(點選上方公眾號,可快速關註)
來源:Yusheng
blog.rainy.im/2015/11/24/extract-color-themes-from-images/
許多從自然場景中拍攝的影象,其色彩分佈上會給人一種和諧、一致的感覺;反過來,在許多介面設計應用中,我們也希望選擇的顏色可以達到這樣的效果,但對一般人來說卻並不那麼容易,這屬於色彩心理學的範疇(當然不是指某些偽神棍所謂的那種)。從彩色影象中提取其中的主題顏色,不僅可以用於色彩設計(參考網站:Design Seeds),也可用於影象分類、搜尋、識別等,本文分別總結並實現影象主題顏色提取的幾種演演算法,包括顏色量化法(Color Quantization)、聚類(Clustering)和顏色建模的方法(顏色建模法僅作總結),原始碼可見:GitHub: ImageColorTheme(連結:github.com/rainyear/ImageColorTheme)。
1. 顏色量化演演算法
彩色影象一般採用RGB色彩樣式,每個畫素由RGB三個顏色分量組成。隨著硬體的不斷升級,彩色影象的儲存由最初的8位、16位變成現在的24位、32真彩色。所謂全綵是指每個畫素由8位($2^8$=0~255)表示,紅綠藍三原色組合共有1677萬($256*256*256$)萬種顏色,如果將RGB看作是三維空間中的三個坐標,可以得到下麵這樣一張色彩空間圖:

當然,一張影象不可能包含所有顏色,我們將一張彩色影象所包含的畫素投射到色彩空間中,可以更直觀地感受影象中顏色的分佈:
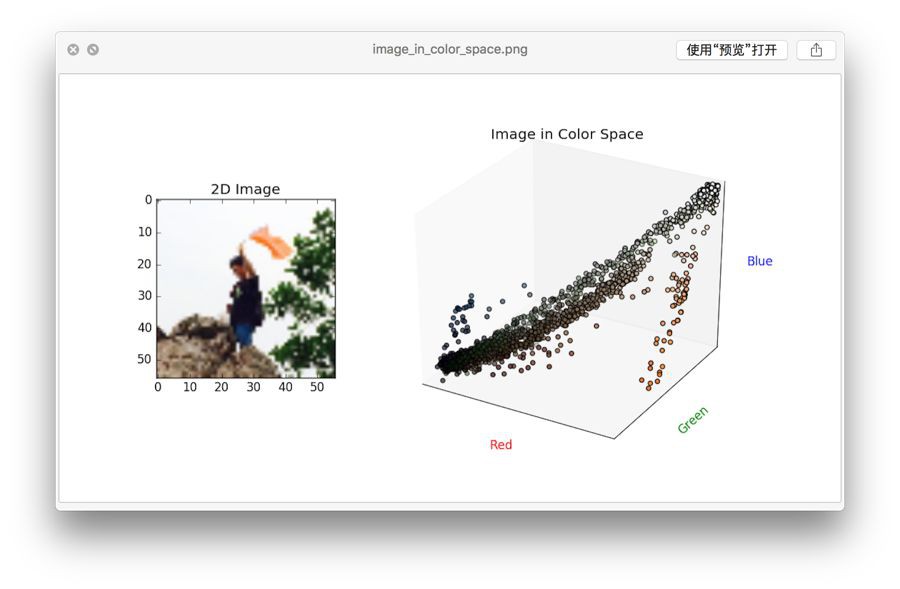
因此顏色量化問題可以用所有向量量化(vector quantization, VQ)演演算法解決。這裡採用開源影象處理庫 Leptonica 中用到的兩種演演算法:中位切分法、八叉樹演演算法。
1.1. 中位切分法(Median cut)
GitHub: color-theif 專案採用了 Leptonica 中的用到的(調整)中位切分法,Js 程式碼比 C 要易讀得多。中位切分演演算法的原理很簡單直接,將影象顏色看作是色彩空間中的長方體(VBox),從初始整個影象作為一個長方體開始,將RGB中最長的一邊從顏色統計的中位數一切為二,使得到的兩個長方體所包含的畫素數量相同,重覆上述步驟,直到最終切分得到長方體的數量等於主題顏色數量為止。
Leptonica 作者在報告 Median-Cut Color Quantization 中總結了這一演演算法存在的一些問題,其中主要問題是有可能存在某些條件下 VBox 體積很大但只包含少量畫素。解決的方法是,每次進行切分時,並不是對上一次切分得到的所有VBox進行切分,而是透過一個優先順序佇列進行排序,剛開始時這一佇列以VBox僅以VBox所包含的畫素數作為優先順序考量,當切分次數變多之後,將體積*包含畫素數作為優先順序。
Python 3 中內建了PriorityQueue:
from queue import PriorityQueue as PQueue
class VBox(object):
def __init__(self, r1, r2, g1, g2, b1, b2, histo):
self.vol = calV()
self.npixs = calN()
self.priority = self.npixs * –1 # PQueue 是按優先順序自小到大排序
