來源:戀習Python(ID:sldata2017
作者,何坦瑨,個人簡介|我在山上寫程式碼,過渡金屬鋰鈉鉀
知乎連結|https://zhuanlan.zhihu.com/p/42470066
殺G之路漫漫,求索之人蹌蹌。如何邊看電影邊記單詞,娛樂學習兩不誤?且讓大資料告訴我們,究竟哪些影視作品大量出現GRE單詞?看懂多少部影視作品,就可以掌握過半GRE詞彙?
說明:GRE,全稱Graduate Record Examination,中文名稱為美國研究生入學考試,適用於除法律與商業外的各專業,由美國教育考試服務處(Educational Testing Service,簡稱ETS)主辦。GRE是世界各地的大學各類研究生院(除管理類學院,法學院)要求申請者所必須具備的一個考試成績,也是教授對申請者是否授予獎學金所依據的最重要的標準。GRE,首次由美國哈佛,耶魯,哥倫比亞,普林斯頓四所大學聯合舉辦,初期由卡耐基基金會(Carnegie Foundation)承辦,1948年交由新成立的教育測試中心ETS負責。
【先放結論】都說沒有調查就沒有發言權,本文透過對11萬部影視作品進行大資料分析,為大家找出那些與GRE最相關的作品。原來包含最多GRE單詞的是哈姆萊特!看懂時長4小時的哈姆萊特可以幫你掌握915個GRE單詞!而掌握過半GRE詞彙,可能只需要看懂20部電影!
一、資料來源
感謝射手站長,他將15年來積累的海量字幕資料無私分享出來,供廣大群眾學習研究使用。其中包括對應於26萬部影視作品的66萬份字幕檔案,壓縮後大約75G。經過壓縮格式分類,解壓縮,字幕格式分類,編碼轉換,英文識別,資料清理等過程後,得到對應於114198部影視作品的225190份英文字幕檔案。
二、資料分析
1. 英文字幕中有多少GRE單詞?
絕大部分英文字幕包涵0-300個GRE單詞,平均值108,方差52,機率分佈如下圖。GRE單詞最多的單個字幕檔案來自於莎翁的《哈姆萊特/Hamlet》,內含915個GRE單詞,難怪讓人如痴如醉!所謂“一千個讀者,就有一千個哈姆萊特”,大概是……看到這些單詞不認識啊!所以就只好亂猜啦,然後每個人都猜得不一樣!反正本寶寶是看得醉了……

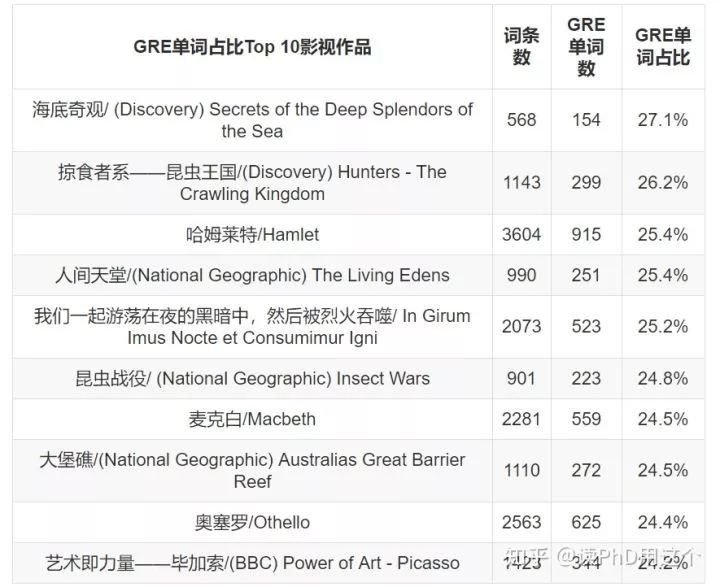
2. 最“學術”的十大影視作品
有的作品包含GRE單詞比較多,但時間也很長。到底哪些影視的“價效比”最高呢?根據GRE單詞佔所有英文詞條的比例排序,以下列出10大最“學術”(GRE單詞佔比最高)的影視作品供參考。其中有來自莎翁的作品有三部——《哈姆萊特/Hamlet》,《麥克白/Macbeth》和《奧塞羅/Othello》,平均每4個不同單詞裡面就有一個可以在紅寶書裡找到!現在,你們知道誰是真正的GRE狂魔了麼!!!
經常有一種錯覺,那些喜歡看紀錄片的同學都逼格很高。現在知道,這並不是錯覺!在top 10高頻GRE電影中,六成是來自Discovery,國家地理和BBC的紀錄片。所以,人家用來思考說話的語言就已經和凡人拉開檔次了好嘛!
