(點選上方公號,快速關註我們)
來源:haolujun
www.cnblogs.com/haolujun/p/9585509.html
前言
在我們日常應用中,應該遇到不少類似的狀況:
-
寫檔案時,單詞拼寫錯誤後,工具自動推薦一個相似且正確的拼寫形式;
-
使用搜狗輸入法時,敲錯某個字的拼音照樣能夠打出我們想要的漢字;
-
利用搜索引擎進行搜尋時,下拉框中自動列出與輸入相近的詞語。
-
等等,不一一列舉。
這種功能是如何實現的呢?裡面用到了哪些演演算法呢?本文就來介紹一個能夠完成這個任務的演演算法。
問題描述
其實,這幾個問題都能夠轉換成同一個問題:即對於給定的輸入字串T,在預先準備好的樣式串集合Q中找到與輸入串相似的樣式串子集。
那麼如何得到準備好的這些樣式串集合呢?我們可以透過資料挖掘等一些機制來得到。
那麼接下來的問題就是如何快速的從這個集合中找到與輸入串相似的字串?通常我們用最小編輯距離來表示兩個字串的相似程度。
例如,對於輸入串T,我們限制錯誤數小於等於2,即在預先準備好的樣式集合中找所有與輸入串編輯距離小於等於2的字串。
有什麼演演算法能夠快速完成這個任務呢?
暴力演演算法
遍歷集合Q中的每個樣式串P,分別計算其與輸入串T的最小編輯距離,如果編輯距離小於指定的錯誤容忍度x,則輸出這個樣式串。
-
時間複雜度:O(|Q| * n * m),當|Q|很大時,速度將會很慢。
那麼這個演演算法可以最佳化麼?可以!
比如,第一個字很少有人輸入錯,所以我們可以在樣式串集合Q中只對第一個字與輸入串第一個字相同的那些字串進行相似度計算,這樣就能夠減少相當多的算量,是一個可行方法。
但是這也有問題,假若少部分人確實第一個字輸入錯了,那麼這個演演算法找到的所有串也是錯的,不能達到糾錯的效果。
所以,針對首字元過濾的最佳化演演算法有一定的侷限性。
步步最佳化
我們仔細思考這個問題,由於樣式串Q是一個集合,那麼其中必定有大量的樣式串有共同的字首。能否利用這個字首進行最佳化呢?
最佳化1: 利用兩個詞的相同字首進行最佳化
比如:字串 explore和explain,他們有公共的字首,這就意味著他們與字串explode的編輯矩陣的前幾列值是相同的,不用重覆計算,如下圖紅色部分所示。

explore與explain無論與任何字串計算編輯距離,編輯矩陣的前4列肯定一模一樣。所以,如果我們已經計算過explore與某個串的編輯距離後,那麼當計算該串與explain的編輯距離時,前4列可以復用,直接從第五列開始計算。
到此,我們得到一個新的演演算法計算多樣式的編輯距離:把樣式串集合建立成一棵字典樹,深度優先遍歷這棵樹,在遍歷的過程中,不斷更新編輯矩陣的某一個列,如果到達的節點是一個終結符,並且T與P(路徑上的字元形成的字串)的編輯距離小於指定的容忍度,則找到一個符合條件的串。
最佳化2:剪枝
雖然我們利用詞字首優化了演演算法,能夠避免擁有相同字首樣式串的編輯矩陣的重覆計算,但是必須要遍歷所有節點。有沒有什麼辦法能夠在計算到某一深度後,根據一些限制條件能夠剪去該子樹其它剩餘節點的計算呢?在搜尋演演算法中,這種最佳化叫做剪枝。接下來我們討論一下該如何設計一個剪枝函式。
重新審視我們的編輯距離定義,其實可以看成是把字串P和T分別拆分成兩段,然後計算對應的段的編輯距離之和,如下圖所示。

字串P和T分別拆分成兩段,紅色和綠色。紅色部分之間的編輯距離與綠色部分之間的編輯距離之和即為字串P和T的編輯距離。
舉個例子,更形象:
-
例子1

ed(“explore”, “express”) = ed(“explo”, “exp”) + ed(“re”, “ress”)
-
例子2

ed(“explore”, “express”) = ed(“exp”, “exp”) + ed(“lore”, “ress”)
-
例子3
但是,並不是每種劃分都是正確的,比如下麵圖所示:
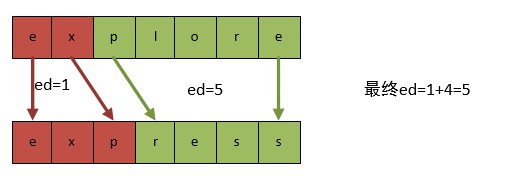
ed(“ex”,“exp”) + ed(“plore”, “ress”) = 1 + 4 = 5
所以,最小編輯距離問題又相當於一個最優拆分,即對於字串P中位置為i的字元,找到在T中的一個最優位置j,使得
ed(P.prefix(i), T.prefix(j)) + ed(P.suffix(i+1), T.suffix(j+1))
最小。
回到我們這個問題中來,如果我們限制P和T的最小編輯距離小於等於x,

