隨著大資料時代的到來,越來越多的網站、應用系統需要支撐海量資料儲存,高併發、高可用、高可擴充套件性等特性要求。

傳統的關係型資料庫在應付這些已經顯得力不從心,並暴露了許多難以剋服的問題。
由此,各種各樣的 NoSQL(Not Only SQL)資料庫作為傳統關係型資料的一個有力補充得到迅猛發展。

本文將分析傳統資料庫存在的一些問題,以及幾大類 NoSQL 如何解決這些問題,希望給大家提供一些在不同業務場景下儲存技術選型方面的參考。
傳統資料庫的缺點
傳統的資料庫有如下幾個缺點:
-
大資料場景下 I/O 較高,因為資料是按行儲存,即使只針對其中某一列進行運算,關係型資料庫也會將整行資料從儲存裝置中讀入記憶體,導致 I/O 較高。
-
儲存的是行記錄,無法儲存資料結構。
-
表結構 Schema 擴充套件不方便,如要修改表結構,需要執行 DDL(data definition language),陳述句修改,修改期間會導致鎖表,部分服務不可用。
-
全文搜尋功能較弱,關係型資料庫下只能夠進行子字串的匹配查詢,當表的資料逐漸變大的時候,like 查詢的匹配會非常慢,即使在有索引的情況下。況且關係型資料庫也不應該對文字欄位進行索引。
-
儲存和處理複雜關係型資料功能較弱,許多應用程式需要瞭解和導航高度連線資料之間的關係,才能啟用社交應用程式、推薦引擎、欺詐檢測、知識圖譜、生命科學和 IT/網路等用例。
然而傳統的關係資料庫並不善於處理資料點之間的關係。它們的表格資料模型和嚴格的樣式使它們很難新增新的或不同種類的關聯資訊。
NoSQL 解決方案
NoSQL,泛指非關係型的資料庫,可以理解為 SQL 的一個有力補充。
在 NoSQL 許多方面效能大大優於非關係型資料庫的同時,往往也伴隨一些特性的缺失,比較常見的是事務庫事務功能的缺失。
資料庫事務正確執行的四個基本要素 ACID 如下:

下麵介紹 5 大類 NoSQL 資料針對傳統關係型資料庫的缺點和提供的解決方案:
列式資料庫
列式資料庫是以列相關儲存架構進行資料儲存的資料庫,主要適合於批次資料處理和即時查詢。
相對應的是行式資料庫,資料以行相關的儲存體系架構進行空間分配,主要適合於小批次的資料處理,常用於聯機事務型資料處理。
基於列式資料庫的列列儲存特性,可以解決某些特定場景下關係型資料庫 I/O 較高的問題。
基本原理
傳統關係型資料庫是按照行來儲存資料庫,稱為“行式資料庫”,而列式資料庫是按照列來儲存資料。
將表放入儲存系統中有兩種方法,而我們絕大部分是採用行儲存的。行儲存法是將各行放入連續的物理位置,這很像傳統的記錄和檔案系統。
列儲存法是將資料按照列儲存到資料庫中,與行儲存類似。下圖是兩種儲存方法的圖形化解釋:

常見列式資料庫

HBase:是一個開源的非關係型分散式資料庫(NoSQL),它參考了谷歌的 BigTable 建模,實現的程式語言為 Java。
它是 Apache 軟體基金會的 Hadoop 專案的一部分,執行於 HDFS 檔案系統之上,為 Hadoop 提供類似於 BigTable 規模的服務。因此,它可以容錯地儲存海量稀疏的資料。

BigTable:是一種壓縮的、高效能的、高可擴充套件性的,基於 Google 檔案系統(Google File System,GFS)的資料儲存系統,用於儲存大規模結構化資料,適用於雲端計算。
相關特性
優點如下:
高效的儲存空間利用率:列式資料庫由於其針對不同列的資料特徵而發明的不同演演算法使其往往有比行式資料庫高的多的壓縮率。
普通的行式資料庫一般壓縮率在 3:1 到 5:1 左右,而列式資料庫的壓縮率一般在 8:1 到 30:1 左右。
比較常見的,透過字典表壓縮資料: 下麵中才是那張表本來的樣子。經過字典表進行資料壓縮後,表中的字串才都變成數字了。
正因為每個字串在字典表裡只出現一次了,所以達到了壓縮的目的(有點像規範化和非規範化 Normalize 和 Denomalize)。

