

在文章“雲端計算的前世今生”中提到: 雲端計算解決了基礎資源層的彈性伸縮,卻沒有解決PaaS層應用隨基礎資源層彈性伸縮而帶來的批次、快速部署問題。於是容器應運而生。
容器是Container,Container另一個意思是集裝箱,其實容器的思想就是要變成軟體交付的集裝箱。集裝箱的特點,一是打包,二是標準。

沒有集裝箱的時代,假設將貨物從A運到B,中間要經過三個碼頭、換三次船。每次都要將貨物卸下船來,擺的七零八落,然後搬上船重新整齊擺好。因此在沒有集裝箱的時候,每次換船,船員們都要在岸上待幾天才能走。

有了集裝箱以後,所有的貨物都打包在一起了,並且集裝箱的尺寸全部一致,所以每次換船的時候,一個箱子整體搬過去就行了,小時級別就能完成,船員再也不能上岸長時間耽擱了。
這是集裝箱“打包”、“標準”兩大特點在生活中的應用。下麵用一個簡單的案例來看看容器在開發部署中的實際應用。
假設有一個簡單的Java網站需要上線,程式碼的執行環境如下:

那麼容器如何對應用打包呢?還是要學習集裝箱,首先要有個封閉的環境,將貨物封裝起來,讓貨物之間互不幹擾,互相隔離,這樣裝貨卸貨才方便。好在Ubuntu中的LXC技術早就能做到這一點。

封閉的環境主要使用了兩種技術,一種是看起來是隔離的技術,稱為NameSpace,也即每個NameSpace中的應用看到的是不同的IP地址、使用者空間、程號等。另一種是用起來是隔離的技術,稱為Cgroup,也即明明整臺機器有很多的CPU、記憶體,而一個應用只能用其中的一部分。
有了這兩項技術,集裝箱的鐵盒子我們是焊好了,接下來是決定往裡面放什麼。

最簡單粗暴的方法,就是將上面串列中所有的都放到集裝箱裡面。但是這樣太大了!因為即使你安裝一個乾乾靜靜的ubuntu作業系統,什麼都不裝,就很大了。把作業系統裝進容器相當於把船也放到了集裝箱裡面!傳統的虛擬機器映象就是這樣的,動輒幾十G。答案當然是NO!所以第一項作業系統不能裝進容器。
撇下第一項作業系統,剩下的所有的加起來,也就幾百M,就輕便多了。因此一臺伺服器上的容器是共享作業系統內核的,容器在不同機器之間的遷移不帶核心,這也是很多人聲稱容器是輕量級的虛擬機器的原因。輕不白輕,自然隔離性就差了,一個容器讓作業系統崩潰了,其他容器也就跟著崩潰了,這相當於一個集裝箱把船壓漏水了,所有的集裝箱一起沉。
另一個需要撇下的就是隨著應用的執行而產生並儲存在本地的資料。這些資料多以檔案的形式存在,例如資料庫檔案、文字檔案。這些檔案會隨著應用的執行,越來越大,如果這些資料也放在容器裡面,會讓容器變得很大,影響容器在不同環境的遷移。而且這些資料在開發、測試、線上環境之間的遷移是沒有意義的,生產環境不可能用測試環境的檔案,所以往往這些資料也是儲存在容器外面的儲存裝置上。也是為什麼人們稱容器是無狀態的。
至此集裝箱焊好了,貨物也裝進去了,接下來就是如何將這個集裝箱標準化,從而在哪艘船上都能運輸。這裡的標準一個是映象,一個是容器的執行環境。
總而言之,容器是輕量級的、隔離差的、適用於無狀態的,可以基於映象標準實現跨主機、跨環境的隨意遷移。

