(點選上方藍字,快速關註我們)
英文:highscalable,翻譯:可觀
https://my.oschina.net/juliashine/blog/88173
統的可擴充套件性是推動NoSQL運動發展的的主要理由,包含了分散式系統協調,故障轉移,資源管理和許多其他特性。這麼講使得NoSQL聽起來像是一個大筐,什麼都能塞進去。儘管NoSQL運動並沒有給分散式資料處理帶來根本性的技術變革,但是依然引發了鋪天蓋地的關於各種協議和演演算法的研究以及實踐。正是透過這些嘗試逐漸總結出了一些行之有效的資料庫構建方法。在這篇文章裡,我將針對NoSQL資料庫的分散式特點進行一些系統化的描述。
接下來我們將研究一些分散式策略,比如故障檢測中的複製,這些策略用黑體字標出,被分為三段:
-
資料一致性。NoSQL需要在分散式系統的一致性,容錯性和效能,低延遲及高可用之間作出權衡,一般來說,資料一致性是一個必選項,所以這一節主要是關於資料複製和資料恢復。
-
資料放置。一個資料庫產品應該能夠應對不同的資料分佈,叢集拓撲和硬體配置。在這一節我們將討論如何分佈以及調整資料分佈才能夠能夠及時解決故障,提供持久化保證,高效查詢和保證叢集中的資源(如記憶體和硬碟空間)得到均衡使用。
-
對等系統。像 leader election 這樣的的技術已經被用於多個資料庫產品以實現容錯和資料強一致性。然而,即使是分散的的資料庫(無中心)也要跟蹤它們的全域性狀態,檢測故障和拓撲變化。這一節將介紹幾種使系統保持一致狀態的技術。
資料一致性
眾所周知,分散式系統經常會遇到網路隔離或是延遲的情況,在這種情況下隔離的部分是不可用的,因此要保持高可用性而不犧牲一致性是不可能的。這一事實通常被稱作“CAP理論”。然而,一致性在分散式系統中是一個非常昂貴的東西,所以經常需要在這上面做一些讓步,不只是針對可用性,還有多種權衡。為了研究這些權衡,我們註意到分散式系統的一致性問題是由資料隔離和複製引起的,所以我們將從研究複製的特點開始:
-
可用性。在網路隔離的情況下剩餘部分仍然可以應對讀寫請求。
-
讀寫延遲。讀寫請求能夠在短時間內處理。
-
讀寫延展性。讀寫的壓力可由多個節點均衡分擔。
-
容錯性。對於讀寫請求的處理不依賴於任何一個特定節點。
-
資料永續性。特定條件下的節點故障不會造成資料丟失。
-
一致性。一致性比前面幾個特性都要複雜得多,我們需要詳細討論一下幾種不同的觀點。 但是我們不會涉及過多的一致性理論和併發模型,因為這已經超出了本文的範疇,我只會使用一些簡單特點構成的精簡體系。
-
原子寫。假如資料庫提供了API,一次寫操作只能是一個單獨的原子性的賦值,避免寫衝突的辦法是找出每個資料的“最新版本”。這使得所有的節點都能夠在更新結束時獲得同一版本,而與更新的順序無關,網路故障和延遲經常造成各節點更新順序不一致。 資料版本可以用時間戳或是使用者指定的值來表示。Cassandra用的就是這種方法。
-
原子化的讀-改-寫。應用有時候需要進行 讀-改-寫 序列操作而非單獨的原子寫操作。假如有兩個客戶端讀取了同一版本的資料,修改並且把修改後的資料寫回,按照原子寫模型,時間上比較靠後的那一次更新將會改寫前一次。這種行為在某些情況下是不正確的(例如,兩個客戶端往同一個串列值中新增新值)。資料庫提供了至少兩種解決方法:
-
衝突預防。 讀-改-寫 可以被認為是一種特殊情況下的事務,所以分散式鎖或是 PAXOS [20, 21] 這樣的一致協議都可以解決這種問題。這種技術支援原子讀改寫語意和任意隔離級別的事務。另一種方法是避免分散式的併發寫操作,將對特定資料項的所有寫操作路由到單個節點上(可以是全域性主節點或者分割槽主節點)。為了避免衝突,資料庫必須犧牲網路隔離情況下的可用性。這種方法常用於許多提供強一致性保證的系統(例如大多數關係資料庫,HBase,MongoDB)。
-
衝突檢測。資料庫跟蹤併發更新的衝突,並選擇回滾其中之一或是維持兩個版本交由客戶端解決。併發更新通常用向量時鐘 [19] (這是一種樂觀鎖)來跟蹤,或者維護一個完整的版本歷史。這個方法用於 Riak, Voldemort, CouchDB.
