導讀:本文由Kubernetes在微博落地的具體工作整理而成。透過圍繞業務需求和大家分享下企業內部如何使用Kubernetes來解決具體的業務問題和相應的方案。文中分享了基於Kubernetes的PaaS層彈性混合部署方案,其中有Kubernetes的優點,也有部分Kubernetes在企業落地的缺陷,歡迎大家一起討論和建設Kubernetes。希望本文對大家有一定的借鑒意義。
彭濤,主要負責微博容器平臺的開發工作。Kubernetes程式碼貢獻者。曾就職於百度基礎架構部,百度公有雲事業部。長期從事雲端計算行業。熟悉網路虛擬化,SDN,OpenStack,Kubernetes。致力於推動Kubernetes在微博的應用落地,構建高效的PaaS平臺
王琨,微博平臺高階產品運維工程師,主要負責微博feed、使用者關係、架構業務的運維支撐及改造工作。擅長大規模分散式系統叢集的管理與運維,疑難問題分析,故障定位與處理。致力於推進運維自動化,構建微博平臺高效的運維平臺。
一、微博容器平臺
2016年微博平臺實現基於混合雲的彈性平臺DCP,提升了Feed、手機微博、廣告、搜尋、話題、影片、直播等多個核心業務熱點應對能力。2017年微博平臺率先探索基於Kubernetes的PAAS層彈性混合部署解決方案,並且積極的和社群保持同步。2018年實現CI/CD與生產環境混合部署,2019年春晚實現部分核心業務混合部署與彈性伸縮。
本文主要介紹微博平臺落地Kubernetes過程中的一些經驗教訓。
二、為什麼選擇Kubernetes
因為歷史原因,微博docker容器治理是採用獨佔物理機(虛擬機器)樣式,直接使用物理機的網路協議棧,服務治理採用服務池方式。隨著裝置計算能力的提升,這種治理方式有幾個問題急需解決:
1. 利用率問題:一個服務池內新、老裝置共存,因為業務容器需要相容老裝置規格,導致服務無法充分發揮出新裝置應有的計算能力。
2. 容器網路問題:因為直接採用物理機網路棧,導致業務混合部署只能採用調整業務監聽埠的方式,造成接入成本、管理成本高。
3. 排程治理問題:因為預設採用獨佔策略,服務池之間資源相互隔離,不同型別的業務型別無法共享資源,導致資源總是相對緊缺。
Kubernetes提供標準化的容器管理,CNI網路虛擬化,自定義彈性排程策略,能夠很好的解決上述問題。但是Kubernetes面向公有PAAS的實現方案在內網環境下有些方面不適用,主要有如下幾個方面:
1. 網路虛擬化:在BGP的虛擬網路方案和隧道的虛擬網路方案中都會引入iptables來完成流量牽引,和防火牆的相關功能,在企業內網使用的過程中並沒有很強烈的防火牆需求,引入iptables往往會造成效能下降(nf_conntrack表被打滿,NAT效能太低)。所以微博平臺現階段沒有使用BGP虛擬化網路方案和隧道虛擬化網路方案