有了容器,使得PaaS層對於使用者自身應用的自動部署變得快速而優雅。容器快,快在了兩方面,第一是虛擬機器啟動的時候要先啟動作業系統,容器不用啟動作業系統,因為是共享內核的。第二是虛擬機器啟動後使用指令碼安裝應用,容器不用安裝應用,因為已經打包在映象裡面了。所以最終虛擬機器的啟動是分鐘級別,而容器的啟動是秒級。容器咋這麼神奇。其實一點都不神奇,第一是偷懶少幹活了,第二是提前把活乾好了。
因為容器的啟動快,人們往往不會建立一個個小的虛擬機器來部署應用,因為這樣太費時間了,而是建立一個大的虛擬機器,然後在大的虛擬機器裡面再劃分容器,而不同的使用者不共享大的虛擬機器,可以實現作業系統內核的隔離。這又是一次合久必分的過程。由IaaS層的虛擬機器池,劃分為更細粒度的容器池。
容器管理平臺
有了容器的管理平臺,又是一次分久必合的過程。
容器的粒度更加細,管理起來更難管,甚至是手動操作難以應對的。假設你有100臺物理機,其實規模不是太大,用Excel人工管理是沒問題的,但是一臺上面開10臺虛擬機器,虛擬機器的個數就是1000臺,人工管理已經很困難了,但是一臺虛擬機器裡面開10個容器,就是10000個容器,你是不是已經徹底放棄人工運維的想法了。
所以容器層面的管理平臺是一個新的挑戰,關鍵字就是自動化:

自發現:容器與容器之間的相互配置還能像虛擬機器一樣,記住IP地址,然後互相配置嗎?這麼多容器,你怎麼記得住一旦一臺虛擬機器掛了重啟,IP改變,應該改哪些配置,串列長度至少萬行級別的啊。所以容器之間的配置透過名稱來的,無論容器跑到哪臺機器上,名稱不變,就能訪問到。
自修複:容器掛了,或是行程宕機了,能像虛擬機器那樣,登陸上去檢視一下行程狀態,如果不正常重啟一下麼?你要登陸萬臺docker了。所以容器的行程掛了,容器就自動掛掉了,然後自動重啟。
彈性自伸縮 Auto Scaling:當容器的效能不足的時候,需要手動伸縮,手動部署麼?當然也要自動來。
當前火熱的容器管理平臺有三大流派:
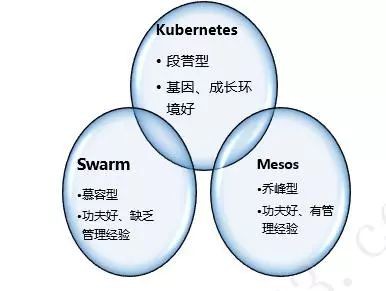
一個是Kubernetes,我們稱為段譽型。段譽(Kubernetes)的父親(Borg)武功高強,出身皇族(Google),管理過偌大的一個大理國(Borg是Google資料中心的容器管理平臺)。
一個是Mesos,我們稱為喬峰型。喬峰(Mesos)的主要功夫降龍十八掌(Mesos的排程功能)獨步武林,為其他幫派所無。而且喬峰也管理過人數眾多的丐幫(Mesos管理過Tweeter的容器叢集)。後來喬峰從丐幫出來,在江湖中特例獨行(Mesos的創始人成立了公司Mesosphere)。
一個是Swarm,我們稱為慕容型。慕容家族(Swarm是Docker家族的叢集管理軟體)的個人功夫是非常棒的(Docker可以說稱為容器的事實標準),但是看到段譽和喬峰能夠管理的組織規模越來越大,有一統江湖的趨勢,著實眼紅了,於是開始想建立自己的慕容鮮卑帝國(推出Swarm容器叢集管理軟體)。
三大容器門派,到底鹿死誰手,誰能一統江湖,尚未可知。
網易雲之所以選型Kubernetes作為自己的容器管理平臺,是因為基於 Borg成熟的經驗打造的Kubernetes,為容器編排管理提供了完整的開源方案,並且社群活躍,生態完善,積累了大量分散式、服務化系統架構的最佳實踐。
容器初體驗
想不想嘗試一下最先進的容器管理平臺呢?我們先瞭解一下Docker的生命週期。如圖所示。
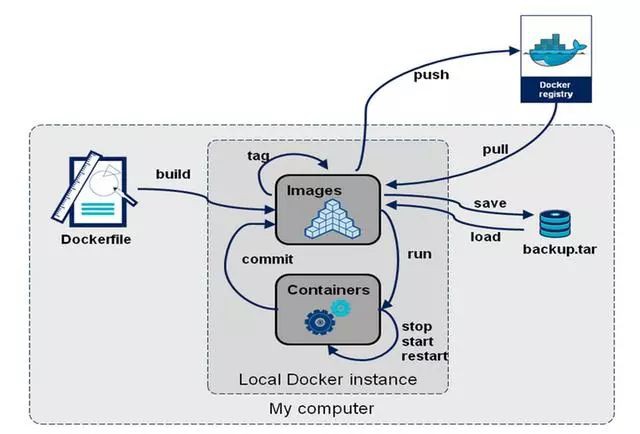
圖中最中間就是最核心的兩個部分,一個是映象Images,一個是容器Containers。映象執行起來就是容器。容器執行的過程中,基於原始映象做了改變,比如安裝了程式,添加了檔案,也可以提交回去(commit)成為映象。
如果大家安裝過系統,映象有點像GHOST映象,從GHOST映象安裝一個系統,執行起來,就相當於容器;容器裡面自帶應用,就像GHOST映象安裝的系統裡面不是裸的作業系統,裡面可能安裝了微信,QQ,影片播放軟體等。安裝好的系統使用的過程中又安裝了其他的軟體,或者下載了檔案,還可以將這個系統重新GHOST成一個映象,當其他人透過這個映象再安裝系統的時候,則其他的軟體也就自帶了。
普通的GHOST映象就是一個檔案,但是管理不方便,比如如果有十個GHOST映象的話,你可能已經記不清楚哪個映象裡面安裝了哪個版本的軟體了。所以容器映象有tag的概念,就是一個標簽,比如Dev-1.0,Dev-1.1,Production-1.1等,凡是能夠幫助你區分不同映象的,都可以。
為了映象的統一管理,有一個映象庫的東西,可以透過push將本地的映象放到統一的映象庫中儲存,可以透過pull將映象庫中的映象拉到本地來。
從映象執行一個容器可使用下麵的命令,如果初步使用Docker,記下下麵這一個命令就可以了。