我們讓 p[i]分別匹配t[i-x],t[i-x+1],……,t[i],t[i+1],……t[i+x],並找到其中前半段匹配的最小的編輯距離ed1=ed(p[1~i],t[1~j]),如果ed1大於x,我們則能推斷出ed(p,t)也終將大於x(ed=ed1+ed2>x)。
為什麼p[i]不匹配t[i-x-1]以及之前的位置呢?那是因為ed(p.prefix(i), t.prefix(i-x-1)) > x,因為必須至少在t.prefix(i-x-1)中插入x+1個字元才能保證字串長度相等;同理p[i]也不能匹配t[i+x+1]及其之後的位置。所以,根據分段原則,最優匹配肯定出現在t[i-x] ~ t[i+x]之間,如果這個區間的最小編輯距離都大於x,那麼我們無需對p[i+1]及其之後的字元進行匹配計算。
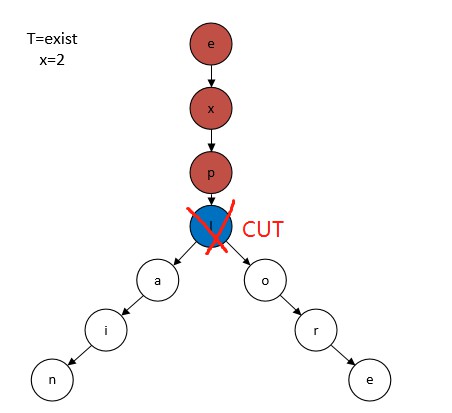
例如:當遍歷到藍色節點l時,路徑形成的字串expl與T=exist滿足剪枝條件,則後序節點不需要遍歷,因為後面不可能有任何一個字串滿足與T的編輯距離小於2。
至此,我們得到了剪枝最佳化:深度遍歷到達字典樹的某個節點,其路徑上的字元組成字串P,計算其與T.prefix(i-x), T.prefix(i-x+1),……T.prefix(i+x)的最小編輯距離,如果其中的最小值大於x,則停止遍歷這棵子樹上的後面的節點。
其實,這個最終版本的最佳化演演算法出自論文:《Error-tolerant finite-state recognition with applications to morphological analysis and spelling correction》.K Oflazer:1996
程式碼實現與效果對比
程式碼實現需需要很強的技巧性,因為無論是剪枝函式還是進行最終確認函式都可以復用同一個編輯矩陣,貼一個很醜陋的程式碼:https://github.com/haolujun/Algorithm/tree/master/muti-edit-distance
這個演演算法在錯誤容忍度非常小的情況下效率非常高,我隨機生成了10萬個長度5~10的樣式串,再隨機生成100個輸入串T(長度5 ~ 10),字符集大小為10,x最小編輯距離限制,計算多樣式編輯距離,處理總時間如下,單位ms:
| 演演算法 | x = 1 | x = 2 | x = 3 | x = 4 | x = 5 | x = 6 |
|---|---|---|---|---|---|---|
| 暴力演演算法 | 21990 | 21990 | 21990 | 21990 | 21990 | 21990 |
| 最佳化演演算法 | 97 | 922 | 4248 | 11361 | 20097 | 28000 |
當容忍度很小時,最佳化演演算法完勝暴力演演算法,並且實際應用中x一般取值都非常小,正好適合最佳化演演算法。
當x值增大,最佳化演演算法效率逐漸下降,並且最後慢於暴力演演算法,這是因為最佳化演演算法實現複雜導致(遞迴+更複雜的判斷)。
所以,最終應用時,我們根據x值選擇不同的演演算法。
【關於投稿】
如果大家有原創好文投稿,請直接給公號傳送留言。
① 留言格式:
【投稿】+《 文章標題》+ 文章連結
② 示例:
【投稿】《不要自稱是程式員,我十多年的 IT 職場總結》:
http://blog.jobbole.com/94148/
③ 最後請附上您的個人簡介哈~
覺得本文有幫助?請分享給更多人
關註「演演算法愛好者」,修煉程式設計內功

