
導讀:國際權威市場洞察報告Gen Market Insights近日釋出《全球人臉識別裝置市場研究報告》稱,中國2017年人臉識別產值佔全世界29.29%市場份額,2023年將達到44.59%。報告還提到中國人工智慧公司雲從科技在2017年佔有12.88%市場份額(佔世界比例)。
人臉識別是AI技術發展較快、應用較多的一個領域,目前國內人臉識別應用已相當廣泛,並積累了不少實戰經驗。
本文內容涵蓋人臉識別發展歷程、市場研究、核心技術、商業應用以及產業落地、個人看法等乾貨研究。註意,本文乾貨滿滿,約有2萬7千字,強烈建議大家先收藏後學習!
作者:放飛人夜
01 發展史
1. 人臉識別的理解
人臉識別(Face Recognition)是一種依據人的面部特徵(如統計或幾何特徵等),自動進行身份識別的一種生物識別技術,又稱為面像識別、人像識別、相貌識別、面孔識別、面部識別等。通常我們所說的人臉識別是基於光學人臉影象的身份識別與驗證的簡稱。
人臉識別利用攝像機或攝像頭採集含有人臉的影象或影片流,並自動在影象中檢測和跟蹤人臉,進而對檢測到的人臉影象進行一系列的相關應用操作。技術上包括影象採集、特徵定位、身份的確認和查詢等等。簡單來說,就是從照片中提取人臉中的特徵,比如眉毛高度、嘴角等等,再透過特徵的對比輸出結果。
2. 人臉識別的發展簡史
第一階段(1950s—1980s)初級階段
人臉識別被當作一個一般性的樣式識別問題,主流技術基於人臉的幾何結構特徵。這集中體現在人們對於剪影(Profile)的研究上,人們對面部剪影曲線的結構特徵提取與分析方面進行了大量研究。人工神經網路也一度曾經被研究人員用於人臉識別問題中。較早從事 AFR 研究的研究人員除了布萊索(Bledsoe)外還有戈登斯泰因(Goldstein)、哈蒙(Harmon)以及金出武雄(Kanade Takeo)等。總體而言,這一階段是人臉識別研究的初級階段,非常重要的成果不是很多,也基本沒有獲得實際應用。
第二階段(1990s)高潮階段
這一階段儘管時間相對短暫,但人臉識別卻發展迅速,不但出現了很多經典的方法,例如Eigen Face, Fisher Face和彈性圖匹配;並出現了若干商業化運作的人臉識別系統,比如最為著名的 Visionics(現為 Identix)的 FaceIt 系統。 從技術方案上看, 2D人臉影象線性子空間判別分析、統計表觀模型、統計樣式識別方法是這一階段內的主流技術。
第三階段(1990s末~現在)
人臉識別的研究不斷深入,研究者開始關註面向真實條件的人臉識別問題,主要包括以下四個方面的研究:1)提出不同的人臉空間模型,包括以線性判別分析為代表的線性建模方法,以Kernel方法為代表的非線性建模方法和基於3D資訊的3D人臉識別方法。2)深入分析和研究影響人臉識別的因素,包括光照不變人臉識別、姿態不變人臉識別和表情不變人臉識別等。3)利用新的特徵表示,包括區域性描述子(Gabor Face, LBP Face等)和深度學習方法。4)利用新的資料源,例如基於影片的人臉識別和基於素描、近紅外影象的人臉識別。
02 市場研究
1. 全球人臉識別市場
前瞻根據人臉識別行業發展現狀;到2016年,全球生物識別市場規模在127.13億美元左右,其中人臉識別規模約26.53億美元,佔比在20%左右。預計到2021年,全球人臉識別市場預計將達到63.7億美元,按預計期間的複合增長率達17.83%。

2. 中國人臉識別市場
前瞻根據人臉識別行業發展現狀,估算我國人臉識別市場規模約佔全球市場的10%左右。2010-2016年,我國人臉識別市場規模逐年增長,年均複合增長率達27%。2016年,我國人臉識別行業市場規模約為17.25億元,同比增長27.97%,增速較上年上升4.64個百分點。
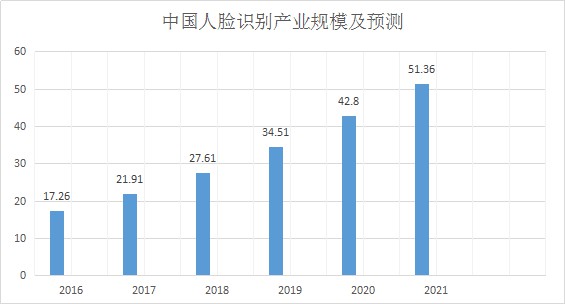
3. 國內主要玩家分佈
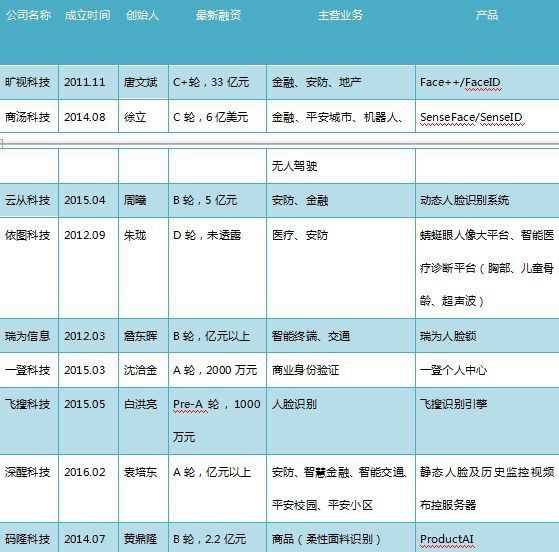
3.1 中國部分人臉識別公司(排名不分先後)

3.2 四大獨角獸介紹及對比細分領域
(1)曠視科技:
2014年,獲阿裡巴巴旗下螞蟻金服投資,主攻金融和監控兩大行業,有子公司曠視智安;團隊成員除了幾名來自清華校友外,還有來自美國哥倫比亞大學、英國牛津大學和美國南加州大學的科研及開發人員,截至目前員工僅有100餘人。
在金融、安防、零售領域分別開始了商業化探索成功發育出Face++Financial,Face++Security,Face++BI等垂直人臉驗證解決方案,主要將人臉識別應用在網際網路產品上,自己做研發,在美圖秀秀、淘寶等網際網路領域得到良好的應用,在金融領域的市場一直佔據沙發前排陣營;2016年獲得上億元C輪融資,最後選擇透過計算機視覺技術與NLP技術的結合,製造出能“識別萬物”的智慧機器人,提供硬體模組,裡面內建他們家的演演算法。目前正在準備啟動IPO的步伐,VIE架構讓他們得以繞過A股,不用達到連續三年盈利的標準實現快速上市。
(2)商湯科技:
SenseTime(商湯科技),獲IDG資本投資,主攻金融、移動網際網路、安防監控三大行業;由香港中文大學的湯曉歐建立,“商湯”中的湯指的就是湯曉歐本人,湯曉鷗及其研究團隊所開發的DeepID演演算法率先將深度學習應用到人臉識別上,在技術指標上實現了新的突破。主要案例是圍繞各個美化軟體與直播平臺製作人臉貼圖,重點強化了人臉識別的關鍵點檢測及跟蹤技術。
團隊有300多號,也從當初toC轉向toB領域;成立於2014年的商湯科技選擇另闢蹊徑,選擇用“四大美女”這個話題讓人們躁動起來,到最後四大美女走了三個;商湯的網路都是自己設計的,這樣對於深度學習網路的掌控力就會更強,提供SaaS服務的同時,可以透過SaaS把背後的資料拿到,再進行更多更細緻的分析再次提升服務質量。
(3)雲從科技:
2015年4月,周曦拿到戰略投資成立雲從科技,同年針對金融和銀行業推出了40多種解決方案,包含從演演算法、產品、銷售、售後的全產業鏈打造,針對農行、建行、交行、中行及多地公安提供定製化服務。團隊成員除了來自中科大的校友外,還來自中國科學院各大研究所、UIUC、IBM、NEC、MicroSoft等全球頂尖學府及研究機構。
截止2016年11月,成立一年半,研發團隊擴充套件為200餘名,核心產品是人臉識別系統及IBIS整合生物識別平臺,還具備3D模型、紅外活體、靜默活體等技術,可根據場景需求自由調節。選擇連線硬體、開發與技術,屬於全產業鏈樣式,因為人臉識別系統多數情況下需要深度定製,只有這樣,才能在客戶提出需求的情況下迅速反饋,修改,統一使用者體驗。
(4)依圖科技:
2012 年九月,朱瓏與他的好友林晨曦在創立依圖科技,這家從事人工智慧創新性研究的創企從影象識別入手,首先與全國省市級公安系統合作,對車輛品牌、型號等進行精準識別,隨後擴充套件到人像識別,透過靜態人像比對技術和動態人像比對技術,協助公安系統進行人員身份核查、追逃、監控、關係挖掘等。
發展近6年,依圖科技的產品已經應用到全國二十多個省市地區的安防領域,安防領域之外,依圖也進入智慧城市領域和健康醫療領域,它要協助政府構建”城市大腦”,也希望將醫療領域的巨大知識鴻溝縮小,改善醫患體驗。
(5)細分領域對比表

