
作者丨金立達,吳承霖
機構丨笨鳥社交 AI Lab
學校丨英國帝國理工學院
研究方向丨自然語言處理、知識圖譜
在擊敗 11 個 NLP 任務的 State-of-the-art 結果之後,BERT 成為了 NLP 界新的里程碑, 同時開啟了新的思路: 在未標註的資料上深入挖掘,可以極大地改善各種任務的效果。資料標註是昂貴的,而大量的未標註資料卻很容易獲得。
在分類中,標簽表示訓練示例所屬的類; 在回歸中,標簽是對應於該示例的實值響應。 大多數成功的技術,例如深度學習,需要為大型訓練資料集提供 ground truth 標簽;然而,在許多工中,由於資料標註過程的高成本,很難獲得強有力的監督資訊。 因此,希望機器學習技術能夠在弱監督下工作。
這不可避免地導致我們重新考慮弱監督學習的發展方向。 弱監督學習的主要標的是僅使用有限量的標註資料,和大量的未標註資料,來提升各項任務的效果。
弱監督最大的難點在於如何用少量的標註資料,和為標註資料來有效地捕捉資料的流形。目前的一些解決方案在面對複雜的資料時,比較難準確地還原資料的流形。但是 BERT 透過大量的預訓練,在這方面有著先天的優勢。
因而,BERT 憑藉對資料分佈的捕獲是否足以超越傳統半監督的效果?又或者,BERT 能否有與半監督方法有效地結合,從而結合兩者優勢?
弱監督
通常,有三種型別的弱監督。第一種是不完全監督,即只有一個(通常很小的)訓練資料子集用標簽給出,而其他資料保持未標註。 這種情況發生在各種任務中。 例如,在影象分類中,ground truth 標簽由人類註釋者給出;很容易從網際網路上獲取大量影象,而由於人工成本,只能註釋一小部分影象。
第二種型別是不精確監督,即僅給出粗粒度標簽。 再次考慮影象分類任務。 期望使影象中的每個物件都註釋;但是,通常我們只有影象級標簽而不是物件級標簽。
第三種型別是不準確監督,即給定的標簽並不總是真實的。 出現這種情況,例如當影象註釋器粗心或疲倦時,或者某些影象難以分類。
對於不完全監督,在這種情況下,我們只給予少量的訓練資料,並且很難根據這樣的小註釋來訓練良好的學習 然而,好的一面是我們有足夠的未標註資料。 這種情況在實際應用中經常發生,因為註釋的成本總是很高。