2. 滾動釋出:目前的Kubernetes的滾動釋出(Deployment)不支援In-place rolling updates ,每次一個Pod都有可能被分配不同的IP地址,在企業內部使用容器的時候,固定IP的需求往往很強烈,所以我們拋棄了Kubernetes而選擇了整合了公司內部的滾動釋出系統
3. 資源隔離:原生的記憶體隔離策略中不支援swap的限制,容器會佔用物理機的swap,我們修改了記憶體隔離限制。
4. 負載均衡:原生的Service樣式會引入iptables來做NAT,同時Service的負載是硬負載沒法調整流量權重。
我們基於Kubernetes搭建了一套PaaS平臺,對Kubernetes進行了改進,提供了以下功能:
1. 網路虛擬化:基於CNI,提供了隔離內網和公有雲網路差異的虛擬化網路方案
2. 排程管理:基於kube-scheduler,提供了鎖定IP的排程系統,該系統支援頻寬初篩,硬碟初篩,機房就近排程,傳回庫存狀態,提前鎖定IP功能等功能
3. CI/CD:一鍵釋出程式碼,替代Kubernetes的Deployment進行滾動釋出
4. 資源隔離:在原有的隔離策略上,擴展出計算資源隔離,網路資源隔離,儲存資源隔離
5. 負載均衡:整合已有的排程系統,利用微服務快速部署+彈性排程提前鎖定IP,減少服務抖動耗時。
6. 模組化運維:把已有的物理機運維工具整合到容器中,在Pod裡面共享儲存,共享網路
7. 彈性擴縮容:透過對DCP的整合,使其具有了容器彈性擴縮容的功能。
8. 監控:透過模組化的運維體系,整合了監控所需日誌,無縫連線已有功能
三、整體方案

圖一
整體方案如圖一,微博容器平臺劃分出如下幾層:
1. 服務層:平臺的主要入口提供容器擴縮容、上下線、維護服務池、負載均衡,監控管理等功能
2. PaaS層:提供容器管理和排程管理等相關功能,負責將服務層的請求轉化成對應容器的操作
3. IaaS層:提高機器資源、網路資源、儲存資源供PaaS生成的容器使用,負責對容器使用資源進行管理
三、容器彈性化擴縮容平臺建設
微博容器彈性擴縮容平臺,是在Kubernetes基礎上進行了改進,充分利用了微博平臺已有的資源。避免重覆造輪子。具體的工作如下:
3.1 基礎建設之網路虛擬化
之前已經說過了,微博的容器會獨佔物理機的網路協議棧,雖然能夠做到網路效率的最大化,但是會導致多容器部署時出現埠衝突。為瞭解決埠衝突需要使用虛擬化網路技術提供容器獨立的IP地址。多個容器獨立IP需要解決以下的三個問題:
1. 容器的IP地址分配問題;
2. 容器的IP路由問題;
3. 虛擬化網路對網路的效能損失要最小化;
第一個問題因為採用Kubernetes IP分配都是透過記錄在etcd中,所以不會出現分配重覆或者分配錯誤的問題,而第二個問題社群裡面通常會採用隧道型別方案和BGP方案。以下是隧道樣式和BGP樣式的優缺點對比如表一, 效能測試如表二(BGP主要工作是路由交換,轉發等不受影響,等同於物理機效能。)