(6)主要客戶對比

4. 商業樣式
4.1 人臉識別商業樣式設計步驟

4.2 人臉識別盈利樣式

03 人臉識別的流程及主要技術
1. 人臉識別系統組成

2. 人臉識別的一般流程
2.1 人臉採集
(1)簡介
不同的人臉影象透過攝像鏡頭採集得到,比如靜態影象、動態影象、不同的位置、不同表情等,當採集物件在裝置的拍攝範圍內時,採集裝置會自動搜尋並拍攝人臉影象。
(2)人臉採集的主要影響因素
-
影象大小:人臉影象過小會影響識別效果,人臉影象過大會影響識別速度。非專業人臉識別攝像頭常見規定的最小識別人臉畫素為60*60或100*100以上。在規定的影象大小內,演演算法更容易提升準確率和召回率。影象大小反映在實際應用場景就是人臉離攝像頭的距離。
-
影象解析度:越低的影象解析度越難識別。影象大小綜合影象解析度,直接影響攝像頭識別距離。現4K攝像頭看清人臉的最遠距離是10米,7K攝像頭是20米。
-
光照環境:過曝或過暗的光照環境都會影響人臉識別效果。可以從攝像頭自帶的功能補光或濾光平衡光照影響,也可以利用演演算法模型最佳化影象光線。
-
模糊程度:實際場景主要著力解決運動模糊,人臉相對於攝像頭的移動經常會產生運動模糊。部分攝像頭有抗模糊的功能,而在成本有限的情況下,考慮透過演演算法模型最佳化此問題。
-
遮擋程度:五官無遮擋、臉部邊緣清晰的影象為最佳。而在實際場景中,很多人臉都會被帽子、眼鏡、口罩等遮擋物遮擋,這部分資料需要根據演演算法要求決定是否留用訓練。
-
採集角度:人臉相對於攝像頭角度為正臉最佳。但實際場景中往往很難抓拍正臉。因此演演算法模型需訓練包含左右側人臉、上下側人臉的資料。工業施工上攝像頭安置的角度,需滿足人臉與攝像頭構成的角度在演演算法識別範圍內的要求。
2.2 人臉檢測
(1)簡介
在影象中準確標定出人臉的位置和大小,並把其中有用的資訊挑出來(如直方圖特徵、顏色特徵、模板特徵、結構特徵及Haar特徵等),然後利用資訊來達到人臉檢測的目的。
(2)人臉關鍵點檢測(人臉對齊)
自動估計人臉圖片上臉部特徵點的坐標。
(3)主流方法
基於檢測出的特徵採用Adaboost學習演演算法(一種用來分類的方法,它把一些比較弱的分類方法合在一起,組合出新的很強的分類方法)挑選出一些最能代表人臉的矩形特徵(弱分類器),按照加權投票的方式將弱分類器構造為一個強分類器,再將訓練得到的若干強分類器串聯組成一個級聯結構的層疊分類器,有效地提高分類器的檢測速度。
最近人臉檢測演演算法模型的流派包括三類及其之間的組合:viola-jones框架(效能一般速度尚可,適合移動端、嵌入式上使用),dpm(速度較慢),cnn(效能不錯)。
2.3 人臉影象預處理
(1)簡介
基於人臉檢測結果,對影象進行處理並最終服務於特徵提取的過程。
(2)原因
系統獲取的原始影象由於受到各種條件的限制和隨機幹擾,往往不能直接使用,必須在影象處理 的早期階段對它進行灰度矯正、噪聲過濾等影象預處理。
(3)主要預處理過程
人臉對準(得到人臉位置端正的影象),人臉影象的光線補償,灰度變換、直方圖均衡化、歸一 化(取得尺寸一致,灰度取值範圍相同的標準化人臉影象),幾何校正、中值濾波(圖片的平滑操作以消除噪聲)以及銳化等。
2.4 人臉特徵提取
(1)簡介
人臉識別系統可使用的特徵通常分為視覺特徵、畫素統計特徵、人臉影象變換繫數特徵、人臉影象代數特徵等。人臉特徵提取就是針對人臉的某些特徵進行的,也稱人臉表徵,它是對人臉進行特徵建模的過程
(2)人臉特徵提取的方法
-
基於知識的表徵方法(主要包括基於幾何特徵法和模板匹配法):根據人臉器官的形狀描述以及它們之間的距離特性來獲得有助於人臉分類的特徵資料,其特徵分量通常包括特徵點間的歐氏距離、曲率、和角度等。人臉由眼睛、鼻子、嘴、下巴等區域性構成,對這些區域性和他們之間結構關係的幾何描述,可作為識別人臉的重要特徵,這些特徵被稱為幾何特徵。
-
基於代數特徵或統計學習的表徵方法:基於代數特徵方法的基本思想是將人臉在空域內的高維描述轉化為頻域或者其他空間內的低維描述,其表徵方法為線性投影表徵方法和非線性投影表徵方法。基於線性投影的方法主要有主成分分析法或稱K-L變化、獨立成分分析法和Fisher線性判別分析法。非線性特徵提取方法有兩個重要的分支:基於核的特徵提取技術和以流形學習為主導的特徵提取技術。
2.5 匹配與識別
提取的人臉特徵值資料與資料庫中存貯的特徵模板進行搜尋匹配,透過設定一個閾值,將相似度與這一閾值進行比較,來對人臉的身份資訊進行判斷。
3. 人臉識別的主要方法
3.1 Eigen Face(特徵臉)
MIT實驗室的特克(Turk)和潘特(Pentland)提出的“特徵臉”方法無疑是這一時期內最負盛名的 人臉識別方法。其後的很多人臉識別技術都或多或少與特徵臉有關係,現在特徵臉已經與歸一化的協相關 量(Normalized Correlation)方法一道成為人臉識別的效能測試基準演演算法。
人臉識別特徵臉演演算法檔案:
https://blog.csdn.net/zizi7/article/details/52757300
3.2 Fisher Face(漁夫臉)
貝爾胡米爾(Belhumeur)等提出的 Fisherface 人臉識別方法是這一時期的另一重要成果。該方法 首先採用主成分分析(PCA)對影象表觀特徵進行降維。在此基礎上,採用線性判別分析(LDA)的方法 變換降維後的主成分以期獲得“儘量大的類間散度和儘量小的類內散度”。該方法目前仍然是主流的人臉 識別方法之一,產生了很多不同的變種,比如零空間法、子空間判別模型、增強判別模型、直接的LDA 判 別方法以及近期的一些基於核學習的改進策略。
Fisher Face演演算法檔案:
https://blog.csdn.net/zizi7/article/details/52999432
3.3 EGM(彈性圖匹配)
其基本思想是用一個屬性圖來描述人臉:屬性圖的頂點代錶面部關鍵特徵點,其屬性為相應特徵點處 的多解析度、多方向區域性特徵——Gabor變換12特徵,稱為Jet;邊的屬性則為不同特徵點之間的幾何 關係。對任意輸入人臉影象,彈性圖匹配透過一種最佳化搜尋策略來定位預先定義的若干面部關鍵特徵點, 同時提取它們的Jet特徵,得到輸入影象的屬性圖。最後透過計算其與已知人臉屬性圖的相似度來完成識 別過程。該方法的優點是既保留了面部的全域性結構特徵,也對人臉的關鍵區域性特徵進行了建模。
彈性圖匹配演演算法檔案:
https://blog.csdn.net/real_myth/article/details/44828219
3.4 基於幾何特徵的方法
幾何特徵可以是眼、鼻、嘴等的形狀和它們之間的幾何關係(如相互之間的距離)。這些演演算法識別速 度快,需要的記憶體小,但識別率較低。
3.5 基於神經網路的方法
神經網路的輸入可以是降低解析度的人臉影象、區域性區域的自相關函式、區域性紋理的二階矩等。這類方法同樣需要較多的樣本進行訓練,而在許多應用中,樣本數量是很有限的。
3.6 基於線段Hausdorff 距離(LHD) 的方法
心理學的研究表明,人類在識別輪廓圖(比如漫畫)的速度和準確度上絲毫不比識別灰度圖差。LHD是基於從人臉灰度影象中提取出來的線段圖的,它定義的是兩個線段集之間的距離,與眾不同的是,LHD並不建立不同線段集之間線段的一一對應關係,因此它更能適應線段圖之間的微小變化。實驗結果表明,LHD在不同光照條件下和不同姿態情況下都有非常出色的表現,但是它在大表情的情況下識別效果不好。
3.7 基於支援向量機(SVM) 的方法
近年來,支援向量機是統計樣式識別領域的一個新的熱點,它試圖使得學習機在經驗風險和泛化能力上達到一種妥協,從而提高學習機的效能。支援向量機主要解決的是一個2分類問題,它的基本思想是試圖把一個低維的線性不可分的問題轉化成一個高維的線性可分的問題。通常的實驗結果表明SVM有較好的識別率,但是它需要大量的訓練樣本(每類300個),這在實際應用中往往是不現實的。而且支援向量機訓練時間長,方法實現複雜,該函式的取法沒有統一的理論。
4. 技術發展方向
-
結合三維資訊:二維和三維資訊融合使特徵更加魯棒
-
多特徵融合:單一特徵難以應對複雜的光照和姿態變化
-
大規模人臉比對:面向海量資料的人臉比對與搜尋
-
深度學習:在大資料條件下充分發揮深度神經網路強大的學習能力
5. 人臉識別資料庫
-
Yale人臉資料庫
-
ORL人臉資料庫
-
CMU PIE人臉資料庫
-
FERET人臉資料庫
-
MIT資料庫
-
BANCA人臉資料庫
-
CAS-PEAL人臉資料庫
-
JAFE表情資料庫
-
Cohn-Kanade表情資料庫
-
MMI表情資料庫
6. 技術指標
6.1 人臉檢測中的關鍵指標
例子:在攝像頭某張抓拍影象中,一共有100張人臉,演演算法檢測出80張人臉,其中75張是真實人臉,5 張是把路標誤識為人臉。
-
檢測率:識別正確的人臉/圖中所有的人臉。檢測率越高,代表檢測模型效果越好。
-
誤檢率:識別錯誤的人臉/識別出來的人臉。誤檢率越低,代表檢測模型效果越好。
-
漏檢率:未識別出來的人臉/圖中所有的人臉。漏檢率越低,代表檢測模型效果越好。
-
速度:從採集影象完成到人臉檢測完成的時間。時間約短,檢測模型效果越好。
在這個實際案例中:檢測率=75/100 誤檢率=5/80 漏檢率=(100-75)/100
6.2 人臉識別中的關鍵指標
1000張樣本圖片裡,共600張正樣本。相似度為0.9的圖片一共100張,其中正樣本為99張。雖然0.9閾值的正確率很高,為99/100;但是0.9閾值正確輸出的數量確很少,只有99/600。這樣很容易發生漏識的情況。
-
檢測率:識別正確的人臉/圖中所有的人臉。檢測率越高,代表檢測模型效果越好。
-
誤檢率:識別錯誤的人臉/識別出來的人臉。誤檢率越低,代表檢測模型效果越好。
-
漏檢率:未識別出來的人臉/圖中所有的人臉。漏檢率越低,代表檢測模型效果越好。
-
速度:從採集影象完成到人臉檢測完成的時間。時間約短,檢測模型效果越好。
在這個實際案例中:檢測率=75/100 誤檢率=5/80 漏檢率=(100-75)/100
6.3 人臉識別中的關鍵指標
1000張樣本圖片裡,共600張正樣本。相似度為0.9的圖片一共100張,其中正樣本為99張。雖然0.9閾值的正確率很高,為99/100;但是0.9閾值正確輸出的數量確很少,只有99/600。這樣很容易發生漏識的情況。
-
精確率(precision):識別為正確的樣本數/識別出來的樣本數=99/100
-
召回率(recall):識別為正確的樣本數/所有樣本中正確的數=99/600
-
錯誤接受率/認假率/誤識率(FARFalse Accept Rate):
-
定義:指將身份不同的兩張照片,判別為相同身份,越低越好
-
FAR = NFA / NIRA
-
式中 NIRA 代表的是類間測試次數,既不同類別間的測試次數,打比方如果有1000個識別 模型,有1000個人要識別,而且每人只提供一個待識別的素材,那 NIRA=1000*(1000-1) 。NFA是錯誤接受次數。
-
FAR決定了系統的安全性,FRR決定了系統的易用程度,在實際中,FAR對應的風險遠遠高於FRR,因此,生物識別系統中,會將FAR設定為一個非常低的範圍,如萬分之一甚至百萬分之一,在FAR固定的條件下,FRR低於5%,這樣的系統才有實用價值。
-
錯誤拒絕率/拒真率/拒識率(FRR False Reject Rate):
-
定義:指將身份相同的兩張照片,判別為不同身份,越低越好
-
FRR = NFR / NGRA
-
上式中NFR是類內測試次數,既同類別內的測試次數,打比方如果有1000個識別模型, 有1000個人要識別, 而且每人只提供一個待識別的素 材,那 NIRA=1000,如果每個人提供N張圖片,那麼 NIRA=N*1000 。NFR是錯誤拒絕次數。
04 行業應用
1. 人臉識別(FR)+其他行業
1.1 FR+金融
(1)實名認證
金融機構傳統上使用人工肉眼判斷、簡訊驗證、系結銀行卡等手段進行實名認證。這些傳統手段存在準確率不高、客戶體驗較差、成本高等問題,對金融企業業務發展造成了巨大的困擾。基於人臉識別的實名認證方式具有準確率高(一億人中才存在兩人長相相同)、客戶體驗好(認證速度快、客戶操作少)、成本低(相較於傳統認證方式)的優點,已被眾多領先金融企業所採用。
(2)人臉識別在銀行遠端開戶上的應用
在遠端開戶時,金融機構可以透過智慧終端線上上進行身份鑒權驗證,使用人臉識別技術開戶可以極大提升業務辦理的安全性、時效性,並節省大量人力。
(3)刷臉取款
在這方面人臉取代了銀行卡,只需要人臉+密碼即可完成取款。在前兩個方面,人臉識別技術已經被國內各大銀行廣泛採用,刷臉取款方面,農行和招行搶先一步在ATM上線了刷臉取款功能。


