
本文是克萊蒙奧弗涅大學發表於 ECCV 2018 的工作,作者提出了一個全新捲簾快門(Rolling Shutter)相機的姿態估計方法。
目前國內對於捲簾快門(Rolling Shutter,RS)這一人手必備的相機關註度並不是很高,因此寫了這篇 RS 相機論文的中文版解讀。希望能幫大家多瞭解一下 RS 相機在計算機視覺應用中的問題,甚至能有更多的同學老師能參與到 RS 相關的研發工作中去。
作者丨勞奕臻
學校丨克萊蒙奧弗涅大學博士生
研究方向丨SLAM / SfM
區別於先前的方法都在關註點特徵和相機自運動模型,本文作者提出了一個關於 RS 相片形變的比喻:
剛體的 3D template 在 RS 相機中的形變,可以被看作一個非剛體可形變的 3D template 被 GS 相機所捕捉。從而將 2D 照片中的形變等效到了 3D 空間中,進而使用 Shape-from-Template 技術實時重建這個一直處於形變中的虛擬 3D template,最後使用已知的 template 和每一幀重建的形變 template 做 3d-3d 註冊,從而求解出了 RS 相機的姿態和瞬時自運動引數。
本文提出的這個等效比喻第一次將 RS 姿態估計問題(RS pose estimation problem)和 非剛體三維重建(Non-rigid scene reconstructution)聯絡起來。
■ 論文 | Rolling Shutter Pose and Ego-motion Estimation using Shape-from-Template
■ 連結 | https://www.paperweekly.site/papers/2281
■ 原始碼 | Yizhen Lao / Omar Ait-Aider / Adrien Bartoli
一些關於RS的題外話
Rolling Shutter(捲簾快門, 下文簡稱 RS)是目前 CMOS 相機的標配快門方式。顧名思義,其快門的樣式是一個捲簾式的連續過程。這和在傳統 CCD 上的 Global Shutter(GS)快門樣式有很大的不同。GS 快門拍出的相片的所有畫素都是在同一個時刻曝光的,而 RS 通常則是逐行掃描的。
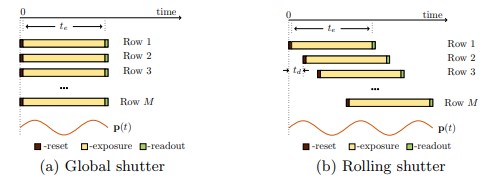
如果在拍攝瞬間,被拍攝的物體和你的相機都是靜止的,RS 拍出來的照片和 GS 當然是一樣的。但是我們可以想象一下,如果你在拍攝時移動你的 RS 相機(或者相機靜止,被拍物體在運動),那麼你拍出來的 RS 照片的每一行其實都處於不同的姿態。一個最直接的弊端就是影像中的形變(distortions, 我們也稱之為 RS effect)。

上面這幅圖(Cenek ALbl, CVPR’16)描述了拍攝瞬間不同的自運動(ego-motion)樣式所帶來的不同的形變型別。
形變首先影響了你所拍攝照片的美觀,但更要命的是,這種形變會嚴重影響使用了 RS 相片的幾何演演算法的精度。熟悉傳統 3D vision 的朋友一定讀過 Multiple View Geometry,在 MVG 中所有的相片都有一個前提假設,同一張相片上的每個畫素都具有相同的 pose。所以我們可以用經典的 P3P 解相機的絕對姿態,可以用五點或者八點法解相對位置。
現在你應該發現問題了,運動的 RS 相機不符合這個前提假設。一旦這個 RS effect 很強的話,你算什麼位置都會出問題的。如果這些基礎問題的解都不可靠的話,那你基於 RS 玩的 AR/VR,Structure from Motion (SfM),Visual Odometry (VO) 和 SLAM 都得受到影響。
那又有朋友要問了:”我不用 RS 只用 GS 不就完了嘛,我從來都沒聽說過這種相機,實際應用中肯定很少用到啊”。實際上呢,大家離 RS 相機都不遠,大概就是你到你手機的距離,因為目前市售的智慧手機攝像頭都裝備的是 RS 相機。
為什麼大家都要用 RS 相機呢?這就要說到 RS 的幾大優勢了:便宜、體積小、功耗低、更高幀率。甚至很多不缺錢的平臺也都在用 RS 拍東西,比如 Google 街景車(Klingner Bryan, ICCV’13)。
總結一下,RS 的優勢讓它非常適合在移動平臺上應用,比如手機,機器人,無人機,無人車。但是,它的逐行掃描樣式又讓它非常不適合在移動平臺上做應用。
正是基於這個矛盾點,針對 RS 相機在 CV 領域的研究越來越多。從 06 年 ECCV 上一篇關於 RS 的文章拿了 Honorable Mention Award 開始,到今年的 ECCV 為止,共有 33 篇關於 RS 的文章發表在 CVPR/ICCCV/ECCV 上,分別涉及 SfM、Pose Estimation 和 Rectification 等 7 大主題。