查詢效率高:讀取多條資料的同一列效率高,因為這些列都是儲存在一起的,一次磁碟操作可以把資料的指定列全部讀取到記憶體中。
下圖透過一條查詢的執行過程說明列式儲存(以及資料壓縮)的優點。

執行步驟如下:
-
去字典表裡找到字串對應數字(只進行一次字串比較)。
-
用數字去串列裡匹配,匹配上的位置設為 1。
-
把不同列的匹配結果進行位運算得到符合所有條件的記錄下標。
-
使用這個下標組裝出最終的結果集。
列式資料庫還適合做聚合操作,適合大量的資料而不是小資料。
缺點如下:
-
不適合掃描小量資料。
-
不適合隨機的更新。
-
不適合做含有刪除和更新的實時操作。
-
單行的資料是 ACID 的,多行的事務時,不支援事務的正常回滾,支援 I(Isolation)隔離性(事務序列提交),D(Durability)永續性,不能保證 A(Atomicity)原子性, C(Consistency)一致性。
使用場景
以 HBase 為例說明:
-
大資料量(100s TB級資料),且有快速隨機訪問的需求。
-
寫密集型應用,每天寫入量巨大,而相對讀數量較小的應用,比如 IM 的歷史訊息,遊戲的日誌等等。
-
不需要複雜查詢條件來查詢資料的應用,HBase 只支援基於 rowkey 的查詢,對於 HBase 來說,單條記錄或者小範圍的查詢是可以接受的。
大範圍的查詢由於分散式的原因,可能在效能上有點影響,HBase 不適用於有 join,多級索引,表關係複雜的資料模型。
-
對效能和可靠性要求非常高的應用,由於 HBase 本身沒有單點故障,可用性非常高。
-
資料量較大,而且增長量無法預估的應用,需要進行優雅的資料擴充套件的 HBase 支援線上擴充套件,即使在一段時間內資料量呈井噴式增長,也可以透過 HBase 橫向擴充套件來滿足功能。
-
儲存結構化和半結構化的資料。
K-V 資料庫
指的是使用鍵值(key-value)儲存的資料庫,其資料按照鍵值對的形式進行組織、索引和儲存。
K-V 儲存非常適合不涉及過多資料關係業務關係的資料,同時能有效減少讀寫磁碟的次數,比 SQL 資料庫儲存擁有更好的讀寫效能,能夠解決關係型資料庫無法儲存資料結構的問題。
常見 K-V 資料庫

Redis:是一個使用 ANSI C 編寫的開源、支援網路、基於記憶體、可選永續性的鍵值對儲存資料庫。
從 2015 年 6 月開始,Redis 的開發由 Redis Labs 贊助,而 2013 年 5 月至 2015 年 6 月期間,其開發由 Pivotal 贊助。
在 2013 年 5 月之前,其開發由 VMware 贊助。根據月度排行網站 DB-Engines.com 的資料顯示,Redis 是最流行的鍵值對儲存資料庫。

Cassandra:Apache Cassandra(社群內一般簡稱為C*)是一套開源分散式 NoSQL 資料庫系統。
它最初由 Facebook 開發,用於儲存收件箱等簡單格式資料,集 Google BigTable 的資料模型與 Amazon Dynamo 的完全分散式架構於一身。
Facebook 於 2008 將 Cassandra 開源,此後,由於 Cassandra 良好的可擴充套件性和效能。
它被 Apple,Comcas,Instagram,Spotify,eBay,Rackspace,Netflix 等知名網站所採用,成為了一種流行的分散式結構化資料儲存方案。