docker stop可以停止這個容器,start可以再啟動這個容器,restart可以重啟這個容器。在容器內部做了改變,例如安裝了新的軟體,產生了新的檔案,則呼叫docker commit變成新的映象。
映象生產過程,除了可以透過啟動一個docker,手動修改,然後呼叫docker commit形成新映象之外,還可以透過書寫Dockerfile,透過docker build來編譯這個Dockerfile來形成新映象。為什麼要這樣做呢?前面的方式太不自動化了,需要手工幹預,而且還經常會忘了手工都做了什麼。用Dockerfile可以很好的解決這個問題。Dockerfile的一個簡單的例子如下:

這其實是一個映象的生產說明書,Docker build的過程就是根據這個生產說明書來生產映象:
- FROM基礎映象,先下載這個基礎映象,然後從這個映象啟動一個容器,並且登陸到容器裡面;
- RUN執行一個命令,在容器裡面執行這個命令;
- COPY/ADD將一些檔案新增到容器裡面;
- 最終給容器設定啟動命令 ENTRYPOINT,這個命令不在映象生成過程中執行,而是在容器執行的時候作為主程式執行;
- 將所有的修改commit成映象。
這裡需要說明一下的就是主程式,是Docker裡面一個重要的概念,雖然映象裡面可以安裝很多的程式,但是必須有一個主程式,主程式和容器的生命週期完全一致,主程式在則容器在,主程式亡則容器亡。

就像圖中展示的一樣,容器是一個資源限制的框,但是這個框沒有底,全靠主行程撐著,主行程掛了,衣服架子倒了,衣服也就垮了。
瞭解瞭如何執行一個獨立的容器,接下來介紹如何使用容器管理平臺。
容器管理平臺初體驗