表一

表二
在測試結果中顯示vxlan因為需要封裝和解封隧道導致頻寬損耗過5%,所以隧道方案不適用於內網的網路環境。而BGP的方案Calico會引入iptables去做ACL,不僅在業務峰值流量的情況下會觸發nf_conntrack表被打滿丟包的風險。而且BGP方案在公有雲和內網落地的時候也存在問題:
公有雲方面:
1. 從公有雲虛擬機器發出的報文必須是Mac地址和IP地址匹配的,所以導致在公有雲機器上BGP虛擬網路的容器根本無法通訊。
內網方面:
1. 內網機器的上聯交換機上做了Vlan和IP的系結,如果在內網機器上起了一個其他網段的IP地址,報文傳送不出本機。
接下來先來看看在網路方案上我們做的一些工作(見圖二)。
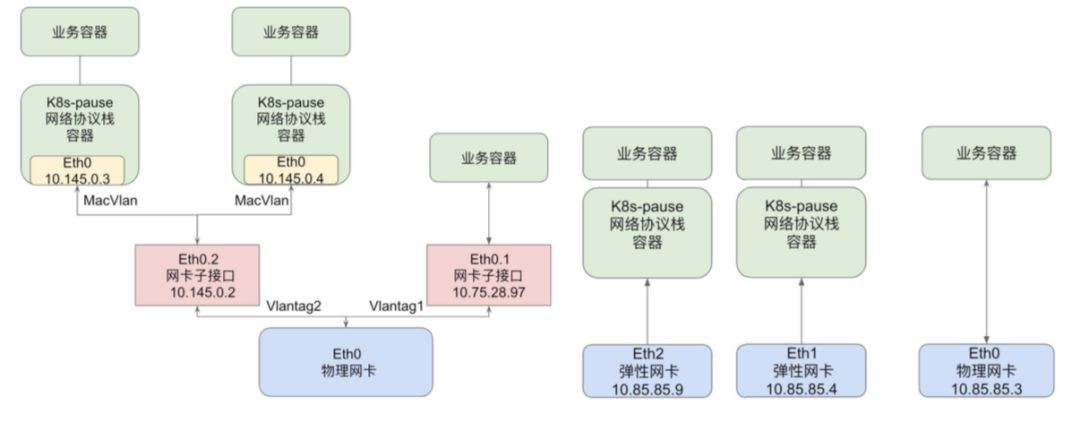
圖二
微博虛擬網路主要是四方面內容:
1. 對機房網路進行改造,修改機器的上聯交換機為trunk樣式,支援多Vlantag的網路通訊
2. 在物理機層面透過建立網絡卡子介面(如圖一左側),透過對網絡卡子介面做MacVlan虛擬網絡卡插入Kubernetes的Pause容器中,把容器網路與物理網路打通。
3. 公有雲方面透過建立彈性網絡卡,讓一個機器上有多個網絡卡,且每塊網絡卡帶獨立IP地址,然後對新加的網絡卡做host-device,將網絡卡的所屬network namespace 修改為Kubernetes的Pause容器,把容器和物理網路打通。
4. 對CNI外掛進行修改,能夠給容器分配指定IP地址 ;
圖二左側是簡化後的內網網路拓撲,容器的虛擬網絡卡透過MacVlan與物理網絡卡的網絡卡子介面相連,發出的報文會帶上網絡卡子介面的Vlantag,而這部分的流量上到上聯交換機之後就和物理機發出的沒有任何區別,之後的都是交換機和閘道器去解決掉路由的問題。這個方案的設計對現有的環境依賴最小。同時改動量少。實現機房物理網路與容器網路的扁平化,解決了容器網路和物理網路互聯互通的問題,由於沒有隧道解封效能問題。效能基本上持平物理機效能。 本質上這是一個私有雲的網路解決方案,但是很好的解決了問題。
圖二右側是簡化後的公有雲網路拓撲,透過把物理機上的網絡卡遷移到容器裡面來間接的實現多IP。由於是虛擬機器的彈性網絡卡,等同於虛擬機器上的物理網絡卡,效能沒有問題。
3.1.1 虛擬網路後續的演近
對Calico進行改進取消iptables依賴。利用Calico去解決內網網路方案中ip浪費的問題。同時可以對Calico做進一步的研究,如動態遷移容器如何保持ip漂移。
3.2 基礎建設之排程管理