1.2 FR+醫療
(1)重點應用
-
打擊涉醫犯罪,確保就診安全。建立有針對性的涉醫犯罪人員布控庫,與屬地公安部門配合,進行實時布控。
-
管控職務犯罪,控制不當競爭。對進入醫院診療區域的醫葯代表進行管控,協助解決藥品流通領域經營不規範、競爭失序等問題。
-
杜絕職業醫鬧,保護人身安全。打擊頻繁出現的職業醫鬧,提高事件的響應速度,從被動響應變為主動預防。
-
規範就診流程,和諧醫患關係。重點防範黃牛、醫託等幹擾正常就診秩序的特殊人群。
-
加強監管力度,維護醫保基金。實現就診病人與醫保資訊庫中身份證照的比對,杜絕冒用醫保卡的現象。
-
易肇事肇禍嚴重精神障礙患者管控。結合“雪亮工程”,確保嚴重精神障礙患者流入地、流出地發現管控到位。
(2)人臉識別在醫療行業的應用突破基於三點
-
獲取到標的物件的資訊:因為行政體系不同,醫療行業想獲取到標的物件資訊存在較大困難,需相關行政單位進行關鍵的協調工作。標的物件資訊包含但不侷限於:人臉照片、人像照片、人員基本資訊、人員動態等。
-
人臉識別的演演算法進一步提升:目前的人臉識別演演算法的精度已經達到了相當高的水準,誤報、漏報均已控制在可接受範圍;更近一步的演演算法,可以從非結構化的影片/圖片中獲取更多的價值資訊,從更多地維度來實現不同的應用。
-
管理者思維和水平的提升:人工智慧、人臉識別是革命性顛覆性的技術,可以給醫療行業帶來巨大的提升。如何將人臉識別真正應用到醫療行業的各方各面需要管理者與技術提供方一起拓展思維、共同努力。
(3)人臉識別在醫療行業的前景
-
對接公安影片監控、醫警聯動平臺:系統滿足公安現有標準要求,後續可與公安機關影片監控、醫警聯動等平臺進行無縫對接,將報警資訊及關聯的影片、圖片推送給轄區派出所,實現聯動。
-
人臉身份查證:輸入標的人員照片,即可知道此人身份及其是否屬於重點管控人員,是否曾經來過醫院,及其出現時間、頻次。可用於篩查可疑人員,找到其活動規律。
-
人員軌跡回放:輸入標的人員照片,即可查詢此人是否來過醫院,到過哪些地方。此功能可還原特定人員的行動軌跡,用於嫌疑人行為研判和事後取證。
-
對接門禁系統:與門禁系統對接,預留刷臉開門、人臉考勤等高階功能,方便辦公區、手術室、藥品庫、住院部等區域的出入管理。
-
對接刷卡系統:與二代證、醫保卡等刷卡系統對接,將採集的人臉照片與證件上儲存的照片進行比對,驗證刷卡人的真實身份。
1.3 FR+新零售
(1)應用人臉識別的優勢
-
為重點客戶畫像:幫助賣家獲得顧客和潛在顧客更精準的資訊,構建使用者畫像。可以安裝在超市、商場、門店等入口,統計每天進入門店的人數、大致年齡和性別等;另一種可以安裝在貨架上,分析客戶的關註點和消費習慣等。透過大資料分析挖掘回頭客,提升客戶提袋率和VIP轉化率;
-
為零售商降本增益:以智慧化系統來代替人工,以人臉識別系統連線支付端來代替收銀員,能跟快實現零售店的導流和商品人流分析等。
-
減少突發事件的產生:門店遇到商品失竊的突發事件,透過對所獲資料的分析,也可以將不良客戶拉入“黑名單”或是降低其信用水平。
-
完美連線線上線下:識別系統獲得的使用者偏好還能反哺線上,將所得資料透過線上反饋給廠商,助力於廠商更全面地瞭解消費者需求,進而精準地研發產品,設計營銷策略。這些都是完美實現新零售“打通線上線下”內在要求的極佳方式。
(2)人臉識別的安全隱患
-
人臉特徵容易被覆制:眾所周知,破解密碼的最常用手段是複製,透過竊取數字密碼以及套取指紋來解密的案例己經不勝列舉。與記錄在大腦中或其他介質上面的數字密碼相比,暴露在外面的人臉更容易被覆制。透過拍照完全可以獲得一個人的臉部特徵併進行複製,利用整容技術或者用照片識別等欺詐的方法可以騙過人臉支付系統。
-
個人資訊洩露問題:在科技發達的今天,人們似乎很輕易就可以透過無孔不入的渠道查到消費者的各種資訊。而對於刷臉支付來講,像人臉特徵這種人體密碼一旦交給別人保管,個人資訊的安全繫數將如何確保?獲取使用者的面部特徵是否會涉及到個人隱私?基於面部掃描系統的支付在普遍應用之後會不會帶來基於位置服務造成的個人行蹤洩露?
1.4 FR+安防
(1)智慧城市的基礎
-
影片分析:基於影片中的人臉照片進行遠距離、快速、無接觸式的重點人員布控預警。讓應用於車站、機場、地鐵等重點場所和大型商場超市等人群密集的公共場所影片監控系統能夠對影片影象進行採集、自動分析、抓取人臉實時比對,主動在監控場景中識別重點關註人員,實現重點人員的布控和識別。
-
重要場所的布控:對機場、車站、港口、地鐵重點場所和大型商超等人群密集公共場所進行布控,以達到對一些重點人員的排查,抓捕逃犯等目的。
-
靜態庫或身份庫的檢索:對常住人口、暫住人口的人臉圖片進行預先建庫,透過輸入各種渠道採集的人臉圖片,能夠進行比對和按照相似度排序,進而獲悉輸入人員的身份或者其他關聯資訊,此類應用存在兩種擴充套件形式,單一身份庫自動批次比對併發現疑似的一個人員具有兩個或以上身份資訊的靜態庫查重,兩個身份庫之間自動交叉比對發現交集資料的靜態庫碰撞。
-
動態庫或抓拍庫的檢索:對持續採集的各攝像頭點位的抓拍圖片建庫,透過輸入一張指定人員的人臉圖片,獲得其在指定時間範圍和指定攝像頭點位出現的所有抓拍記錄,方便快速瀏覽,當攝像頭點位關聯GIS系統,則可以進一步的按照時間順序排列檢索得到的抓拍記錄,並繪製到GIS上,得到人員運動的軌跡。
(2)反恐行動的助力
現在新疆、西藏等城市都將人臉識別作為基礎設施建設領域的投資重點,由於人員複雜、居住人口相對混亂等因素,這些城市成為了恐怖襲擊等違法犯罪行為的高發場所。而人臉識別技術採用人臉檢測演演算法、人臉跟蹤演演算法、人臉質量評分演演算法以及人臉識別演演算法。實現城市居住人員人臉的抓拍採集、建模儲存,實時黑名單比對報警和人臉後檢索等功能。能及時在危險發生之前制止。
(3)兒童安全的保鏢
近年來兒童拐賣活動越來越猖獗,為了更好的保護兒童安全,有些幼兒園、小學在門口已經安裝上了面部識別系統。系統採用人臉識別加IC/ID卡(非接觸式智慧卡) 雙重認證:每一位幼兒在入學註冊時進行相關登記:資料、面像、IC/ID卡號、接送者、接送者面像。
每次入園時刷卡進行報道,放學時刷卡併進行接送家長人臉認證,如果認證失敗拍照後即報警通知管理員,如果認證成功即拍照放行。不論識別成功與否,系統都會記錄下被識別者影象。每一次接送都有詳細的時間、接送人員的照片可供查詢。另外系統提供簡訊提示的擴充套件功能,家長可在手機上看到人臉識別認證時所拍的照片,從而監控到接送這個過程,從其中一個重要源頭杜絕了兒童被拐的可能性。
(4)智慧酒店的管理
以前開房登記流程是:接待人員問詢——身份證掃描確認——支付押金——選房層發房卡——列印紙質票據,這些流程非常繁雜,尤其是身份認證耗時最長,若遇到團隊入住情況則更為複雜,身份證識別裝置可能會因高頻使用出現故障,而急於進房間休息的顧客卻只能在前臺等待手續完成,客戶體驗非常糟糕。
人臉識別技術就能很好的解決這一難題,幫助酒店實現系統化業務管理和一站式共享解決方案。智慧酒店的安防系統利用人臉識別技術,當顧客走到前臺時系統已經自動根據顧客被攝像頭捕捉到的影像調取顧客身份核對。整個驗證核對過程簡單、快速且實現了自動化,更大幅降低了人工識別造成的誤差。而且,針對酒店VIP客人,系統可實時對比酒店大堂的攝像頭影像和登記在酒店基礎系統中的VIP面部資料,當VIP客人到達時,酒店可第一時間提供個性化周到服務,提高客戶的滿意度。
1.5 FR+公安
-
尋人尋親:對老百姓或其他業務部門提供的照片,直接送入系統進行比對、檢索、篩選,最後人工確認。
-
派出所擋獲違法人員:對派出所擋獲的人員,登記筆錄,對於其中一些少數民族、聾啞人或保持沉默者等無法查證身份的人員,可拍攝照片送入各種照片庫中比對,排查涉及大案要案人員,以免漏網;或查證其前科,累計處理。
-
查證無名屍源:需要查證無名屍源時,先拍攝正面照片,送入計算機,如果照片閉眼、破損或變形,可用人像合成系統或人工繪製一幅標準照,送入比對系統比對查證。
-
目擊者描述排查:獲得現場目擊者對嫌疑人的形象描述後,可用人像合成系統進行排查。
-
影片監控照片:一般監控系統針對場景,得到的涉案嫌疑人的影象都有模糊、偏轉、逆側光等質量不佳問題,這時需要根據影象用人像合成系統或人工繪製一幅標準照,送入照片比對系統比對查證。
-
公共場所集會:在政府、球場等公共場所,時常會有人員滋事,此時公安民警不便直接帶人處理,可以採用長焦攝像機拍攝特寫鏡頭,如果效果不夠好可以用人像合成系統修正,送入比對系統比對查證。
-
一代/二代居民身份證識別:根據犯罪人員的身份證照片資訊,與系統照片庫中的資訊資料進行比對,提取出與證件上照片相似的人員資訊,能充分利用現有的二代身份證照片資源,為公安部門的工作提供高效有利的幫助。
-
其他應用:常住人口的比對查詢、暫住人口的比對查詢、重點人口的比對查詢、CCIC在逃人員的比對查詢等。
1.6 FR+商業場景
-
訪客登記:訪客到訪公司,於平板電腦進行訪客資訊登記,由攝像頭自動抓取人臉,透過系統打印出 訪客貼紙;
-
識別迎賓:公司員工,貴賓進入公司入口,攝像頭能識別到訪人員,實現門禁功能管理;
-
人臉識別考勤:透過入口處的前臺平板電腦進行人臉識別考勤,也可透過手機端進行人臉識別考;
-
智慧生活:較多的園區、樓宇需要人臉門禁系統,人員進出快速通行,便於管理住戶、訪客的進出記 錄;
-
智慧教育:為嚴防替考事件的發生,確保考試安全,人臉識別可加強考試入場環節的考生身份認證, 並有效實現智慧影片監考、作弊防控等;
-
智慧商場:利用人臉識別技術追蹤並分析商場內的人流屬性,人群分佈等。
應用樣式典型具體應用特點說明應用領域:
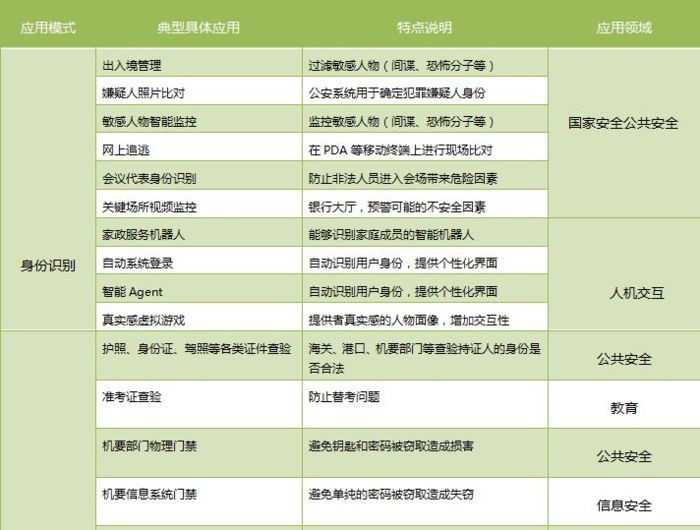
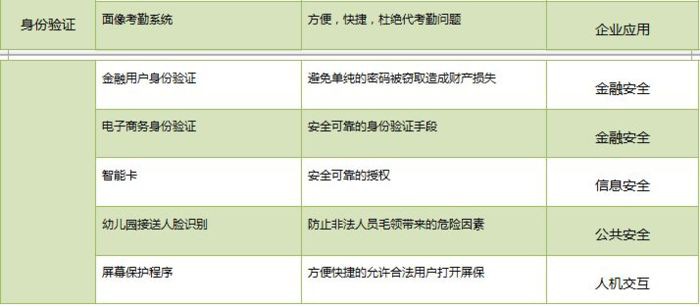
2. FR的部分應用
2.1 人臉檢測跟蹤
(1)應用
商場客流跟蹤分析,地鐵、火車站、會場、機場等場所的可疑人員的跟蹤檢測,體育賽事的現場監控等。
(2)難點
多人臉跟蹤、遠場識別人臉、背景複雜、低質量圖片人臉識別(演演算法預處理),還有側臉(3D重建人物全面),遮擋,模糊,表情變化、強弱光(多特徵融合增強抗幹擾力)等各種實際環 境。
(3)建議
遠場識別(可依據距離識別)、背景複雜(可虛化無關場景,凸顯主角)。
2.2 人臉關鍵點定位
(1)應用
可用於圖片的合成、動態圖片的分析(直播行業鑒黃、鑒暴),透過關鍵點分析人臉表情情緒。
(2)難點
大角度側臉,表情變化、遮擋、模糊、明暗等,動靜態關鍵點捕捉。
(3)建議
對模糊部位可進行平滑處理,根據眼睛、嘴的特點建立不同的區域塊等。
2.3 人臉身份認證
(1)應用
關鍵性應用(金融身份認證、海關檢查、火車站和機場等進站),非關鍵性應用(智慧小區居民進出、辦公大樓進出、公司單位上班打卡等)
(2)難點
年輕時的證件照和本人識別匹配、戴眼鏡和未戴眼鏡、側臉和正臉、表情、背景幹擾、整容後、雙胞胎及長相類似等。
(3)建議
可基於三維人像分析避免認證時的假冒,動作分析等。(曠視的難以區分蠟像、海報和真人)
2.4 人臉屬性(性別、年齡、種族、表情、飾品、鬍鬚、面部動作狀態)
(1)人臉表情識別(Face expression recognition 簡稱FER)
-
普遍認為人類主要有六種基本情感:憤怒(anger)、高興(happiness)、悲傷(sadness)、驚訝(surprise)、厭惡(disgust)、恐懼(fear)。而大多數表情識別是基於這六種情感及其拓展情緒實現的
-
主要困難點是:
-
表情的精細化程度劃分:每種情緒最微弱的表現是否需要被分類。分類的界限需要產品給出評估規則。
-
表情類別的多樣化:是否還需要補充其他類別的情緒,六種情緒在一些場景下遠不能變現人類的真實 情緒。因此除了基本表情識別外,還有精細表情識別、混合表情識別、非基本表情識別等細緻領域的研究。
-
缺少魯棒性
(2)人臉性別識別
性別分類是一個典型的二類問題,人臉性別分類問題需要解決的兩個關鍵問題是人臉特徵提取和分類器的選擇。人臉性別識別其實僅能識別到人臉外貌更偏向於女性還是男性,很難對女生男相、男生女相進行正確判斷。
(3)人臉年齡識別
-
難點:單人的不同年齡段識別和多人的不同年齡段識別,人臉年齡識別常和人臉識別進行組合識別,能更正確的判斷在一定年限內“是否是一個人”的問題;除了以上內容,還有是否戴眼鏡、頭髮長度、膚色等。
-
建議:識別年齡無變化的人臉用分類即可,而對年齡變化的人臉識別方法是透過年齡模擬,將測試影象和查詢庫中的影象變換到某一共同的年年齡,從而去除年齡不同的影響,使識別在年齡相同的人臉影象進行。
(4)人臉屬性的應用
根據物理屬性(性別、年齡、種族、眼鏡顏值等)可用於廣告定向投放、個性化智慧推薦、顧客分析、婚戀交友等;化學屬性(面部動作、情緒等)可用於即時影片社交、圖片合成、圖片美化等。
(5)識別建議
人臉屬性分析時,可利用K-近鄰演演算法匹配雲端庫裡的類似照片後再對相似屬性進行分析。
2.5 人臉聚類
(1)應用:個性化相簿管理、照片分享社交、婚戀交友相似臉型匹配推薦興趣社交等。
(2)難點:角度、光線、髮型、相似臉型等幹擾分類。
(3)建議:可基於一張正臉照片,將其他照片進行依次比對分析後再分類等(智慧相簿、婚戀社交)。
2.6 真人檢測
(1)應用:銀行開戶驗證、車站、機場、公司打卡等。
(2)難點:2D和3D的識別檢測、真人與蠟像、矽膠假冒人臉識別、照片和真人識別檢測驗證等。
(3)建議:可基於三維人像分析避免認證時的假冒等,動態識別驗證以區分假象(曠視的難以區分蠟像、海報和真人)。
2.7 人像美顏/美妝
(1)應用:興趣社交、婚戀交友、影象合成、個性化用品推薦和廣告投放等。
(2)難點:美顏與一般濾鏡效果的區別、美顏後的自然效果等。
(3)建議:基於資料集的演演算法更新迭代。
2.8 人體關鍵點(CPM、DeeperCut)
(1)應用:關鍵動作抓拍、人體姿態估計、舞蹈難度評定。
(2)難點:多標的關鍵點定位、關鍵點遮擋、光線強弱等。
(3)建議:關鍵點遮擋(分塊處理、三維構建找尋關鍵點)
3. FR的商業化
3.1 從時間上看商業化的不同階段

