機器學習是目前人工智慧最令人激動的研究方向之一。我們可能更關註機器學習演演算法的實現細節,沉浸於機器學習所需要的數學功底,但對於機器學習從業者來說,如何更好更快速的實現一個機器學習專案更值得關註。
正如吳恩達在《機器學習》這門課中所說,他將花費更多的時間來教授機器學習、人工智慧的最佳實踐以及如何讓它們工作。好的工具,在會用和不會用的人之間存在著鴻溝。
當我們做一個機器學習專案時,不糾結於各個模型演演算法的內部細節,從整體的角度看具體問題該如何更可靠更高效得出結論,才不至於浪費更多的時間。從對數學的焦慮中,眾多演演算法的選擇中抽身出來, 去思考以下幾個問題:
-
我們如何在專案中選擇更為合適的演演算法?
-
選擇演演算法之後,如何知道我們的模型是更有用的或更好的?
-
如何進一步最佳化模型以達到更理想的效果?
本文將基於上述幾個問題展開,在此之前,首先明確幾個概念。
機器學習:機器學習是一門涉及多領域,多門學科理論的交叉學科,透過一個程式使其能從已有的經驗中學習,從而能提升對某一項任務的解決能力。
有監督學習:有監督學習是指需要給出一定量的標簽指導計算機去完成任務。就像一個學生需要在老師的教導啟發下進行學習。
如預測房屋的價格,需要預先知道一些房屋的價格以及房屋的有關屬性的資料,對已有資料進行訓練後,得到的模型將會產生對不同屬性房屋特性的價格預測情況。
無監督學習:無監督學習顧名思義是指不需要給定標簽,讓模型自己訓練,得出結論。類似於一個學生透過自己的積累產生對知識的理解。
如有一些房屋的有關屬性的資料, 模型可以自動識別出哪些特徵是屬於市中心的房子, 哪些事屬於郊區的房子,得到的模型可以產生對不同房屋屬性的類別的判斷。
針對具體的問題選擇不同的演演算法。
如一個分類問題可優先選擇邏輯回歸,支援向量機,神經網路等模型,資料集較大的問題優先選擇樸素貝葉斯方法,決策樹和邏輯回歸具有可解釋性。聚類問題我們可能會考慮層次分析,k均值模型。 如果資料集的特徵很多,可以考慮採用主成分分析,線性判別分析等進行降維。

第一步,明確具體問題
明確標的任務,進而實現對演演算法的選擇。
有監督學習主要有回歸和分類任務:
回歸是研究因變數與自變數之間關係的方法。
上文所說的房屋價格的預測的例子就是一個回歸問題,構建房屋價格與房屋其他屬性之間關係的模型, 實現新房屋的價格的預測,我們預測的是一個模型的連續性的值。
分類將資料集按照不同的特點分為不同的類別。
如金融市場中一個常見的預測股價漲跌的示例,給定一段時間內股價的漲跌方向作為模型的輸出,即我們設定的標簽,預測後一段時間股價的漲跌情況,這裡的結果只會有漲和跌兩種情況,預測的是間斷的值。
無監督學習主要有聚類和降維任務:
聚類將資料集分為多個類似的物件組成的多個類。
當我們在網站上搜索一條內容的時候,網站會有相似的內容推薦,這是因為網站透過聚類的方式將有相似瀏覽特徵的客戶聚集在一起共同分析,以便更瞭解客戶。聚類與分類的差別是,分類是我們知道怎樣的特徵能夠屬於一類,並設定了標簽,而聚類分的類別則完全是模型自主切分。
降維的基本原理是將樣本點從輸入空間透過線性或非線性變換對映到一個低維空間,從而降低了原資料集的維度,同時又能儘量減少資料資訊的丟失。經過降維,一方面可以對資料進行視覺化研究,另一方面由於資料量大大減少,將提高機器學習的效率。
第二步,選擇演演算法
明確專案的任務,對演演算法有進一步的瞭解,可以幫助我們瞭解模型的使用細節,以便更快速實現模型。
我們將一些演演算法模型整理成如下思維導圖的形式,並對相關演演算法的基本思想做了簡單闡述。
你可以很快速的瀏覽每個演演算法的核心及應用,在面對實際問題時做出大致的判斷。

