接上一篇文章,問題背景描述的差不多了,下麵該解決方案登場了。
編譯器最佳化亂序和CPU執行亂序的問題可以分別使用最佳化屏障 (Optimization Barrier)和記憶體屏障 (Memory Barrier)這兩個機制來解決:
最佳化屏障 (Optimization Barrier):避免編譯器的重排序最佳化操作,保證編譯程式時在最佳化屏障之前的指令不會在最佳化屏障之後執行。這就保證了編譯時期的最佳化不會影響到實際程式碼邏輯順序。
IA-32/AMD64架構上,在Linux下常用的GCC編譯器上,最佳化屏障定義為(linux kernel, include/linux/compiler-gcc.h):
|
最佳化屏障告知編譯器:
-
1.記憶體資訊已經修改,屏障後的暫存器的值必須從記憶體中重新獲取
-
2.必須按照程式碼順序產生彙編程式碼,不得越過屏障
C/C++的volatile關鍵字也能起到最佳化限制的作用,但是和Java中的volatile(Java 5之後)不同,C/C++中的volatile不提供任何防止亂序的功能,也並不保證訪存的原子性。
記憶體屏障 (Memory Barrier)分為寫屏障(Store Barrier)、讀屏障(Load Barrier)和全屏障(Full Barrier),其作用有兩個:
-
防止指令之間的重排序
-
保證資料的可見性
關於第一點,關於指令重排,這裡不考慮架構的話,Load和Store兩種操作會有Load-Store、Store-Load、Load-Load、Store-Store這四種可能的亂序結果。 上文提到的三種屏障則是限制這些不同亂序的機制。
關於第二點。寫屏障會阻塞直到把Store Buffer中的資料刷到Cache中;讀屏障會阻塞直到Invalid Queue中的訊息執行完畢。以此來保證核間各級資料的一致性。
這裡要強調,記憶體屏障解決的只是順序一致性的問題,不解決Cache一致性的問題(這是Cache一致性協議的責任,也不需要程式員關註)。Store Buffer和Load Buffer等元件是屬於流水線的一部分,和Cache無關。這裡一定要區分清楚這兩點,Cache一致性協議只是保證了Cache一致性(Cache Coherence),但是不關註順序一致性(Sequential Consistency)的問題。比如,一個處理器對某變數A的寫入操作僅比另一個處理器對A的讀取操作提前很短的一點時間,那就不一定能確保該讀取操作會傳回新寫入的值。這個新寫入的值多久之後能確保被讀取操作讀取到,這是記憶體一致性模型(Memory Consistency Models)要討論的問題。
完全的確保順序一致性需要很大的代價,不僅限制編譯器的最佳化,也限制了CPU的執行效率。為了更好地挖掘硬體的並行能力,現代的CPU多半都是介於兩者之間,即所謂的寬鬆的記憶體一致性模型(Relaxed Memory Consistency Models)。不同的架構在重排上有各自的尺度,在嚴格排序和自由排序之間會有各自的偏向。偏向嚴格排序的一邊,稱之為強模型(Strong Model),而偏向於自由排序的一邊,稱之為弱模型(Weak Model)。AMD64架構是強模型:
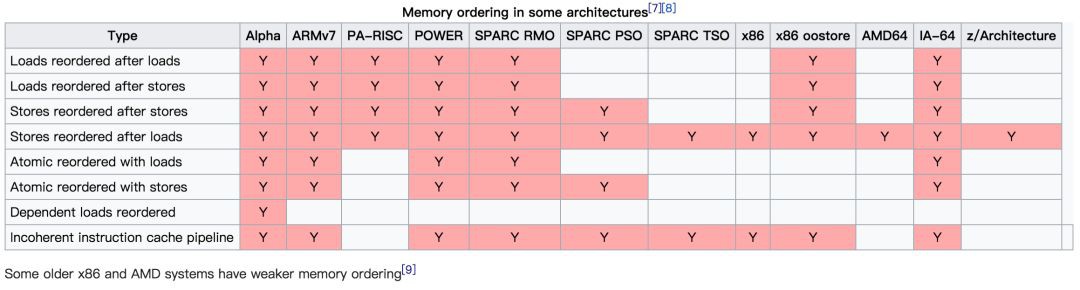
特別地,早先時候,AMD64架構也會有Load-Load亂序發生(Memory Ordering in Modern Microprocessors, PaulE.McKenney, 2006)。

註意這裡的IA-64(Intanium Processor Family)是弱模型,它和Intel® 64不是一回事。後者是從AMD交叉授權來的,源頭就是AMD64架構。這裡不討論歷史,只需要知道平時說的x86-64/x64就是指的AMD64架構即可。
《Intel® 64 and IA-32 Architectures Software Developer’s Manual》有如下的闡述:

簡單翻譯一下:
讀操作之間不能重新排序
寫操作不能跟舊的讀操作排序
主存寫操作不能跟其他的寫操作排序,但是以下情況除外:
帶有CLFLUSH(失效快取)指令的寫操作
帶有non-temporal move指令的流儲存(寫入)(MOVNTI, MOVNTQ, MOVNTDQ, MOVNTPS, 和 MOVNTPD,都是SSE/SSE2擴充套件的指令)
字串操作(REP STOSD等)
不同記憶體地址的讀可以與較早的寫排序,同一地址的情況除外
對I/O指令、鎖指令、序列化指令的讀寫不能重排序
讀不能越過較早的讀屏障指令(LFENCE)或者全屏障指令(MFENCE)
寫不能越過較早的讀屏障指令(LFENCE)、寫屏障指令(SFENCE)和全屏障指令(MFENCE)
讀屏障指令(LFENCE)不能越過較早的讀
寫屏障指令(SFENCE)不能越過較早的寫