-
寫一致性。分割槽的資料庫經常會發生寫衝突。資料庫應當能處理這種衝突並保證多個寫請求不會被不同的分割槽所處理。這方面資料庫提供了幾種不同的一致性模型:
-
寫後讀一致性。在資料項X上寫操作的效果總是能夠被後續的X上的讀操作看見。
-
讀後讀一致性。在一次對資料項X的讀操作之後,後續對X的讀操作應該傳回與第一次的傳回值相同或是更加新的值。
-
讀寫一致性。從讀寫的觀點來看,資料庫的基本標的是使副本趨同的時間盡可能短(即更新傳遞到所有副本的時間),保證最終一致性。除了這個較弱的保證,還有一些更強的一致性特點:
現在讓我們仔細看看常用的複製技術,並按照描述的特點給他們分一下類。第一幅圖描繪了不同技術之間的邏輯關係和不同技術在系統的一致性、擴充套件性、可用性、延遲性之間的權衡坐標。 第二張圖詳細描繪了每個技術。


複本因子是4。讀寫協調者可以是一個外部客戶端或是一個內部代理節點。
我們會依據一致性從弱到強把所有的技術過一遍:
-
(A, 反熵) 一致性最弱,基於策略如下。寫操作的時候選擇任意一個節點更新,在讀的時候如果新資料還沒有透過後臺的反熵協議傳遞到讀的那個節點,那麼讀到的仍然是舊資料。(下一節會詳細介紹反熵協議)。這種方法的主要特點是:
-
過高的傳播延遲使它在資料同步方面不太好用,所以比較典型的用法是隻作為輔助性的功能來檢測和修複計劃外的不一致。Cassandra就使用了反熵演演算法來在各節點之間傳遞資料庫拓撲和其他一些元資料資訊。
-
一致性保證較弱:即使在沒有發生故障的情況下,也會出現寫衝突與讀寫不一致。
-
在網路隔離下的高可用和健壯性。用非同步的批處理替代了逐個更新,這使得效能表現優異。
-
永續性保障較弱因為新的資料最初只有單個副本。
-
(B) 對上面樣式的一個改進是在任意一個節點收到更新資料請求的同時非同步的傳送更新給所有可用節點。這也被認為是定向的反熵。
-
與純粹的反熵相比,這種做法只用一點小小的效能犧牲就極大地提高了一致性。然而,正式一致性和永續性保持不變。
-
假如某些節點因為網路故障或是節點失效在當時是不可用的,更新最終也會透過反熵傳播過程來傳遞到該節點。
-
(C) 在前一個樣式中,使用提示移交技術 [8] 可以更好地處理某個節點的操作失敗。對於失效節點的預期更新被記錄在額外的代理節點上,並且標明一旦特點節點可用就要將更新傳遞給該節點。這樣做提高了一致性,降低了複製收斂時間。
-
(D, 一次性讀寫)因為提示移交的責任節點也有可能在將更新傳遞出去之前就已經失效,在這種情況下就有必要透過所謂的讀修複來保證一致性。每個讀操作都會啟動一個非同步過程,向儲存這條資料的所有節點請求一份資料摘要(像簽名或者hash),如果發現各節點傳回的摘要不一致則統一各節點上的資料版本。我們用一次性讀寫來命名組合了A、B、C、D的技術- 他們都沒有提供嚴格的一致性保證,但是作為一個自備的方法已經可以用於實踐了。
-
(E, 讀若干寫若干) 上面的策略是降低了複製收斂時間的啟髮式增強。為了保證更強的一致性,必須犧牲可用性來保證一定的讀寫重疊。 通常的做法是同時寫入W個副本而不是一個,讀的時候也要讀R個副本。
-
首先,可以配置寫副本數W>1。
-
其次,因為R+W>N,寫入的節點和讀取的節點之間必然會有重疊,所以讀取的多個資料副本里至少會有一個是比較新的資料(上面的圖中 W=2, R=3, N=4 )。這樣在讀寫請求依序進行的時候(寫執行完再讀)能夠保證一致性(對於單個使用者的讀寫一致性),但是不能保障全域性的讀一致性。用下麵圖示裡的例子來看,R=2,W=2,N=3,因為寫操作對於兩個副本的更新是非事務的,在更新沒有完成的時候讀就可能讀到兩個都是舊值或者一新一舊:
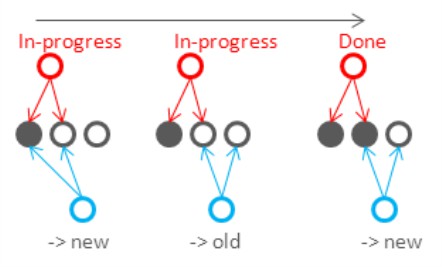
-
對於某種讀延遲的要求,設定R和W的不同值可以調整寫延遲與永續性,反之亦然。
-
如果W<=N/2,併發的多個寫入會寫到不同的若干節點(如,寫操作A寫前N/2個,B寫後N/2個)。 設定 W>N/2 可以保證在符合回滾模型的原子讀改寫時及時檢測到衝突。
-
嚴格來講,這種樣式雖然可以容忍個別節點的失效, 但是對於網路隔離的容錯性並不好。在實踐中,常使用”近似數量透過“這樣的方法,透過犧牲一致性來提高某些情景下的可用性。