從 15 年開始,關於 RS 的頂會文章穩定在了每年五篇。但是其實關於 RS 的 CV 應用的坑還有很多很多。像是 SLAM with RS 現在都還沒有一個非常 work 的工作出現。目前還沒有看到國內高校或者企業的同行們關註 RS 相關的工作,所以也歡迎大家能更關註甚至投身到 RS 的 CV 應用研發中去。
論文介紹
RS Pose and Ego-motion問題
言歸正傳到這篇論文上,我們在這篇文章中主要解決的是利用已知的 3D 點(又稱 template)來估計相機姿態的問題。
在 GS 中,比較有名的有利用三個已知的 3D 點來求解相機 6 dof 的 p3p (Xiao-shan Gao, PAMI’2003)。當然對於 RS,不只有相機姿態的六個引數,還會有拍攝瞬間的 ego-motion(角速度/線速度)的引數。
這就牽扯出了關於 RS ego-motion 模型的假設。如果我們假設相片中的每一行都有一個獨立的 pose,那麼 n 行的照片就得求解 6n 個引數,這顯然是不可能實現的。有一個很好的解決方法是,為快門時間內相機的 ego-motion 設計動力學模型,這就相當於給每一行的 pose 之間設計了時空上的聯絡,從而有效地降低了要求解得引數個數。
由於快門時間其實非常非常的短,最簡單的模型就是勻速模型,假設 RS 相機在快門時間內只做勻速運動(加速度為 0)。 例如在 Omar Ait-Aider, ECCV’06 中:


將一張相片第一行的 pose 設為 [R T],則第 vi 行的 pose 應為:
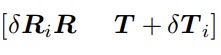
我們可以發現在這個模型中,對於一個影像來說 ego-motion 也有六個引數,分別是角速度三個和線速度三個。所以對於此模型的 RS pose and ego-motion 問題來說,求解的就是 12 dof 而不是傳統 GS pn p問題中的 6 dof 了。
相關研究
關於 RS 的 pose 求解方法可分為兩類:
1. 以 Omar Ait-Aider, ECCV’06 和 Ludovic Magerand, ECCV’12 為代表的迭代最佳化求解方法。此類方法最大的缺點就是慢,也沒辦法用 ransac 去過濾outliers;
2. 以 R6P (Cenek ALbl, CVPR’15) 為代表的 minimal solution 方法。這個是當年的 CVPR oral,作者首先對上面的勻速模型做了進一步簡化。在角速度上,假設了一張相片的 ego-motion 不超過 30 度,因此上文的羅德里德公式只取一級泰勒展開。這個近似讓整個 ego-motion 模型的先行性大大提高,他們又進一步對旋轉公式進行了線性化,這個 double-linearized model 是這樣的:

感興趣的朋友可以去讀原論文。總而言之,R6P 是一個需要六對 3D-2D matches 的線性方法,需要用 p3p 初始化,但是執行速度還是非常快,可以結合在 RANSAC 中進行 outlier 剔除。
無形變的 Template 在 RS 相機中形變?還是一個會形變的 Template 被 GS 相機拍下來了?
這一節的標題很長,但也闡述了這篇論文的核心思想:我們認為 RS 相片中物體的 2D 形變,可以看成是這個物體在 3D 中形變了、並被一個 GS 相機給拍下。
沒太理解這句話?沒關係,我們一步一步來看:

一個已知的 3D surface 被我們稱作 template,它被一個移動的 GS 相機拍到了。因為是 GS,毫無意外的,照片 I1 裡沒有任何形變。

如果同一個 3D surface (template) 被一個移動中的 RS 相機拍到。無意外的,這時候我們拍出來的照片 I2 就是一個形變的 surface 了。
這個時候,我們來做一個思想實驗。能不能用一臺 GS 相機拍出和 I2 相片一樣的形變呢?答案是可以的,只要把那個 3D surface 掰扯變形,我們也可以用 GS 相機拍出一模一樣的形變照片:
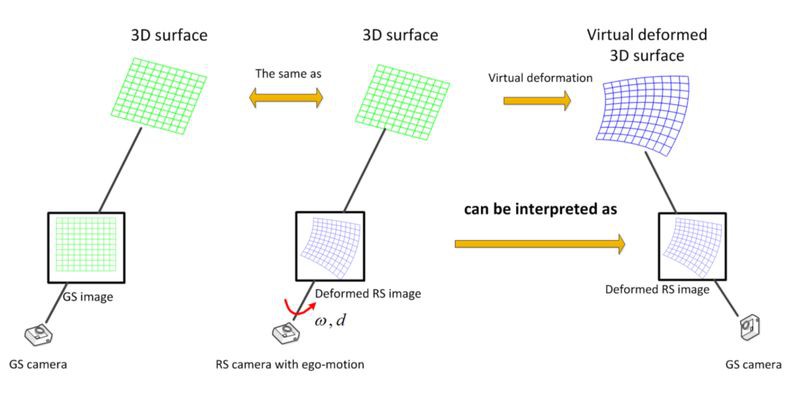
但其實這一切都停留在想象之中,這個掰扯的形變完全是虛擬的。因此我們先暫時稱這個幻想的形變為 Virtual Deformation。這個等價性在論文中有詳細的證明過程。
等等,你為什麼要建立這個等價關係?有什麼意義呢?
當然是有的,其中一個原因是在非剛體場景三維重建的技術中,有一個叫 shape-from-template(SfT)的成熟方法,它要解決的問題和這個關於 3D template 的形變幻想有很大的相似性,其他的原因會在後面章節提到。
Shape-from-Template
SfT 是一種針對非剛體場景(non-rigid),根據已知 t0 時刻的 3D template 和 tn時刻的 2D image,來恢復 tn 時刻的 3D 模型的技術(Adrien Bartoli, PAMI’2015)。
比如,醫生可以在手術前用 CT 或者 NMRI 來獲取患者心髒的 3D 模型,但在手術中,醫生卻無法藉助各類大型儀器實時恢復心髒的 3D 形態。對於醫生而言,如果僅藉助 2D 內窺鏡實施微創手術,那無疑對其操作技術存在較高要求。這時候 SfT 就能大顯身手了,它透過術前重建 t0 時刻的 3D 模型和手術中內窺鏡的 2D 影像,就能實時重建出跳動中的心臟三維模型。
SfT 目前已有高速的 real-time 版本(Toby Collins, ISMAR’15),並且有成熟的 outliers 剔除演演算法(Daniel Pizarro, IJCV’12)。
好,回到 RS 的問題上來,大家有沒有發現 SfT 和上述思想實驗的共同點:都有一個 3D template 當 reference,然後每一張照片都對應了一個 template 的形變。因此,我們可以用 3D template 和 RS image 去重建這個 Virtual Deformed Template。

