
騰訊 AI Lab 主導提出一種新的影片再定位方法,能在多個備選影片中快速找到希望搜尋的片段。該研究論文被頂級會議 ECCV 2018 收錄,以下是技術詳細解讀。
ECCV(European Conference on Computer Vision,計算機視覺歐洲大會)將於 9 月 8 日-14 日在德國慕尼黑舉辦,該會議與 CVPR、ICCV 共稱為計算機視覺領域三大頂級學術會議,每年錄用論文約 300 篇。AI Lab 是第二次參與該會議,錄取文章數高達 19 篇,位居國內前列。在剛結束的計算機視覺領域另外兩大會議 CVPR,ICCV 中也收穫頗豐,分別錄取 21 篇和 7 篇論文。
■ 論文 | Video Re-localization
■ 連結 | https://www.paperweekly.site/papers/2272
■ 作者 | Yang Feng / Lin Ma / Wei Liu / Tong Zhang / Jiebo Luo
該研究由騰訊 AI Lab 主導,與美國羅切斯特大學(University of Rochester)合作完成,研究目的是在給定一個欲搜尋的影片後,在某個備選影片中,快速找到與搜尋影片語意相關的片段,這在影片處理研究領域仍屬空白。
因此本文定義了一個新任務——影片再定位(Video Re-localization),重組 ActivityNet 資料集影片,生成了一個符合研究需求的新資料集,並提出一種交叉過濾的雙線性匹配模型,實驗已證明瞭其有效性。
目前應用最廣泛的影片檢索方法是基於關鍵字的影片檢索,這種檢索方法依賴人工標記,而人工標記不能涵蓋影片的所有內容。基於內容的影片檢索(CBVR)可以剋服上述不足,但是 CBVR 方法一般傳回完整的影片,並不會傳回具體的相關內容的位置。行為定位(Action Localization)方法可以定位到具體行為在影片當中發生的位置,但是這類方法一般只能定位某些具體的行為類別。

▲ 圖1:一段查詢影片(上)和兩段備選影片(中、下)。與查詢影片相關的片段已經用綠色方框標出。
圖 1 當中有三段影片,當給定圖 1 中的查詢影片之後,如何在兩個備選影片當中找到與查詢影片語意相關的片段?
已有的影片處理方法並不能很好的解決這個問題。比如,影片複製檢測(Video Copy Detection)方法只能檢測同一段影片出現的不同位置,複製檢測不能處理圖 1 當中的場景變化和動作角色變化的情況。另外,也很難用行為定位方法來解決這個問題,因為訓練行為定位的模型需要大量的行為樣本資料,在圖 1 的例子當中,我們只有一個資料樣本。
思路
為瞭解決這類問題,我們定義了一項新的任務,任務的名字是影片再定位。在給定一段查詢影片和一段備選影片之後,影片再定位的標的是快速的在備選影片當中定位到與查詢影片語意相關的影片片段。
要解決影片再定位問題,面臨的第一個困難是缺少訓練資料。雖然目前有很多影片資料集,但是它們都不適合影片再定位研究。訓練影片再定位模型,需要成對的查詢影片和備選影片,並且備選影片當中需要有和查詢影片語意相關的片段,相關片段的起始點和終止點也需要標註出來。
收集這樣的訓練資料費時費力。為了得到訓練資料,我們決定重新組織現有的資料集,來生成一個適合影片再定位研究的新資料集。經過調研,我們決定使用 ActivityNet 資料集當中的影片,來構建新資料集。
ActivityNet 資料集當中包含 200 類行為,我們認為同一個類別下的兩個行為片段是互相語意相關的。在 ActivityNet 資料集當中,每類行為的樣本被劃分到訓練集,驗證集和測試集。因為影片再定位並不侷限在一些特定的類別,這種劃分並不適合影片再定位任務。
因此,我們決定根據行為的類別,來劃分訓練集,驗證集和測試集。我隨機選取了 160 類行為作為訓練用,其餘的 20 類行為做驗證用,再剩餘的 20 類行為做測試用。經過一系列的影片預處理和篩選,我們得到了近 10000 個可用的影片。在訓練的過程當中,我們隨機的選擇同一行為類別的兩個影片,分別作為查詢影片和備選影片。測試的時候,我們固定了查詢影片和備選影片的組合。圖 2 展示了本文構建的資料集中每部分影片樣本的數量。

▲ 圖2:本文構建的資料集當中,每類行為當中的影片樣本個數。綠色,藍色和紅色分別表示訓練,驗證和測試用的影片。
模型
為瞭解決影片再定位問題,我們提出了一種交叉過濾的雙線性匹配模型。對於給定一段查詢影片以及一段備選影片,我們首先分別對查詢影片和備選影片進行特徵提取,然後將查詢影片使用註意力機制合併成一個特徵向量用於與備選影片匹配。匹配的時候,我們過濾掉不相關的資訊,提取相關的資訊,然後用雙向 LSTM 來生成匹配結果。最後,我們把匹配結果整合,輸出預測的起始點和終止點的機率。
接下來,我們著重介紹模型中具有創新性的交叉過濾機制,雙向性匹配機制,以及定位層。