boxQueue.put((vbox0.priority, vbox0))
vbox.priority *= vbox.vol
boxQueue.put((vbox0.priority, vbox0))
除此之外,演演算法中最重要的部分是統計色彩分佈直方圖。我們需要將三維空間中的任意一點對應到一維坐標中的整數,這樣才能以最快地速度定位這一顏色。如果採用全部的24位資訊,那麼我們用於儲存直方圖的陣列長度至少要是$2^{24}=16777216$,既然是要提取顏色主題(或是顏色量化),我們可以將顏色由RGB各8位壓縮至5位,這樣陣列長度只有$2^{15}=32768$:
def getColorIndex(self, r, g, b):
return (r << (2 * self.SIGBITS)) + (g << self.SIGBITS) + b
def getPixHisto(self):
pixHisto = np.zeros(1 << (3 * self.SIGBITS))
for y in range(self.h):
for x in range(self.w):
r = self.pixData[y, x, 0] >> self.rshift
g = self.pixData[y, x, 1] >> self.rshift
b = self.pixData[y, x, 2] >> self.rshift
pixHisto[self.getColorIndex(r, g, b)] += 1
return pixHisto
分別對4張圖片進行切分、提取:
def testMMCQ(pixDatas, maxColor):
start = time.process_time()
themes = list(map(lambda d: MMCQ(d, maxColor).quantize(), pixDatas))
print(“MMCQ Time cost: {0}”.format(time.process_time() – start))
return themes
imgs = map(lambda i: ‘imgs/photo%s.jpg’ % i, range(1,5))
pixDatas = list(map(getPixData, imgs))
maxColor = 7
themes = [testMMCQ(pixDatas, maxColor)]
imgPalette(pixDatas, themes, [“MMCQ Palette”])

1.2. 八叉樹演演算法(Octree)
八叉樹演演算法的原理可以參考這篇文章:圖片主題色提取演演算法小結。作者也提供了 Js 實現的程式碼,雖然與 Leptonica 中 C 實現的方法差別很大,但原理上是一致的。
建立八叉樹的原理實際上跟上面提到的統計直方圖有些相似,將顏色成分轉換成二進位制之後,較低位(八叉樹中位置較深層)數值將被壓縮排較高位(八叉樹中較淺層)。八叉樹演演算法應用到主題色提取可能存在的問題是,每次削減掉的葉子數不確定,但是新增加的只有一個,這就導致我們需要的主題色數量並不一定剛好得到滿足,例如設定的主題色數量為7,可能上一次葉子時總數還有10個,到了下一次只剩5個了。類似的問題在後面手動實現的KMeans演演算法中也有出現,為了保證可以得到足夠的主題色,不得不強行提高演演算法中的顏色數量,然後取影象中包含數量較多的作為主題色:
def getColors(self, node):