容器管理平臺會對容器做更高的抽象,容器不再是單打獨鬥,而且組成集團軍共同戰鬥。
多個容器組成一個Pod,這幾個容器親如兄弟,乾的也是相關性很強的活,能夠透過localhost訪問彼此,真是兄弟齊心,力可斷金。有的任務一幫兄弟還剛不住,就需要多個Pod合力完成,這個由Replication Controller進行控制,可以將一個Pod複製N個副本,同時承載任務,眾人拾柴火焰高。
N個Pod如果對外散兵作戰,一是無法合力,二是給人很亂的感覺,因而需要有一個老大,作為代言人,將大家團結起來,一致對外,這就是Service。老大對外提供統一的虛擬IP和埠,並將這個IP和服務名關聯起來,訪問服務名,則自動對映為虛擬IP。老大的意思就是,如果外面要訪問我這個團隊,喊一聲名字就可以,例如”雷鋒班,幫敬老院打掃衛生!”,你不用管雷鋒班的那個人去打掃衛生,每個人打掃哪一部分,班長會統一分配。
最上層透過NameSpace分隔完全隔離的環境,例如生產環境,測試環境,開發環境等。就像軍隊分華北野戰軍,東北野戰軍一樣。野戰軍立正,出發,部署一個Tomcat的Java應用。
作者簡介:劉超,網易雲解決方案首席架構師。10年雲端計算領域研發及架構經驗,Open DC/OS貢獻者。長期專註於kubernetes, OpenStack、Hadoop、Docker、Lucene、Mesos等開源軟體的企業級應用及產品化。
原文標題:雲端計算前世今生(下)
編者總結:
編者註意到更多文章把容器和虛擬機器進行比較,他們之間存在很大區別和聯絡,下麵進行簡單總結。
容器和虛擬機器都是虛擬化技術,用來解決資源隔離、提高系統資源利用率的一種技術,容器比較輕量(容器空間在MB級別、VM是GB級別),部署密度高,效能損耗小。基於容器映象分層技術可以實現通用依賴庫和系統特定庫分離,實現應用、配置檔案和特定庫依賴打包,可以做到了一處編譯、到處執行。

容器執行效率基本接近於物理機,容器操作(啟動,停止,重啟等)毫秒到秒級,容器的靈活性極大促進混合雲場景負載遷移。最重要的一點是,容器共享宿主機資源,所以可以最到彈性收縮,不像虛擬機器,分配的物理硬體資源固化,不能靈活調整給其他資源使用。
但是容器也存在不足,如無熱遷移,網路隔離性、安全性支援比較薄弱,Docker釋出libnetwork增強網路特性,很多專案也在致力改善容器網路。容器應用只能針對應用和特定庫進行修改,不能有kernel及通用庫改動,因為任何改動都會影響到其他容器執行。
容器隨著使用者行程的停止而銷毀,容器資料和日誌資料無法更好管理和收集,運維能力較弱。業務相關高可用、可恢復性、容災等需求,暫時還無法滿足企業應用要求。
容器還有個重要約束,Linux容器在Linux主機上執行不同跨系統。也可以在Windows Server上執行Windows容器,採用Windows版的Docker容器管理器進行管理。如果要在Windows上執行Linux容器,可以在Windows下啟動Linux虛擬機器,使用Linux虛擬機器作為容器宿主系統,或採用Boot2Docker完成安裝。
容器主要透過依賴Linux系統的NameSpace、Cgroups和檔案系統、映象分層機制技術,實現容器資源隔離、空間隔離和跨平臺打包部署。
NameSpace(名稱空間)是Linux核心針對實現容器虛擬化而引入的特性。每個容器都可以擁有自己單獨的名稱空間,執行在其中的應用都像是在獨立的作業系統中執行一樣,保證了容器之間彼此互不影響。在作業系統中,所有包括核心、檔案系統、網路、PID、UID、IPC、記憶體、硬碟、CPU等資源都是應用行程直接共享的。不但要實現對記憶體、CPU、網路IO、硬碟IO、儲存空間等的限制,還要實現檔案系統、網路、PID、UID、IPC等的相互隔離。前者相對容易實現,後者則需要宿主主機系統的深入支援。
隨著Linux系統對於名稱空間功能的逐步完善,雖然,在容器間都共用一個Linx系統內核和某些執行時環境(系統命令和系統基礎庫),但是他們彼此是不可見的。
Cgroups(Control Groups)是linux核心提供的一種可以跟蹤、限制、隔離行程組所使用的物理資源的機制。僅從資源管理上看,Linux Container是在Cgroups的基礎上做了一層封裝,Docker在LXC的基礎上又做了一層封裝。

Cgroups提供了給容器分配資源的控制機制,避免多個容器同時執行時的系統資源競爭。控制組可以提供對容器的記憶體、CPU、磁碟IO等資源進行限制和計費管理。控制組的設計標的是為不同的應用提供統一的介面,實現對單一行程到系統級虛擬化(包括OpenVZ、Linux VServer、LXC等)的控制。
溫馨提示:
請識別二維碼關註公眾號,點選原文連結獲取更多技微服務和容器術資料總結。