-
(F, 讀全部寫若干)讀一致性問題可以透過在讀資料的時候訪問所有副本(讀資料或者檢查摘要)來減輕。這確保了只要有至少一個節點上的資料更新新的資料就能被讀取者看到。但是在網路隔離的情況下這種保證就不能起到作用了。
-
(G, 主從) 這種技術常被用來提供原子寫或者 衝突檢測持久級別的讀改寫。為了實現衝突預防級別,必須要用一種集中管理方式或者是鎖。最簡單的策略是用主從非同步複製。對於特定資料項的寫操作全部被路由到一個中心節點,併在上面順序執行。這種情況下主節點會成為瓶頸,所以必須要將資料劃分成一個個獨立的片區(不同片有不同的master),這樣才能提供擴充套件性。
-
(H, Transactional Read Quorum Write Quorum and Read One Write All) 更新多個副本的方法可以透過使用事務控制技術來避免寫衝突。 眾所周知的方法是使用兩階段提交協議。但兩階段提交並不是完全可靠的,因為協調者失效可能會造成資源阻塞。 PAXOS提交協議 [20, 21] 是更可靠的選擇,但會損失一點效能。 在這個基礎上再向前一小步就是讀一個副本寫所有副本,這種方法把所有副本的更新放在一個事務中,它提供了強容錯一致性但會損失掉一些效能和可用性。
上面分析中的一些權衡有必要再強調一下:
-
一致性與可用性。 嚴密的權衡已經由CAP理論給出了。在網路隔離的情況下,資料庫要麼將資料集中,要麼既要接受資料丟失的風險。
-
一致性與擴充套件性。 看得出即使讀寫一致性保證降低了副本集的擴充套件性,只有在原子寫模型中才可以以一種相對可擴充套件的方式處理寫衝突。原子讀改寫模型透過給資料加上臨時性的全域性鎖來避免衝突。這表明, 資料或操作之間的依賴,即使是很小範圍內或很短時間的,也會損害擴充套件性。所以精心設計資料模型,將資料分片分開存放對於擴充套件性非常重要。
-
一致性與延遲。 如上所述,當資料庫需要提供強一致性或者永續性的時候應該偏向於讀寫所有副本技術。但是很明顯一致性與請求延遲成反比,所以使用若干副本技術會是比較中允的辦法。
-
故障轉移與一致性/擴充套件性/延遲。有趣的是容錯性與一致性、擴充套件性、延遲的取捨衝突並不劇烈。透過合理的放棄一些效能與一致性,叢集可以容忍多達 up to 的節點失效。這種折中在兩階段提交與 PAXOS 協議的區別裡體現得很明顯。這種折中的另一個例子是增加特定的一致性保障,比如使用嚴格會話行程的“讀己所寫”,但這又增加了故障轉移的複雜性 [22]。
反熵協議, 謠言傳播演演算法
讓我們從以下場景開始:
有許多節點,每條資料會在其中的若干的節點上面存有副本。每個節點都可以單獨處理更新請求,每個節點定期和其他節點同步狀態,如此一段時間之後所有的副本都會趨向一致。同步過程是怎樣進行的?同步何時開始?怎樣選擇同步的物件?怎麼交換資料?我們假定兩個節點總是用較新版本的資料改寫舊的資料或者兩個版本都保留以待應用層處理。
這個問題常見於資料一致性維護和叢集狀態同步(如叢集成員資訊傳播)等場景。雖然引入一個監控資料庫並制定同步計劃的協調者可以解決這個問題,但是去中心化的資料庫能夠提供更好的容錯性。去中心化的主要做法是利用精心設計的傳染協議[7],這種協議相對簡單,但是提供了很好的收斂時間,而且能夠容忍任何節點的失效和網路隔離。儘管有許多型別的傳染演演算法,我們只關註反熵協議,因為NoSQL資料庫都在使用它。
反熵協議假定同步會按照一個固定進度表執行,每個節點定期隨機或是按照某種規則選擇另外一個節點交換資料,消除差異。有三種反風格的反熵協議:推,拉和混合。推協議的原理是簡單選取一個隨機節點然後把資料狀態傳送過去。在真實應用中將全部資料都推送出去顯然是愚蠢的,所以節點一般按照下圖所示的方式工作。

節點A作為同步發起者準備好一份資料摘要,裡麵包含了A上資料的指紋。節點B接收到摘要之後將摘要中的資料與本地資料進行比較,並將資料差異做成一份摘要傳回給A。最後,A傳送一個更新給B,B再更新資料。拉方式和混合方式的協議與此類似,就如上圖所示的。
