來自:情情說(微訊號:qingqing_talk)
最近有個需求,要修改現有儲存結構,涉及查詢條件和查詢效率的考量,看了幾篇索引和HBase相關的文章,回憶了相關知識,結合專案需求,說說自己的理解和總結。
部分內容摘錄了幾個博友的文章,最後會給出文章的連結,感謝他們的精彩分析和付出。
會從以下幾個方面介紹:
-
為什麼需要索引
-
索引的類別
-
MySQL索引演化
-
MySQL索引最佳化
-
HBase介紹
-
HBase儲存結構
-
HBase索引介紹
-
業務需求及設計
準備分3篇文章介紹,這篇主要介紹前3小節,理解我們常常說的MySQL索引,第2篇重點介紹索引分析方法和常見索引最佳化,第3篇介紹下業務中使用的HBase。
總體來說,索引是為了提高查詢速度的,當資料量比較大時,從頭到尾依次檢索是無法接受的。另外,儲存的資料會包含多個屬性來描述業務物體,屬性可以連續或分開儲存,分別對應到MySQL和HBase。
以MySQL為例,學生這個物體有學號、姓名、性別、所屬班級等屬性,一般還有個主鍵ID,現在有個需求:查詢學號為002的學生姓名。

資料是儲存在磁碟上的,作業系統讀取磁碟的最小單位是塊,如果沒有索引,會載入所有的資料到記憶體,依次進行檢索,載入的總資料會很多,磁碟IO多。
如果有了索引,會以學號為key建立索引,MySQL採用B+樹結構儲存,一方面載入的資料只有學號和主鍵ID,另一方便採用了多叉平衡樹,定位到指定學號會很快,根據關聯的ID可以快速定位到對應行的資料,所以檢索的速度會很快,因為載入的總資料很少,磁碟IO少。
可見,索引可以大大減少檢索資料的範圍、減少磁碟IO,使查詢速度很快,因為磁碟IO是很慢的,是由它的硬體結構決定的。
下麵,再詳細介紹下磁碟儲存結構和資料定位過程,加深對索引的理解。
硬碟儲存結構
磁碟內部結構如下:

-
很多個碟片被串在一個主軸上,主軸帶著他們快速的旋轉;
-
每個碟片都有很多一圈一圈的磁軌,每個磁軌又分為一個一個的扇區;
-
多個碟片上的同一位置的磁軌組成了一個柱面;
-
每個碟片上都有可以讀寫資料的磁頭;
訪問資料時,可以說:把1柱面,1磁頭,1扇區的資料取出來?
磁碟會把1磁頭挪到1柱面,就是對應的磁軌, 這叫「尋道時間」,然後再旋轉磁碟,讓磁頭指向1扇區,開始讀取資料,這叫「旋轉時間」,轉速快的硬碟能更快的旋轉到特定扇區,所以效能會更好。
結構比較複雜,但作業系統給封裝了,提供了一個叫做邏輯塊的方式,你看到磁碟就是有一個個「塊」組成的,編號為1, 2, 3, ..n,把指定的塊轉化成柱面,磁頭,扇區, 按照上面說的方法尋道,旋轉,讀取資料。
為了方便我們操作,作業系統又進一步抽象,抽象成了檔案,由檔案系統去儲存和讀取資料,我們只需要與檔案打交道,檔案使用inode結構,透過它可以輕鬆的找到這個檔案所使用的所有磁碟塊。

扇區是對硬碟而言,塊是對檔案系統而言,塊是檔案存取的最小單位,一般一個塊由連續的幾個扇區組成。
一個表的資料塊以連結串列的方式串聯在一起,資料以行為單位一行一行的存放在磁碟的塊中。