▲ 圖3:模型的框架圖
交叉過濾 (Cross Gating)
因為在備選影片當中有很多我們不關心的內容,所以在匹配的過程當中,我們需要一種過濾機制來去除不相關的內容。我們根據當前的查詢影片的特徵,來生成一個過濾門,用來過濾備選影片。相應的,我們根據備選影片的特徵,來生成另外一個過濾門,來過濾查詢影片。

這裡的 σ 表示 sigmoid 函式,⊙ 表示對對應位相乘,![]() 、
、![]() 、
、![]() 、
、![]() 是模型的引數。
是模型的引數。![]() 和
和![]() 分別是備選影片和查詢影片的特徵表示。
分別是備選影片和查詢影片的特徵表示。
雙線性匹配 (Bilinear Matching)
在得到查詢影片和備選影片的特徵表示之後,傳統的方法將他們拼接到一起,然後輸入到神經網路來計算匹配結果。直接的拼接的方法,並不能很好的得到影片中相關的內容,所以我們採用雙線性匹配的方法來代替拼接,來更加全面的獲取影片的相關內容。
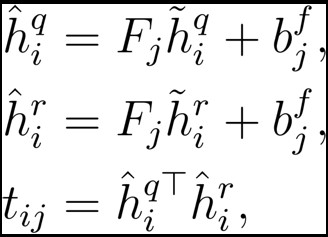
上式中,![]() 、
、![]() 是模型的引數。
是模型的引數。
定位層(Localization)
根據影片匹配結果,我們來預測備選影片當中每個時間點是開始點和結束點的機率。除此之外,我們還預測了一個時間點是在相關影片片段之內或者不在相關影片片段之內的機率。
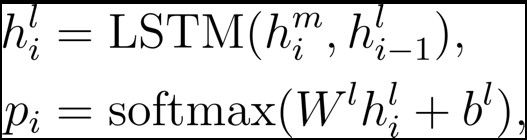
其中,![]() 是 LSTM 的隱含狀態,
是 LSTM 的隱含狀態,![]() 、
、![]() 是模型的引數,
是模型的引數,![]() 是上一層匹配得到的結果。在預測的時候,我們選擇聯合機率最大的影片片段。
是上一層匹配得到的結果。在預測的時候,我們選擇聯合機率最大的影片片段。
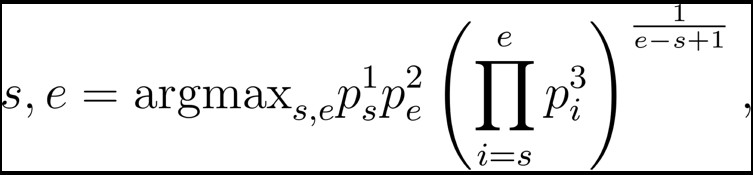
其中,![]() 是第 s 個時間點是影片片段的起始點的機率,
是第 s 個時間點是影片片段的起始點的機率,![]() 是第 e 個時間點是影片片段的終止點的機率,
是第 e 個時間點是影片片段的終止點的機率,![]() 是第 i 個時間點是影片片段中的一個時間點的機率。
是第 i 個時間點是影片片段中的一個時間點的機率。
實驗
在實驗當中,我們設計了三種基線方法。第一個基線方法根據影片幀之間的相似度,計算兩個影片片段的相關程度。第二個基線方法把每個影片編碼成一個特徵向量,然後用特徵向量的距離表示兩段影片的相關程度。第三個基線方法沒有使用查詢影片,僅根據備選影片選擇最有可能包含行為的影片片段。
在新構建的資料集上定位的定量結果如表 1 所示。另外,一些定性的結果如圖 4 所示。可以看到我們提出的方法取得的較優的定位結果。

▲ 表1. 不同方法的定位結果

▲ 圖4. 定性結果

點選以下標題檢視更多論文解讀:
 #投 稿 通 道#
#投 稿 通 道#
讓你的論文被更多人看到
如何才能讓更多的優質內容以更短路徑到達讀者群體,縮短讀者尋找優質內容的成本呢? 答案就是:你不認識的人。
總有一些你不認識的人,知道你想知道的東西。PaperWeekly 或許可以成為一座橋梁,促使不同背景、不同方向的學者和學術靈感相互碰撞,迸發出更多的可能性。
PaperWeekly 鼓勵高校實驗室或個人,在我們的平臺上分享各類優質內容,可以是最新論文解讀,也可以是學習心得或技術乾貨。我們的目的只有一個,讓知識真正流動起來。
? 來稿標準:
• 稿件確系個人原創作品,來稿需註明作者個人資訊(姓名+學校/工作單位+學歷/職位+研究方向)
• 如果文章並非首發,請在投稿時提醒並附上所有已釋出連結
• PaperWeekly 預設每篇文章都是首發,均會新增“原創”標誌
? 投稿郵箱:
• 投稿郵箱:hr@paperweekly.site
• 所有文章配圖,請單獨在附件中傳送
• 請留下即時聯絡方式(微信或手機),以便我們在編輯釋出時和作者溝通
?
現在,在「知乎」也能找到我們了
進入知乎首頁搜尋「PaperWeekly」
點選「關註」訂閱我們的專欄吧
關於PaperWeekly
PaperWeekly 是一個推薦、解讀、討論、報道人工智慧前沿論文成果的學術平臺。如果你研究或從事 AI 領域,歡迎在公眾號後臺點選「交流群」,小助手將把你帶入 PaperWeekly 的交流群裡。

▽ 點選 | 閱讀原文 | 下載論文