我們論述了有關問題的定位以及相關演演算法模型的選擇,但需要註意的是,我們已經針對演演算法模型有一個初步的定位,在實踐過程中仍然需要將實際資料與模型結合考慮。最初嘗試時可以使用較少的資料量快速過濾出一些演演算法,最終選定少數的演演算法進行後續的最佳化。同時,對資料的理解程度也將影響模型的選擇,對資料越熟悉越能夠做出更高效的判斷。
選擇合適的演演算法之後,如何知道我們所設計的模型是有用的或者較好的?
機器學習是利用模型對資料進行擬合,對訓練集進行擬合,訓練模型,對樣本外資料集進行預測。其中模型對訓練集資料的誤差稱為經驗誤差, 對測試集資料的誤差稱為泛化誤差。模型對樣本外資料集的預測能力稱為模型的泛化能力。
過擬合與欠擬合
欠擬合和過擬合都是模型泛化能力不高的表現。欠擬合通常表現為模型學習能力不足,沒有學習到資料的一般規律。而過擬合則是模型捕捉到資料中太多的特徵,以至於將所有特徵都認為是資料的一般規律。如下圖樹葉的示例很形象的表達了欠擬合與過擬合。

我們希望的狀態是模型能訓練出資料的一般規律,既不過擬合,也不欠擬合。如下圖所示,最左側可能是一種欠擬合狀態,擬合的函式和訓練集的誤差較大,最右側是過擬合,擬合的函式與訓練集幾乎完全匹配,這種情況在測試集中結果反而會變差。由此,需要構建評估模型來評估模型的泛化能力,這是檢驗一個模型是否更為有效的方法。

評估方法
將一個模型的訓練集也當作測試集會導致對模型泛化能力的評估不準確,因此我們需要將資料拆分,即使用訓練集進行訓練, 測試集進行驗證評估模型的準確性, 兩個資料集不相交,從而驗證模型的泛化能力。
常見的模型評估方法有留出法,k折交叉驗證法和自助法:

K折交叉驗證中k一般會選擇5,10,20,其中k越大需要訓練的次數越長,其誤差估計的效果也越好。在驗證中,訓練集和測試集的資料分佈應盡可能一致,如果不一致,可能會影響測試集的誤差。
評估模型的泛化能力評估,當模型的應用不理想時,我們應該如何最佳化模型?假設我們在做一個預測模型時, 預測的結果與實際有很大的誤差。我們知道模型不理想主要來源於模型的欠擬合和過擬合,接下來該如何做?
學習曲線
考慮使用學習曲線來判斷模型的過擬合問題。
學習曲線是透過畫出不同訓練集大小時訓練集和交叉驗證的準確率,可以看到模型在新資料上的表現,進而判斷模型是否方差偏高或偏差過高,以及增大訓練集是否可以減小過擬合。
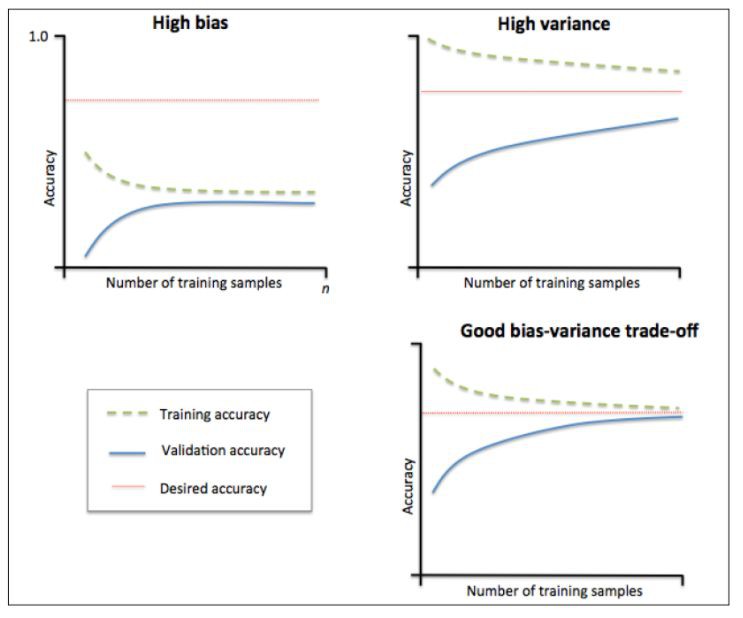
當訓練集與測試集的誤差收斂但卻很高時,為高偏差,左上角偏差較高,訓練集和驗證集的準確率很低,可能是欠擬合。當訓練集與測試集的誤差之間有很大的差距時,為高方差,右上角中方差較高,訓練集的準確率要高於驗證集的準確率,可能是過擬合。理想的狀況是偏差和方差都很小,此時既不欠擬合也不過擬合。
最佳化模型
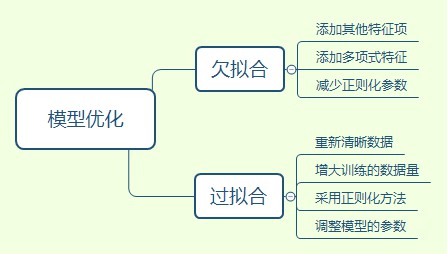
基於上文,當模型出現過擬合或欠擬合時,可從以下幾個方面考慮:
1. 資料量的多少。較少的資料量更容易過擬合,增大資料量對過擬合是有效的。
2. 增加或減少特徵量。特徵值較少會影響模型對樣本資料的認識,導致欠擬合,增加特徵值對欠擬合時有效的。
3. 增加或減少正則化。正則化的使用對過擬合是有效的。
具體可以參見以下思維導圖:
一個機器學習專案是實踐與理論相結合的過程,透過實踐加深對理論的認識,學習理論提高對實際問題的應用能力。在不斷熟悉實際問題的資料型別與背景的過程中,透過訓練機器學習模型,使用各種方法調整並最佳化模型以得到滿意的結論,這一過程可能比單一熟悉機器學習演算法理論耗時要長。 通常情況下,我們會花更多的時間在資料的預處理和引數調優上,需要不斷調整資料,最佳化模型,直到達到較為理想的效果。
如果想要更好的加強這方面的鍛煉,建議多交流,看看別人的經驗總結,網易雲課堂推出機器學習微專業,目前有免費的直播課程,由行業專業人士免費為各位答疑解惑,加強交流。以下福利都是限時免費送出,感興趣的不要錯過:
Part.1
從理論到實踐,教你輕鬆應對面試中的SVM
<2月20日 週三 20:00>
直播大綱:
1 AI大廈的基礎 :數學
2 誰說SVM只能做分類?
3 面試重點:SVM標的函式推導
4 案例實戰:基於SVM的手寫數字識別
直播講師:

網易特邀AI講師Jason
Part.2
免費體驗課
▼
《機器學習基礎》

課程大綱
1 機器學習的就業前景
2 Python實戰學習
(附15天學習計劃和趣味專案原始碼)
3 機器學習工程師的實際應用
小姐姐群內答疑
▼

Part.3
人工智慧學習資料包
▼
6個實戰案例學習資料及程式碼

▼
面試相關問題

▼
程式員簡歷模板

▼
數學基礎學習資料

▼
134篇國際經典論文集

Part.4
答疑助力+福利獲取方式
掃碼新增小助手,即可免費獲取以上所有福利

席位有限,先到先得~