透過使用弱監督方法,我們嘗試以最有效的方式利用這些未標註的資料。有兩種主要方法可以解決這個問題,即主動學習和半監督學習。兩者的明確區別在於前者需要額外的人為輸入,而後者不需要人為幹預。
主動學習(Active Learning)
主動學習假設可以向人類從查詢未標註資料的 ground truth。標的是最小化查詢的數量,從而最大限度地減少人工標簽的工作量。換句話說,此方法的輸出是:從所有未標註的資料中,找到最有效的資料點,最值得標註的資料點然後詢問 ground truth。
例如,可能有一個距離決策邊界很遠的資料點,具有很高的正類可信度,標註這一點不會提供太多資訊或改進分類模型。但是,如果非常接近分離閾值的最小置信點被重新標註,則這將為模型提供最多的資訊增益。
更具體地說,有兩種廣泛使用的資料點選擇標準,即資訊性和代表性。資訊性衡量未標註實體有助於減少統計模型的不確定性,而代表性衡量實體有助於表示輸入樣式結構的程度。
關於資訊性,有兩種主要方法,即不確定性抽樣(Uncertainty sampling)和投票機制(query-by-committee)。 前者培訓單個分類器,然後查詢分類器 confidence 最低的未標註資料。 後者生成多個分類器,然後查詢分類器最不相同的未標註資料。
關於代表性,我們的標的是通常透過聚類方法來利用未標註資料的聚類結構。
半監督學習(Semi-Supervised Learning)
另一方面,半監督學習則試圖在不詢問人類專家的情況下利用未標註的資料。 起初這可能看起來反直覺,因為未標註的資料不能像標註資料一樣,直接體現額外的資訊。
然而,未標註的資料點卻存在隱含的資訊,例如,資料分佈。新資料集的不斷增加以及獲得標簽資訊的困難使得半監督學習成為現代資料分析中具有重要實際意義的問題之一。
半監督學習的最主要假設:資料分佈中有可以挖掘的的資訊。
圖 1 提供了直觀的解釋。如果我們必鬚根據唯一的正負點進行預測,我們可以做的只是隨機猜測,因為測試資料點正好位於兩個標註資料點之間的中間位置;如果我們被允許觀察一些未標註的資料點,如圖中的灰色資料點,我們可以高可信度地預測測試資料點為正數。雖然未標註的資料點沒有明確地具有標簽資訊,但它們隱含地傳達了一些有助於預測建模的資料分佈資訊。