全屏障指令(MFENCE)不能越過較早的讀和寫
在多處理器的情況下,單處理器內部的記憶體訪問排序仍然依照以上的原則,並且規定處理器與處理器之間遵循如下的原則:
某個處理器的全部寫操作以同樣的順序被其它處理器觀察到
不同處理器之間的寫操作不重排序
排序遵循邏輯上的因果關係
第三方總是觀察到一致的寫操作順序
那麼上文提到的四種可能的亂序在AMD64下明確說明不會有Load-Load亂序、Load-Store亂序,明確會出現Store-Load亂序,Store-Store亂序除了幾種例外的情況也不會出現。參考文獻5中給出了在Linux下重現出Store-Load亂序的程式碼,有興趣的讀者可以自行測試。
但是記憶體一致性模型不僅僅是沒有指令重排就會保證一致的。但是如果僅僅只考慮指令重排,完全按照該規則來思考,就會遇到違反直覺的事情。特別的,在對寫快取的同步處理上,AMD64記憶體訪問模型的 Intra-Processor Forwarding Is Allowed這個特性比較要命:

只考慮指令重排的話,AMD64架構既然不會有Load-Load重排的,r2=r4=0就不可能會出現,但是實際的結果是違反直覺的。出現這個現象的原因就是Intel對Store Buffer的處理上,Store Buffer的修改對其他CPU核心是不可見的。Processor 0對_x的修改快取在了Processor 0的Store Buffer中,還未提交到L1 Cache,自然也不會失效掉Processor 1的L1 Cache中的相關行。Processor 1對_y的修改同理。
對於以上問題,AMD64提供了三個記憶體屏障指令來解決:

sfence指令為寫屏障(Store Barrier),作用是:
-
保證了sfence前後Store指令的順序,防止Store重排序
-
透過掃清Store Buffer保證sfence之前的Store要指令對全域性可見
lfence指令讀屏障(Load Barrier),作用是:
-
保證了lfence前後的Load指令的順序,防止Load重排序
-
掃清Load Buffer
mfence指令全屏障(Full Barrier),作用是:
-
保證了mfence前後的Store和Load指令的順序,防止Store和Load重排序
-
保證了mfence之後的Store指令全域性可見之前,mfence之前的Store指令要先全域性可見
如前文所說,AMD64架構上是不存在Load-Load重排的,但是當一個CPU核心收到其他CPU核心失效Cache Line的訊息後,立即回覆給對方一個應答訊號。但是此時並沒有立即失效掉Cache Line,而是將其包裝成一個結構投遞到自身的Load Buffer裡。AMD64架構上不存在Load-Load重排並不意味著流水線真的就一條一條執行Load指令。在保證兩個CPU核看到的Store順序一致的情況下,是允許Load亂序的。比如連續的兩個訪存指令,指令1 Cache Miss,指令2 Cache Hit,實際上指令2是不會真的等待指令1的Load完成整個Cache替換過程後才執行的。實際流水線的實現中,Load先是亂序執行,然後有一個Load-ordering-Buffer(Load Buffer)的結構,在Load Commit之前檢測衝突,Load過的地址是否又被其他CPU核心寫過(沒有存在失效資訊)。只要沒有衝突,這種亂序就是安全的。如果發生衝突,這種亂序就違反x86要求,需要被取消並Flush流水線。而上文提到的lfence指令會掃清Load Buffer,保證當前CPU核心立即讀取到最新的資料。
另外, 除了顯式的記憶體屏障指令,有些指令也會造成指令保序的效果,比如I/O操作的指令、exch等原子交換的指令,任何帶有lock字首的指令以及CPUID等指令都有記憶體屏障的作用。
說了這麼多,環形佇列(Ring buffer)在IA-32/AMD64架構上到底怎麼實現才能保證安全?Linux Kernel裡的KFIFO的實現可以拿來參考(include/linux/kfifo.h):
現可以拿來參考(include/linux/kfifo.h):
|
程式碼中的smp_wmb()、smp_rmb()和smp_mb()在AMD64架構上分別對應sfence、lfence、mfence指令。但是Linux Kernel的程式碼要相容所有的SMP架構,還要考慮很多弱記憶體模型的架構。所以這裡的記憶體同步操作很多,但是不一定在AMD64上是必要的。當然,如果要考慮跨平臺跨架構的程式碼,這樣做是最保險的(另外Linux Kernel 4.0上KFIFO這個資料結構變化很大,記憶體同步操作也僅剩下smp_wmb(),這個還沒顧得上研究)。
如果IA-32/AMD64架構下,Ring Buffer如果要實現單Reader和單Writer不需要記憶體同步,需要滿足哪些特性呢?