if node.isLeaf:
[r, g, b] = list(map(lambda n: int(n[0] / n[1]), zip([node.r, node.g, node.b], [node.n]*3)))
self.theme.append([r,g,b, node.n])
else:
for i in range(8):
if node.children[i] is not None:
self.getColors(node.children[i])
self.theme = sorted(self.theme, key=lambda c: –1*c[1])
return list(map(lambda l: l[:-1],self.theme[:self.maxColor]))
對比上面兩種演演算法的結果:
def testOQ(pixDatas, maxColor):
start = time.process_time()
themes = list(map(lambda d: OQ(d, maxColor).quantize(), pixDatas))
print(“OQ Time cost: {0}”.format(time.process_time() – start))
return themes
themes = [testMMCQ(pixDatas, maxColor), testOQ(pixDatas, maxColor)]
imgPalette(pixDatas, themes, [“MMCQ Palette”, “OQ Palette”])

可見八叉樹演演算法可能更適合用於提取調色盤,而且兩種演演算法執行時間差異也很明顯:
#MMCQ Time cost: 8.238793
#OQ Time cost: 55.173573
除了OQ中採用較多遞迴以外,未對原圖進行抽樣處理也是其中原因之一。
2. 聚類
聚類是一種無監督式機器學習演演算法,我們這裡採用K均值演演算法。雖然說是“機器學習”聽起來時髦些,但演演算法本質上比上面兩種更加簡單粗暴。
KMeans演演算法
KMeans演演算法的原理更加簡潔:“物以類聚”。我們目的是將一堆零散的資料(如上面圖2)歸為k個類別,使得每個類別中的每個資料樣本,距離該類別的中心(質心,centroid)距離最小,數學公式為:
$ $ \sum_{i=0}^N \min_{ \mu_j \in C} (||x_i – \mu_j||^2) $ $
上文提到八叉樹演演算法可能出現結果與主題色數量不一致的情況,在KMeans演演算法中,初始的k個類別的質心的選擇也可能導致類似的問題。當採用隨機選擇的方法時,有可能出現在迭代過程中,選擇的中心點距離所有其它資料太遠而最終導致被孤立。這裡分別採用手動實現和scikit-learn的方法實現,根據scikit-learn 提供的API,完成主題色的提取大概只需要幾行程式碼:
from sklearn.cluster import KMeans as KM
import numpy as np
#@pixData image pixels stored in numpy.ndarray
#@maxColor theme color number
h, w, d = pixData.shape
data = np.reshape((h*w, d))
km = KM(n_clusters=maxColor)
km.fit(data)