3D-3D Registration
在用 SfT 重建好這個形變了的 template 之後,我們可以使用已知的未形變的 template 做一個遞迴的 3d-3d registration。這一步給整個 proposed 的方法帶來了兩個好處:
1. 將之前的 3D-2D 問題轉換為了 3D-3D 問題,這對於 RS pose 問題來說可以規避掉大量的退化配置風險,例如 R6P 在 plane scene 上就有 degeneracy case;
2. 在 3d-3d registration 中,可以非常容易地結合各式各樣的 ego-motion model,包括勻速的、加速的等等。
整體流程
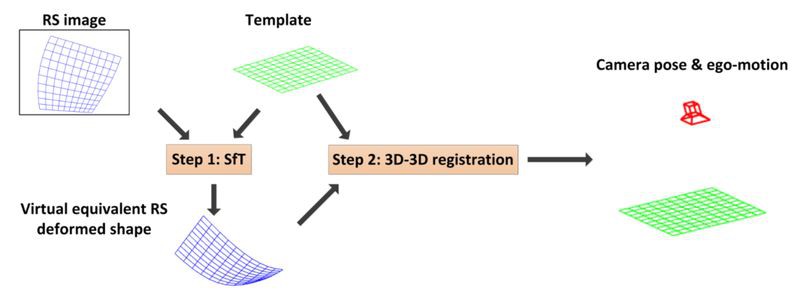
整個方法非常簡單,就分為兩步:
1. 用 SfT 重建虛擬形變的 template;
2. 用形變的 template 和未形變的 template 做 3D-3Dregistration,解出 pose 和 ego-motion。
實驗
我們的方法在模擬實驗和真實 video 實驗中的精確度和穩定性上都遠勝於 P3P,也高於 R6P。R6P 在 plane scene 中有著極高的不穩定性,其結果甚至遠不如 P3P。
參考文獻
[1]. Ait-Aider, O., Andreff, N., Lavest, J.M., Martinet, P.: Simultaneous object pose and velocity computation using a single view from a rolling shutter camera. In: European Conference on Computer Vision, Springer (2006) 56–68
[2]. Albl, C., Kukelova, Z., Pajdla, T.: R6p-rolling shutter absolute camera pose. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. (2015) 2292–2300
[3]. Albl, C., Kukelova, Z., Pajdla, T.: Rolling shutter absolute pose problem with known vertical direction. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. (2016) 3355–3363
[4] Bartoli, A., G´erard, Y., Chadebecq, F., Collins, T., Pizarro, D.: Shape-fromtemplate. IEEE transactions on pattern analysis and machine intelligence 37(10) (2015) 2099–2118
[5]. Magerand, L., Bartoli, A., Ait-Aider, O., Pizarro, D.: Global optimization of object pose and motion from a single rolling shutter image with automatic 2d-3d matching. In: European Conference on Computer Vision, Springer (2012) 456–469

點選以下標題檢視更多論文解讀:
 #投 稿 通 道#
#投 稿 通 道#
讓你的論文被更多人看到
如何才能讓更多的優質內容以更短路徑到達讀者群體,縮短讀者尋找優質內容的成本呢? 答案就是:你不認識的人。
總有一些你不認識的人,知道你想知道的東西。PaperWeekly 或許可以成為一座橋梁,促使不同背景、不同方向的學者和學術靈感相互碰撞,迸發出更多的可能性。
PaperWeekly 鼓勵高校實驗室或個人,在我們的平臺上分享各類優質內容,可以是最新論文解讀,也可以是學習心得或技術乾貨。我們的目的只有一個,讓知識真正流動起來。
? 來稿標準:
• 稿件確系個人原創作品,來稿需註明作者個人資訊(姓名+學校/工作單位+學歷/職位+研究方向)
• 如果文章並非首發,請在投稿時提醒並附上所有已釋出連結
• PaperWeekly 預設每篇文章都是首發,均會新增“原創”標誌
? 投稿郵箱:
• 投稿郵箱:hr@paperweekly.site
• 所有文章配圖,請單獨在附件中傳送
• 請留下即時聯絡方式(微信或手機),以便我們在編輯釋出時和作者溝通
?
現在,在「知乎」也能找到我們了
進入知乎首頁搜尋「PaperWeekly」
點選「關註」訂閱我們的專欄吧
關於PaperWeekly
PaperWeekly 是一個推薦、解讀、討論、報道人工智慧前沿論文成果的學術平臺。如果你研究或從事 AI 領域,歡迎在公眾號後臺點選「交流群」,小助手將把你帶入 PaperWeekly 的交流群裡。

▽ 點選 | 閱讀原文 | 下載論文