▲ Figure 1 為標註資料分佈對分類的幫助 [12]
所有半監督演演算法都有兩個主要假設,即流形假設和聚類假設。前者假設資料位於流形上,因此,附近的實體具有類似的預測。 而後者假設資料具有固有的叢集結構,因此落入同一叢集的實體具有相同的類標簽。
簡而言之,類似的資料點應該具有相似的輸出,我們假設存在資料間點間關係,這些關係可以透過未標註的資料顯示出來。
Self-Training
下麵我們詳細看一下各類的半監督方法。說到半監督學習,我們不得不提到自我訓練方案(Self-training)。
Self-training 透過自己的預測結果中信心最高的樣本來進行 Bootstrapping。也就是說,原始分類器首先對測試集進行一輪預測,並將最自信的預測新增到訓練集中。選擇最自信的預測通常基於預定義的閾值,然後使用新的擴大訓練集作為輸入重覆訓練過程,並將整個過程迭代到某個終止條件。
我們可以參考圖 2 來對比 Self-training 和常規的 Expectation Maximisation (EM) 方法。
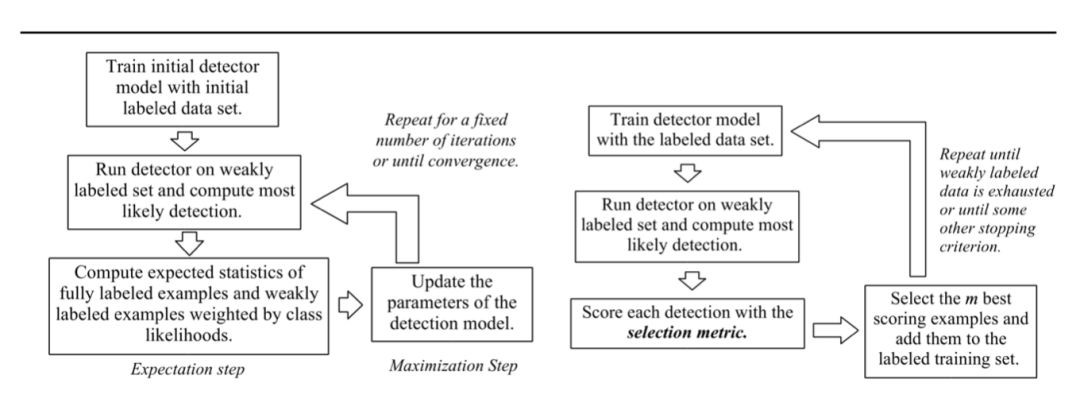
▲ Figure 2 Self-training 流程 [12]
該方法是作為現有訓練流程的 Wrapper 實現的。然而,這種方法的缺點是它是啟髮式的,這意味著它們可能會加劇錯誤。例如,第一個模型錯誤地預測樣本具有高可信度,可能是由於標簽噪聲等,這在現實世界的任務中非常常見。這將影響所有後續迭代,並且不會有自校正機制,因此錯誤將無論如何傳播。
除了自我訓練,半監督學習的許多其他版本和類別得到發展,一些有著非常悠久的歷史。 還有四種其他主要類別的半監督學習方法,即生成方法(Generative Methods),基於圖的方法(Graph-based Methods),低密度分離方法(Low-density Separation)和基於分歧的方法(Disagreement-based Methods)。我們將選取其中幾種方法進行深入研究,以及不同方法的發展。
下麵可以看到幾種不同方法的發展歷程:
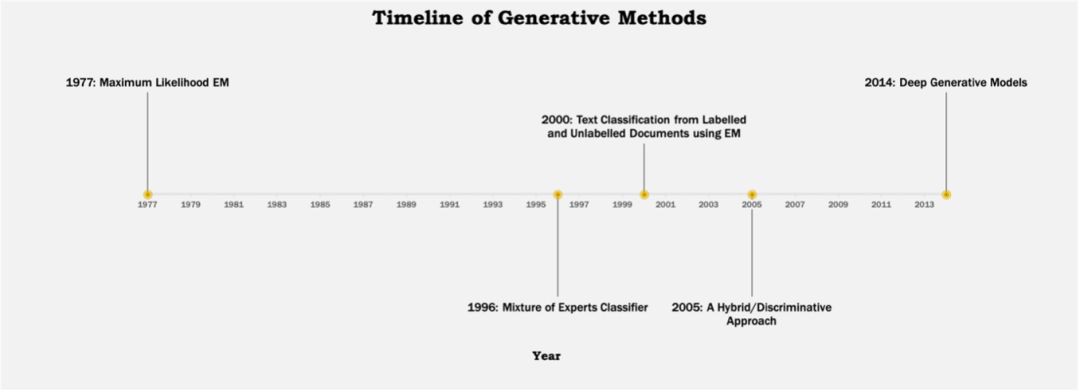
▲ Figure 3 生成方法的發展歷程

▲ Figure 4 圖方法的發展歷程
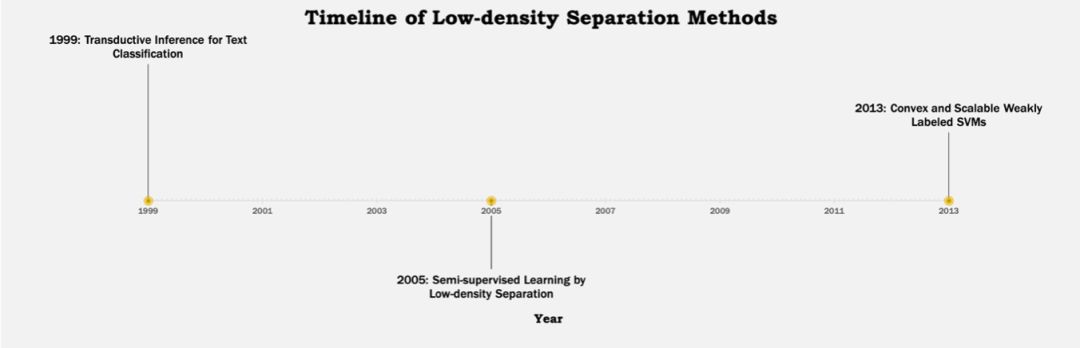
▲ Figure 5 Low-density Separation 的發展歷程
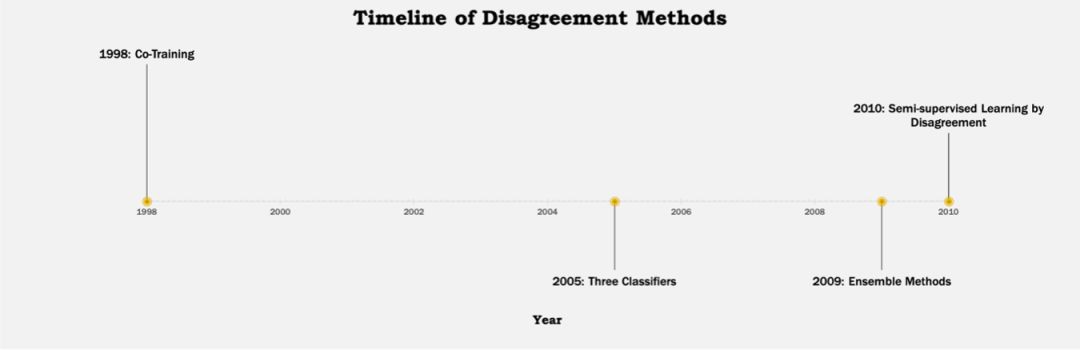
▲ Figure 6 Disagreement Methods 的發展歷程

▲ Figure 7 綜合方法的發展歷程
Generative Methods
生成方法假設標註和未標註資料都是從相同的固有模型生成的。 因此,未標註實體的標簽可以被視為模型引數的缺失值並且透過諸如期望最大化(Expectation-Maximisation)演演算法的方法來估計。
Mixture of Experts
早在 1996 年,就已經在半監督學習領域進行了研究。學習基於總資料可能性的最大化,即基於標註和未標註資料子集。兩種不同的EM學習演演算法,不同之處在於應用於未標註資料的EM形式。 基於特徵和標簽的聯合機率模型的分類器是“專家的混合”結構,其等同於徑向基函式(RBF)分類器,但是與 RBF 不同,其適合於基於可能性的訓練。
Hybrid Discriminative/Generative
現有的半監督學習方法可分為生成模型或判別模型。而這個方法側重於機率半監督分類器設計,並提出了一種利用生成和判別方法的混合方法。在原有的生成模型(標註樣本上訓練得到)新引入偏差校正模型。基於最大熵原理,結合生成和偏差校正模型構建混合模型。該方法結合了判別和生成方法的優點。
Graph Based Methods
在圖 8 中,我麼可以一眼看出問號代表的樣本,有很大的可能性為正樣本。這充分體現出未標註資料的分佈對於分類效果提升的幫助。

▲ Figure 8 資料分佈對分類的影響 [5]
我們可以把分類任務定義為圖結構,構建連線相似資料點的圖,隱藏/觀察到的標簽為圖節點上的隨機變數(圖便成為 MRF)。類似的資料點具有相似的標簽,資訊從標註的資料點“傳播”。如圖 9 所示:
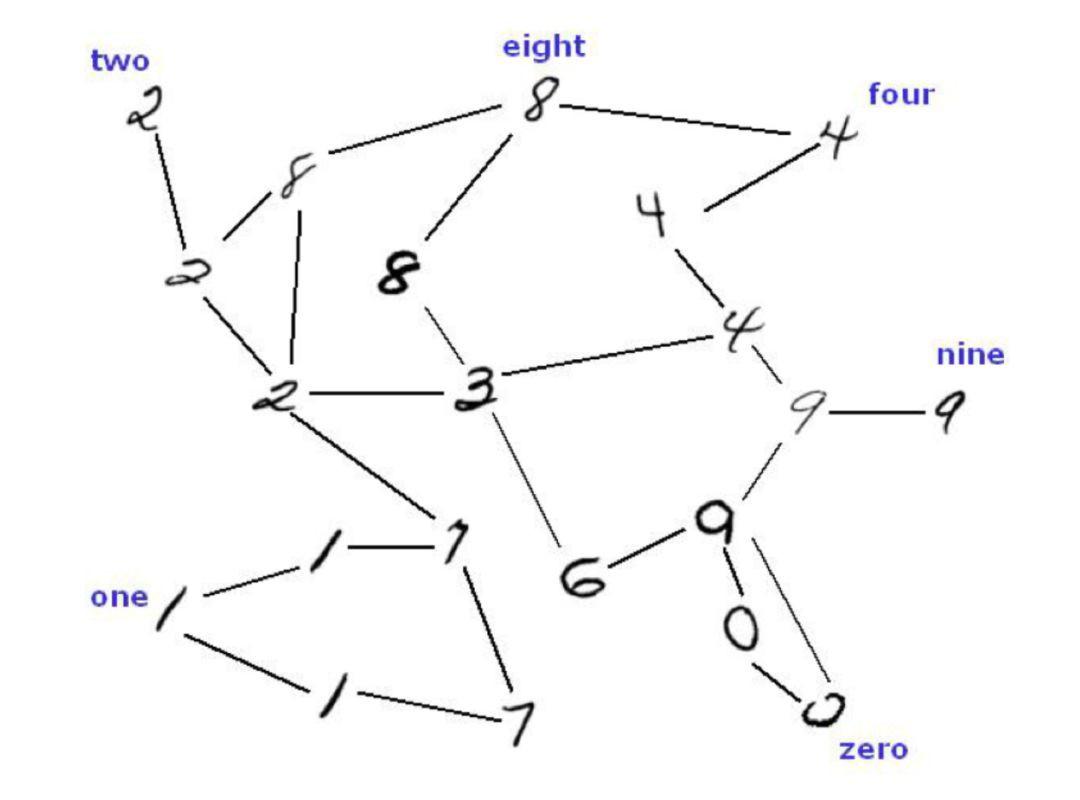
▲ Figure 9 根據相似度建立圖 [7]
各個樣本為圖的節點,連結相似的樣本。標的則是最小化整體能量,能量的定義如下圖所示:

給出的資訊是 n×n 相似度矩陣。應該已經有一些方法來確定所有樣本之間的相似性 – 並且已經在這個階段給出。有許多不同的方法可以確定相似性,每種方法都有自己的優點和缺點。
從圖 10 我們可以形象的看出最佳化能量的過程,紅色邊為高能量,最終目的則是要減少高能量的邊。

▲ Figure 10 不同狀態的能量 [7]
過程可以定義為離散馬爾可夫隨機場(Discrete Markov Random Fields)如圖 11:
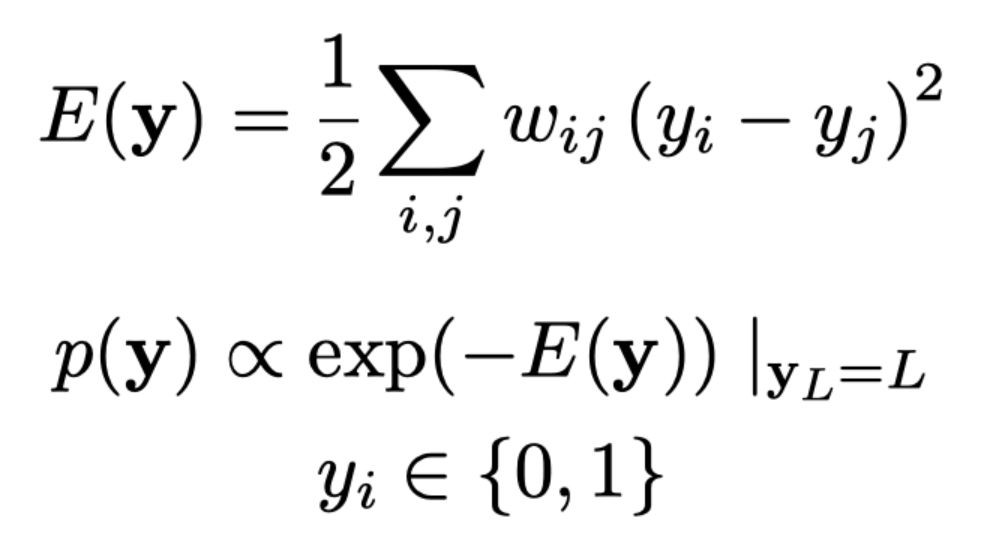
▲ Figure 11 離散馬爾科夫隨機場 [7]
Learning using Graph Mincuts
圖方法中比較早的研究,此研究相對於較早方法關鍵的突破在於可以在指數複雜度最佳化問題上實現多項式運算時間。這裡用的相似度為 Nearest Neighbour(NN),並最佳化最近鄰的一致性。潛在的隨機場為我們的方法提供了一個連貫的機率語意,但是本此方法僅使用場的均值,其特徵在於諧波函式和譜圖理論。
半監督學習問題的關鍵是先驗假設的一致性,這意味著:(1)附近的點可能具有相同的標簽; (2)同一結構上的點(通常稱為簇或歧管)可能具有相同的標簽。值得註意的是第一點是 Local,而第二點是 Global。傳統監督學習演演算法,例如 k-NN,通常僅取決於區域性一致性的第一假設。
預訓練預訓練與多工學習
透過以上對半監督學習中不同方法的分析,我們可以看到,半監督的核心問題是資料流形構成不準確,在樣本數量少的時候更是如此。如果我們可以準確地定義資料的分佈,我們更有可能對未出現過的資料做出更好的預測。
BERT 透過大量的預訓練,空間相對穩定,可以把流形更加清楚地構造出來。在半監督任務中可以加入 BERT 提供的流形先驗,做整體的約束。我們可以用下圖來直觀地表示效果:

▲ Figure 12 BERT 理論上對資料流形的增強效果 [14]
