
菜菜呀,由於公司業務不斷擴大,線上分散式快取伺服器扛不住了呀


如果加硬體能解決的問題,那就不需要修改程式


我是想加伺服器來解決這個問題,但是有個問題呀
???
你忘了去年分散式快取伺服器也擴容過一次,很多請求都穿透了,DB差點扛不住呀,這次再擴容DB估計就得掛了
為什麼會有這麼多請求穿透呢?公司的快取策略是什麼?
很簡單,根據快取資料key的雜湊值然後和快取伺服器個數取模,即:伺服器資訊=hash(key)%伺服器數量
這樣的話,增加一臺伺服器,豈不是大部分的快取幾乎都命中不了了?
給你半天,把這個機制最佳化一下,你要加油呀
工資能不能漲一點?
將來公司發達了,給你發股票……
心想:呸!!

問題分析
這裡還要多說一句,key的取值可以根據具體業務具體設計。比如,我想要做負載均衡,key可以為呼叫方的伺服器IP;獲取使用者資訊,key可以為使用者ID;等等。
假如我們現在伺服器的數量為10,當我們請求key為6的時候,結果是4,現在我們增加一臺伺服器,伺服器數量變為11,當再次請求key為6的伺服器的時候,結果為5.不難發現,不光是key為6的請求,幾乎大部分的請求結果都發生了變化,這就是我們要解決的問題, 這也是我們設計分散式快取等類似場景時候主要需要註意的問題。
我們終極的設計標的是:在伺服器數量變動的情況下
1. 儘量提高快取的命中率(轉移的資料最少)
2. 快取資料儘量平均分配
解決方案
N的數值選擇,可以根據具體業務選擇一個滿足情況的值。比如:我們可以肯定將來伺服器數量不會超過100臺,那N完全可以設定為100。那帶來的問題呢?
目前的情況可以認為伺服器編號是連續的,任何一個請求都會命中一個伺服器,還是以上作為例子,我們伺服器現在無論是10還是增加到11,key為6的請求總是能獲取到一臺伺服器資訊,但是現在我們的策略公式分母為100,如果伺服器數量為11,key為20的請求結果為20,編號為20的伺服器是不存在的。
以上就是簡單雜湊策略帶來的問題(簡單取餘的雜湊策略可以抽象為連續的陣列元素,按照下標來訪問的場景)
為瞭解決以上問題,業界早已有解決方案,那就是一致性雜湊。
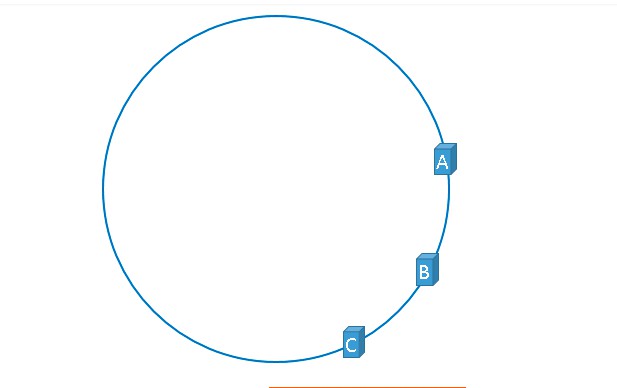
 1. 首先求出伺服器(節點)的雜湊值,並將其配置到環上,此環有2^32個節點。
1. 首先求出伺服器(節點)的雜湊值,並將其配置到環上,此環有2^32個節點。
2. 採用同樣的方法求出儲存資料的鍵的雜湊值,並對映到相同的圓上。
3. 然後從資料對映到的位置開始順時針查詢,將資料儲存到找到的第一個伺服器上。如果超過2^32仍然找不到伺服器,就會儲存到第一臺伺服器上

當增加新的伺服器的時候會發生什麼情況呢?