3. 看電影背GRE的學習曲線
現在問題來了,走過多少路才叫做成長,最少看完多少電影才學完GRE?考慮到不同影片的單詞大量重覆,這並不是一個簡單的問題。
用數學的語言說,是給定全集U以及一個包含n個集合且這n個集合的並集為全集的集合S,要找到S的一個最小的子集,使得他們的並集等於全集,簡稱最小集合改寫,是一個經典的NP難問題。(?一臉懵逼,能不能說人話!)
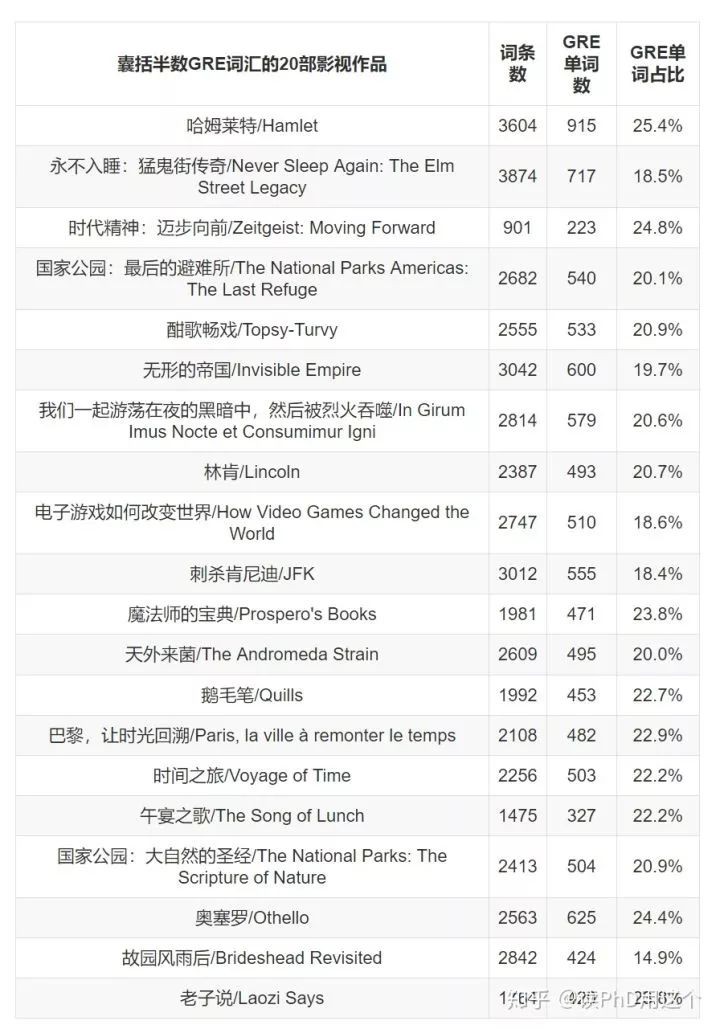
翻譯成中文就是說,這個問題很難,非常難,難到本寶寶不會,地球人到現在也沒有找到優雅的解法?……所以本寶寶就偷懶用貪心演演算法做個簡版的回答啦~如果本寶寶每次都觀看可以使當前GRE詞彙量增加最多的一部影片,那麼本寶寶的GRE學習曲線將是如下這樣,紅線表示累計學到的GRE詞彙量,綠線表示每多看一部電影可以學到的GRE新詞數目。在這時,本寶寶發現了一個秘密:如果看懂x軸上的前20部影片,本寶寶就可以掌握4143個GRE單詞,超過全部8250個GRE單詞的半數!本寶寶決定把這份電影清單分享給大家,如果想要知道特定電影的GRE單詞數目,讀者也可以私信詢問本寶寶哦~

附解壓縮所有字幕壓縮包詳情程式碼:
# gz: 即gzip。通常僅僅能壓縮一個檔案。與tar結合起來就能夠實現先打包,再壓縮。
#
# tar: linux系統下的打包工具。僅僅打包。不壓縮
#
# tgz:即tar.gz。先用tar打包,然後再用gz壓縮得到的檔案
#
# zip: 不同於gzip。儘管使用相似的演演算法,能夠打包壓縮多個檔案。只是分別壓縮檔案。壓縮率低於tar。
#
# rar:打包壓縮檔案。最初用於DOS,基於window作業系統。
import gzip
import os
import tarfile
import zipfile
import rarfile
import re
import shutil
# gz
# 因為gz一般僅僅壓縮一個檔案,全部常與其它打包工具一起工作。比方能夠先用tar打包為XXX.tar,然後在壓縮為XXX.tar.gz
# 解壓gz,事實上就是讀出當中的單一檔案
def un_gz(file_name):
"""ungz zip file"""
f_name = file_name.replace(".gz", "")
#獲取檔案的名稱,去掉
g_file = gzip.GzipFile(file_name)
#建立gzip物件
open(f_name, "w+").write(g_file.read())
#gzip物件用read()開啟後,寫入open()建立的檔案裡。
g_file.close()
#關閉gzip物件
# tar
# XXX.tar.gz解壓後得到XXX.tar,還要進一步解壓出來。
# 註:tgz與tar.gz是同樣的格式,老版本號DOS副檔名最多三個字元,故用tgz表示。
# 因為這裡有多個檔案,我們先讀取全部檔案名稱。然後解壓。例如以下:
# 註:tgz檔案與tar檔案同樣的解壓方法。
def un_tar(file_name):
# untar zip file"""
tar = tarfile.open(file_name)
names = tar.getnames()
if os.path.isdir(file_name + "_files"):
pass
else:
os.mkdir(file_name + "_files")
#因為解壓後是很多檔案,預先建立同名目錄
for name in names:
tar.extract(name, file_name + "_files/")
tar.close()
# zip
# 與tar類似,先讀取多個檔案名稱,然後解壓。例如以下:
def un_zip(file_name, destination_folder=None):
"""unzip zip file"""
zip_file = zipfile.ZipFile(file_name)
if destination_folder == None:
destination_folder = file_name + '_files'
if os.path.isdir(destination_folder):
pass
elif not os.path.exists(destination_folder):
os.makedirs(destination_folder)
else:
destination_folder = destination_folder + '_files'
os.makedirs(destination_folder)
for names in zip_file.namelist():
zip_file.extract(names, destination_folder)
zip_file.close()
# rar
# 由於rar通常為window下使用,須要額外的Python包rarfile。
#
# 可用地址: http://sourceforge.net/projects/rarfile.berlios/files/rarfile-2.4.tar.gz/download
#
# 解壓到Python安裝檔案夾的/Scripts/檔案夾下,在當前窗體開啟命令列,
#
# 輸入Python setup.py install
#
# 安裝完畢。
def un_rar(file_name, destination_folder=None):