3.2 從業務場景上看
場景關鍵點:
-
盤子夠大,支撐公司發展
-
資料迴流,為公司所用
-
高頻使用,需求佔比高
-
可在行業中複製

3.3 垂直行業人臉解決方案(地產行業為例)
(1)地產行業分佈
-
商業地產:辦公樓宇+園區廠區+商業零售+酒店
-
住宅地產:生活小區+公寓
(2)地產行業的市場規模
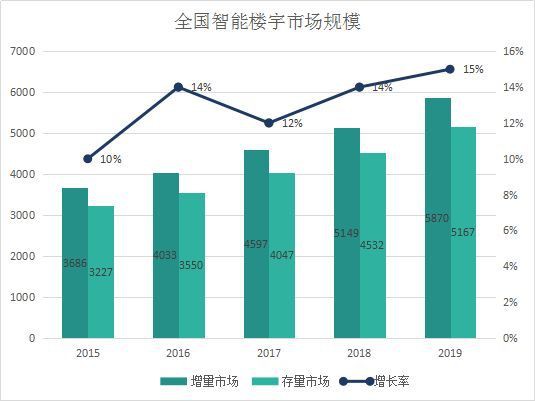
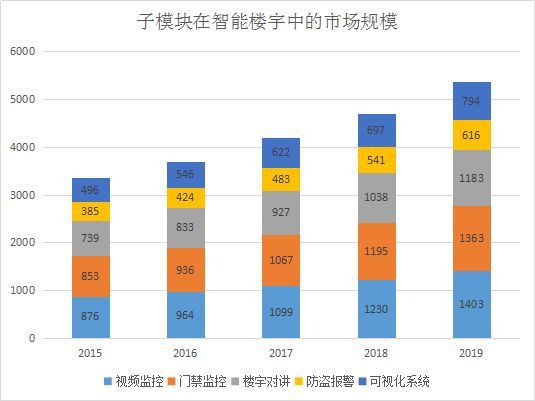
(3)演變方向及客戶痛點
-
影片監控:傳統影片監控廠家正在進行智慧化轉型,從原先的“監控”影片,到現在的“讀懂”影片當中的人、 車、物、事;
-
門禁控制:傳統門禁控制領域價值鏈低,所有廠家正在尋求新的方式來轉型,絕大部分都在生物識別方式上進行 摸索;人臉識別面板機、閘機及其它通行道閘雨後春筍般出現;
-
樓宇對講:普通樓宇對講功能已無法滿足使用要求,結合人臉識別功能的門禁系統需求越來越多;
-
防盜告警:透過智慧化手段,達到降本增效目的,已成為防盜告警、巡更檢查等功能的重點迭代方向;
-
視覺化系統:降低非專業人士的使用難度,使得多方資料為“我”所用,為多種決策提供依據;資訊孤島問題亟待解決,萬物互聯已是所有廠家達成的共識。
-
資訊孤島問題(痛點):
-
智慧化系統種類繁多,系統之間無法實現無縫連線,綜合管理難度大,效率低;
-
智慧化子系統資料採集離散,標準不一,資料價值大打折扣,無法為管理提供決策依據和幫助;
-
各子系統依靠人工管理,人員配備要求高、勞動強度大,人工成本居高不小;
-
絕大多數B端客戶不懂具體業務或細節,需要具象化、視覺化系統呈現。
(4)建設步驟及架構
步驟:
第一步:人員通訊管理
-
基於人員通行管理的平臺系統(功能性產品+後臺系統管理)
-
員工、VIP、訪客、陌生人、黑名單等人員許可權管理;
第二步:感測網路融合
-
CCTV、車輛等;
-
基於“人員”、“車”、“監控”的三位一體智慧建築場景應用;
-
其他子系統模組連結,形成整體感測網路,智慧物聯;
第三步:商業地產+新零售
-
人員、車輛、CCTV三功能在工作+消費場景融合;
-
構建以人為核心的商業綜合體運營方案。
整體IoT架構:


(5)影響因素與最佳化方案
-
決定監控系統效能的幾個主要因素:
-
模板庫的人數:不宜大,包含關鍵人物即可;
-
經過攝像頭的人數:同時出現在攝像頭的人數決定了單位時間裡的比對次數;
-
報警反饋時間:實時性越強,對系統效能要求越高;
-
攝像頭採集幀數:幀數越高,人員經過攝像頭前採集的次數越多,比對的次數也越多。
-
實戰中的最佳化方案:
-
使用更先進的高畫質攝像頭(3-5百萬);
-
室內均勻光線,或室外白天,無側光和折射光;
-
人群面向同樣的方向,朝向相機的方向運動;
-
恰當的監控點,如走廊、巷子或安檢門/閘機口等(不要一群人同時出現);
-
相機與人臉的角度小於20度。
3.4 頂尖公司的應用舉例
(1)Google:2011年07月 谷歌收購人臉識別軟體公司PittPatt
(2)Facebook:2012年6月 Facebook收購以色列臉部識別公司Face.com
(3) 微軟:2012年6月 微軟亞洲研究院釋出人臉檢測演演算法,面部識別系統
(4)網易:2012年5月,網易人臉識別系統全國公測,用於郵箱登陸
(5)百度:2012年12月 百度推出人臉識別,基於影象的全網人臉搜尋
(6)阿裡:2015年11月,在推出支付寶刷臉認證付款
(7)騰訊:2012年下半年,成立優圖專案組
05 人臉識別(FR)的產品落地
1. FR技術產品的優勢
1.1 非接觸
人臉影象的採集不同於指紋、掌紋需要接觸指掌紋專用採集裝置,指掌紋的採集除了對裝置有一定的磨損外,也不衛生,容易引起被採集者的反感,而人臉影象採集的裝置是攝像頭,無須接觸。
1.2 非侵擾
人臉照片的採集可使用攝像頭自動拍照,無須工作人員幹預,也無須被採集者配合,只需以正常狀態經過攝像頭前即可。
1.3 友好
人臉是一個人出生之後暴露在外的生物特徵,因此它的隱私性並不像指掌紋、虹膜那樣強,因此人臉的採集並不像指掌紋採集那樣難以讓人接受。
1.4 直觀
我們判斷一個人是誰,透過看這個人的臉就是最直觀的方式,不像指掌紋、虹膜等需要相關領域專家才可以判別。
1.5 快速
從攝像頭監控區域進行人臉的採集是非常快速的,因為它的非幹預性和非接觸性,讓人臉採集的時間大大縮短。
1.6 簡便
人臉採集前端裝置——攝像頭隨處可見,它不是專用裝置,因此簡單易操作。
1.7 可擴充套件性好
它的採集端完全可以採用現有影片監控系統的攝像裝置,後端應用的擴充套件性決定了人臉識別可以應用在出入控制、黑名單監控、人臉照片搜尋等多領域。
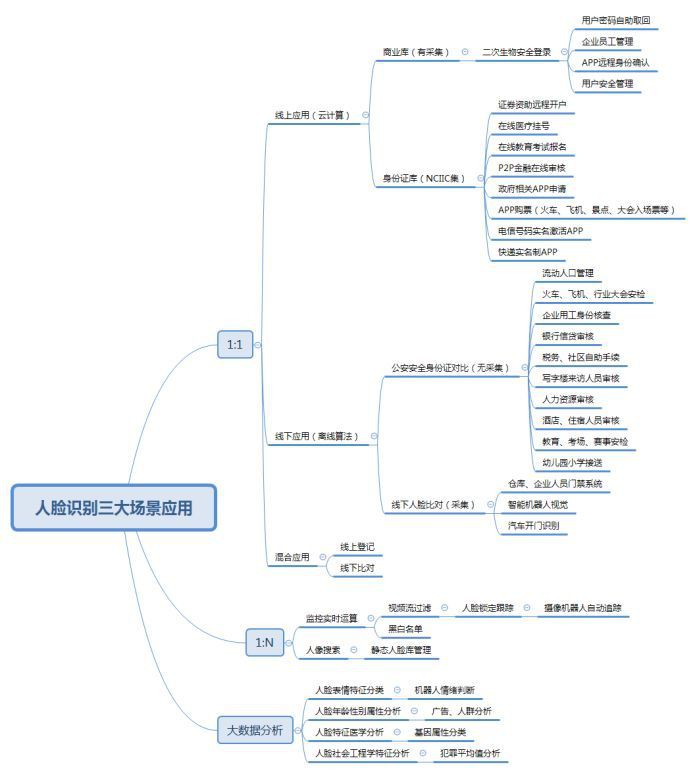
2. FR三大識別場景
2.1 人臉確認(1:1)
-
簡介:將某人面像與指定人員面像進行一對一的比對,根據其相似程度來判斷二者是否是同一人,相似 程度一般以能否超過某一量化閥值為依據。簡單的說就是A/B兩張照片比對,產生的計算數值是否達到要求。
-
產品應用:快速的人臉識別比對,移動支付認證、安全性身份核對、作為身份確認的一種新方式,比如考生身份確認、公司考勤確認、各種證件照和本人確認。
-
實際問題:產品在系統設計的邏輯上,需要先考慮調取已儲存物件資訊的先驗條件。透過介面/語音的提示,使得待認證者預先知道自己正處於被核對的過程中,且已預先瞭解擬核對物件的身份。
-
比對來源的三種主要方式:
-
使用者自傳照片,比如支付寶的人臉比對,使用者自傳的照片最大的問題是照片質量的合格率太低,拍照的光線、角度等因素會導致採集源的質量下降,不利於後期的大批次人臉特徵碼管理。
-
使用身份證讀卡器,讀取身份證上的照片,遺憾的是這張照片2K的大小,不過也是目前用最多的源照片提取方式,比較適合簽到場合。
-
使用公安部旗下NCIIC的人臉比對介面(註意,不是網紋照片介面,這個介面已經不對外),使用的是直接的人臉比對介面。
2.2 人臉辨認(1:N)
(1)簡介
將某人面像與資料庫中的多人的人臉進行比對,並根據比對結果來鑒定此人身份,或找到其中最相似的人臉,並按相似程度的大小輸出檢索結果。
(2)產品應用
人臉開門、人臉檢索,排查犯罪嫌疑人、失蹤人口的全庫搜尋、一人多證的重覆排查等。
(3)實際問題
-
走失兒童的專案中去: 這一類系統的部署需要兩個條件:A. BCD基本庫(比如1000萬人) B.強大的演演算法硬體
-
零售店中的刷臉支付長江,需要使用者預先輸入全手機號,確定使用者身份再進行人臉識別,將原本為1:N的問題轉化為了1:1的問題。
(4)產品難點
a. 1:N中的N能夠支援多大
-
場景多樣化:從一個班級百號人刷臉簽到,到一個公司千號人的刷臉打卡,再到一個學校的幾萬人,一個四線城市幾十 萬人,一個一線城市的幾千萬人,難度是呈指數上升的。
-
公司實際情況:目前各家公司的成熟人臉識別應用能夠支援幾萬到幾百萬人不等的應用場景,而且還有一個錯誤率的概念。比如,公司宣稱千萬分之一的錯誤率的情況下(1/10000000),人臉透過率其實只有93%,這是因為很難做到一定不發生錯誤,而且每個人都能識別透過。(假如一家公司說自己能做到億分之一的錯誤率,透過率能做到98%以上,多半是虛假宣傳,在實際使用中是很難達到的)
b. 非配合場景
-
在配合場景下:比如ATM機刷臉取款,使用者會自主配合,將人臉以一個理想的角度透過識別。
-
而在非配合應用場景下,比如監控影片下的人臉識別,追蹤違法犯罪分子的身份資訊,情況就要困難得多。這種情況下,使用者臉部會發生角度偏大,遮擋,光線不可控等問題。
c. 跨人種,跨年齡識別問題
-
研究發現,在一個資料集上訓練好的模型,想到遷移到另外一個人種上,效果會出現較大程度的下降。另 外,人臉隨著年齡的變化帶來的改變也給人臉識別帶來不小的挑戰。
-
要改善這樣的問題,一個必要條件是需要建立一個足夠完備的跨人種,跨年齡的人臉資料庫;在國內的話,是 以漢族人為主,同時跨年齡的人臉資料庫也比較難收集,需要不短的時間跨度。
d. 產品體驗
-
近來備受關註的刷臉支付,很多時候都會要求使用者輸入全手機號,或手機號後四位,以縮小使用者搜尋庫大 小,實際上這是比較影響體驗的。
-
西安一高校晨讀刷臉簽到,由於系統實際響應匹配時間過長,導致學生排百米長隊。
2.3 多人臉檢索(N:N)
(1)簡介
1:N同時作業就是N:N了,同時相應多張照片檢索需求。
(2)實際產品問題中
-
在影片級N:N的校驗中,如果要提高透過率,很多時候是採取降低準確率的方式,降低演演算法佇列數量;同樣在一些比賽中為了降低誤識率,大大提高了準確率,所以演演算法在校驗的過程中必須遵循至少一個固定標準,追求的是速度效率還是最高準確率。
-
影片流的幀處理所用,對伺服器的計算環境要求嚴苛,目前的演算法系統所支撐的輸出率非常有限。
主要的限制如下:
海量的人臉照片解析需要大量運算(目前很少看到在採集端直接解析的,都是照片剪裁)海量的人臉照片傳輸需要大量的頻寬(常見的720布控攝像頭抓取最小的人臉照片為20K)海量的人臉照片在後臺檢索需要耗費大量的運算(國內主流主機為例,最多到24路攝像頭)。
3. 產品實戰中的物理問題
3.1 光照問題
(1)簡介
光照問題是機器視覺重的老問題,在人臉識別中的表現尤為明顯。由於人臉的3D結構,光照投射出的陰影,會加強或減弱原有的人臉特徵。
(2)解決思路
A、對其進行包括光照強度和方向、人臉反射屬性的量化,面部陰影和照度分析等,嘗試建立數學模型,以利用這些光照模型,在人臉影象預處理或者歸一化階段盡可能的補償乃至消除其對識別效能的影響,將固有的人臉屬性(反射率屬性、3D錶面形狀屬性)和光源、遮擋及高光等非人臉固有屬性分離開來。
B、基於光照子空間模型的任意光照影象生成演演算法,用於生成多個不同光照條件的訓練樣本,然後利用具有良好的學習能力的人臉識別演演算法,如子空間法,SVM等方法進行識別。
3.2 人臉姿態問題
(1)簡介
與光照問題類似,姿態問題也是目前人臉識別研究中需要解決的一個技術難點。姿態問題涉及頭部在三維垂直坐標系中繞三個軸的旋轉造成的面部變化,其中垂直於影象平面的兩個方向的深度旋轉會造成面部資訊的部分缺失。針對姿態的研究相對比較的少,目前多數的人臉識別演演算法主要針列正面、準正而人臉影象,當發生俯仰或者左右側而比較厲害的情況下,人臉識別演演算法的識別率也將會急劇下降。面部幅度較大的哭、笑、憤怒等表情變化同樣影像著面部識別的準確率。
(2)解決思路
-
第一種思路:是學習並記憶多種姿態特徵,這對於多姿態人臉資料可以容易獲取的情況比較實用,其優點是演演算法與正面人臉識別統一,不需要額外的技術支援,其缺點是儲存需求大,姿態泛化能力不能確定,不能用於基於單張照片的人臉識別演演算法中等。
-
第二種思路:是基於單張檢視生成多角度檢視,可以在只能獲取使用者單張照片的情況下合成該使用者的多個學習樣本,可以解決訓練樣本較少的情況下的多姿態人臉識別問題,從而改善識別效能。
-
第三種思路:是基於姿態不變特徵的方法,即尋求那些不隨姿態的變化而變化的特徵。中科院計算所的思路是採用基於統計的視覺模型,將輸入姿態影象校正為正面影象,從而可以在統一的姿態空間內作特徵的提取和匹配。
3.3 遮擋問題
對於非配合情況下的人臉影象採集,遮擋問題是一個非常嚴重的問題。特別是在監控環境下,往往彼監控物件都會帶著眼鏡,帽子等飾物,使得被採集出來的人臉影象有可能不完整,從而影響了後面的特徵提取與識別,甚至會導致人臉檢測演演算法的失效。
3.4 年齡變化
隨著年齡的變化,面部外觀也在變化,特別是對於青少年,這種變化更加的明顯。對於不同的年齡段,人臉識別演演算法的識別率也不同。一個人從少年變成青年,變成老年,他的容貌可能會發生比較大的變化,從而導致識別率的下降。對於不同的年齡段,人臉識別演演算法的識別率也不同。
3.5 人臉相似性
不同個體之間的區別不大,所有的人臉的結構都相似,甚至人臉器官的結構外形都很相似。這樣的特點對於利用人臉進行定位是有利的,但是對於利用人臉區分人類個體是不利的。
3.6 影象質量
人臉影象的來源可能多種多樣,由於採集裝置的不同,得到的人臉影象質量也不一樣,特別是對於那些低解析度、噪聲大、質量差的人臉影象(如手機攝像頭拍攝的人臉圖片、遠端監控拍攝的圖片等)如何進行有效地人臉識別是個需要關註的問題。同樣的,對於高分辨影象對人臉識別演演算法的影響也需要進一步的研究。
3.7 樣本缺乏
基於統計學習的人臉識別演演算法是目前人臉識別領域中的主流演演算法,但是統計學習方法需要大量的訓練。由於人臉影象在高維空間中的分佈是一個不規則的流形分佈,能得到的樣本只是對人臉影象空間中的一個極小部分的取樣,如何解決小樣本下的統計學習問題有待進一步的研究。
3.8 海量資料
傳統人臉識別方法如PCA、LDA等在小規模資料中可以很容易進行訓練學習。但是對於海量資料,這些方法其訓練過程難以進行,甚至有可能崩潰。
3.9 大規模人臉識別
隨著人臉資料庫規模的增長,人臉演演算法的效能將呈現下降。
3.10 動態識別
非配合性人臉識別的情況下,運動導致面部影象模糊或攝像頭對焦不正確都會嚴重影響面部識別的成功率。在地鐵、高速公路卡口、車站卡口、超市反扒、邊檢等安保和監控識別的使用中,這種困難明顯突出。
3.11 人臉防偽
偽造人臉影象進行識別的主流欺騙手段是建立一個三維模型,或者是一些表情的嫁接。隨著人臉防偽技術的完善、3D面部識別技術、攝像頭等智慧計算視覺技術的引入,偽造面部影象進行識別的成功率會大大降低。
3.12 丟幀和丟臉問題
需要的網路識別和系統的計算機識別可能會造成影片的丟幀和丟臉現象,特別是監控人流量大的區域,由於網路傳輸的頻寬問題和計算能力問題,常常引起丟幀和丟臉問題。
3.13 攝像機的頭像問題
攝像機很多技術引數影響影片影象的質量,這些因素有感光器(CCD、CMOS)、感光器的大小、DSP的處理速度、內建影象處理晶片和鏡頭等,同時攝像機內建的一些設定引數也將影響質量,如曝光時間、光圈、動態白平衡等引數。
4. 實戰中的資料標註
4.1 資料標註
(1)一般來說,資料標註部分可以有三個角色
-
標註員:標註員負責標記資料。
-
審核員:審核員負責審核被標記資料的質量。
-
管理員:管理人員、發放任務、統計工資。
只有在資料被審核員審核透過後,這批資料才能夠被演演算法同事利用。
(2)資料標記流程
-
任務分配:假設標註員每次標記的資料為一次任務,則每次任務可由管理員分批發放記錄,也可將整個流程做成“搶單式”的,由後臺直接分發。
-
標記程式設計:需要考慮到如何提升效率,比如快捷鍵的設定、邊標記及邊存等等功能都有利於提高標記效率。
-
進度跟蹤:程式對標註員、審核員的工作分別進行跟蹤,可利用“規定截止日期”的方式淘汰怠惰的人。
-
質量跟蹤:透過計算標註人員的標註正確率和被審核透過率,對人員標註質量進行跟蹤,可利用“末位淘汰”制提高標註人員質量。
4.2 模型訓練
資料標記完成後,交由演演算法同學進行模型的訓練,期間發現的問題可與產品一起商討。訓練過程中,最好能視覺化一些中間結果。一來可以檢測程式碼實現是否有Bug,二來也可以透過這些中間結果,來幫助自己更好的理解這個演演算法的過程。
4.3 模型測試
測試同事(一般來說演演算法同事也會直接負責模型測試)將未被訓練過的資料在新的模型下做測試。
如果沒有後臺設計,測試結果只能由人工抽樣計算,抽樣計算繁瑣且效率較低。模型的效果,需要在精確率(識別為正確的樣本數/識別出來的樣本數)和召回率(識別為正確的樣本數/所有樣本中正確的數)中達到某一個平衡。
測試同事需要關註特定領域內每個類別的指標,比如針對識別人臉的表情,裡面有喜怒哀樂等分類,每一個分類對應的指標都是不一樣的。測試同事需要將測試的結果完善地反饋給演演算法同事,演演算法同事才能找準模型效果欠缺的原因。同時,測試同事將本次模型的指標結果反饋給產品,由產品評估是否滿足上線需求。
(1)測試環境說明
例如:
-
CPU:Intel(R) Core(TM) i7-4790 CPU @ 3.60 GHz
-
記憶體:8GB
-
系統:Ubuntu 14.04 x86_64/Windows 7 SP1 64bit
-
GCC版本:4.8.2
(2)測試集和測試需求說明
比如“圖片包含人臉大小應超過96*96畫素,測試結果達到XX程度滿足需求。
-
經典人臉身份識別測試集LFW,共包含13233 張圖片 5749 種不同身份;世界記錄99.7%。
-
CK+ (一個人臉表情資料集),包含固定表情和自發表情,包含123個人的593個表情序列。每個序列的標的表情被FACS編碼,同時添加了已驗證的情感標簽(生氣、厭惡、害怕、快樂、悲傷、驚訝)。
(3)需要說明“有效距離,左右角度,上下角度,速度”等引數值(範圍)
註:這和“部署的靈活性”相關——由於不同客戶不同場景的需求不同,所以技術方的人臉檢測模組,一般可以透過調整引數得到N種亞型,以適應不同應用場景(光照、角度、有效距離、速度) 下對運算量和有效檢測距離的需求。
(4)測試結果——欠擬合
-
定義:模型沒有很好地捕捉到資料特徵,不能夠很好地擬合資料