以下麵的定義為例:
structring_buffer {
uint32_tread_index;
uint32_twrite_index;
uchar_tbuffer[BUFF_LEN];
};
首先,read_index和write_index的寫入操作必須是原子的,這就要求這兩個變數本身在P6 Family及以後的CPU上至少是不能跨Cache行的。同時如果是32-bit的變數則P6之前的CPU還要保持32-bit位元組對齊,如果是64-bit變數在IA-32上無法保障(IA-32下64bit的變數Store操作不是原子的)。另外,為了避免False Sharing,這兩個變數最好按照Cache行對齊,即:
structring_buffer {
uint32_tread_index __attribute__ ((aligned(64)));
uint32_twrite_index __attribute__ ((aligned(64)));
uchar_tbuffer[BUFF_LEN];
};
然後在入隊和出隊的地方插入編譯屏障禁止掉編譯器最佳化,根據Intel的檔案,就能保證不會出現亂序問題:
主存寫操作不能跟其他的寫操作排序,但是以下情況除外:
帶有CLFLUSH(失效快取)指令的寫操作
帶有non-temporal move指令的流儲存(寫入)(MOVNTI, MOVNTQ, MOVNTDQ, MOVNTPS, 和 MOVNTPD,都是SSE/SSE2擴充套件的指令)
字串操作(REP STOSD等)
在多處理器的情況下,單處理器內部的記憶體訪問排序仍然依照以上的原則,並且規定處理器與處理器之間遵循如下的原則:
某個處理器的全部寫操作以同樣的順序被其它處理器觀察到
第三方總是觀察到一致的寫操作順序
至於串操作,對buffer的修改可能是memcpy之類的操作,而對index的操作是普通賦值。memcpy在某些庫中的實現使用了串操作指令又會怎樣?會導致Store操作亂序嗎?Intel有如下的說明:

所以不擔心index的修改出現在rep:stosd之前。但是這樣做是有這樣的前提的,即Reader和Writer當前的修改不需要立即被對方知曉,即允許一段時間內的“不一致”。否則,必然需要記憶體屏障來確保修改操作全域性一致。
以上的結論很容易引起口水仗,所以這裡再次強調該結論只是在AMD64架構下,且不考慮可移植性的情況下成立。但是,按照我個人看法,這幾個屏障指令不見得在所有Intel的CPU上都是有意義的,甚至有些屏障指令在Intel某些CPU上沒有該屏障本身的語意。比如lfence本意是限制Load重排,然而AMD64就沒有Load-Load亂序(記憶體可見性另說)。這幾個屏障指令更像是Intel提供給軟體開發者的一個Interface,在需要加屏障的地方讓開發者加吧。至於實際上需不需要,CPU本身會判斷,如果不需要的話直接由CPU直接NOP掉即可。這也是一種長遠的考慮,那你問我在AMD64架構的CPU上寫程式碼的時候,需要強一致的時候加不加屏障?那當時是要加的。按照Interface寫程式碼是最保險的,萬一Intel以後出一個採用弱一致模型的CPU(替被市場淘汰的IA-64默哀三分鐘),遺留程式碼出點問題就不好了。
下麵說說鎖和原子變數。對於資料競爭(Data Races)的情況,最簡單和最常見的場景就是使用Mutex了,包括並不限於互斥鎖、自旋鎖、讀寫鎖等。拿互斥鎖來說,除了保護臨界區只能有一個執行流之外,還有其他的作用。這裡要引入寬鬆的記憶體一致性模型(Relaxed Memory Consistency Models)中的Release Consistency模型[6]來解釋,這個模型包含了同步操作Acquire和Release:
-
Acquire: 在此操作後的所有讀寫操作必然發生在Acquire這個動作之後
-
Release: 在此操作前的所有讀寫操作必然發生在Release這個動作之前
要註意的是Acquire和Release都只保證了一半的順序:
-
對於Acquire來說,並沒保證Acquire前的讀寫操作不會發生在Acquire動作之後
-
對於Release來說,並沒保證Release後的讀寫操作不會發生在Release動作之前
因此Acquire和Release的組合便形成了記憶體屏障。
Mutex的Lock操作暗含了Acquire語意,Unlock暗含了Release語意。這裡是脫離架構在討論的,在具體的平臺上如果Load和Store操作暗含Acquire和Release語意的話自然保證一致,否則可以是相關的記憶體屏障指令。所以Mutex不僅會保證執行的序列化,同時也保證了訪存的一致性。與之類似,平臺提供的原子變數除了保證記憶體操作原子之外,也會保證訪存的一致性。