反熵協議提供了足夠好的收斂時間和擴充套件性。下圖展示了一個在100個節點的叢集中傳播一個更新的模擬結果。在每次迭代中,每個節點只與一個隨機選取的對等節點發生聯絡。

可以看到,拉方式的收斂性比推方式更好,這可以從理論上得到證明[7]。而且推方式還存在一個“收斂尾巴”的問題。在多次迭代之後,儘管幾乎遍歷到了所有的節點,但還是有很少的一部分沒受到影響。與單純的推和拉方式相比, 混合方式的效率更高,所以實際應用中通常使用這種方式。反熵是可擴充套件的,因為平均轉換時間以叢集規模的對數函式形式增長。
儘管這些技術看起來很簡單,仍然有許多研究關註於不同約束條件下反熵協議的效能表現。其中之一透過一種更有效的結構使用網路拓撲來取代隨機選取 [10] 。在網路頻寬有限的條件下調整傳輸率或使用先進的規則來選取要同步的資料 [9]。摘要計算也面臨挑戰,資料庫會維護一份最近更新的日誌以有助於摘要計算。
最終一致資料型別Eventually Consistent Data Types
在上一節我們假定兩個節點總是合併他們的資料版本。但要解決更新衝突並不容易,讓所有副本都最終達到一個語意上正確的值出乎意料的難。一個眾所周知的例子是Amazon Dynamo資料庫[8]中已經刪除的條目可以重現。
我們假設一個例子來說明這個問題:資料庫維護一個邏輯上的全域性計數器,每個節點可以增加或者減少計數。雖然每個節點可以在本地維護一個自己的值,但這些本地計數卻不能透過簡單的加減來合併。假設這樣一個例子:有三個節點A、B和C,每個節點執行了一次加操作。如果A從B獲得一個值,並且加到本地副本上,然後C從B獲得值,然後C再從A獲得值,那麼C最後的值是4,而這是錯誤的。解決這個問題的方法是用一個類似於向量時鐘[19]的資料結構為每個節點維護一對計數器[1]:
1 class Counter {
2 int[] plus
3 int[] minus
4 int NODE_ID
5
6 increment() {
7 plus[NODE_ID]++
8 }
9
10 decrement() {
11 minus[NODE_ID]++
12 }
13
14 get() {
15 return sum(plus) – sum(minus)
16 }
17
18 merge(Counter other) {
19 for i in 1..MAX_ID {
20 plus[i] = max(plus[i], other.plus[i])
21 minus[i] = max(minus[i], other.minus[i])
22 }
23 }
24 }Cassandra用類似的方法計數[11]。利用基於狀態的或是基於操作的複製理論也可以設計出更複雜的最終一致的資料結構。例如,[1]中就提及了一系列這樣的資料結構,包括:
-
計數器(加減操作)
-
集合(新增和移除操作)
-
圖(增加邊或頂點,移除邊或頂點)
-
串列(插入某位置或者移除某位置)
最終一致資料型別的功能通常是有限的,還會帶來額外的效能開銷。
資料放置
這部分主要關註控制在分散式資料庫中放置資料的演演算法。這些演演算法負責把資料項對映到合適的物理節點上,在節點間遷移資料以及像記憶體這樣的資源的全域性調配。
均衡資料
我們還是從一個簡單的協議開始,它可以提供叢集節點間無縫的資料遷移。這常發生於像叢集擴容(加入新節點),故障轉移(一些節點宕機)或是均衡資料(資料在節點間的分佈不均衡)這樣的場景。如下圖A中所描繪的場景 – 有三個節點,資料隨便分佈在三個節點上(假設資料都是key-value型)。

如果資料庫不支援資料內部均衡,就要在每個節點上釋出資料庫實體,如上面圖B所示。這需要手動進行叢集擴充套件,停掉要遷移的資料庫實體,把它轉移到新節點上,再在新節點上啟動,如圖C所示。儘管資料庫能夠監控到每一條記錄,包括MongoDB, Oracle Coherence, 和還在開發中的 Redis Cluster 在內的許多系統仍然使用的是自動均衡技術。也即,將資料分片並把每個資料分片作為遷移的最小單位,這是基於效率的考慮。很明顯分片數會比節點數多,資料分片可以在各節點間平均分佈。按照一種簡單的協議即可實現無縫資料遷移,這個協議可以在遷移資料分片的時候重定向客戶的資料遷出節點和遷入節點。下圖描繪了一個Redis Cluster中實現的get(key)邏輯的狀態機。
