TIOBE 最新釋出的 9 月程式語言排行榜中,Python 憑 4.67% 的增速以 0.26% 的優勢力壓 C++,逆襲成功進入 Top 3。

TIOBE 9 月程式語言 Top 5
而近一年勢頭不滅的 Python 在資料分析領域,是專家們的必備技能。隨著 IT 行業的增長,對有經驗的資料科學家的需求也水漲船高,而 Python 也一躍而成最受歡迎的語言。本文旨在介紹分析資料的基本知識,並利用 Python 建立一些漂亮的資料視覺化。

概要
-
為什麼要學資料科學中的 Python?
-
Python 簡介
-
為資料科學中的 Python 安裝 Jupyter
-
Python 的基本知識
-
用於資料科學的 Python 庫
-
Demo:實際應用

資料科學領域,非 Python 語言莫屬?
Python 是最適合資料科學家的語言,這一點毫無爭議。下麵幾點可以幫你理解為什麼從事資料科學的人選擇了 Python:
-
Python 是一門免費,靈活且強大的開源語言。
-
Python 能減少一半的開發時間,同時提供簡潔易讀的語法。
-
使用 Python 可以進行資料操作、資料分析和視覺化。
-
Python 提供功能強大的庫,用於機器學習應用和其他科學計算。
你知道最大的好處是什麼嗎?資料科學家是目前收入最高的職位之一,根據 Indeed.com 的資料,平均年薪為 $130,621。
Python 由 Guido Van Rossum 於 1989 年建立。它是個解釋語言,擁有動態語意。它在所有的平臺上可以免費使用。Python 是:

-
面向物件
-
高階語言
-
容易學
-
面向過程

為資料科學中的 Python 安裝 Jupyter
我們先來在自己的系統上安裝 Jupyter。請按照以下步驟進行:
-
第 1 步:訪問 https://jupyter.org/
-
第 2 步:點選“Try in your browser”或“Install the Notebook”
我建議你使用 Anaconda 發行版(https://www.anaconda.com/download/)安裝 Python 和 Jupyter。裝好Jupyter 之後,可以在命令列中輸入“Jupyter Notebook”即可在預設瀏覽器中開啟。現在我們在 Jupyter 上寫個最基本的程式。
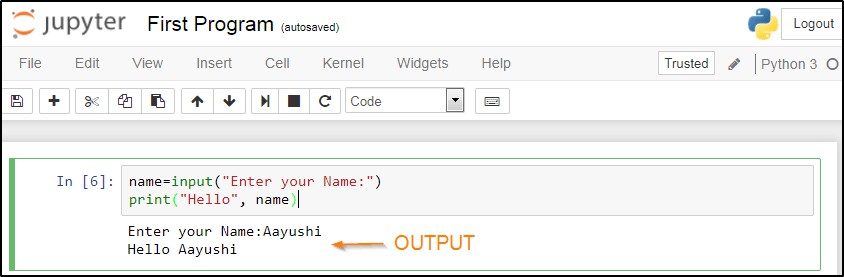
name=input("Enter your Name:")
print("Hello", name)
要執行這段程式碼,可以按下“Shift+Enter”,即可檢視輸出。如下麵的截圖所示:

資料科學中的 Python 的基礎
現在可以開始程式設計了。為了程式設計,你需要先瞭解以下的基礎知識:
-
變數:“變數”這個術語指記憶體中的一塊保留的位置,用於儲存值。在Python中,使用變數之前不需要定義變數,更不需要宣告變數的型別。
-
資料型別:Python 支援多種資料型別,這些資料型別定義了變數上可能的操作,以及它們的儲存方式。資料型別包括數值、串列、字串、元組、集合和字典。
-
運運算元:運運算元可以操縱運算元中的值。Python 中的運運算元包括數值運運算元、串列運運算元、字串運運算元、元組運運算元、集合運運算元和字典運運算元。
-
條件陳述句:條件陳述句可以根據某個條件執行一組陳述句。有三個條件陳述句:if、elif 和 else。
-
迴圈:迴圈用來反覆執行一小段程式碼。有三種迴圈,分別是while、for和巢狀迴圈。
-
函式:函式用來將程式碼分隔成有意義的功能塊,以便更好地組織程式碼,讓程式碼更易讀,重用程式碼,還能節省時間。
關於 Python的更多資訊和實際的實現,可以參考這篇文章:Python 入門(https://www.edureka.co/blog/python-tutorial/)。

資料科學中的 Python 庫
這是 Python 在資料科學中發揮力量的部分。Python 擁有大量用於科學計算、分析、視覺化等的庫。一些庫如下:
-
Numpy – NumPy 是 Python 在資料科學方面的核心庫,它的名字的意思是“數值計算用的Python”。它可以用於科學計算,包含了強大的 n 維陣列物件,並提供了許多工具與 C、C++ 等語言整合。它還可以用作多維容器,用來儲存任意資料,從而進行各種 NumPy 操作和特殊功能。
-
Matplotlib – Matplotlib 是個強大的視覺化 Python 庫。它可以用於Python 指令碼、shell、Web 應用伺服器上,還可以用於其他 GUI 工具中。可以用它繪製各種圖表,也可以把多種圖表畫在一起。
-
Scikit-learn – Scikit-learn 是最引人註目的庫之一,透過它可以用 Python 實現機器學習。這個免費的庫包含了用於資料分析和資料挖掘的簡單有效的工具。用它可以實現各種演演算法,如邏輯回歸。
-
Seaborn – Seaborn 是個統計繪圖的 Python 庫。在資料科學中使用 Python 時,可以使用 matplotlib(用於二維視覺化)和 Seaborn,後者有漂亮的樣式和高階介面可以用於繪製統計圖表。
-
Pandas – Pandas 是資料科學中的重要的 Python 庫。它用來運算元據和分析資料。它很適合不同型別的資料,如表格、有序時間序列、無序時間序列、矩陣等。這裡有個影片(https://youtu.be/B42n3Pc-N2A)演示瞭如何在處理資料之前使用 Pandas 進行資料分析。