theme = np.array(km.cluster_centers_, dtype=np.uint8)
imgs = map(lambda i: ‘imgs/photo%s.jpg’ % i, range(1,5))
pixDatas = list(map(getPixData, imgs))
maxColor = 7
themes = [testKmeans(pixDatas, maxColor), testKmeans(pixDatas, maxColor, useSklearn=False)]
imgPalette(pixDatas, themes, [“KMeans Palette”, “KMeans DIY”])
測試比較手動實現和scikit-learn的結果如下:
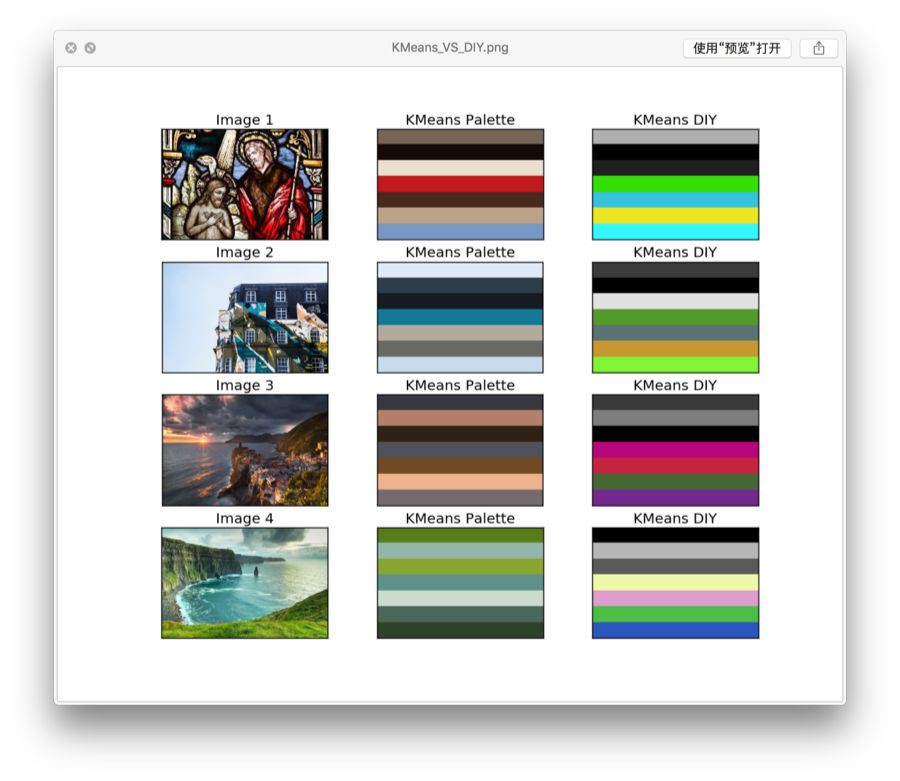
好吧我承認很慘,耗時方面也是慘不忍睹。
3. 色彩建模
從上面幾種演演算法結果來看,MMCQ和 KMeans在時間和結果上都還算不錯,但仍有改進的空間。如果從人類的角度出發,兩種演演算法的策略或者說在解決主題色提取這一問題時採納的特徵(feature)都接近於顏色密度,即相近的顏色湊在一起數量越多,越容易被提取為主題顏色。
最後要提到的演演算法來自斯坦福視覺化組13年的一篇研究:Modeling how people extract color themes from images,實際上比較像一篇心理學研究的套路:建模-找人類被試進行行為實驗-調參擬合。文章提取了影象中的79個特徵變數併進行多元回歸,同時找到普通人類被試和藝術系學生對影象的主題顏色進行選擇,結果證明特徵+回歸能夠更好地擬合人類選擇的結果。

79個特徵的多元回歸模型,不知道會不會出現過度擬合?另外雖然比前面演演算法多了很多特徵,但仍舊多物理特徵。對人類觀察者來說,我們看到的並非一堆無意義的色塊,雖然有研究表明顏色資訊並非場景識別的必要線索,但反過來場景影象中的語意資訊卻很有可能影響顏色對觀察者的意義,這大概就是心理學研究與電腦科學方向上的差異。
總結
以上演演算法若要應用還需更多最佳化,例如先抽樣再處理,計算密集的地方用C/C++或並行等。另外需要一個對Python每個函式執行時間進行記錄的工具,分析執行時間長的部分。
參考
-
Color Quantization
-
Color quantization using modified median cut
-
Median-Cut Color Quantization
-
Wicked Code
-
Clustering – scikit-learn
-
Color Quantization using K-Means
-
Extract Color Themes from Images
-
Lin, S., & Hanrahan, P. (2013). Modeling how people extract color themes from images. Proc of Chi Acm, 3101-3110.
【關於投稿】
如果大家有原創好文投稿,請直接給公號傳送留言。
① 留言格式:
【投稿】+《 文章標題》+ 文章連結
② 示例:
【投稿】《不要自稱是程式員,我十多年的 IT 職場總結》:
http://blog.jobbole.com/94148/
③ 最後請附上您的個人簡介哈~
覺得本文有幫助?請分享給更多人
關註「演演算法愛好者」,修煉程式設計內功

