
來源:Linux學習
ID:LoveLinux1024
以往的人臉識別主要是包括人臉影象採集、人臉識別預處理、身份確認、身份查詢等技術和系統。現在人臉識別已經慢慢延伸到了ADAS中的駕駛員檢測、行人跟蹤、甚至到了動態物體的跟蹤。由此可以看出,人臉識別系統已經由簡單的影象處理髮展到了影片實時處理。而且演演算法已經由以前的Adaboots、PCA等傳統的統計學方法轉變為CNN、RCNN等深度學習及其變形的方法。現在也有相當一部分人開始研究3維人臉識別識別,這種專案目前也受到了學術界、工業界和國家的支援。
首先看看現在的研究現狀。如上的發展趨勢可以知道,現在的主要研究方向是利用深度學習的方法解決影片人臉識別。
主要的研究人員:
如下:中科院計算所的山世光教授、中科院生物識別研究所的李子青教授、清華大學的蘇光大教授、香港中文大學的湯曉鷗教授、Ross B. Girshick等等。
主要開源專案:
-
SeetaFace人臉識別引擎。該引擎由中科院計算所山世光研究員帶領的人臉識別研究組研發。程式碼基於C++實現,且不依賴於任何第三方的庫函式,開源協議為BSD-2,可供學術界和工業界免費使用。github連結:
https://github.com/seetaface/SeetaFaceEngine
主要軟體API/SDK:
-
face++。Face++.com 是一個提供免費人臉檢測、人臉識別、人臉屬性分析等服務的雲端服務平臺。Face++是北京曠視科技有限公司旗下的全新人臉技術雲平臺,在黑馬大賽中,Face++獲得年度總冠軍,已獲得聯想之星投資。
-
skybiometry.。主要包含了face detection、face recognition、face grouping。
主要的人臉識別影象庫:
目前公開的比較好的人臉影象庫有LFW(Labelled Faces in the Wild)和YFW(Youtube Faces in the Wild)。現在的實驗資料集基本上是來源於LFW,而且目前的影象人臉識別的精度已經達到99%,基本上現有的影象資料庫已經被刷爆。下麵是現有人臉影象資料庫的總結:

現在在中國做人臉識別的公司已經越來越多,應用也非常的廣泛。其中市場佔有率最高的是漢王科技。主要公司的研究方向和現狀如下:
-
漢王科技:漢王科技主要是做人臉識別的身份驗證,主要用在門禁系統、考勤系統等等。
-
科大訊飛:科大訊飛在香港中文大學湯曉鷗教授團隊支援下,開發出了一個基於高斯過程的人臉識別技術–Gussian face, 該技術在LFW上的識別率為98.52%,目前該公司的DEEPID2在LFW上的識別率已經達到了99.4%。
-
川大智勝:目前該公司的研究亮點是三維人臉識別,並拓展到3維全臉照相機產業化等等。
-
商湯科技:主要是一家致力於引領人工智慧核心“深度學習”技術突破,構建人工智慧、大資料分析行業解決方案的公司,目前在人臉識別、文字識別、人體識別、車輛識別、物體識別、影象處理等方向有很強的競爭力。在人臉識別中有106個人臉關鍵點的識別。
人臉識別的過程
人臉識別主要分為四大塊:人臉定位(face detection)、 人臉校準(face alignment)、 人臉確認(face verification)、人臉鑒別(face identification)。
人臉定位(face detection):
對影象中的人臉進行檢測,並將結果用矩形框框出來。在openCV中有直接能拿出來用的Harr分類器。
人臉校準(face alignment):
對檢測到的人臉進行姿態的校正,使其人臉盡可能的”正”,透過校正可以提高人臉識別的精度。校正的方法有2D校正、3D校正的方法,3D校正的方法可以使側臉得到較好的識別。 在進行人臉校正的時候,會有檢測特徵點的位置這一步,這些特徵點位置主要是諸如鼻子左側,鼻孔下側,瞳孔位置,上嘴唇下側等等位置,知道了這些特徵點的位置後,做一下位置驅動的變形,臉即可被校”正”了。如下圖所示:

這裡介紹一種MSRA在14年的技術:Joint Cascade Face Detection and Alignment(ECCV14)。這篇文章直接在30ms的時間裡把detection和alignment都給做了。
人臉確認(face verification):
Face verification,人臉校驗是基於pair matching的方式,所以它得到的答案是“是”或者“不是”。在具體操作的時候,給定一張測試圖片,然後挨個進行pair matching,matching上了則說明測試影象與該張匹配上的人臉為同一個人的人臉。一般在小型辦公室人臉刷臉打卡系統中採用的(應該)是這種方法,具體操作方法大致是這樣一個流程:離線逐個錄入員工的人臉照片(一個員工錄入的人臉一般不止一張),員工在刷臉打卡的時候相機捕獲到影象後,透過前面所講的先進行人臉檢測,然後進行人臉校正,再進行人臉校驗,一旦match結果為“是”,說明該名刷臉的人員是屬於本辦公室的,人臉校驗到這一步就完成了。在離線錄入員工人臉的時候,我們可以將人臉與人名對應,這樣一旦在人臉校驗成功後,就可以知道這個人是誰了。上面所說的這樣一種系統優點是開發費用低廉,適合小型辦公場所,缺點是在捕獲時不能有遮擋,而且還要求人臉姿態比較正(這種系統我們所有,不過沒體驗過)。下圖給出了示意說明:

人臉識別(face identification/recognition):
Face identification或Face recognition,人臉識別正如下圖所示的,它要回答的是“我是誰?”,相比於人臉校驗採用的pair matching,它在識別階段更多的是採用分類的手段。它實際上是對進行了前面兩步即人臉檢測、人臉校正後做的影象(人臉)分類。

根據上面四個概念的介紹,我們可以瞭解到人臉識別主要包括三個大的、獨立性強的模組:

我們將上面的步驟進行詳細的拆分,得到下麵的過程圖: 
人臉識別分類
現在隨著人臉識別技術的發展,人臉識別技術主要分為了三類:一是基於影象的識別方法、二是基於影片的識別方法、三是三維人臉識別方法。
基於影象的識別方法:
這個過程是一個靜態的影象識別過程,主要利用影象處理。主要的演演算法有PCA、EP、kernel method、 Bayesian Framwork、SVM 、HMM、Adaboot等等演演算法。但在2014年,人臉識別利用Deep learning 技術取得了重大突破,為代表的有deepface的97.25%、face++的97.27%,但是deep face的訓練集是400w集的,而同時香港中文大學湯曉鷗的Gussian face的訓練集為2w。
基於影片的實時識別方法:
這個過程可以看出人臉識別的追蹤過程,不僅僅要求在影片中找到人臉的位置和大小,還需要確定幀間不同人臉的對應關係。
DeepFace
參考論文(資料):
1. DeepFace論文。DeepFace:Closing the Gap to Human-level Performance in Face Verificaion
2. 摺積神經網路瞭解部落格。http://blog.csdn.net/zouxy09/article/details/8781543
3. 摺積神經網路的推導部落格。http://blog.csdn.net/zouxy09/article/details/9993371/
4. Note on convolution Neural Network.
5. Neural Network for Recognition of Handwritten Digits
6. DeepFace博文:http://blog.csdn.net/Hao_Zhang_Vision/article/details/52831399?locationNum=2&fps;=1
DeepFace是FaceBook提出來的,後續有DeepID和FaceNet出現。而且在DeepID和FaceNet中都能體現DeepFace的身影,所以DeepFace可以謂之CNN在人臉識別的奠基之作,目前深度學習在人臉識別中也取得了非常好的效果。所以這裡我們先從DeepFace開始學習。
在DeepFace的學習過程中,不僅將DeepFace所用的方法進行介紹,也會介紹當前該步驟的其它主要演演算法,對現有的影象人臉識別技術做一個簡單、全面的敘述。
1.DeepFace的基本框架
1.1 人臉識別的基本流程
face detection -> face alignment -> face verification -> face identification
1.2 人臉檢測(face detection)
1.2.1 現有技術:
haar分類器:
人臉檢測(detection)在opencv中早就有直接能拿來用的haar分類器,基於Viola-Jones演演算法。
Adaboost演演算法(級聯分類器):
1.參考論文: Robust Real-Time face detection 。
2. 參考中文部落格:http://blog.csdn.net/cyh_24/article/details/39755661
3. 部落格:http://blog.sina.com.cn/s/blog_7769660f01019ep0.html
1.2.2 文章中所用方法
本文中採用了基於檢測點的人臉檢測方法(fiducial Point Detector)。
-
先選擇6個基準點,2隻眼睛中心、 1個鼻子點、3個嘴上的點。
-
透過LBP特徵用SVR來學習得到基準點。
效果如下: 
1.3 人臉校準(face alignment)
2D alignment:
-
對Detection後的圖片進行二維裁剪, scale, rotate and translate the image into six anchor locations。 將人臉部分裁剪出來。
3D alignment:
-
找到一個3D 模型,用這個3D模型把二維人臉crop成3D人臉。67個基點,然後Delaunay三角化,在輪廓處新增三角形來避免不連續。
-
將三角化後的人臉轉換成3D形狀
-
三角化後的人臉變為有深度的3D三角網
-
將三角網做偏轉,使人臉的正面朝前
-
最後放正的人臉
效果如下:

上面的2D alignment對應(b)圖,3D alignment依次對應(c) ~ (h)。
1.4 人臉表示(face verification)
1.4.1 現有技術
LBP && joint Beyesian:
透過高維LBP跟Joint Bayesian這兩個方法結合。
-
論文: Bayesian Face Revisited: A Joint Formulation
DeepID系列:
將七個聯合貝葉斯模型使用SVM進行融合,精度達到99.15%
-
論文: Deep Learning Face Representation by Joint Identification-Verification
1.4.2 文章中的方法

論文中透過一個多類人臉識別任務來訓練深度神經網路(DNN)。網路結構如上圖所示。
結構引數:
經過3D對齊以後,形成的影象都是152×152的影象,輸入到上述網路結構中,該結構的引數如下:
-
Conv:32個11×11×3的摺積核
-
max-pooling: 3×3, stride=2
-
Conv: 16個9×9的摺積核
-
Local-Conv: 16個9×9的摺積核,Local的意思是摺積核的引數不共享
-
Local-Conv: 16個7×7的摺積核,引數不共享
-
Local-Conv: 16個5×5的摺積核,引數不共享
-
Fully-connected: 4096維
-
Softmax: 4030維
提取低水平特徵:
過程如下所示:
-
預處理階段:輸入3通道的人臉,併進行3D校正,再歸一化到152*152畫素大小——152*152*3.
-
透過摺積層C1:C1包含32個11*11*3的濾波器(即摺積核),得到32張特徵圖——32*142*142*3。
-
透過max-polling層M2:M2的滑窗大小為3*3,滑動步長為2,3個通道上分別獨立polling。
-
透過另一個摺積層C3:C3包含16個9*9*16的3維摺積核。
上述3層網路是為了提取到低水平的特徵,如簡單的邊緣特徵和紋理特徵。Max-polling層使得摺積網路對區域性的變換更加魯棒。如果輸入是校正後的人臉,就能使網路對小的標記誤差更加魯棒。然而這樣的polling層會使網路在面部的細節結構和微小紋理的精準位置上丟失一些資訊。因此,文中只在第一個摺積層後面接了Max-polling層。這些前面的層稱之為前端自適應的預處理層級。然而對於許多計算來講,這是很必要的,這些層的引數其實很少。它們僅僅是把輸入影象擴充成一個簡單的區域性特徵集。
後續層:
L4,L5,L6都是區域性連線層,就像摺積層使用濾波器一樣,在特徵影象的每一個位置都訓練學習一組不同的濾波器。由於校正後不同區域的有不同的統計特性,摺積網路在空間上的穩定性的假設不能成立。比如說,相比於鼻子和嘴巴之間的區域,眼睛和眉毛之間的區域展現出非常不同的表觀並且有很高的區分度。換句話說,透過利用輸入的校正後的影象,定製了DNN的結構。
使用區域性連線層並沒有影響特徵提取時的運算負擔,但是影響了訓練的引數數量。僅僅是由於有如此大的標記人臉庫,我們可以承受三個大型的區域性連線層。區域性連線層的輸出單元受到一個大型的輸入圖塊的影響,可以據此調整區域性連線層的使用(引數)(不共享權重)
比如說,L6層的輸出受到一個74*74*3的輸入圖塊的影響,在校正後的人臉中,這種大的圖塊之間很難有任何統計上的引數共享。
頂層:
最後,網路頂端的兩層(F7,F8)是全連線的:每一個輸出單元都連線到所有的輸入。這兩層可以捕捉到人臉影象中距離較遠的區域的特徵之間的關聯性。比如,眼睛的位置和形狀,與嘴巴的位置和形狀之間的關聯性(這部分也含有資訊)可以由這兩層得到。第一個全連線層F7的輸出就是我們原始的人臉特徵表達向量。
在特徵表達方面,這個特徵向量與傳統的基於LBP的特徵描述有很大區別。傳統方法通常使用區域性的特徵描述(計算直方圖)並用作分類器的輸入。
最後一個全連線層F8的輸出進入了一個K-way的softmax(K是類別個數),即可產生類別標號的機率分佈。用Ok表示一個輸入影象經過網路後的第k個輸出,即可用下式表達輸出類標號k的機率:
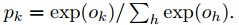
訓練的標的是最大化正確輸出類別(face 的id)的機率。透過最小化每個訓練樣本的叉熵損失實現這一點。用k表示給定輸入的正確類別的標號,則叉熵損失是:

透過計算叉熵損失L對引數的梯度以及使用隨機梯度遞減的方法來最小化叉熵損失。
梯度是透過誤差的標準反向傳播來計算的。非常有趣的是,本網路產生的特徵非常稀疏。超過75%的頂層特徵元素是0。這主要是由於使用了ReLU啟用函式導致的。這種軟閾值非線性函式在所有的摺積層,區域性連線層和全連線層(除了最後一層F8)都使用了,從而導致整體級聯之後產生高度非線性和稀疏的特徵。稀疏性也與使用使用dropout正則化有關,即在訓練中將隨機的特徵元素設定為0。我們只在F7全連線層使用了dropout.由於訓練集合很大,在訓練過程中我們沒有發現重大的過擬合。
給出影象I,則其特徵表達G(I)透過前饋網路計算出來,每一個L層的前饋網路,可以看作是一系列函式:

歸一化:
在最後一級,我們把特徵的元素歸一化成0到1,以此降低特徵對光照變化的敏感度。特徵向量中的每一個元素都被訓練集中對應的最大值除。然後進行L2歸一化。由於我們採用了ReLU啟用函式,我們的系統對影象的尺度不變性減弱。
對於輸出的4096-d向量:
-
先每一維進行歸一化,即對於結果向量中的每一維,都要除以該維度在整個訓練集上的最大值。
-
每個向量進行L2歸一化。
2. 驗證
2.1 卡方距離
該系統中,歸一化後的DeepFace特徵向量與傳統的基於直方圖的特徵(如LBP)有一下相同之處:
-
所有值均為負
-
非常稀疏
-
特徵元素的值都在區間 [0, 1]之間
卡方距離計算公式如下:

2.2 Siamese network
文章中也提到了端到端的度量學習方法,一旦學習(訓練)完成,人臉識別網路(截止到F7)在輸入的兩張圖片上重覆使用,將得到的2個特徵向量直接用來預測判斷這兩個輸入圖片是否屬於同一個人。這分為以下步驟:
a. 計算兩個特徵之間的絕對差別;
b,一個全連線層,對映到一個單個的邏輯單元(輸出相同/不同)。
3. 實驗評估
3.1 資料集
-
Social Face Classification Dataset(SFC): 4.4M張人臉/4030人
-
LFW: 13323張人臉/5749人
-
restricted: 只有是/不是的標記
-
unrestricted:其他的訓練對也可以拿到
-
unsupervised:不在LFW上訓練
-
Youtube Face(YTF): 3425videos/1595人
result on LFW:

result on YTF:
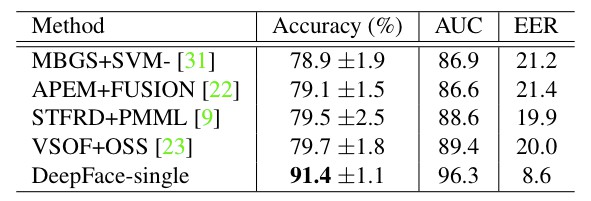
DeepFace與之後的方法的最大的不同點在於,DeepFace在訓練神經網路前,使用了對齊方法。論文認為神經網路能夠work的原因在於一旦人臉經過對齊後,人臉區域的特徵就固定在某些畫素上了,此時,可以用摺積神經網路來學習特徵。
本文的模型使用了C++工具箱dlib基於深度學習的最新人臉識別方法,基於戶外臉部資料測試庫Labeled Faces in the Wild 的基準水平來說,達到了99.38%的準確率。
更多演演算法
http://www.gycc.com/trends/face%20recognition/overview/
dlib:http://dlib.net/
資料測試庫Labeled Faces in the Wild:http://vis-www.cs.umass.edu/lfw/
模型提供了一個簡單的 face_recognition 命令列工具讓使用者透過命令就能直接使用圖片檔案夾進行人臉識別操作。
在圖片中捕捉人臉特徵
在一張圖片中捕捉到所有的人臉

找到並處理圖片中人臉的特徵
找到每個人眼睛、鼻子、嘴巴和下巴的位置和輪廓。
import face_recognition
image = face_recognition.load_image_file(“your_file.jpg”)
face_locations = face_recognition.face_locations(image)