容器排程,其實是為了提高資源利用率,同時減少資源碎片化。Kubernetes的排程策略做的相對靈活,對Pod的排程透過三個階段來實現,初篩階段用於篩選出符合基本要求的物理機節點,優選階段用於得到在初篩的節點裡面根據策略來完成選擇最優節點。在優選完畢之後,還有一個系結過程,用於把Pod和物理機進行系結,鎖定機器上的資源。這三步完成之後,位於節點上的kubelet才能開始真正的建立Pod。在實際的接入過程中,Kubernetes的基礎排程策略不能滿足平臺的業務需求,主要有如下兩點:
1. 因為沒有規格的概念所以無法給出庫存狀態
2. 初篩的緯度太少,目前只支援CPU,記憶體的初篩,優選不支援同機房就近排程。
3.2.1 整體方案
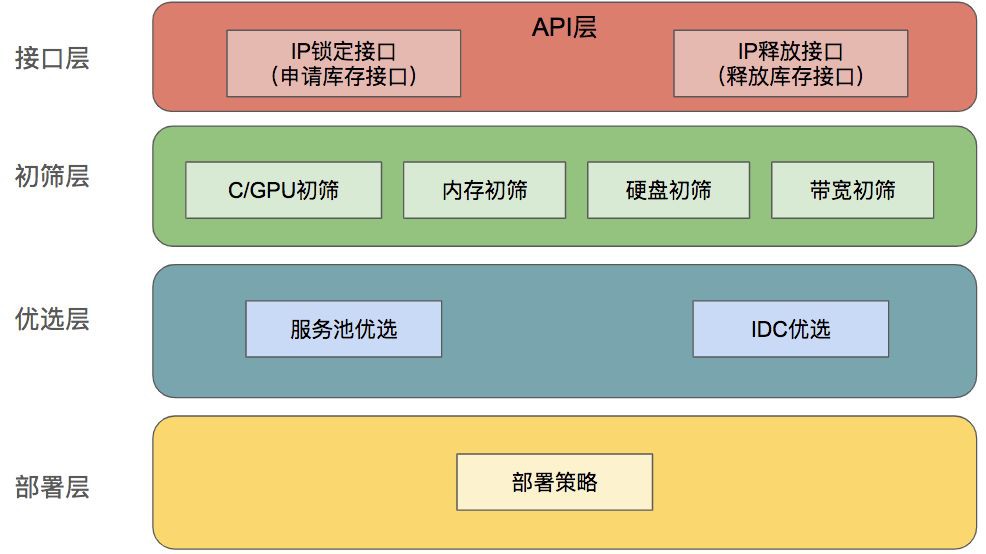
圖三
整體的排程管理分成如下幾層:
1. 介面層:
a. 用於接收請求傳回特定規格,特定排程需求下的庫存數量,同時傳回鎖定好的虛擬IP地址。
b. 用於接收請求釋放虛擬IP地址。
2. 初篩層:對快取中的節點資訊進行初篩,傳回能部署規格的全部物理機節點資訊
3. 優選層:根據優選結果,模擬部署Pod,統計整體庫存。
4. 部署策略層:按照部署策略挑選物理機,並且鎖定物理機上的虛擬IP地址,傳回庫存資訊
3.2.2 排程管理之介面層
鎖定庫存介面層的邏輯:
1. 把請求引數轉化為Kubernetes的Pod物件 -> v1.Pod。
2. 把scheduler的Cache進行一次深複製,後續的動作都會在這個深複製的Cache中完成
3. 請求監控傳回物理機的實時硬碟資訊,實時頻寬資訊。整合到深複製Cache中
4. 連同請求引數都傳遞給初篩層
釋放庫存介面層的邏輯:
1. 呼叫Kubernetes介面,把物理機節點上虛擬IP的label改成unusing。
3.2.3 排程管理
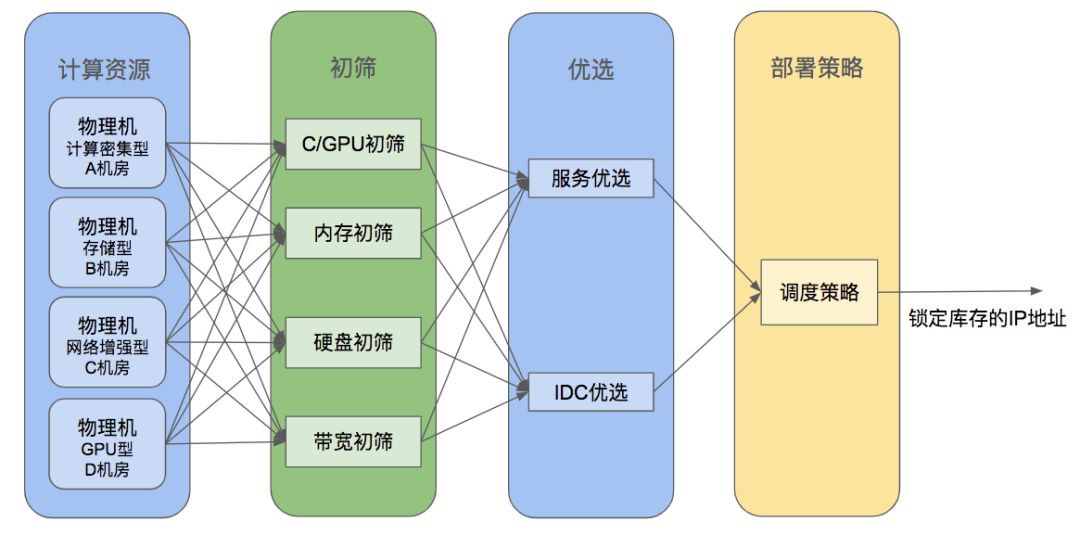
圖四
初篩層:對上述的cache部分裡面的Node節點進行CPU,記憶體,硬碟和頻寬的初步篩選,傳回透過篩選的所有物理機節點。
優選層:對上述的物理機節點資訊進行打分,對節點進行排序。然後根據請求所需部署的容器數量,按照物理機節點的進行模擬部署(挑選物理機按照分數從高到低排列),直到全部節點上可部署容器數量為0,統計每個節點能部署的容器個數。
部署策略層:根據請求引數的不同(目前只支援集中/平鋪),鎖定物理機上的IP地址(呼叫kubernetes的API 把物理機上虛擬IP的label置為Using狀態),並且傳回這些IP地址。
3.2.6 整體流程圖
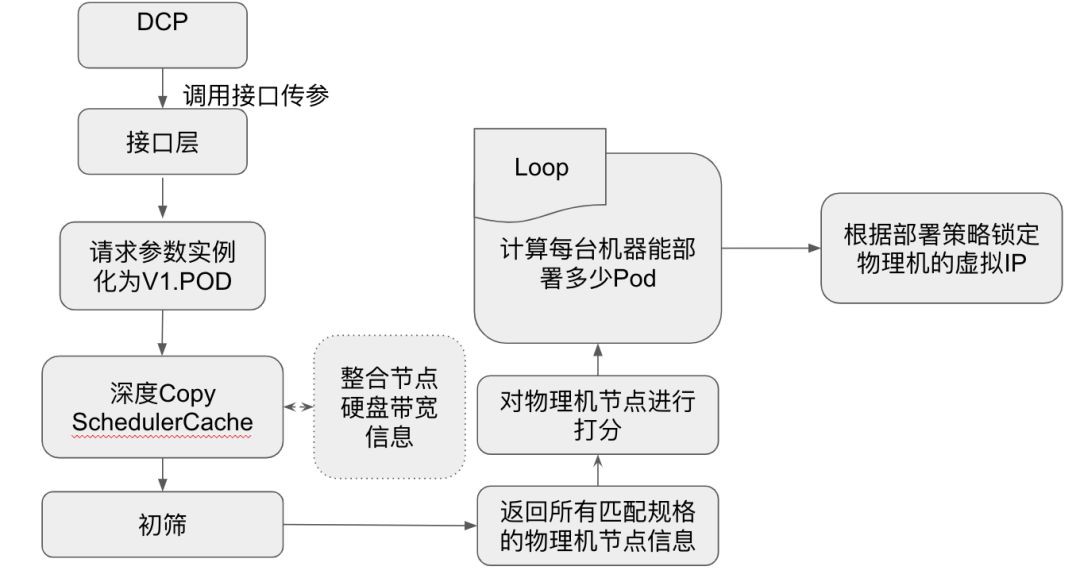
圖五
3.2.7 後續演進
支援排程優先順序,且能根據實際的資源使用情況進行排程而不是Kubernetes預分配的資源進行排程。
3.3 基礎建設之資源隔離