Demo:實際應用
問題描述:給定一組資料集,該資料集是由多種資料組成的綜合統計資料,如監獄設施的分佈和情況、監獄的擁擠程度、監獄中的犯人型別,等等。請在這個資料集上做描述性的統計,並從資料中找出有用的資訊。下麵是幾個任務:
-
資料載入:使用 Pandas 載入資料集“prisoners.csv”並顯示資料集中的前五行和最後五行。然後用 Pandas 的 describe 方法找出列數。
-
資料操作:建立一個新的列 – “total benefitted”,它是所有樣式下的受益的犯人總數。
-
資料視覺化:建立條形圖,用每個州的名字作為X軸,受益犯人的總數作為條的高度。
載入資料使用以下程式碼:
import pandas as pd
import matplotlib.pyplot as plot
%matplotlib inline
file_name = "prisoners.csv"
prisoners = pd.read_csv(file_name)
prisoners

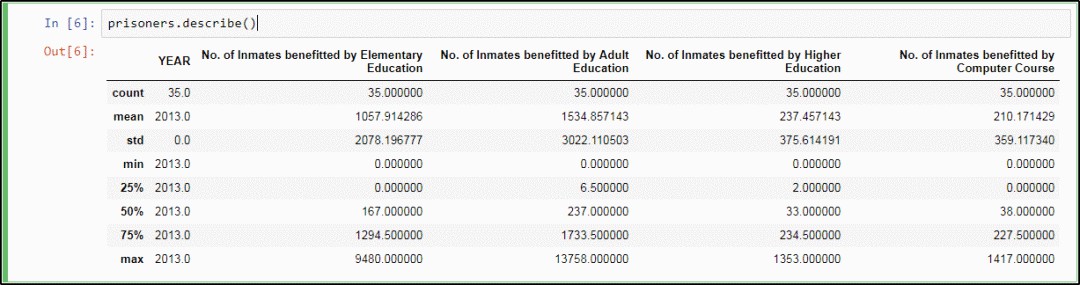
然後用 Pandas 的 describe 方法,只需輸入以下陳述句:
prisoners.describe()
然後進行資料操作:
prisoners["total_benefited"]=prisoners.sum(axis=1)
prisoners.head()

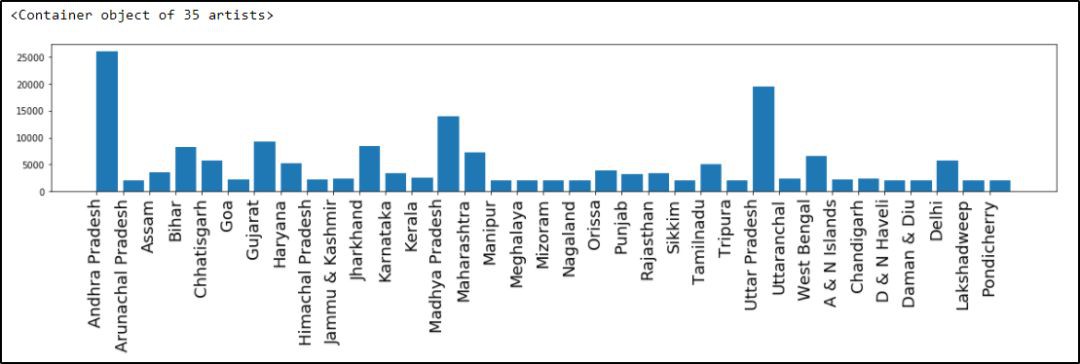
最後,用 Python 做一些資料視覺化。程式碼如下:
import numpy as np
xlabels = prisoners['STATE/UT'].values
plot.figure(figsize=(20, 3))
plot.xticks(np.arange(xlabels.shape[0]), xlabels, rotation = 'vertical', fontsize = 18)
plot.xticks
plot.bar(np.arange(prisoners.values.shape[0]),prisoners['total_benefited'],align = 'edge')
原文:https://dzone.com/articles/learn-python-for-data-science-using-python-librari
作者:Aayushi Johari; 譯者:彎月
版權宣告:本號內容部分來自網際網路,轉載請註明原文連結和作者,如有侵權或出處有誤請和我們聯絡。
關聯閱讀
原創系列文章:
資料運營 關聯文章閱讀:
資料分析、資料產品 關聯文章閱讀:
80%的運營註定了打雜?因為你沒有搭建出一套有效的使用者運營體系
合作請加qq:365242293
更多相關知識請回覆:“ 月光寶盒 ”;
資料分析(ID : ecshujufenxi )網際網路科技與資料圈自己的微信,也是WeMedia自媒體聯盟成員之一,WeMedia聯盟改寫5000萬人群。