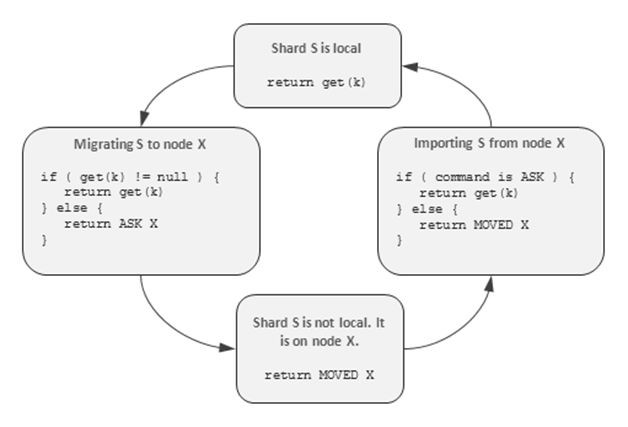
假定每個節點都知道叢集拓撲,能夠把任意key對映到相應的資料分片,把資料分片對映到節點。如果節點判斷被請求的key屬於本地分片,就會在本地查詢(上圖中上面的方框)。假如節點判斷請求的key屬於另一個節點X,他會傳送一個永久重定向命令給客戶端(上圖中下方的方框)。永久重定向意味著客戶端可以快取分片和節點間的對映關係。如果分片遷移正在進行,遷出節點和遷入節點會標記相應的分片並且將分片的資料加鎖逐條加鎖然後開始移動。遷出節點首先會在本地查詢key,如果沒有找到,重定向客戶端到遷入節點,假如key已經遷移完畢的話。這種重定向是一次性的,並且不能被快取。遷入節點在本地處理重定向,但定期查詢在遷移還沒完成前被永久重定向。
動態環境中的資料分片和複製
我們關註的另一個問題是怎麼把記錄對映到物理節點。比較直接的方法是用一張表來記錄每個範圍的key與節點的對映關係,一個範圍的key對應到一個節點,或者用key的hash值與節點數取模得到的值作為節點ID。但是hash取模的方法在叢集發生更改的情況下就不是很好用,因為增加或者減少節點都會引起叢集內的資料徹底重排。導致很難進行複製和故障恢復。
有許多方法在複製和故障恢復的角度進行了增強。最著名的就是一致性hash。網上已經有很多關於一致性hash的介紹了,所以在這裡我只提供一個基本介紹,僅僅為了文章內容的完整性。下圖描繪了一致性hash的基本原理:

一致性hash從根本上來講是一個鍵值對映結構 – 它把鍵(通常是hash過的)對映到物理節點。鍵經過hash之後的取值空間是一個有序的定長二進位制字串,很顯然每個在此範圍內的鍵都會被對映到圖A中A、B、C三個節點中的某一個。為了副本複製,將取值空間閉合成一個環,沿環順時針前行直到所有副本都被對映到合適的節點上,如圖B所示。換句話說,Y將被定位在節點B上,因為它在B的範圍內,第一個副本應該放置在C,第二個副本放置在A,以此類推。
這種結構的好處體現在增加或減少一個節點的時候,因為它只會引起臨接區域的資料重新均衡。如圖C所示,節點D的加入只會對資料項X產生影響而對Y無影響。同樣,移除節點B(或者B失效)只會影響Y和X的副本,而不會對X自身造成影響。但是,正如參考資料[8]中所提到的,這種做法在帶來好處的同時也有弱點,那就是重新均衡的負擔都由鄰節點承受了,它們將移動大量的資料。透過將每個節點對映到多個範圍而不是一個範圍可以一定程度上減輕這個問題帶來的不利影響,如圖D所示。這是一個折中,它避免了重新均衡資料時負載過於集中,但是與基於模組的對映相比,保持了總均衡數量適當降低。
給大規模的叢集維護一個完整連貫的hash環很不容易。對於相對小一點的資料庫叢集就不會有問題,研究如何在對等網路中將資料放置與網路路由結合起來很有意思。一個比較好的例子是Chord演演算法,它使環的完整性讓步於單個節點的查詢效率。Chord演演算法也使用了環對映鍵到節點的理念,在這方面和一致性hash很相似。不同的是,一個特定節點維護一個短串列,串列中的節點在環上的邏輯位置是指數增長的(如下圖)。這使得可以使用二分搜尋只需要幾次網路跳躍就可以定位一個鍵。

這張圖畫的是一個由16個節點組成的叢集,描繪了節點A是如何查詢放在節點D上的key的。 (A) 描繪了路由,(B) 描繪了環針對節點A、B、C的區域性影象。在參考資料[15]中有更多關於分散式系統中的資料複製的內容。
按照多個屬性的資料分片
當只需要透過主鍵來訪問資料的時候,一致性hash的資料放置策略很有效,但是當需要按照多個屬性來查詢的時候事情就會複雜得多。一種簡單的做法(MongoDB使用的)是用主鍵來分佈資料而不考慮其他屬性。這樣做的結果是依據主鍵的查詢可以被路由到接個合適的節點上,但是對其他查詢的處理就要遍歷叢集的所有節點。查詢效率的不均衡造成下麵的問題:
有一個資料集,其中的每條資料都有若干屬性和相應的值。是否有一種資料分佈策略能夠使得限定了任意多個屬性的查詢會被交予儘量少的幾個節點執行?