LevelDB:是一個由 Google 公司所研發的鍵/值對(Key/Value Pair)嵌入式資料庫管理系統程式設計庫, 以開源的 BSD 許可證釋出。
相關特性
以 Redis 為例,K-V 資料庫優點如下:
-
效能極高:Redis 能支援超過 10W 的 TPS。
-
豐富的資料型別:Redis 支援包括 String,Hash,List,Set,Sorted Set,Bitmap 和 Hyperloglog。
-
豐富的特性:Redis 還支援 publish/subscribe,通知,key 過期等等特性。
缺點如下:
-
針對 ACID,Redis 事務不能支援原子性和永續性(A 和 D),只支援隔離性和一致性(I 和 C) 。
特別說明一下,這裡所說的無法保證原子性,是針對 Redis 的事務操作,因為事務是不支援回滾(roll back),而因為 Redis 的單執行緒模型,Redis 的普通操作是原子性的。
大部分業務不需要嚴格遵循 ACID 原則,例如遊戲實時排行榜,粉絲關註等場景,即使部分資料持久化失敗,其實業務影響也非常小。因此在設計方案時,需要根據業務特徵和要求來做選擇。
使用場景
適用場景:
-
儲存使用者資訊(比如會話)、配置檔案、引數、購物車等等。這些資訊一般都和 ID(鍵)掛鉤。
不適用場景:
-
需要透過值來查詢,而不是鍵來查詢。Key-Value 資料庫中根本沒有透過值查詢的途徑。
-
需要儲存資料之間的關係。在 Key-Value 資料庫中不能透過兩個或以上的鍵來關聯資料。
-
需要事務的支援。在 Key-Value 資料庫中故障產生時不可以進行回滾。
檔案資料庫
檔案資料庫(也稱為檔案型資料庫)是旨在將半結構化資料儲存為檔案的一種資料庫。檔案資料庫通常以 JSON 或 XML 格式儲存資料。
由於檔案資料庫的 no-schema 特性,可以儲存和讀取任意資料。
由於使用的資料格式是 JSON 或者 BSON,因為 JSON 資料是自描述的,無需在使用前定義欄位,讀取一個 JSON 中不存在的欄位也不會導致 SQL 那樣的語法錯誤,可以解決關係型資料庫表結構 Schema 擴充套件不方便的問題。
常見檔案資料庫

MongoDB:是一種面向檔案的資料庫管理系統,由 C++ 撰寫而成,以此來解決應用程式開發社群中的大量現實問題。2007 年 10 月,MongoDB 由 10gen 團隊所發展。2009 年 2 月首度推出。

CouchDB:Apache CouchDB 是一個開源資料庫,專註於易用性和成為”完全擁抱 Web 的資料庫”。
它是一個使用 JSON 作為儲存格式,JavaScript 作為查詢語言,MapReduce 和 HTTP 作為 API 的 NoSQL 資料庫。
其中一個顯著的功能就是多主複製。CouchDB 的第一個版本釋出在 2005 年,在 2008 年成為了 Apache 的專案。
相關特性
以 MongoDB 為例進行說明,檔案資料庫優點如下:
-
新增欄位簡單,無需像關係型資料庫一樣先執行 DDL 陳述句修改表結構,程式程式碼直接讀寫即可。
-
容易相容歷史資料,對於歷史資料,即使沒有新增的欄位,也不會導致錯誤,只會傳回空值,此時程式碼相容處理即可。
-
容易儲存複雜資料,JSON 是一種強大的描述語言,能夠描述複雜的資料結構。
相比傳統關係型資料庫,檔案資料庫的缺點主要是對多條資料記錄的事務支援較弱,具體體現如下:
-
Atomicity(原子性),僅支援單行/檔案級原子性,不支援多行、多檔案、多陳述句原子性。
-
Solation(隔離性),隔離級別僅支援已提交讀(Read committed)級別,可能導致不可重覆讀,幻讀的問題。
-
不支援複雜查詢,例如 join 查詢,如果需要 join 查詢,需要多次運算元據庫。
MongonDB 還支援多檔案事務的 Consistency(一致性)和 Durability(永續性),雖然官方宣佈 MongoDB 將在 4.0 版本中正式推出多檔案 ACID 事務支援,最後落地情況還有待見證。
使用場景
適用場景:
-
資料量很大或者未來會變得很大。
-
表結構不明確,且欄位在不斷增加,例如內容管理系統,資訊管理系統。
不適用場景:
-
在不同的檔案上需要新增事務。Document-Oriented 資料庫並不支援檔案間的事務。
-
多個檔案之間需要複雜查詢,例如 join。
全文搜尋引擎
傳統關係型資料庫主要透過索引來達到快速查詢的目的,在全文搜尋的業務下,索引也無能為力,主要體現在:
-
全文搜尋的條件可以隨意排列組合,如果透過索引來滿足,則索引的數量非常多。
-
全文搜尋的模糊匹配方式,索引無法滿足,只能用 like 查詢,而 like 查詢是整表掃描,效率非常低。
而全文搜尋引擎的出現,正是解決關係型資料庫全文搜尋功能較弱的問題。
基本原理
全文搜尋引擎的技術原理稱為“倒排索引”(inverted index),是一種索引方法,其基本原理是建立單詞到檔案的索引。與之相對的是“正排索引”,其基本原理是建立檔案到單詞的索引。
現在有如下檔案集合:

正排索引得到索引如下:

由上可見,正排索引適用於根據檔名稱查詢檔案內容。簡單的倒排索引如下:
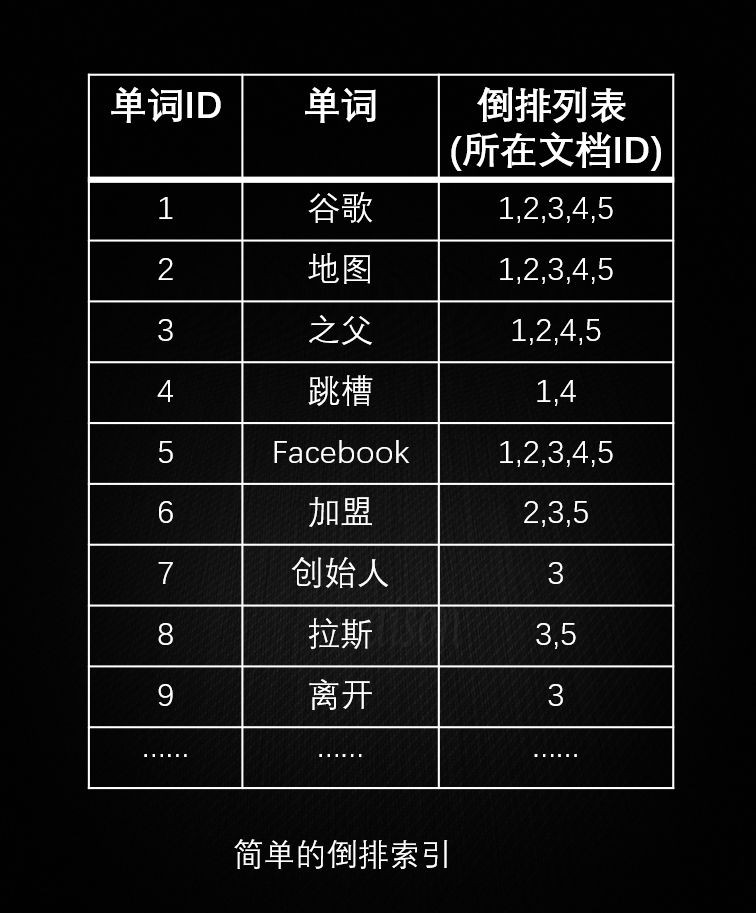
帶有單詞頻率資訊的倒排索引如下:

由上可見,倒排索引適用於根據關鍵詞來查詢檔案內容。
常見全文搜尋引擎

Elasticsearch:是一個基於 Lucene 的搜尋引擎。它提供了一個分散式,多租戶,能夠全文搜尋與發動機 HTTP Web 介面和無架構 JSON 檔案。
Elasticsearch 是用 Java 開發的,並根據 Apache License 的條款作為開源釋出。
根據 DB-Engines 排名,Elasticsearch 是最受歡迎的企業搜尋引擎,後面是基於 Lucene 的 Apache Solr。