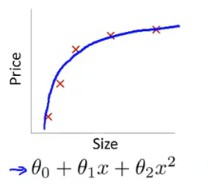
左圖表示size與prize關係的資料,中間的圖就是出現欠擬合的模型,不能夠很好地擬合資料,如果在中間的圖的模型後面再加一個二次項,就可以很好地擬合圖中的資料了,如右面的圖所示。
-
解決方法
-
新增其他特徵項,有時候我們模型出現欠擬合的時候是因為特徵項不夠導致的,可以新增其他特徵項來很好地解決。例如,“組合”、“泛化”、“相關性”三類特徵是特徵新增的重要手段,無論在什麼場景,都可以照葫蘆畫瓢,總會得到意想不到的效果。
-
新增多項式特徵,這個在機器學習演演算法裡面用的很普遍,例如將線性模型透過新增二次項或者三次項使模型泛化能力更強。例如上面的圖片的例子。
-
減少正則化引數,正則化的目的是用來防止過擬合的,但是現在模型出現了欠擬合,則需要減少正則化引數。
-
嘗試非線性模型,比如核SVM 、決策樹、DNN等模型。
(5)測試結果——過擬合
-
定義:模型把資料學習的太徹底,以至於把噪聲資料的特徵也學習到了,這樣就會導致在後期測試的時候不能夠很好地識別資料,即不能正確的分類,模型泛化能力太差。例如下麵的例子。


上面左圖表示size和prize的關係,我們學習到的模型曲線如右圖所示,雖然在訓練的時候模型可以很好地匹配資料,但是很顯然過度扭曲了曲線,不是真實的size與prize曲線。
-
解決方法
從產品角度:
-
重新清洗資料,導致過擬合的一個原因也有可能是資料不純導致的,噪音太多影響到模型效果,如果出現了過擬合就需要我們重新清洗資料。
-
增大資料的訓練量,還有一個原因就是我們用於訓練的資料量太小導致的,訓練資料佔總資料的比例過小。
從演演算法角度:
-
交叉檢驗,透過交叉檢驗得到較優的模型引數;
-
特徵選擇,減少特徵數或使用較少的特徵組合,對於按區間離散化的特徵,增大劃分的區間;
-
正則化,常用的有 L1、L2 正則。而且 L1正則還可以自動進行特徵選擇;
-
如果有正則項則可以考慮增大正則項引數 lambda;
-
增加訓練資料可以有限的避免過擬合;
-
Bagging ,將多個弱學習器Bagging 一下效果會好很多,比如隨機森林等.
4.5 標註流程中遇到的問題
(1)專案過程中的不確定性
a. 出現原因:
一般情況下,只要資料標註的規範清晰,對規則的界定從一而終,標註工作的流程還是比較簡單的。
資料標註規範可能會在測試後根據結果情況進行調整,那麼,規則修改前後“資料標註的一致性”就出現了問題,會導致多次返工,在時間和人工成本上頗有影響。
b. 解決方法:
-
1)如是分類性質的解析工作,建議標註規則先從非常肯定的非黑即白開始;規則設定由簡到繁,帶有疑慮資料再另外作記號。隨著規則一步步深入,可能會出現交叉影響,此時就需要放棄一些低頻問題的規則,餘下的未標註的資料就根據新的規則標註。
-
2)如是多類規則同時進行的標註工作,需要把每類規則定得足夠細緻。
-
3)實體:
-
如詢問機器人會幹什麼的語料中出現,“你說你會幹什麼?”可以理解為詢問,也可能是嫌棄,這兩類應對的策略不同,有歧義,所以不能把它歸納如詢問類,需要把它從訓練集裡剔除。
-
如人臉情緒識別中,一個人在流眼淚,有時可以理解為傷心落淚,有時可以理解為喜極而泣,還有時可以理解為激動落淚,甚至是感動落淚等,所以在看到此類照片時,不能簡單的憑藉慣性化思維將其歸納到悲傷一類中,當人眼都很難判別清楚時,需要把它從訓練集裡剔除。
5. 實際案例分析
5.1 某領域的人臉識別監測與身份確認
(1)案例問題
光照影響:過暗或過亮等非正常光照環境,會對模型的效果產生很大幹擾。
(2)解決方案
a. 從產品角度控制
-
在使用者可以更換環境的前提下(比如銀行刷臉取錢等),可語音/介面提示使用者目前環境不理想(頭歪、頭髮、眼鏡等),建議進行正確的正臉取照。
-
在使用者不能控制更換環境的情況下(比如人臉識別、車輛識別等攝像頭固定的場景),只能透過除錯硬體設施彌補這個問題。
-
晚上:由於攝像頭在晚上會自動切換到黑夜場景(從圖片上看就是從彩色切換為黑白),因此在晚上強光下(例如路燈照射)人臉就會過曝,這時,我們可以透過強制設定攝像頭環境為白天(影象為彩色)來避免。而過暗的情況,從節省成本角度看,可以在攝像頭旁邊增加一個光線發散、功率不高的燈來彌補。當然這兩個問題也可以透過購買高質量的攝像頭解決,但這樣做也意味著更高的成本。
-
白天:白天也會出現光線過亮的情況,這種情況可以考慮用濾光片等等。
b. 從演演算法角度控制
用演演算法將圖片進行處理,可以將圖片恢復得讓人眼看清的程度。
5.2 某款人臉年齡識別產品
(1)案例問題
一款識別人臉年齡的產品對女性某個年齡階段(25—35)的判斷,誤差較大,經過發現,是因為該年齡階段有以下特點:
-
女性在這個年齡階段面貌變化不是很大,有時人眼給出的判斷誤差都很離譜。
-
在這個年齡層次的女性註重打扮,化妝品很大程度上掩蓋了其真實年齡,有時30多的跟20歲沒多大差別;C. 精裝打扮的和素顏的差別不是很大。
(2)解決方案
-
補充資料:針對該年齡層次的人臉圖片資料做補充。不僅補充正例(“XXX”應為多少歲),還應補充負例(“XXX”不應為多少歲)。
-
最佳化資料:修改大批以往的錯誤標註。
-
資料總結:對化妝和不化妝的人臉圖片進行分析,以便調整演演算法引數。
(3)需求研究
-
自拍:如女性群體一般都希望自拍時,年齡的判別在心裡預期中能越小越好,當在和一群人自拍中可以適當的將主人公的年齡判別結果調低至達到使用者心理滿足感。此時可適當降低演演算法的參照度。
-
婚戀交友:在婚戀網站交友過程中,雙方都希望知道彼此的真實年齡資訊,此時運用人臉年齡識別可以分析雙方的年齡、面板等物理資訊為彼此提供參考。此時的資訊就不能以達到心理滿足感為主了,應當追求準確度。
5.3 某款AR美顏相機
(1)無法定位出人臉
在背景出現多人或寵物時,相機有時並未能精確定位出標的使用者,而定位到背景圖片中的人、寵物、身旁的其他人;有時螢幕一片漆黑;有時顯示未檢測出人臉。
-
從產品角度:介面提醒使用者遠離複雜背景,或美顏時最好螢幕中只出現一人,或給出方框圖讓使用者自己手動選擇主要定位區域進行AR美顏;螢幕一片漆黑時可提醒使用者是否是光線太暗,或是攝像頭被障礙物遮擋等;
-
從演演算法角度:可對人臉關鍵點進行定位,計算標的使用者與攝像頭的距離或計算人臉在頻幕的區域佔比來確定標的使用者(一般幾何距離近的、頻幕區域佔比較大的為美顏標的),結合活體檢測來排除背景圖片人物的幹擾等。
(2)影象模糊昏暗
光線太暗、運動、對焦等造成模糊(攝像頭距離因素,造成影象低頻存在,高頻流失等)
-
從產品角度:可提醒使用者在光線較溫和的區域進行美顏操作;或是擦除前置攝像頭的障礙物;或文字提示動作太快;或是更換高畫質前置攝像頭;或提示對焦失敗,給與對焦框圖讓使用者手動對焦等。
-
從演演算法角度:在美顏前可在後臺中調取手機亮度調節功能,用演演算法調節光線的亮暗程度以適應美顏所需的物理條件;用演演算法設法補齊高頻部分從,而減少對照片的幹擾。
(3)人臉關鍵動作抓捕太慢
在進行AR美顏搞怪時(如張嘴動作,螢幕出現音符、唾沫星子等)對動作抓捕太慢(半天才抓捕到張嘴動作)。
-
從產品角度:文字提示不支援快速移動或提示緩慢移動(如,親!您的動作太快了,奴家還未反應過來等)
-
從演演算法角度:人臉姿態估計、關鍵點定位來捕捉人臉動作。
(4)關鍵位置新增虛擬物品失敗(如在嘴上叼煙、耳朵弔耳環、眼鏡戴墨鏡、臉顯紅暈)
-
從產品角度:文字/圖片提醒使用者擺正人臉位置。
-
從演演算法角度:可利用演演算法對人臉關鍵區域進行分割並定位,來達到人臉精準定位新增虛擬物品
5.4 人臉開門和人臉檢索
(1)人臉開門等跨網方案需要關註的因素
-
遠端演演算法更新:遠端演演算法更新必然會造成本地區域網功能暫時性無法使用。因此遠端演演算法更新的頻率、時間、更新效果都需要產品在更新前精確評估。
-
增刪改人臉資料與本地資料的同步:本地區域網和網際網路是無法直接互動的,因此使用者在網際網路一旦對人臉資料庫進行增刪改的操作,下發程式的穩定性和及時性都需要重點關註。
-
硬體環境:本地儲存空間的大小和GPU直接影響到本地識別的速度。伺服器的穩定性影響到功能地正常使用。
-
守護程式:斷電等外接情況意外情況發生又被處理完善後,程式能自動恢復正常。
(2)人臉檢索等某一區域網方案需要關註的因素
-
速度:除了演演算法識別需要消耗一定時間外,該區域網下的網速會影響到識別結果輸出的速度。
-
資料庫架構:透過檢索結果關聯結構化資料。
-
閾值的可配置性:在介面設定閾值功能,從產品層面輸入閾值後,改變相對應的結果輸出。
-
輸出結果排序:根據相似度排序或結構化資料排序內容地抉擇
-
雲服務的穩定性。
5.5 曠視科技官網產品體驗(多圖預警)
(1)年齡略有差距,自我估計+-5,性別基本無誤,頭部狀態略有誤差,人種誤差在30-40%(樣本量10,白種人和黃種人誤差明顯),情緒基本無誤,眼鏡種類識別有誤差(商品識別的範疇),強光狀態下表現不佳。