Kubernetes支援CPU、記憶體的隔離。在宿主機層面支援驅逐樣式。透過虛擬化網路的方案,主容器網路和混部容器的網路分割開來。整體的資源隔離標的是為了隔離開主容器和混部容器對資源的使用。以下是我們做的一些改進。
計算資源隔離
1. K8S提供了記憶體的限制能力,是透過OOM來限制記憶體的使用。在此基礎上,我們還增加了限制容器使用物理機的swap。
儲存資源隔離
1. K8S沒有提供基於物理機的儲存資源配額方案,但是提供了相關的框架介面。在此基礎上,開發了有配額大小限制的物理機靜態儲存解決方案。
網路資源隔離
1. 針對容器的網路限速方案,已經在內部測試透過,同時幫助社群完善了相關的限速程式碼。
3.3.1 後續的演進
資源隔離的後續方向很多,首先要解決的是Kubernetes如何能動態設定資源閾值。其後需要能夠設定記憶體OOM優先順序,以及滿足資源超賣的需求
3.4 基礎建設之CI/CD
平臺於2018年基於gitlab開發了CI/CD,透過CI/CD和Kubernetes的配合來完成從程式碼提交到上線的完整流程,其中使用Kubernetes的上線流程(如Deployment)的滾動釋出存在著容器IP不固定,動態化的問題。是因為Kubernetes的設計原則中對叢集的管理尤其是服務升級過程中需要保持“無損”升級(升級過程中提供服務的副本數一直符合預期)。如果對一個Deployment進行滾動升級,那麼這個Deployment裡面的IP地址和滾動升級之前的IP地址是不會相同的。而如果叢集夠大,一次滾動釋出就會導致負載均衡變更 (叢集副本數/滾動釋出步長)次。對於微博服務來說,頻繁變更會導致這個負載均衡轄下,所以後端實體的介面不穩定。
而平臺內部的之前的上線系統是根據業務冗餘度及業務實際需要來調整上線的步長,減少在上線過程中業務的抖動,也就是通常說的In-place rolling updates。保證在上線過程中容器的IP不變。
整體流程的核心思路為:
1. 切斷容器的流量
2. 進行流量檢測,確保已經沒有線上流量
3. 清理舊容器
4. 部署新容器
5. 檢測服務是否正常啟動(埠檢測,介面驗證)
6. 接收線上流量,提供服務
針對該問題,容器平臺沒有使用Kubernetes的原生滾動釋出而是做了以下幾個改進和適配:
1. 首先不使用DP,RC的概念來完成滾動釋出,只使用Pod的概念。
2. 整合已有的上線系統,來完成滾動釋出,回滾功能
3. 流量引入/流量拒絕 利用Kubernetes容器生命週期管理的lifecycle(修改了其中的postStar的原生實現,因為原生裡面只呼叫一次,不管成功與否都會殺掉容器。改進成瞭如果不成功會按照指定的次數或時間進行重試),服務檢查利用 liveness probe、 readiness probe來完成
主要流程有