HyperDex資料庫提供了一種解決方案。基本思想是把每個屬性視作多維空間中的一個軸,將空間中的區域對映到物理節點上。一次查詢會被對應到一個由空間中多個相鄰區域組成的超平面,所以只有這些區域與該查詢有關。讓我們看看參考資料[6]中的一個例子:
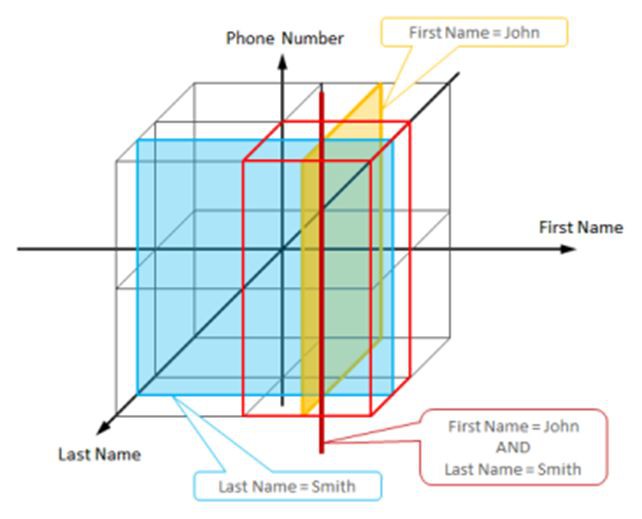
每一條資料都是一條使用者資訊,有三個屬性First Name 、Last Name 和Phone Number。這些屬性被視作一個三維空間,可行的資料分佈策略是將每個象限對映到一個物理節點。像“First Name = John”這樣的查詢對應到一個貫穿4個象限的平面,也即只有4個節點會參與處理此次查詢。有兩個屬性限制的查詢對應於一條貫穿兩個象限的直線,如上圖所示,因此只有2個節點會參與處理。
這個方法的問題是空間象限會呈屬性數的指數函式增長。結果就會是,只有幾個屬性限制的查詢會投射到許多個空間區域,也即許多臺伺服器。將一個屬性較多的資料項拆分成幾個屬性相對較少的子項,並將每個子項都對映到一個獨立的子空間,而不是將整條資料對映到一個多維空間,這樣可以一定程度上緩解這個問題:
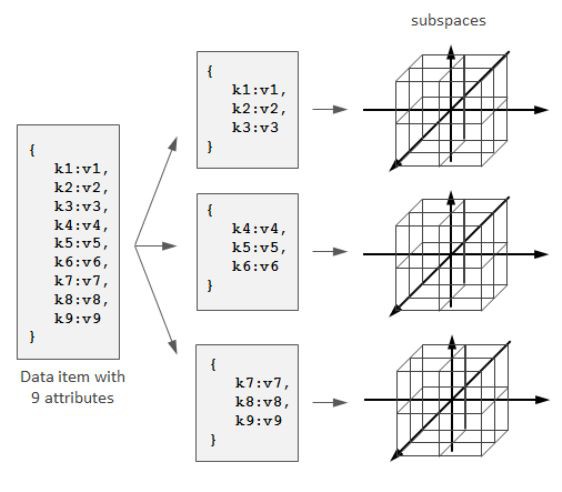
這樣能夠提供更好的查詢到節點的對映,但是增加了叢集協調的複雜度,因為這種情況下一條資料會散佈在多個獨立的子空間,而每個子空間都對應各自的若干個物理節點,資料更新時就必須考慮事務問題。參考資料 [6]有這種技術的更多介紹和實現細節。
鈍化副本
有的應用有很強的隨機讀取要求,這就需要把所有資料放在記憶體裡。在這種情況下,將資料分片並把每個分片主從複製通常需要兩倍以上的記憶體,因為每個資料都要在主節點和從節點上各有一份。為了在主節點失效的時候起到代替作用,從節點上的記憶體大小應該和主節點一樣。如果系統能夠容忍節點失效的時候出現短暫中斷或效能下降,也可以不要分片。
下麵的圖描繪了4個節點上的16個分片,每個分片都有一份在記憶體裡,副本存在硬碟上:

灰色箭頭突出了節點2上的分片複製。其他節點上的分片也是同樣複製的。紅色箭頭描繪了在節點2失效的情況下副本怎樣載入進記憶體。叢集內副本的均勻分佈使得只需要預留很少的記憶體就可以存放節點失效情況下啟用的副本。在上面的圖裡,叢集只預留了1/3的記憶體就可以承受單個節點的失效。特別要指出的是副本的啟用(從硬碟載入入記憶體)會花費一些時間,這會造成短時間的效能下降或者正在恢復中的那部分資料服務中斷。
系統協調
在這部分我們將討論與系統協調相關的兩種技術。分散式協調是一個比較大的領域,數十年以來有很多人對此進行了深入的研究。這篇文章裡只涉及兩種已經投入實用的技術。關於分散式鎖,consensus協議以及其他一些基礎技術的內容可以在很多書或者網路資源中找到,也可以去看參考資料[17, 18, 21]。
故障檢測
故障檢測是任何一個擁有容錯性的分散式系統的基本功能。實際上所有的故障檢測協議都基於心跳通訊機制,原理很簡單,被監控的元件定期傳送心跳資訊給監控行程(或者由監控行程輪詢被監控元件),如果有一段時間沒有收到心跳資訊就被認為失效了。除此之外,真正的分散式系統還要有另外一些功能要求:
-
自適應。故障檢測應該能夠應對暫時的網路故障和延遲,以及叢集拓撲、負載和頻寬的變化。但這有很大難度,因為沒有辦法去分辨一個長時間沒有響應的行程到底是不是真的失效了,因此,故障檢測需要權衡故障識別時間(花多長時間才能識別一個真正的故障,也即一個行程失去響應多久之後會被認為是失效)和虛假警報率之間的輕重。這個權衡因子應該能夠動態自動調整。
-
靈活性。乍看上去,故障檢測只需要輸出一個表明被監控行程是否處於工作狀態的布林值,但在實際應用中這是不夠的。我們來看參考資料[12]中的一個類似MapReduce的例子。有一個由一個主節點和若干工作節點組成的分散式應用,主節點維護一個作業串列,並將串列中的作業分配給工作節點。主節點能夠區分不同程度的失敗。如果主節點懷疑某個工作節點掛了,他就不會再給這個節點分配作業。其次,隨著時間推移,如果沒有收到該節點的心跳資訊,主節點就會把執行在這個節點上的作業重新分配給別的節點。最後,主節點確認這個節點已經失效,並釋放所有相關資源。