捕捉臉部特徵有很重要的用途,當然也可以用來進行圖片的數字美顏digital make-up(例如美圖秀秀)
digital make-up:https://github.com/ageitgey/face_recognition/blob/master/examples/digital_makeup.py
識別圖片中的人臉
識別誰出現在照片裡


安裝步驟
本方法支援Python3/python2,我們只在macOS和Linux中測試過,還不知是否適用於Windows。
使用pypi的pip3 安裝此模組(或是Python 2的pip2)
重要提示:在編譯dlib時可能會出問題,你可以透過安裝來自源(而不是pip)的dlib來修複錯誤,請見安裝手冊How to install dlib from source
https://gist.github.com/ageitgey/629d75c1baac34dfa5ca2a1928a7aeaf
透過手動安裝dlib,執行pip3 install face_recognition來完成安裝。
使用方法命令列介面
當你安裝face_recognition,你能得到一個簡潔的叫做face_recognition的命令列程式,它能幫你識別一張照片或是一個照片檔案夾中的所有人臉。
首先,你需要提供一個包含一張照片的檔案夾,並且你已經知道照片中的人是誰,每個人都要有一張照片檔案,且檔案名需要以該人的姓名命名;

然後你需要準備另外一個檔案夾,裡面裝有你想要識別人臉照片;
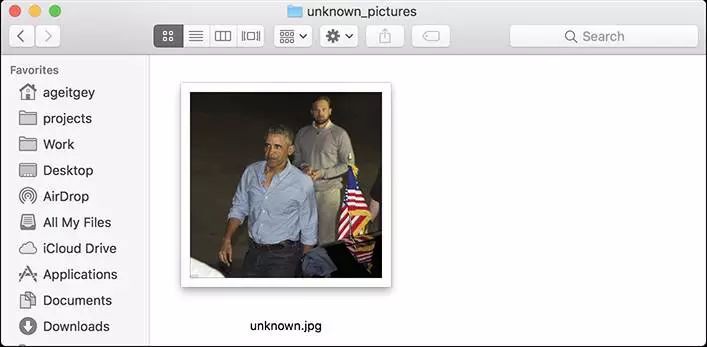
接下來你只用執行face_recognition命令,程式能夠透過已知人臉的檔案夾識別出未知人臉照片中的人是誰;

針對每個人臉都要一行輸出,資料是檔案名加上識別到的人名,以逗號分隔。
如果你只是想要知道每個照片中的人名而不要檔案名,可以進行如下操作:

Python模組
你可以透過引入face_recognition就能完成人臉識別操作:
API 檔案: https://face-recognition.readthedocs.io.
在圖片中自動識別所有人臉
請參照此案例this example: https://github.com/ageitgey/face_recognition/blob/master/examples/find_faces_in_picture.py
識別圖片中的人臉並告知姓名
請參照此案例this example: https://github.com/ageitgey/face_recognition/blob/master/examples/recognize_faces_in_pictures.py
Python程式碼案例
所有例子在此 here.
https://github.com/ageitgey/face_recognition/tree/master/examples
·找到照片中的人臉Find faces in a photograph
https://github.com/ageitgey/face_recognition/blob/master/examples/find_faces_in_picture.py
· 識別照片中的面部特徵Identify specific facial features in a photograph
https://github.com/ageitgey/face_recognition/blob/master/examples/find_facial_features_in_picture.py
· 使用數字美顏Apply (horribly ugly) digital make-up
https://github.com/ageitgey/face_recognition/blob/master/examples/digital_makeup.py
·基於已知人名找到並識別出照片中的未知人臉Find and recognize unknown faces in a photograph based on photographs of known people
https://github.com/ageitgey/face_recognition/blob/master/examples/recognize_faces_in_pictures.py
人臉識別方法的原理
如果你想學習此方法的人臉定位和識別原理,請參見read my article。
https://medium.com/@ageitgey/machine-learning-is-fun-part-4-modern-face-recognition-with-deep-learning-c3cffc121d78
註意事項
本人臉識別模型僅限用於成人,對於兒童來說效果不佳,模型可能會由於使用預設的對比閾值(0.6)而無法清楚識別出兒童的臉。
github原始碼:https://github.com/ageitgey/face_recognition#face-recognition
《Linux雲端計算及運維架構師高薪實戰班》2018年08月27日即將開課中,120天衝擊Linux運維年薪30萬,改變速約~~~~
*宣告:推送內容及圖片來源於網路,部分內容會有所改動,版權歸原作者所有,如來源資訊有誤或侵犯權益,請聯絡我們刪除或授權事宜。
– END –


更多Linux好文請點選【閱讀原文】哦
↓↓↓