1. 提前劃分給每個機器上劃分虛擬IP段,並給機器打上虛擬IP的label
2. 在原有的上線系統中增加對Kubernetes管理容器的上線流程,上線過程中透過服務池中已有IP反查Pod Name,然後刪掉舊Pod,然後用新的映象tag 生成Pod的json字串(其中nodeSelect=${IP}),然後提交Kubernetes去建立新tag版本的Pod
3. Kubelet接到建立請求之後,提取其中的IP地址發給CNI,建立指定IP的新tag版本Pod
上線回滾的流程變成了刪除Pod,建立Pod的固定化操作(見圖六)

圖六
由於給機器打好了虛擬IP標簽,所以Pod的建立會被分配給固定的物理機去執行,配合修改之後的CNI就能建立指定新tag+固定IP的Pod來提供服務。滾動釋出和回滾變成了刪除Pod,建立Pod的固定化操作。
3.5 基礎建設之模組化運維
由於之前的容器是獨佔物理機的樣式,所以對於容器的運維也是在物理機上進行的,一些功能如日誌處理、域名解析、時鐘同步、運維Agent管理以及定時任務等都是在物理機層面操作。如果開始多容器混合部署,以上的功能都相容改動工作量大。再加上平臺面向的業務方眾多,需求各不相同。例如日誌推送的方式已經出現scribe、flume、filebeat等不同的方式,業務運維需要根據自身去定製運維容器,由此可見模組化運維的必要性。我們基於Kubernetes的Pod概念做瞭如下的工作,整體架構見圖七。

圖七
1. 單獨做了運維容器,把運維相關的工具整合在容器裡面;
2. 運維容器和業務容器共享網路協議棧,共享日誌儲存;
3. 在容器裡面共享儲存是帶配額的靜態儲存;
3.5.1 模組化運維之定時任務
物理機上的定時任務以來於crontab,而crontab會由systemd來啟動。在容器中使用systemd啟動會涉及到提權問題,在實踐過程中發現用systemd如果許可權控制不當會造成容器被Kill的情況,所以單獨開發了相容linux crontab語法的定時任務工具-gorun,把這個工具整合在了運維容器裡面,替代了crontab來完成定時任務。
3.1.5.2 模組化運維之日誌處理
日誌的處理主要包括監控採集、日誌推送、日誌查詢、日誌壓縮清理四方面:
1. 日誌推送:透過scribe,flume等方式接收業務日誌,推送給資訊系統部等資料處理部門(如圖八)。

圖八
2. 日誌查詢:容器產生的日誌需要能夠靜態儲存三天左右,方便故障定位。所以日誌會儲存基於Kubernetes的PVC概念開發的本地帶配額的靜態儲存裡面。
3. 日誌壓縮清理:磁碟空間有限,列印的日誌需要定期的清理和壓縮
4. 監控採集:透過監聽檔案變化或者監聽埠來採集需要的監控資料
透過上述手段,能夠利用現有的日誌體系,同時開發的工作量最小,透過這樣的操作,以後的容器想要接入,只需要在Pod的配置檔案裡面多寫一個container的配置即可。
