造。基於此類原因綜合考量後,決定採用OpenShift所提供的網路能力替換Eruka。
由於本地開發和聯調過程中依然依賴Eruka,所以只在生產上透過配置引數來控制:
-
eureka.client.enabled設定為false,停止各服務的Eureka註冊
-
ribbon.eureka.enabled設定為false,讓Ribbon不從Eureka獲取服務串列
-
以服務foo為例,foo.ribbon.listofservers 設定為 http://foo:8080,那麼當一個服務需要使用服務foo的時候,就會直接呼叫到http://foo:8080
CI的改造主要是多了一部編譯docker image並打包到Harbor的過程,部署時會直接從Harbor拉取映象。另一個就是資料庫的升級工具。之前我們使用flyway作為資料庫升級工具,當應用啟動時自動執行SQL指令碼。隨著服務實體越來越多,一個服務的多個實體同時升級的情況也時有發生,雖然flyway是透過資料庫鎖實現了升級過程不會有併發,但會導致被鎖服務啟動時間變長的問題。從實際升級過程來看,將可能發生的併發升級變為單一行程可能更靠譜。此外後期分庫分表的架構也會使隨應用啟動自動升級資料庫變的困難。綜合考量,我們將升級任務做了拆分,每個服務都有自己的升級專案並會做容器化。在使用時,作為run once的工具來使用,即docker run -rm的方式。並且後續也支援了設定標的版本的功能,在私有化專案的跨版本升級中起到了非常好的效果。
至於自動部署,由於服務之間存在上下游關係,例如Config,Eruka等屬於基本服務被其他服務依賴,部署也產生了先後順序。基於Jenkins做Pipeline可以很好的解決這個問題。
其實以上的每一點都可以深入的寫成一篇文章,微服務的架構演進涉及到開發,測試和運維,要求團隊內多工種緊密合作。分治是軟體行業解決大系統的不二法門,作為小團隊我們並沒有盲目追新,而是在發展的過程透過服務化的方式解決問題。從另一方面我們也體會到了微服務對於人的要求,以及對於團隊的挑戰都比過去要高要大。未來仍需探索,演進仍在路上。
作者:Dean,曾就職SAP,目前在初創團隊任職架構師。
原文連結:https://deanwangpro.com/2019/02/18/road-of-microservice/
Kubernetes實戰培訓將於2019年3月8日在深圳開課,3天時間帶你係統掌握Kubernetes,學習效果不好可以繼續學習。本次培訓包括:雲原生介紹、微服務;Docker基礎、Docker工作原理、映象、網路、儲存、資料捲、安全;Kubernetes架構、核心元件、常用物件、網路、儲存、認證、服務發現、排程和服務質量保證、日誌、監控、告警、Helm、實踐案例等。
長按二維碼向我轉賬

受蘋果公司新規定影響,微信 iOS 版的贊賞功能被關閉,可透過二維碼轉賬支援公眾號。