-
可擴充套件性和健壯性。失敗檢測作為一個系統功能應該能夠隨著系統的擴大而擴充套件。他應該是健壯和一致的,也即,即使在發生通訊故障的情況下,系統中的所有節點都應該有一個一致的看法(即所有節點都應該知道哪些節點是不可用的,那些節點是可用的,各節點對此的認知不能發生衝突,不能出現一部分節點知道某節點A不可用,而另一部分節點不知道的情況)
所謂的累計失效檢測器[12]可以解決前兩個問題,Cassandra[16]對它進行了一些修改並應用在產品中。其基本工作流程如下:
-
對於每一個被監控資源,檢測器記錄心跳資訊到達時間Ti。
-
計算在統計預測範圍內的到達時間的均值和方差。
-
假定到達時間的分佈已知(下圖包括一個正態分佈的公式),我們可以計算心跳延遲(當前時間t_now和上一次到達時間Tc之間的差值) 的機率,用這個機率來判斷是否發生故障。如參考資料[12]中所建議的,可以使用對數函式來調整它以提高可用性。在這種情況下,輸出1意味著判斷錯誤(認為節點失效)的機率是10%,2意味著1%,以此類推。

根據重要程度不同來分層次組織監控區,各區域之間透過謠言傳播協議或者中央容錯庫同步,這樣可以滿足擴充套件性的要求,又可以防止心跳資訊在網路中泛濫[14]。如下圖所示(6個故障檢測器組成了兩個區域,互相之間透過謠言傳播協議或者像ZooKeeper這樣的健壯性庫來聯絡):

協調者競選
協調者競選是用於強一致性資料庫的一個重要技術。首先,它可以組織主從結構的系統中主節點的故障恢復。其次,在網路隔離的情況下,它可以斷開處於少數的那部分節點,以避免寫衝突。
Bully 演演算法是一種相對簡單的協調者競選演演算法。MongoDB 用了這個演演算法來決定副本集中主要的那一個。Bully 演演算法的主要思想是叢集的每個成員都可以宣告它是協調者並通知其他節點。別的節點可以選擇接受這個聲稱或是拒絕併進入協調者競爭。被其他所有節點接受的節點才能成為協調者。節點按照一些屬性來判斷誰應該勝出。這個屬性可以是一個靜態ID,也可以是更新的度量像最近一次事務ID(最新的節點會勝出)。
下圖的例子展示了bully演演算法的執行過程。使用靜態ID作為度量,ID值更大的節點會勝出:
1、最初叢集有5個節點,節點5是一個公認的協調者。
2、假設節點5掛了,並且節點2和節點3同時發現了這一情況。兩個節點開始競選併傳送競選訊息給ID更大的節點。
3、、節點4淘汰了節點2和3,節點3淘汰了節點2。
4、這時候節點1察覺了節點5失效並向所有ID更大的節點發送了競選資訊。
5、節點2、3和4都淘汰了節點1。
6、節點4傳送競選資訊給節點5。
7、節點5沒有響應,所以節點4宣佈自己當選並向其他節點通告了這一訊息。

協調者競選過程會統計參與的節點數目並確保叢集中至少一半的節點參與了競選。這確保了在網路隔離的情況下只有一部分節點能選出協調者(假設網路中網路會被分割成多塊區域,之間互不聯通,協調者競選的結果必然會在節點數相對比較多的那個區域中選出協調者,當然前提是那個區域中的可用節點多於叢集原有節點數的半數。如果叢集被隔離成幾個區塊,而沒有一個區塊的節點數多於原有節點總數的一半,那就無法選舉出協調者,當然這樣的情況下也別指望叢集能夠繼續提供服務了)。
參考資料
1、M. Shapiro et al. A Comprehensive Study of Convergent and Commutative Replicated Data Types
2、I. Stoica et al. Chord: A Scalable Peer-to-peer Lookup Service for Internet Applications
3、R. J. Honicky, E.L.Miller. Replication Under Scalable Hashing: A Family of Algorithms for Scalable Decentralized Data Distribution