(2)邏輯錯誤:左眼(睜眼、普通眼鏡)、右眼(墨鏡);相似度大(下圖為張一山和夏雨)的較難區分(雙胞胎估計很難區分)
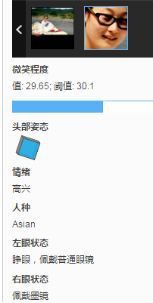
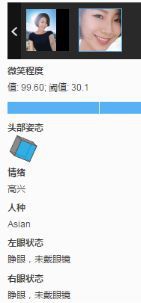

(3)遠距離檢測較難:左圖檢測出一張,右圖檢測出兩張(估計10米開外檢測不到)


(4)能夠識別蠟像、海報等非真人場景,因此在一些場合可欺騙攝像頭,如在金融領域裡的身份識別,海關檢查等關鍵性應用中,將會有風險。



(5)佩戴的口罩無法檢測出人臉

(6)公司體驗對比結果

6. 專案虛擬實戰(以AR美顏APP為例,過程為理論經驗推理所得,自己並未實習)
人臉檢測系統下,有很多FR相關的應用,比如人臉屬性識別(年齡、表情、性別、種族等)、人臉美顏/美妝、人臉聚類等等。我們從AR美顏/美妝這一個例子著手,探索專案的具體流程。
6.1 專案前期準備
(1)需求調研
場景及痛點:現在大多數美顏相機拍照後,都只有新增各種濾鏡、加幾個字、變白一點,早已經不能滿足廣大女性群體對於美顏的需求;加上如今年輕女性和男性的審美標準和獵奇心理都在發生改變,社交方式的趣味性也變得不同,比如原來大家可能在空間、朋友圈、直播上看到美女帥哥都會覺得很吸睛,點贊粉絲直奔而來,但隨著快手和抖音的出現,可以發現不僅僅是俊男靚女的照片和影片能引起圍觀,同樣的各種普通群眾的搞怪合成影片或合成照片(虛擬的AR特效帶來的各種浮誇造型)同樣能吸引無數粉絲的追捧,讓普通人也能享受被人膜拜的滿足感,而這些都需要用到人臉識別的相關技術。
(2)標的使用者畫像分析
-
瞭解標的使用者的主流群體:學生(大學生、高中生、初中生)群體對月美顏美妝的心理需求、時尚人士的美妝需求、長相普通的人和長相突出的人對於美顏的心理需求等。
-
瞭解使用者的年齡組成、地域分佈對應美妝的特點。
-
不同收入群體(白領、金領、藍領等)的美顏美妝需求關註點。
(3)市場分析
美顏美妝的市場規模,產業鏈,潛在的邊際效應利益等。
6.2 檔案準備
(1)需求檔案
詳細的分析目前的使用者需求,針對不同群體,設計不同的產品解決方案,包括市場的需求檔案。
(2)資料檔案
前期的人臉圖片收集、分發、標註總結檔案(確定什麼樣的圖片能要,什麼樣的不能要),各種臉型(長的、寬的、圓的、前額凸出的、眼睛深陷的等等)的分類,多少人完成眼睛美顏圖片的分類等。
(3)產品檔案
-
場景落地檔案:如聽歌時頭上戴虛擬耳機,嘆氣時嘴上叼煙,說話時唾沫星子等針對不同的人臉姿態場景研究可能的落地產品形式。
-
產品的設計檔案:如美顏APP的頁面互動設計、導航設計、視覺呈現設計等;直播APP中的彈幕呈現設計、點贊分享按鈕設計等。
-
產品開發流程檔案:如PM先提交需求、可行性分析、立項、設計流程、開發流程,演演算法搭建、模型訓練、測試訓練等一系列流程的步驟及跟進。
-
模型訓練及測試檔案:資料標註好後,喂給演演算法,搭建人臉識別美顏的模型框架,如前期用成千上萬的照片訓練機器的人臉關鍵點定位,讓機器找準鼻子、眼睛、耳朵、嘴等位置等。
6.3 資料標註
(1)資料圖片的採集
在檔案的指引下,從公開網站上爬取收集符合模型訓練的人臉圖片、或是運用公司的資料圖片等
(2)資料圖片的標註
在標註規範檔案的指引下,將圖片分發給標註團隊進行資料的標註,對一些模稜兩可的圖片,如圖片中的人臉較模糊,此時該照片是要還是不要,期間應與演演算法同事保持溝通,有時暗的圖片在演演算法的最佳化中能準確識別,這樣增加實際情況的容錯率(實際中較暗的人臉影象也能定位出關鍵部位),那麼這張圖片則視為有效資料;有時較暗的圖片經過演演算法之後並不能達到要求(及無法定位出人臉關鍵點),此時這照片則視為無效資料,直接剔除;但是標註團隊並不知道這張圖片是有效還是無效,所以標註過程中,演演算法同事也需間接參與進來。
(3)資料的反饋
在部分圖片標註過程後,交於演演算法同事訓練模型調節引數,期間將測試後的資料(精確率和召回率的計算,來反映資料的標註結果)反饋給還在標註的人員,有時可能造成過擬合有時可能造成欠擬合等方便對資料進行重新操作。
6.4 專案流程跟蹤
(1)產品立項後,每天的任務管理,流程進度跟蹤,產出時間管理,開會反饋工作成果等。
(2)軟硬體端:在開發流程檔案的指引下,按照常規的軟硬體跟蹤開發。
(3)演演算法流程:人臉採集、人臉檢測、影象的預處理(模糊的則用演演算法去模糊等)、人臉特徵提取、影象的匹配識別、AR虛擬等。
6.5 專案測試
-
手機攝像頭測試
-
平臺後臺程式測序
-
演演算法與平臺後臺測試
-
模型識別時間、準確率、召回率測試
-
伺服器穩定性測試
-
網路頻寬限制測試
-
其他平臺、硬體產品常規測試
-
標的使用者使用測試
6.6 專案最佳化
經過各種測試之後,針對反饋回來的資料進行產品的最佳化。
如一張嘴就給你來根煙,結果煙插到鼻子上了,這就明顯是沒有定位到人臉關鍵點,是資料的原因還是演演算法的原因,這些都要經過最佳化處理;經過種子使用者測試後,反饋得知這個點贊按鈕操作起來有點彆扭,應該怎樣怎樣,這時可能要與設計的同學討論一下,該怎樣最佳化產品的設計和體驗。
6.7 專案驗收上線
產品按照流程功能進行驗收後上線。
06 FR的個人看法
1. 人臉識別的現狀
1.1 實驗室效果和現實效果對比,差距巨大
現如今的人臉識別技術在金融、安防等領域的應用實際上的效果要比實驗室裡的差很多,前陣子西安的某高校引入人臉識別晨讀打卡,由於反應速度太慢,到中午還排著很長的隊。可見實際生活中,由於各種物理因素(光照、角度、對焦、人魚攝像頭的距離等)導致抓拍的圖片質量比較差,又經過網路傳輸到區域網/網際網路進行對比(網路差的過程中,反應很慢),使得實際效果大打折扣。大多數情況下,實際抓拍影象質量遠低於訓練影象質量。
1.2 訓練時的標準和實際應用的標準
大多數情況下,實際應用的標準會遠高於訓練標準。例如,人臉識別實驗室的標準是透過正臉資料訓練出模型,能識別正確人臉就可以。而實際情況可能沒有正臉資料,對訓練提出了更高的要求。
1.3 訓練效果和現實效果
大多數情況下,實際效果會遠低於訓練效果。現在市面上CV公司都是說自己的訓練效果在99%以上(無限接近於100%),但這不等於實際應用的效果就是99%。工業上場景複雜的人臉應用(類似識別黑名單這種1:N的人臉比對)正確率在90%以上就已經是表現得很好的演演算法模型。
2. 未來發展趨勢的思考
隨著人工智慧的火熱和發展,在全球資訊化、雲端計算、大資料的背景下,生物識別技術的應用面會越來越大,由以人臉識別為其中代表。以下幾個發展趨勢呈現:
-
網路化趨勢:人臉識別解決了日常生活中一個基本的身份識別問題,今後,這總身份認證的結果會越來越多的和各行各業應用結合起來,並透過網際網路和物聯網得以資訊共享,簡單來說就是“身份識別+物聯網”的發展趨勢未來將十分普遍。
-
多生物識別樣式融合趨勢:人臉識別技術現如今的還達不到人類的預期體驗,對於一些安全性要求高的特殊行業應用,如金融行業,人臉識別很容易被不法分子攻破漏洞進行身份造假,因此需要多種生物特徵識別技術的融合應用(如活體檢測、虹膜識別等)以進一步提高身份識別的整體安全性。
-
雲技術:未來的雲技術也將大大給人臉識別的應用提供資料和計算力支援,基於雲技術的門禁控制可以同時管理成百上千的通道,加上物聯網的普及,使用者對任何地方的門禁進行遠端控制和管理,準確識別本人,將廣泛應用到企業、學校、培訓機構、大型商業場合、辦公大樓的門禁解決方案。