3.5.3 後續的演進
後續的運維容器將會進一步的拆分,做成標準化的服務,例如域名解析容器,日誌推送容器。讓業務的接入變得更加的容易。
3.6 基礎建設之彈性擴縮容
彈性伸縮在微博的應用很廣,作為支援了全公司春晚擴容的DCP系統其主要能力就是進行IAAS層虛擬機器的彈性伸縮。是對業務進行保障的重要手段之一。彈性擴縮容保證在峰值流量來臨時透過擴容提高介面的可用性,在業務量級下降後回收資源節省了成本,而PaaS層的擴縮容比IaaS層的擴縮容更具有優勢,一來是因為PaaS的啟動更輕,沒有虛擬機器的初始化階段。所以啟動更快,二來是因為我們的彈性排程系統能提前鎖定IP,可以做到業務容器和變更Nginx同步進行。所以在PaaS層的彈性擴縮容,我們目前做到瞭如下幾點工作:
1. 定時擴縮容實現;
2. 自動化擴縮容的實現
定時擴縮容是復用了DCP系統的定時擴縮容功能,並做了一定的適配,目前可以選擇使用原生擴容樣式(IaaS層)和Kubernetes擴容樣式。選擇好了樣式之後需要填的就是Pod的排程引數和本身Pod的標準化json檔案,之後就是常規功能。
自動化擴縮容的實現,是基於CI/CD系統中的放量系統完成的,CI/CD會在上線過程中有單機放量的步驟,其中會採集放量容器的監控資料,業務資料和日誌資料。橫向對比當前服務池的整體介面耗時和縱向對比歷史七天內單機的介面耗時。透過這套系統,把相關的閾值指標匯出之後,整合到監控系統中,如果判斷介面的QPS和耗時產生了惡化,會相應的觸發擴容操作,不同於IaaS層的擴容,PaaS的擴容在存量機器上是免費的的。例如前端某介面的QPS過高,處理不過來了可以在機器學習服務池的機器上進行容器擴縮容去先扛住量。
3.1.7 基礎建設之負載均衡
微博平臺的7層負載均衡方案是使用Nginx。目前仍使用的是靜態檔案的進行路由資訊管理,nginx變更系統實現了一套動態的解決方案,將upstream與對應的服務池進行關聯,確保對應的介面由對應的服務池來提供服務,當服務池內有節點變更時,自動觸發配置下發進行nginx的變更。
Kubernetes從最開始的Service上就開始了負載均衡和服務發現的嘗試,例如在Service上利用Iptables進行請求的隨機負載(問題在於後端某個實體的壓力已經很高了,由於是iptables的硬負載不能感知到,依然把請求傳遞過來)。而且和網路虛擬化一樣引入Iptables會有nf_conntrack打滿的風險,考慮到公司內部的已經有成熟的負載均衡系統,這塊進行了一個適配。
由於彈性排程的功能,我們會在建立Pod之前就可以鎖定的IP地址。當IP地址鎖定後,我們可以同步的變更我們的負載均衡系統+啟動我們的業務容器。能夠更快的響應業務請求(見圖九)。

圖九
3.8 基礎建設之監控系統