透過上圖我們可以發現發生變化的只有如黃色部分所示。刪除伺服器情況類似。
透過以上介紹,一致性雜湊正是解決我們目前問題的一種方案。解決方案千萬種,能解決問題即為好
最佳化方案


擴充套件閱讀
 1. 既然是雜湊就會有雜湊衝突,那多個伺服器節點的雜湊值相同該怎麼辦呢?我們可以採用散串列定址的方案:從當前位置順時針開始查詢空位置,直到找到一個空位置。如果未找到,菜菜認為你的雜湊環是不是該擴容了,或者你的分母引數是不是太小了呢。
1. 既然是雜湊就會有雜湊衝突,那多個伺服器節點的雜湊值相同該怎麼辦呢?我們可以採用散串列定址的方案:從當前位置順時針開始查詢空位置,直到找到一個空位置。如果未找到,菜菜認為你的雜湊環是不是該擴容了,或者你的分母引數是不是太小了呢。
2. 在實際的業務中,增加伺服器或者減少伺服器的操作要比查詢伺服器少的多,所以我們儲存雜湊環的資料結構的查詢速度一定要快,具體說來本質是:自雜湊環的某個值起,能快速查詢第一個不為空的元素。
3. 如果你度娘過你就會發現,網上很多介紹虛擬雜湊環節點個數為2^32(2的32次方),千篇一律。難道除了這個個數就不可以嗎?在菜菜看來,這個數目完全必要這麼大,只要符合我們的業務需求,滿足業務資料即可。
4. 一致性雜湊用到的雜湊函式,不止要保證比較高的效能,還要保持雜湊值的儘量平均分佈,這也是一個工業級雜湊函式的要求,一下程式碼實體的雜湊函式其實不是最佳的,有興趣的同學可以最佳化一下。
5. 有些語言自帶的GetHashCode()方法應用於一致性雜湊是有問題的,例如c#。程式重啟之後同一個字串的雜湊值是變動的。所有需要一個更加穩定的字串轉int的雜湊演演算法