Solr:是 Apache Lucene 專案的開源企業搜尋平臺。其主要功能包括全文檢索、命中標示、分面搜尋、動態聚類、資料庫整合,以及富文字(如 Word、PDF)的處理。Solr 是高度可擴充套件的,並提供了分散式搜尋和索引複製。
相關特性
以 Elasticsearch 為例,全文搜尋引擎優點如下:
-
查詢效率高,對海量資料進行近實時的處理。
-
可擴充套件性,基於叢集環境可以方便橫向擴充套件,可以承載 PB 級資料。
-
高可用,Elasticsearch 叢集彈性,他們將發現新的或失敗的節點,重組和重新平衡資料,確保資料是安全的和可訪問的。
缺點如下:
-
ACID 支援不足,單一檔案的資料是 ACID 的,包含多個檔案的事務時不支援事務的正常回滾,支援 I(Isolation)隔離性(基於樂觀鎖機制的),D(Durability)永續性,不支援 A(Atomicity)原子性,C(Consistency)一致性。
-
對類似資料庫中透過外來鍵的複雜的多表關聯操作支援較弱。
-
讀寫有一定延時,寫入的資料,最快 1s 中能被檢索到。
-
更新效能較低,底層實現是先刪資料,再插入新資料。
-
記憶體佔用大,因為 Lucene 將索引部分載入到記憶體中。
使用場景
適用場景如下:
-
分散式的搜尋引擎和資料分析引擎。
-
全文檢索,結構化檢索,資料分析。
-
對海量資料進行近實時的處理,可以將海量資料分散到多臺伺服器上去儲存和檢索。
不適用場景如下:
-
資料需要頻繁更新。
-
需要複雜關聯查詢。
圖形資料庫

圖形資料庫應用圖形理論儲存物體之間的關係資訊。最常見例子就是社會網路中人與人之間的關係。
關係型資料庫用於儲存“關係型”資料的效果並不好,其查詢複雜、緩慢、超出預期。
而圖形資料庫的獨特設計恰恰彌補了這個缺陷,解決關係型資料庫儲存和處理複雜關係型資料功能較弱的問題。
常見圖形資料庫

Neo4j:是由 Neo4j,Inc. 開發的圖形資料庫管理系統。由其開發人員描述為具有原生圖儲存和處理的符合 ACID 的事務資料庫,根據 DB-Engines 排名,Neo4j 是最流行的圖形資料庫。

ArangoDB:是由 triAGENS GmbH 開發的原生多模型資料庫系統。資料庫系統支援三個重要的資料模型(鍵/值,檔案,圖形),其中包含一個資料庫核心和統一查詢語言 AQL(ArangoDB 查詢語言)。
查詢語言是宣告性的,允許在單個查詢中組合不同的資料訪問樣式。ArangoDB 是一個 NoSQL 資料庫系統,但 AQL 在很多方面與 SQL 類似。

Titan:是一個可擴充套件的圖形資料庫,針對儲存和查詢包含分佈在多機群集中的數百億個頂點和邊緣的圖形進行了最佳化。
Titan 是一個事務性資料庫,可以支援數千個併發使用者實時執行複雜的圖形遍歷。
相關特性
以 Neo4j 為例,Neo4j 使用資料結構中圖(graph)的概念來進行建模。Neo4j 中兩個最基本的概念是節點和邊。
節點表示物體,邊則表示物體之間的關係。節點和邊都可以有自己的屬性。不同物體透過各種不同的關係關聯起來,形成複雜的物件圖。
針對關係資料,兩種資料庫的儲存結構不同:
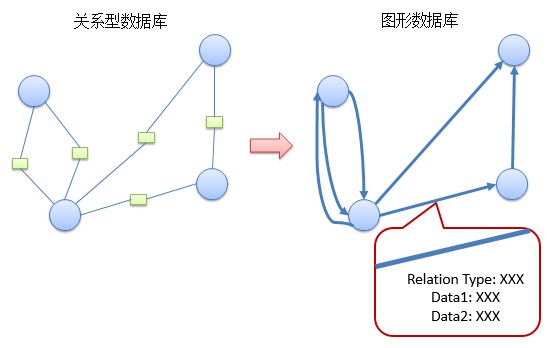
Neo4j 中,儲存節點時使用了“index-free adjacency”,即每個節點都有指向其鄰居節點的指標,可以讓我們在 O(1) 的時間內找到鄰居節點。
另外,按照官方的說法,在 Neo4j 中邊是最重要的,即“first-class entities”,所以單獨儲存,這有利於在圖遍歷的時候提高速度,也可以很方便地以任何方向進行遍歷。