監控和日誌都是平臺內部成熟的元件,透過模組化運維中日誌資訊的採集推送,監控資料採集推送已經相容原有方式推送到監控平臺。而物理機監控已經透過運維物理機部署Agent來採集,不需要重新引入別的工具去完成。整體的監控總共有如下的幾個部分:
1. 物理機資訊監控:物理機CPU、記憶體、IOPS、頻寬、負載、網路等基礎監控資訊
2. 業務容器的業務監控:包括介面QPS、耗時、傳回狀態碼佔比、err/warn日誌記數、連結資源耗時等(見圖十)
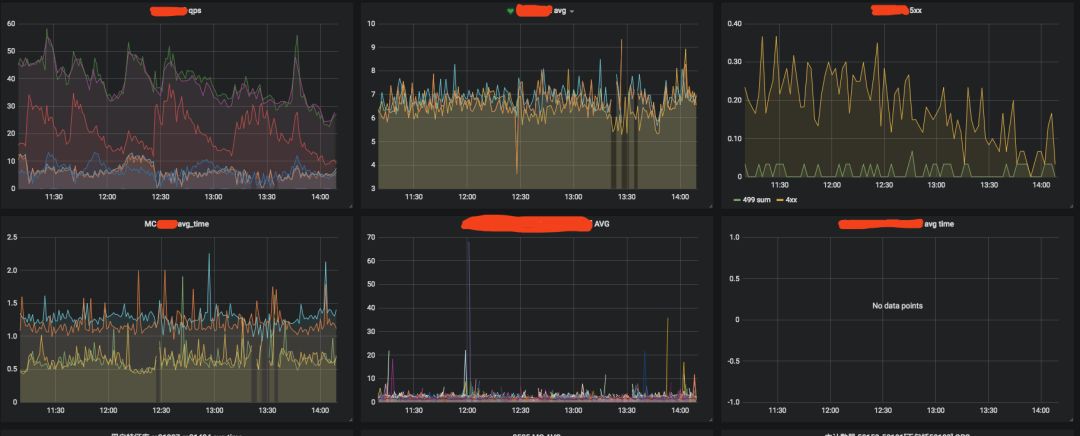
圖十
3. 容器使用物理資源監控:CPU、記憶體、IOPS、頻寬、負載、網路等基礎監控資訊,由於已有一套監控體系,修改了的實現把原先需要集中處理的部分落在了計算節點本地,然後透過已有的物理機監控資料推送到遠端監控上。一來避免了之前Heapster結構中的單點問題,二來可以復用現有的日誌推送架構。(見圖十一)
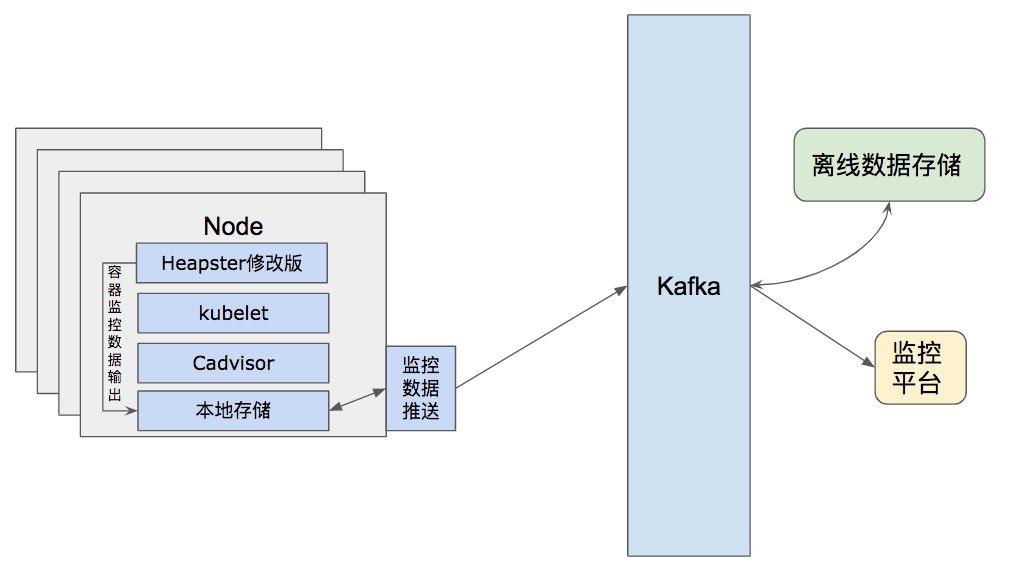
圖十一
4. Kubernetes 元件監控:包括單機的kubelet介面耗時、成功率監控、日誌中err、warn監控,同樣包括master節點的同類資料監控
基礎平臺的建設不限於上述的部分,還做了鑒權,DNS最佳化等相關服務。限於篇幅不便展開,於此同時微博平臺Kubernetes也在積極的與社群保持迭代,爭取做到能回饋社群。
四、業務落地
2019年春晚期間,後端服務支援紅包飛業務,如果按照傳統方式需要近百臺的公有雲裝置按需成本。我們透過把垂直業務從大容器中抽離形成微服務,利用Kubernetes PaaS整合能力,在未增加資源成本的情況下完成春晚紅包飛保障。
目前有6大服務池接入Kubernetes PaaS,共管理數千核CPU,數TB記憶體的計算資源。透過Kubernetes整合閑散資源與合理的混合部署,可提供近整體的30%的彈性伸縮能力。
綜上,是微博平臺在探索Kubernetes與業務更好結合道路上的一些體會,實際業務接入過程中依然會有很多的挑戰。但是在團隊成員的努力下,最終實現了方案的落地並保障了春晚的線上業務的穩定。透過這次的平臺建設充分體會到只有和業務結合,並且服務好業務才能更好的促進自身架構的成長,很多時候看似很完美的方案,面對真實的業務需求還是會出現紕漏。我們會吸取歷史的教訓,總結經驗。爭取利用先進的技術來為公司創造更大的價值。
五、展望未來
未來我們將長期執行混合部署的微服務架構,最佳化排程系統,對接更多的IAAS層提供商。更進一步提高介面可用性和資源利用率,也會對服務的穩定性和資源的利用率做進一步探索,利用技術提升研發效率也是我們後續的方向。在探索的同時我們也會對ServiceMesh、Serverless持續關註,結合著業務需求,更進一步最佳化容器基礎平臺。