"""unrar zip file"""
rar = rarfile.RarFile(file_name)
if destination_folder == None:
destination_folder = file_name + '_files'
if os.path.isdir(destination_folder):
pass
elif not os.path.exists(destination_folder):
os.makedirs(destination_folder)
else:
destination_folder = destination_folder + '_files'
os.makedirs(destination_folder)
# os.chdir(, destination_folder)
rar.extractall(path=destination_folder)
rar.close()
# uncompress zip and rar
def uncompress(file_name, destination_folder=None):
# status == 1 for successful
# status == 0 for error
status = 1
# find destination_folder
if destination_folder == None:
destination_folder = file_name + '_files'
# unrar
if tmp_file[-4:].lower() == '.rar':
# uncompress rar
try:
un_rar(file_name, destination_folder)
status = 1
except:
status = 0
# unzip
elif tmp_file[-4:].lower() == '.zip':
# uncompress rar
try:
un_zip(file_name, destination_folder)
status = 1
except:
status = 0
return status
# uncompress a zip and rar and also uncompress the zip and rar in sub-folders while walking through the tree
def uncompress_tree(file_name, destination_folder=None):
# status == 1 for successful
# status == 0 for error
status = 1
# find destination_folder
if destination_folder == None:
destination_folder = file_name + '_files'
# unrar
if file_name[-4:].lower() == '.rar':
# uncompress rar
try:
un_rar(file_name, destination_folder)
status = 1
except:
status = 0
# unzip
elif file_name[-4:].lower() == '.zip':
# uncompress rar
try:
un_zip(file_name, destination_folder)
status = 1
except:
status = 0
# walk through sub-folders and uncompress
if status == 1:
for root, directories, filenames in os.walk(os.path.join(destination_folder)):
# for directory in directories:
# print('directory', os.path.join(root, directory))
for tmp_file in filenames:
if tmp_file[-4:].lower() == '.rar' or tmp_file[-4:].lower() == '.zip':
status = uncompress_tree(os.path.join(root, tmp_file), os.path.join(root, tmp_file[:-4]))
os.remove(os.path.join(root, tmp_file))
if status != 1:
break
if status != 1:
break
# if status != 1 and imcomplete folder established, clean all generated files
if status != 1 and os.path.exists(destination_folder):
shutil.rmtree(destination_folder)
return status
if __name__ == '__main__':
# 0. change directory
os.chdir('.')