4、G. Shah. Distributed Data Structures for Peer-to-Peer Systems
5、A. Montresor, Gossip Protocols for Large-Scale Distributed Systems
6、R. Escriva, B. Wong, E.G. Sirer. HyperDex: A Distributed, Searchable Key-Value Store
7、A. Demers et al. Epidemic Algorithms for Replicated Database Maintenance
8、G. DeCandia, et al. Dynamo: Amazon’s Highly Available Key-value Store
9、R. van Resesse et al. Efficient Reconciliation and Flow Control for Anti-Entropy Protocols
10、S. Ranganathan et al. Gossip-Style Failure Detection and Distributed Consensus for Scalable Heterogeneous Clusters
11、http://www.slideshare.net/kakugawa/distributed-counters-in-cassandra-cassandra-summit-2010
12、N. Hayashibara, X. Defago, R. Yared, T. Katayama. The Phi Accrual Failure Detector
13、M.J. Fischer, N.A. Lynch, and M.S. Paterson. Impossibility of Distributed Consensus with One Faulty Process
14、N. Hayashibara, A. Cherif, T. Katayama. Failure Detectors for Large-Scale Distributed Systems
15、M. Leslie, J. Davies, and T. Huffman. A Comparison Of Replication Strategies for Reliable Decentralised Storage
16、A. Lakshman, P.Malik. Cassandra – A Decentralized Structured Storage System
17、N. A. Lynch. Distributed Algorithms
18、G. Tel. Introduction to Distributed Algorithms
19、http://basho.com/blog/technical/2010/04/05/why-vector-clocks-are-hard/
20、L. Lamport. Paxos Made Simple
21、J. Chase. Distributed Systems, Failures, and Consensus
22、W. Vogels. Eventualy Consistent – Revisited
23、J. C. Corbett et al. Spanner: Google’s Globally-Distributed Database
【關於投稿】
如果大家有原創好文投稿,請直接給公號傳送留言。
① 留言格式:
【投稿】+《 文章標題》+ 文章連結
② 示例:
【投稿】《不要自稱是程式員,我十多年的 IT 職場總結》:http://blog.jobbole.com/94148/
③ 最後請附上您的個人簡介哈~
看完本文有收穫?請轉發分享給更多人
關註「資料分析與開發」,提升資料技能