優點如下:
-
高效能表現,圖的遍歷是圖資料結構所具有的獨特演演算法,即從一個節點開始,根據其連線的關係,可以快速和方便地找出它的鄰近節點。
這種查詢資料的方法並不受資料量的大小所影響,因為鄰近查詢始終查詢的是有限的區域性資料,不會對整個資料庫進行搜尋。
-
設計的靈活性,資料結構的自然伸展特性及其非結構化的資料格式,讓圖資料庫設計可以具有很大的伸縮性和靈活性。
因為隨著需求的變化而增加的節點、關係及其屬性並不會影響到原來資料的正常使用。
-
開發的敏捷性,直觀明瞭的資料模型,從需求的討論開始,到程式開發和實現,以及最終儲存在資料庫中的樣子,它的模樣似乎沒有什麼變化,甚至可以說本來就是一模一樣的。
-
完全支援 ACID,不像別的 NoSQL 資料庫,Neo4j 還具有完全事務管理特性,完全支援 ACID 事務管理。
缺點如下:
-
具有支援節點,關係和屬性的數量的限制。
-
不支援拆分。
使用場景
適用場景如下:
-
在一些關係性強的資料中,例如社交網路。
-
推薦引擎。如果我們將資料以圖的形式表現,那麼將會非常有益於推薦的制定。
不適用場景如下:
-
記錄大量基於事件的資料(例如日誌條目或感測器資料)。
-
對大規模分散式資料進行處理,類似於 Hadoop。
-
適合於儲存在關係型資料庫中的結構化資料。
-
二進位制資料儲存。
總結
關係型資料庫和 NoSQL 資料庫的選型,往往需要考慮幾個指標:
-
資料量
-
併發量
-
實時性
-
一致性要求
-
讀寫分佈和型別
-
安全性
-
運維成本
常見軟體系統資料庫選型參考如下:
-
內部使用的管理型系統,如運營系統,資料量少,併發量小,首選考慮關係型。
-
大流量系統,如電商單品頁,後臺考慮選關係型,前臺考慮選記憶體型。
-
日誌型系統,原始資料考慮選列式,日誌搜尋考慮選倒排索引。
-
搜尋型系統,例如站內搜尋,非通用搜索,如商品搜尋,後臺考慮選關係型,前臺考慮選倒排索引。
-
事務型系統,如庫存,交易,記賬,考慮選關係型+快取+一致性型協議。
-
離線計算,如大量資料分析,考慮選列式或者關係型也可以。
-
實時計算,如實時監控,可以考慮選記憶體型或者列式資料庫。
在設計實踐中,我們要基於需求、業務驅動架構,無論選用 RDB/NoSQL/DRDB,一定是以需求為導向,最終資料儲存方案必然是各種權衡的綜合性設計。
參考資料:
-
從0開始學架構 —— Alibaba 李運華
-
NoSQL漫談
-
圖形資料庫 Neo4j 開發實戰
-
大資料時代的 9 大Key-Value儲存資料庫
-
事務—— Redis官方檔案
-
MongoDB是如何實現事務的ACID?
-
MySQL臟讀、虛讀、幻讀
-
全面梳理關係型資料庫和 NoSQL 的使用情景
-
淺析列式資料庫的特點
-
一分鐘搞懂列式與行式資料庫
-
HBase 基本概念
-
NoSQL Databases, why we should use, and which one we should choose
-
傳統關係資料庫與分散式資料庫知識點
作者:陳彩華
編輯:陶家龍、孫淑娟
陳彩華(caison),主要從事服務端開發、需求分析、系統設計、最佳化重構工作,主要開發語言是 Java,現任廣州貝聊服務端研發工程師。微訊號:hua1881375。
更多近期精華文章:
本文由 51CTO技術棧 授權轉載,歡迎投稿,詳情請戳公眾號選單「聯絡我們」。
高可用架構
改變網際網路的構建方式

長按二維碼 關註「高可用架構」公眾號