資料定位過程
以MySQL的B+樹為例,簡單說下幾種常見場景下,資料的定位過程。
第一種場景:索引精確查詢
select * from user_info where id = 23 ;確定定位條件, 找到根節點Page No, 根節點讀到記憶體, 逐層向下查詢, 讀取葉子節點Page,透過 二分查詢找到記錄或未命中。
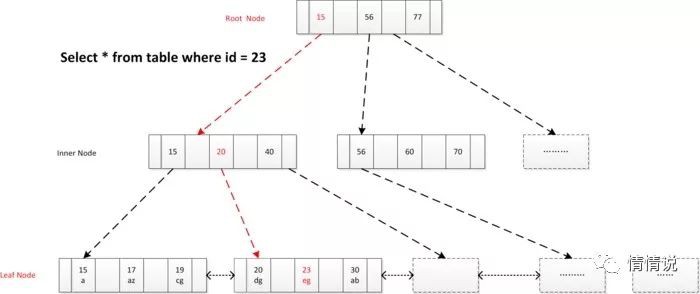
第二種場景:索引範圍查詢
select * from user_info where id >= 18 and id < 22 ;讀取根節點至記憶體, 確定索引定位條件id=18, 找到滿足條件第一個葉節點, 順序掃描所有結果, 直到終止條件滿足id >=22。

第三種場景:全表掃描
select * from user_info where name = 'abc' ;
直接讀取葉節點頭結點, 順序掃描, 傳回符合條件記錄, 到最終節點結束

第四中場景:二級索引查詢
create table table_x(int id primary key, varchar(64) name , key sec_index(name) ) ;
select * from table_x where name = 'd' ;
透過二級索引查出對應主鍵,拿主鍵回表查主鍵索引得到資料, 二級索引可篩選掉大量無效記錄,提高效率

上面介紹了索引的優點和資料的定位過程,對其有了整體瞭解,另外,索引有不同種類和不同的實現方式,這節重點梳理下這些概念。
聚簇索引與非聚簇索引
簡單來說,聚集索引是一種索引組織形式,索引的鍵值邏輯順序決定了表資料行的物理儲存順序,而非聚集索引則就是普通索引了,僅僅只是對資料列建立相應的索引,不影響整個表的物理儲存順序。
聚簇索引的優點有:
-
範圍查詢效率更高;
-
特別適合有一小部分熱點資料頻繁讀寫的場景;
-
透過主鍵訪問資料時快速可達;
InnoDB引擎是聚集索引組織表,它的聚集索引選擇規則是這樣的:
-
首先選擇顯式定義的主鍵索引做為聚集索引;
-
如果沒有,則選擇第一個不允許NULL的唯一索引;
-
還是沒有的話,就採用InnoDB引擎內建的ROWID作為聚集索引;
主鍵索引和輔助索引
主鍵索引,簡稱主鍵,由一個或多個列組成,用於唯一性標識資料表中的某一條記錄。
InnoDB資料表的主鍵設計通常遵循幾個原則:
-
採用一個沒有業務用途的自增屬性列作為主鍵;
-
主鍵欄位值總是不更新,只有新增或者刪除兩種操作;
-
不選擇會動態更新的型別,比如當前時間戳等;
輔助索引,常規所指的索引,也叫二級索引,又分為唯一索引和非唯一索引。
InnoDB引擎中,主鍵索引會被選中作為聚集索引,而唯一索引和普通輔助索引間除了唯一性約束外,在儲存上沒本質區別。
本小節主要介紹索引是如何根據需求一步步演變最終成為B+樹結構,基本思路是減少訪問資料的總量,相應的減少磁碟IO。
密集索引(Dense Index )
根據減少無效資料訪問的原則,我們將鍵的值拿過來存放到獨立的塊中。並且為每一個鍵值新增一個指標, 指向原來的資料塊。