理論結合實際才是真諦(NetCore程式碼)
//真實節點的資訊
public abstract class NodeInfo
{
public abstract string NodeName { get; }
}
測試程式所用節點資訊:
class Server : NodeInfo
{
public string IP { get; set; }
public override string NodeName
{
get => IP;
}
}
以下為一致性雜湊核心程式碼:
///
/// 1.採用虛擬節點方式 2.節點總數可以自定義 3.每個物理節點的虛擬節點數可以自定義
/// public class ConsistentHash
{
//雜湊環的虛擬節點資訊
public class VirtualNode
{
public string VirtualNodeName { get; set; }
public NodeInfo Node { get; set; }
}
//新增元素 刪除元素時候的鎖,來保證執行緒安全,或者採用讀寫鎖也可以
private readonly object objLock = new object();
//虛擬環節點的總數量,預設為100
int ringNodeCount;
//每個物理節點對應的虛擬節點數量
int virtualNodeNumber;
//雜湊環,這裡用陣列來儲存
public VirtualNode[] nodes = null;
public ConsistentHash(int _ringNodeCount = 100, int _virtualNodeNumber = 3)
{
if (_ringNodeCount <= 0 || _virtualNodeNumber <= 0)
{
throw new Exception(“_ringNodeCount和_virtualNodeNumber 必須大於0”);
}
this.ringNodeCount = _ringNodeCount;
this.virtualNodeNumber = _virtualNodeNumber;
nodes = new VirtualNode[_ringNodeCount];
}
//根據一致性雜湊key 獲取node資訊,查詢操作請業務方自行處理超時問題,因為多執行緒環境下,環的node可能全被清除
public NodeInfo GetNode(string key)
{
var ringStartIndex = Math.Abs(GetKeyHashCode(key) % ringNodeCount);
var vNode = FindNodeFromIndex(ringStartIndex);
return vNode == null ? null : vNode.Node;
}
//虛擬環新增一個物理節點
public void AddNode(NodeInfo newNode)
{
var nodeName = newNode.NodeName;
int virtualNodeIndex = 0;
lock (objLock)
{
//把物理節點轉化為虛擬節點
while (virtualNodeIndex {
var vNodeName = $”{nodeName}#{virtualNodeIndex}“;
var findStartIndex = Math.Abs(GetKeyHashCode(vNodeName) % ringNodeCount);
var emptyIndex = FindEmptyNodeFromIndex(findStartIndex);
if (emptyIndex 0)
{
// 已經超出設定的最大節點數
break;
}
nodes[emptyIndex] = new VirtualNode() { VirtualNodeName = vNodeName, Node = newNode };
virtualNodeIndex++;
}
}
}
//刪除一個虛擬節點
public void RemoveNode(NodeInfo node)
{
var nodeName = node.NodeName;
int virtualNodeIndex = 0;
List<string> lstRemoveNodeName = new List<string>();
while (virtualNodeIndex {
lstRemoveNodeName.Add($”{nodeName}#{virtualNodeIndex}“);
virtualNodeIndex++;
}
//從索引為0的位置迴圈一遍,把所有的虛擬節點都刪除
int startFindIndex = 0;
lock (objLock)
{
while (startFindIndex {
if (nodes[startFindIndex] != null && lstRemoveNodeName.Contains(nodes[startFindIndex].VirtualNodeName))
{
nodes[startFindIndex] = null;
}
startFindIndex++;
}
}
}
//雜湊環獲取雜湊值的方法,因為系統自帶的gethashcode,重啟服務就變了
protected virtual int GetKeyHashCode(string key)
{
var sh = new SHA1Managed();
byte[] data = sh.ComputeHash(Encoding.Unicode.GetBytes(key));
return BitConverter.ToInt32(data, 0);
}
//從虛擬環的某個位置查詢第一個node
private VirtualNode FindNodeFromIndex(int startIndex)
{
if (nodes == null || nodes.Length <= 0)
{
return null;
}
VirtualNode node = null;
while (node == null)
{
startIndex = GetNextIndex(startIndex);
node = nodes[startIndex];
}
return node;
}
//從虛擬環的某個位置開始查詢空位置
private int FindEmptyNodeFromIndex(int startIndex)
{
while (true)
{
if (nodes[startIndex] == null)
{
return startIndex;
}
var nextIndex = GetNextIndex(startIndex);
//如果索引回到原地,說明找了一圈,虛擬環節點已經滿了,不會新增
if (nextIndex == startIndex)
{
return -1;
}
startIndex = nextIndex;
}
}
//獲取一個位置的下一個位置索引
private int GetNextIndex(int preIndex)
{
int nextIndex = 0;
//如果查詢的位置到了環的末尾,則從0位置開始查詢
if (preIndex != nodes.Length – 1)
{
nextIndex = preIndex + 1;
}
return nextIndex;
}
}
測試生成的節點
ConsistentHash h = new ConsistentHash(200, 5);
h.AddNode(new Server() { IP = "192.168.1.1" });
h.AddNode(new Server() { IP = "192.168.1.2" });
h.AddNode(new Server() { IP = "192.168.1.3" });
h.AddNode(new Server() { IP = "192.168.1.4" });
h.AddNode(new Server() { IP = "192.168.1.5" });
for (int i = 0; i {
if (h.nodes[i] != null)
{
Console.WriteLine($"{i}===={h.nodes[i].VirtualNodeName}");
}
}
輸出結果(還算比較均勻):
2====192.168.1.3#4
10====192.168.1.1#0
15====192.168.1.3#3
24====192.168.1.2#2
29====192.168.1.3#2
33====192.168.1.4#4
64====192.168.1.5#1
73====192.168.1.4#3
75====192.168.1.2#0
77====192.168.1.1#3
85====192.168.1.1#4
88====192.168.1.5#4
117====192.168.1.4#1
118====192.168.1.2#4
137====192.168.1.1#1
152====192.168.1.2#1
157====192.168.1.5#2
158====192.168.1.2#3
159====192.168.1.3#0
162====192.168.1.5#0
165====192.168.1.1#2
166====192.168.1.3#1
177====192.168.1.5#3
185====192.168.1.4#0
196====192.168.1.4#2
測試一下效能
Stopwatch w = new Stopwatch();
w.Start();
for (int i = 0; i 100000; i++)
{
var aaa = h.GetNode("test1");
}
w.Stop();
Console.WriteLine(w.ElapsedMilliseconds);
輸出結果(呼叫10萬次耗時657毫秒):
657
1. 雜湊函式
2. 很多for迴圈的臨時變數
有興趣最佳化的同學可以留言哦!!


網際網路之路,菜菜與君一同成長
長按識別二維碼關註

聽說轉發文章
會給你帶來好運