近日微軟釋出的 MT-DNN,在 GLUE 的 11 項 NLP 任務中有 9 項超越了 BERT!MT-DNN 在 BERT 預訓練的基礎上,加入了多工學習(Multi-task Learning)的方法,不像 BERT 只採用了未標註資料來做預訓練,MT-DNN 還利用了其他相關任務的監督資料,與 BERT 預訓練進行互補,並且減輕對特定任務的過擬合。
實驗
為了對比 BERT 在半監督中的效果,我們做了一些實驗來對比:傳統的監督 Naïve Bayes 分類器,半監督 Naïve Bayes 分類器,BERT 和半監督 BERT。
這裡用到的半監督方法是 Self-training/Label Propagation。我們使用相同的資料集 – 20 Newsgroups Dataset,並使用相同數量的訓練和測試集 1,200 和 10,000。實驗結果如圖 13 所示:

▲ Figure 13 20 Newsgroup 分類結果
可以看到加入了 BERT 之後效果非常明顯,BERT-base 已經在原有的半監督方法的基礎上面提升了接近 10%,說明 BERT 本身可以更加好地捕獲資料流形。此外,加入了半監督方法的 BERT 在原有的基礎上有更好的效果,半監督跟預訓練的方法還有結合互補的潛力。
總結
在深入瞭解弱監管的歷史和發展之後,我們可以看到這一研究領域的侷限性和改進潛力。資料標簽成本總是很昂貴,因為需要領域專業知識並且過程非常耗時,尤其是在 NLP 中,文字理解因人而異。但是,我們周圍存在大量(幾乎無限量)未標註的資料,並且可以很容易地提取。
因此,我們始終將持續利用這種豐富資源視為最終標的,並試圖改善目前的監督學習表現。從 ULMFiT 等語言模型到最近的 BERT,遷移學習是另一種利用未標註資料的方法。透過捕獲語言的結構,本質上是另一種標簽形式。在這裡,我們建議未來發展的另一個方向 – 將遷移學習與半監督學習相結合,透過利用未標註的資料進一步提高效果。
參考文獻
[1] Blum, A. and Chawla, S. (2001). Learning from Labeled and Unlabeled Data using Graph Mincuts.