GCC提供了Built-in的原子操作函式可以使用,GCC 4以後的版本也提供了Built-in的屏障函式__sync_synchronize(),這個屏障函式既是編譯屏障又是記憶體屏障,程式碼插入這個函式的地方會被安插一條mfence指令。不過GCC 4.4以上才支援mfence,這個問題的討論(bug?)在這裡,Patch在這裡。
實際上無鎖的程式碼僅僅是不需要顯式的Mutex來完成,但是存在資料競爭(Data Races)的情況下也會涉及到同步(Synchronization)的問題。從某種意義上來講,所謂的無鎖,僅僅只是顆粒度特別小的“鎖”罷了,從程式碼層面上逐漸降低階別到CPU的指令級別而已,總會在某個層級上付出等待的代價,除非邏輯上彼此完全無關。另外,Lockfree和Lockless是兩個概念,但這個話題太大,我個人尚且拿捏不住,就此打住。至於工程上,普通的程式員老老實實的用Mutex就好了,普通的計數類場景用原子變數也無可厚非。諸如無鎖佇列這種能明確證明其正確性的資料結構在一些場合也是很有價值的,用用無妨(但是多說一句,CAS這種樂觀鎖在核數很多的時候不見得高效,競爭太厲害的時候總體消耗很可能超出普通的鎖)。但是如果不能做到在任何時候都能想明白順序一致性的話,還是老老實實的用Mutex吧,否則造成的麻煩可比提升的這一點點效率折騰多了。
最後,討論這些問題的文章太多了,各路說法到處飛,我也不敢保證這篇文章的說法全部正確,但至少我覺得是可以自圓其說的。如果你覺得哪裡的描述有問題,不妨一起討論,我們一起糾正這些錯誤的觀點。
文章的撰寫過程中參考了若干資料,下麵列出的參考的資料和文章中,個別文章我只是“部分同意”原作者的觀點,因為取用了作者部分說法,所以一併列出。這不代表我完全同意原作者觀點,具體細節請讀者自行判斷(有了衝突,自然是以Intel最新檔案的說法為準)。
參考文獻
[1] Intel® 64 and IA-32 Architectures Software Developer’s Manual, https://software.intel.com/en-us/articles/intel-sdm
[2] Memory Barriers/Fences, https://mechanical-sympathy.blogspot.jp/2011/07/memory-barriersfences.html
[3] Memory Barriers: a Hardware View for Software Hackers, Paul E. McKenney, Linux Technology Center, IBM Beaverton, https://www.researchgate.net/publication/228824849_Memory_Barriers_a_Hardware_View_for_Software_Hackers
[4] 為什麼程式員需要關心順序一致性(Sequential Consistency)而不是Cache一致性(Cache Coherence)?, http://www.parallellabs.com/2010/03/06/why-should-programmer-care-about-sequential-consistency-rather-than-cache-coherence/
[5] 一個關於Memory Reordering的實驗, http://blog.csdn.net/yxc135/article/details/11747995
[6] 計算機體系結構:量化研究方法, (美)亨尼西 等著, 機械工業出版社, 2012-1-1
[7] http://stackoverflow.com/questions/23603304/java-8-unsafe-xxxfence-instructions
[8] Intel Sandy Bridge Configuration, http://www.7-cpu.com/cpu/SandyBridge.html
[9] Intel’s Haswell CPU Microarchitecture, http://www.realworldtech.com/haswell-cpu/5/
[10] Write Combining, http://mechanical-sympathy.blogspot.com/2011/07/write-combining.html
[11] Memory ordering, https://en.wikipedia.org/wiki/Memory_ordering
(完)