3. 盈利樣式的思考
(1)單一盈利樣式
現如今的人臉識別技術服務商,都以將技術接入第三方應用軟體,或是搭載在智慧終端上,透過收取一定技術服務費來獲取盈利。目前國內的第一梯隊創業公司都在技術和資料上沉澱,而是否盈利,盈利多少都還尚不明確。
如在金融領域,人臉識別用於身份確認,然而身份確認之後,就沒你什麼事,你跟使用者的關係只在於,開啟某款APP或某個終端場景(閘機)的鑰匙,開啟之後,使用者的所有行為都沉浸在APP中,並沒有給FR技術服務商帶來其他的使用資料及使用者行為資訊;從根本上來看,使用者只是用鑰匙開了門,而往往是門裡面的東西(使用者資料)才能帶來商業價值。
(2)對比網際網路和移動網際網路
-
網際網路時代早期有很多功能性的產品。如早年間的QQ只有聊天的功能;360使用者只是用它來給電腦殺防毒;百度就是個即問即答的老師;搜狐、新浪也就是用來看看新聞而已。
-
移動網際網路時代也有很多這樣的產品。滴滴幫使用者叫個車;高德也就差不多是古代的指南針。
-
案例分析:眾所周知,上面舉的例子不是網際網路時代的高市值企業,就是移動網際網路時代高融資率的企業。
-
QQ後來使用者數越來越多,QQ號成網路身份的一個必不可少的身份屬性之一,使用者大量的資料沉澱在其中,透過使用者的使用行為資訊,小馬哥知道了這麼多人都用我的QQ,那趕緊搞個什麼娛樂活動,讓有QQ號的人都來玩,於是就有了龐大的遊戲帝國產業,遊戲裡面又加上各種鑽(什麼粉鑽、綠鑽、紫鑽、黑鑽)對應的各種會員機制,QQ號又以其他的方式來獲取使用者的行為資訊如,QQ音樂(下歌要錢、換面板要錢)、騰訊影片(各種廣告收入、會員充錢等)、QQ郵箱(會員高階功能)等,讓人們越加沉浸在QQ帝國的生態圈中,莫名其妙的就被吸走了很多錢。可能你會說我還可以用其他的呀,但是好煩啊,這個也要註冊,那個也要註冊,明明一個QQ號可以玩轉所有,沒辦法我就是這麼懶,所以說懶人創造了這個世界的絕大多數科技產品。
-
滴滴現如今估值幾百億美刀,投資人為何給一個只幫你叫車的公司如此高的估值,我們知道滴滴打車比一般的直接叫車要便宜一點點(專車除外),那它的盈利點從而來,投資人有看中了它的哪一點。其實不難理解,滴滴之所以有如今的估值,正因為其幾乎壟斷了國內的打車市場,大量的使用者使用它,必然就會有使用者的使用資料,而這些資料便是變現的好東西,一旦整個生態搭建完畢,未來滴滴就將這些資料用無人駕駛方面,一旦搶佔了市場的制高點,未來在行業鏈上就有絕對的議價能力。比如現在人們已經習慣了去一個陌生地方,就來一個滴滴打車,若滴滴突然漲價,一公里漲幾毛或一元,你用它還是不用;心理學表明,人養成一個習慣之後,就會有慣性,對於沒有超出心理承受預期的東西(不是漲價漲得特別離譜),人們會一直保持這個習慣中的一些行為,而不願做出改變(也就是常說的人有一種惰性)。因此我想大多數人都會去接受,因為可能你花時間自己打車也是需要很多成本的;使用者基數比較大,那這個漲了幾毛的就會帶來不少的盈利空間(中國十幾億人口,一人給我一毛錢,我都能成為億萬富翁了,但對別人而言,一毛錢可能連袋辣條都買不到),這還只是一方面。
d. 人臉識別作為一種技術,並沒有實際的產品承載點。以上分析中的種種產品,你都能叫出來名字,是因為這些功能或是技術都有一個實際的產品承載點,比如QQ用了即時通訊技術,頭條背後的智慧推薦用了機器學習相關技術,但在我們心目中它不是以一種技術停留在我們的心智空間裡,它是一款實實在在的產品,我們可以操作它,使用它。無論是QQ還是滴滴、高德、今熱頭條、新浪等等,這些產品我們都能實實在在的接觸到,並且後續行為都在這個技術的承載點裡(如即時通訊技術的產品承載點是QQ,機器學習技術的產品承載點是頭條),那麼使用者的資料自然也就在產品承載點之中,這樣我們才能應用資料來創造價值,從而實現盈利。
e. 人臉識別目前的階段停留在大眾視野裡只是一種技術,人們的潛意識裡並沒有建立起一個概念,那就是這個人臉識別到底是個什麼東西,我能操作它嗎?它能給我帶來什麼呢?而一旦人臉識別有一個產品承載點,讓使用者能實實在在的進行操作,並有資料積累,才會有盈利的可能。而人臉識別的產品承載點是什麼,目前還都沒有出現,未來肯定會有,這也是未來的一大機會,無論是什麼,這個產品必然都能被使用者實實在在的接觸到,並且後續也都將在其中產生行為,後者是必要條件。
4. 資訊保安的思考
一旦前面提到的產品承載點出現,FR技術必將大行其道,隨之而來的可能是資訊保安問題。
物聯網時代之下,萬物互聯,萬物智慧,FR技術也必將融入到物聯網之中,人們可能都不需要身份類的實物證件。回家開門掃臉,外出開車門掃臉,進公司掃臉,出去吃飯付錢掃臉。當人臉成為你的虛擬證件時,一旦又不法公司、團體、個人洩露或是破解了你的人臉虛擬證件,那麼你的一切資訊可能都暴露在他人面前,財產、房子、車子可能都有風險,還有可能因為丟失人臉證件,將無法證明你自己的身份,就像你丟了身份證一樣。可想而知資訊保安的重要性,未來估計會誕生一個虛擬身份資訊系統,裡面有每一個人的身份資訊,當第三方需要身份認證時,可接入系統等。前陣子臉書因為社交資訊洩露而惹上眾怒引起公關麻煩。我想未來如果有一個公司專門負責使用者資訊資料的監管,我也不會覺得很奇怪的。
5. 產品形式的思考
-
可接觸性:無論FR技術最終是以硬體還是軟體方式出現在使用者面前,前提是使用者能夠實際的接觸到,而不是彷彿在雲端不可觸控,只有使用者接觸了,才能在心裡產生出它是一款產品,而不是一項技術的概念。如AR美顏就是實實在在可操作的產品。
-
連續使用性(高頻性):產品必須是使用者能連續使用的,也就是所謂的高頻性,只有這樣才能產生可利用的資訊資料來變現。
-
功能承載性:產品要能以一種功能的方式為使用者解決生活中的某一類問題。人臉除了身份認證(金融行業、安防門禁)、視覺欣賞(美顏美妝、整容)、社交評判依據(婚戀網站)還能用來乾什麼呢?
-
To C or To B:結合網際網路時代的發展,我個人始終認為一款產品只有圍繞使用者提供服務,才有可能成就明星產品。從歷史的角度來看,每一個王朝的興衰更替都是以老百姓的意願為轉移,有道是“水能載舟亦能覆舟”。產品亦是如此,產品概念誕生到現在,每一款產品的興衰也都是建立在使用者的基礎之上。任何一款產品拋開使用者之後都只能死亡,儘管目前FR大層面上應用在B端,但是未來成功的FR應用產品必然是誕生在C端。
下麵附上總結這篇系列文章的思路導圖:
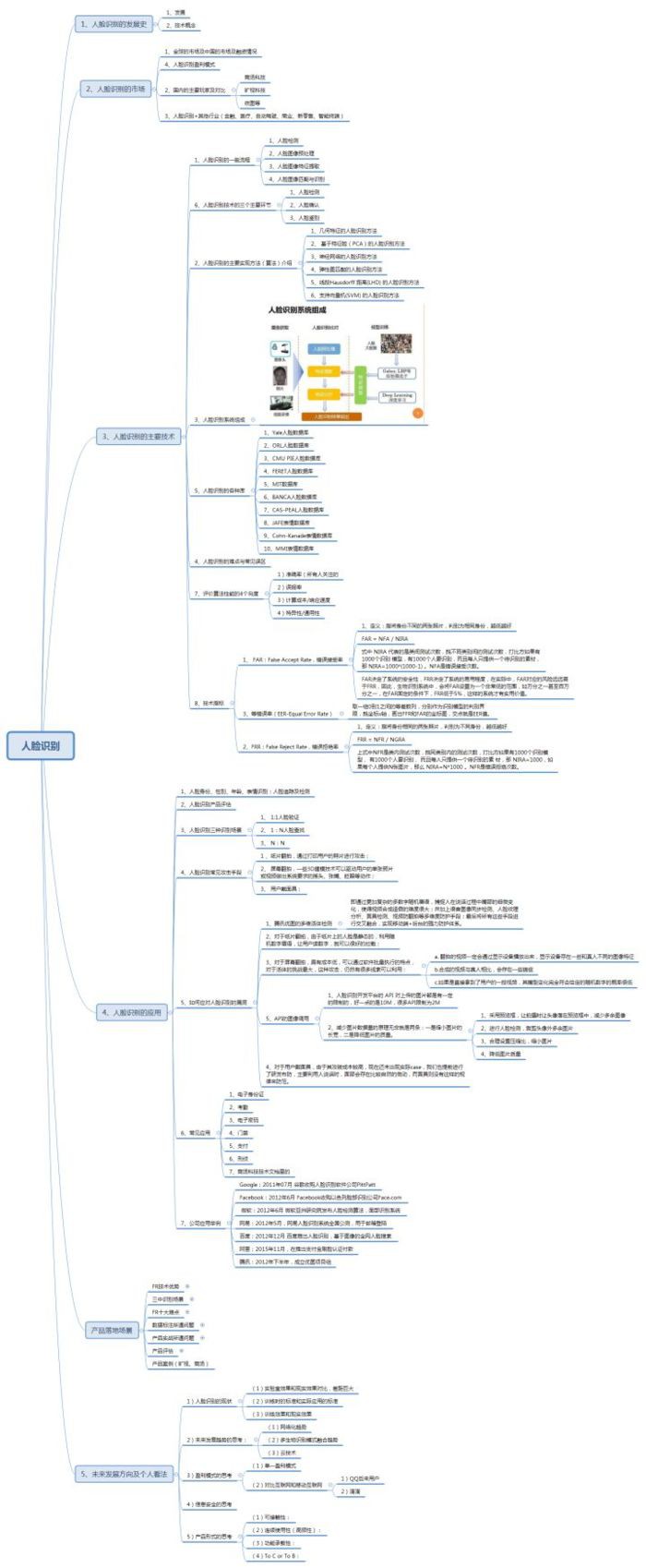
大圖地址:
https://upload-images.jianshu.io/upload_images/8484039-397ceeedb8b3d438.png
作者:放飛人夜
原文連結:
https://www.jianshu.com/p/639e3f8b7253

更多精彩
在公眾號後臺對話方塊輸入以下關鍵詞
檢視更多優質內容!
PPT | 報告 | 讀書 | 書單 | 乾貨
Python | 機器學習 | 深度學習 | 神經網路
區塊鏈 | 揭秘 | 高考 | 福利
猜你想看
Q: 人臉識別的機遇與問題都有哪些?
歡迎留言與大家分享
覺得不錯,請把這篇文章分享給你的朋友
轉載 / 投稿請聯絡:baiyu@hzbook.com
更多精彩,請在後臺點選“歷史文章”檢視