[2] Chapelle, O. and Zien, A. (2005). Semi-Supervised Classiflcation by Low Density Separation.
[3] Fujino, A., Ueda, N. and Saito, K. (2006). A Hybrid Generative/Discriminative Classifier Design for Semi-supervised Learing. Transactions of the Japanese Society for Artificial Intelligence, 21, pp.301-309.
[4] Gui, J., Hu, R., Zhao, Z. and Jia, W. (2013). Semi-supervised learning with local and global consistency. International Journal of Computer Mathematics, 91(11), pp.2389-2402.
[5] Jo, H. (2019). ∆-training: Simple Semi-Supervised Text Classification using Pretrained Word Embeddings.
[6] Kipf, T. (2017). Semi-Supervised Classification with Graph Convolutional Networks.
[7] Li, Q. (2018). Deeper Insights into Graph Convolutional Networks for Semi-Supervised Learning.
[8] Liu, X., He, P., Chen, W. and Gao, J. (2019). Multi-Task Deep Neural Networks for Natural Language Understanding.
[9] Miyato, T., Maeda, S., Ishii, S. and Koyama, M. (2018). Virtual Adversarial Training: A Regularization Method for Supervised and Semi-Supervised Learning. IEEE Transactions on Pattern Analysis and Machine Intelligence, pp.1-1.
[10] NIGAM, K. (2001). Text Classification from Labeled and Unlabeled Documents using EM.
[11] Triguero, I., García, S. and Herrera, F. (2013). Self-labeled techniques for semi-supervised learning: taxonomy, software and empirical study. Knowledge and Information Systems, 42(2), pp.245-284.
[12] Zhou, Z. (2017). A brief introduction to weakly supervised learning. National Science Review, 5(1), pp.44-53.
[13] Zhu, X. (2003). Semi-Supervised Learning Using Gaussian Fields and Harmonic Functions.
[14] Zhuanlan.zhihu.com. (2019). [online] Available at: https://zhuanlan.zhihu.com/p/23340343 [Accessed 18 Feb. 2019].

點選以下標題檢視更多往期內容:
讓你的論文被更多人看到 如何才能讓更多的優質內容以更短路徑到達讀者群體,縮短讀者尋找優質內容的成本呢? 答案就是:你不認識的人。
總有一些你不認識的人,知道你想知道的東西。PaperWeekly 或許可以成為一座橋梁,促使不同背景、不同方向的學者和學術靈感相互碰撞,迸發出更多的可能性。
PaperWeekly 鼓勵高校實驗室或個人,在我們的平臺上分享各類優質內容,可以是最新論文解讀,也可以是學習心得或技術乾貨。我們的目的只有一個,讓知識真正流動起來。
? 來稿標準: • 稿件確系個人原創作品,來稿需註明作者個人資訊(姓名+學校/工作單位+學歷/職位+研究方向) • 如果文章並非首發,請在投稿時提醒並附上所有已釋出連結 • PaperWeekly 預設每篇文章都是首發,均會新增“原創”標誌
? 投稿郵箱: • 投稿郵箱:hr@paperweekly.site • 所有文章配圖,請單獨在附件中傳送 • 請留下即時聯絡方式(微信或手機),以便我們在編輯釋出時和作者溝通
 #投 稿 通 道#
#投 稿 通 道#
?
現在,在「知乎」也能找到我們了
進入知乎首頁搜尋「PaperWeekly」
點選「關註」訂閱我們的專欄吧
關於PaperWeekly
PaperWeekly 是一個推薦、解讀、討論、報道人工智慧前沿論文成果的學術平臺。如果你研究或從事 AI 領域,歡迎在公眾號後臺點選「交流群」,小助手將把你帶入 PaperWeekly 的交流群裡。

▽ 點選 | 閱讀原文 | 獲取最新論文推薦