當進行定位操作時,不再進行表掃描。而是進行索引掃描(Index Scan),依次讀出所有的索引塊,進行鍵值的匹配,這樣帶來的問題是需要很多空間來儲存Dense索引。另外索引的定位效率也比較低,可以透過排序和查詢演演算法來減少IO的訪問。
假設一個塊中能儲存100行資料,10,000,000行的資料需要100,000個塊的儲存空間。假設鍵值列(+指標)佔用一行資料1/10的空間。那麼大約需要10,000個塊來儲存Dense索引。因此我們用大約1/10的額外儲存空間換來了大約全表掃描10倍的定位效率。
折半塊查詢
需要對Dense進行索引,每個索引塊內是有序的,另外,需要一個陣列按順序儲存索引塊地址,這樣整體就有序了,陣列也要儲存到磁碟上,放在單獨的塊鏈中。
折半查詢的時間複雜度是O(log2(N)),在上面的列子中,dense索引總共有10,000個塊。假設1個塊能儲存2000個指標,需要5個塊來儲存這個陣列。透過折半塊查詢,我們最多隻需要讀取5(陣列塊)+ 14(索引塊log 2(10000))+1(資料塊)=20個塊。

從圖中可以看到,相對於密集索引,編號是有序的。
稀疏索引(Sparse Index)
介紹基於塊的折半查詢時發現,讀出每個塊後只需要和第一行的鍵值匹配,就可以決定下一個塊的位置(方向)。 因此有效資料是每個塊的第一行資料,將每一個塊的第一行的資料單獨拿出來,和索引陣列的地址放到一起。這樣就可以直接在這個陣列上進行折半查找了,這個陣列就進化成了Sparse Index了。

需要10個塊來儲存10000個Dense Index塊的地址和首行鍵值,透過Sparse索引,僅需要讀取10(Sparse塊)+1(Dense塊)+1(資料塊)=12個塊。
多層稀疏索引
因為Sparse Index本身是有序的,所以可以為Sparse Index再建sparse Index。透過這個方法,一層一層的建立 Sparse Indexes,直到最上層的Sparse Index只佔用一個塊為止。

這個例子中,Sparse Index只有10個塊,只需要再建立一個Sparse Index.透過兩層Sparse Index和一層Dense Index查詢時,只需讀取1+1+1+1=4個塊。
如果資料本身是基於某個Key來排序的,那麼可以直接在資料上建立sparse索引,而不需要建立一個dense索引層(可以認為資料就是dense索引層),這就是說的聚集索引。
B+樹
由於鍵值是有序的,因此可以進行範圍查詢。只需要將資料塊、Dense Index塊分別以雙向連結串列的方式進行連線, 就可以實現高效的範圍查詢。如下圖所示:
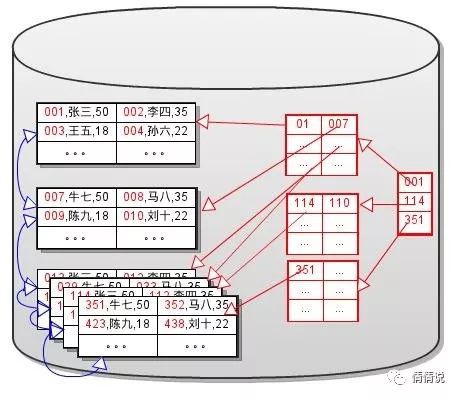
這就是我們常說的B+ Tree,倒過來看下:

最後總結下它的特點:
-
每次進行定位操作時,都從根開始查詢;
-
每層索引只需要讀出一個塊;
-
最底層的Dense Index或資料稱作葉子(leaf);
-
每次查詢都必須要搜尋到葉子節點,才能定位到資料;
-
索引的層數稱作索引樹的高度(height);
-
索引的IO效能和索引樹的高度密切相關,索引樹越高,磁碟IO越多;
-
進行範圍查詢時,效率很高;
參考文章:
-
MYSQL-B+TREE索引原理
-
FAQ系列 | MySQL索引之聚集索引
-
由淺入深理解索引的實現
●編號398,輸入編號直達本文
●輸入m獲取文章目錄

Web開發
更多推薦《18個技術類微信公眾號》
涵蓋:程式人生、演演算法與資料結構、駭客技術與網路安全、大資料技術、前端開發、Java、Python、Web開發、安卓開發、iOS開發、C/C++、.NET、Linux、資料庫、運維等。