# 1. unzip all zip files
print('----------------------------')
print('unzip all zip files')
file_unzipped = []
for tmp_file in os.listdir('rsc'):
if os.path.isfile(os.path.join('rsc', tmp_file)):
if re.match('shooter_mirror.*\.zip', tmp_file):
un_zip(os.path.join('rsc', tmp_file),
os.path.join('generated', tmp_file[:-4]))
file_unzipped.append(tmp_file)
print('len(file_unzipped)', len(file_unzipped))
print()
# 2. rename files from zip to get sub-folders which are compresses as .rar and .zip
print('----------------------------')
print('rename all files')
# get mapping dict
with open('rsc/rename_subtitleWeb.txt', 'r') as fr:
data = fr.readlines()
map_dict = {}
for tmp_index, tmp_line in enumerate(data[:]):
if tmp_line.startswith('ren'):
tmp_data = tmp_line.strip().split()
map_dict[tmp_data[1]] = tmp_data[1] + '_' + tmp_data[2].strip('\"')
# print(map_dict)
# rename files
file_renamed = []
file_skipped = []
for tmp_folder in os.listdir('generated'):
if os.path.isdir(os.path.join('generated', tmp_folder) ):
if tmp_folder.startswith('shooter_mirror'):
for tmp_file in os.listdir(os.path.join('generated', tmp_folder)):
if os.path.isfile(os.path.join('generated', tmp_folder, tmp_file)):
if tmp_file in map_dict:
# DEBUG
# if tmp_file != '000001':
# continue
file_renamed.append(tmp_file)
os.rename(os.path.join('generated', tmp_folder, tmp_file),
os.path.join('generated', tmp_folder, map_dict[tmp_file]))
else:
file_skipped.append(tmp_file)
file_not_found = sorted(list(set(map_dict) - set(file_renamed)))
# print('file_renamed', file_renamed)
print('file_skipped', file_skipped)
# print('file_not_found', file_not_found)
print('len(file_renamed)', len(file_renamed))
print('len(file_skipped)', len(file_skipped))
print('len(map_dict)', len(map_dict))
print('len(file_not_found)', len(file_not_found))
print()
# 3. uncompress sub-folders
print('----------------------------')
print('uncompress sub-folders')
file_uncompressed = []
file_error = []
file_skipped = []
for tmp_folder in os.listdir('generated'):
if os.path.isdir(os.path.join('generated', tmp_folder) ):
if tmp_folder.startswith('shooter_mirror'):
for tmp_file in os.listdir(os.path.join('generated', tmp_folder)):
if os.path.isfile(os.path.join('generated', tmp_folder, tmp_file)):
if tmp_file[-4:].lower() == '.rar' or tmp_file[-4:].lower() == '.zip':
# uncompress rar or zip
uncompress_status = uncompress_tree(os.path.join('generated', tmp_folder, tmp_file),
os.path.join('generated', 'uncompressed_' + tmp_folder, tmp_file[:-4]))
if uncompress_status == 1:
file_uncompressed.append(tmp_file)
else:
file_error.append(tmp_file)
else:
file_skipped.append(tmp_file)
# print('file_uncompressed', file_uncompressed)
print('file_error', file_error)
print('file_skipped', file_skipped)
print('len(file_uncompressed)', len(file_uncompressed))
print('len(file_error)', len(file_error))
print('len(file_skipped)', len(file_skipped))
Take away
1. 看懂時長4小時的哈姆萊特就可以幫你掌握915個GRE單詞哦!
2. GRE成績最好的那個同學可能是威廉·莎士比亞。
3. 看紀錄片提高逼數是可以有科學原理的!
4. 學完半數GRE單詞可能只需看懂20部劇作。
註1:並不保證看電影學英語是最高效的GRE的備考方法。
註2:因字幕版本,檔案格式,內容分節等原因,有的作品對應有若干份字幕。
註3:本寶寶蒐集了網上不同版本的GRE詞彙串列,合併起來共8250個單詞。
●編號502,輸入編號直達本文
●輸入m獲取文章目錄

Web開發
更多推薦《18個技術類微信公眾號》
涵蓋:程式人生、演演算法與資料結構、駭客技術與網路安全、大資料技術、前端開發、Java、Python、Web開發、安卓開發、iOS開發、C/C++、.NET、Linux、資料庫、運維等。