(點選上方公眾號,可快速關註)
來源:SylvanasSun’s Blog ,
sylvanassun.github.io/2018/03/16/2018-03-16-map_family/
我們上述所講的Map都是非執行緒安全的,這意味著不應該在多個執行緒中對這些Map進行修改操作,輕則會產生資料不一致的問題,甚至還會因為併發插入元素而導致連結串列成環(插入會觸發擴容,而擴容操作需要將原陣列中的元素rehash到新陣列,這時併發操作就有可能產生連結串列的迴圈取用從而成環),這樣在查詢時就會發生死迴圈,影響到整個應用程式。
Collections.synchronizedMap(Map
public static
Map synchronizedMap(Map m) { return new SynchronizedMap<>(m);
}
private static class SynchronizedMap
implements Map
, Serializable { private static final long serialVersionUID = 1978198479659022715L;
private final Map
m; // Backing Map final Object mutex; // Object on which to synchronize
SynchronizedMap(Map
m) { this.m = Objects.requireNonNull(m);
mutex = this;
}
SynchronizedMap(Map
m, Object mutex) { this.m = m;
this.mutex = mutex;
}
public int size() {
synchronized (mutex) {return m.size();}
}
public boolean isEmpty() {
synchronized (mutex) {return m.isEmpty();}
}
…………
}
然而ConcurrentHashMap的實現細節遠沒有這麼簡單,因此效能也要高上許多。它沒有使用一個全域性鎖來鎖住自己,而是採用了減少鎖粒度的方法,儘量減少因為競爭鎖而導致的阻塞與衝突,而且ConcurrentHashMap的檢索操作是不需要鎖的。
在Java 7中,ConcurrentHashMap把內部細分成了若干個小的HashMap,稱之為段(Segment),預設被分為16個段。對於一個寫操作而言,會先根據hash code進行定址,得出該Entry應被存放在哪一個Segment,然後只要對該Segment加鎖即可。
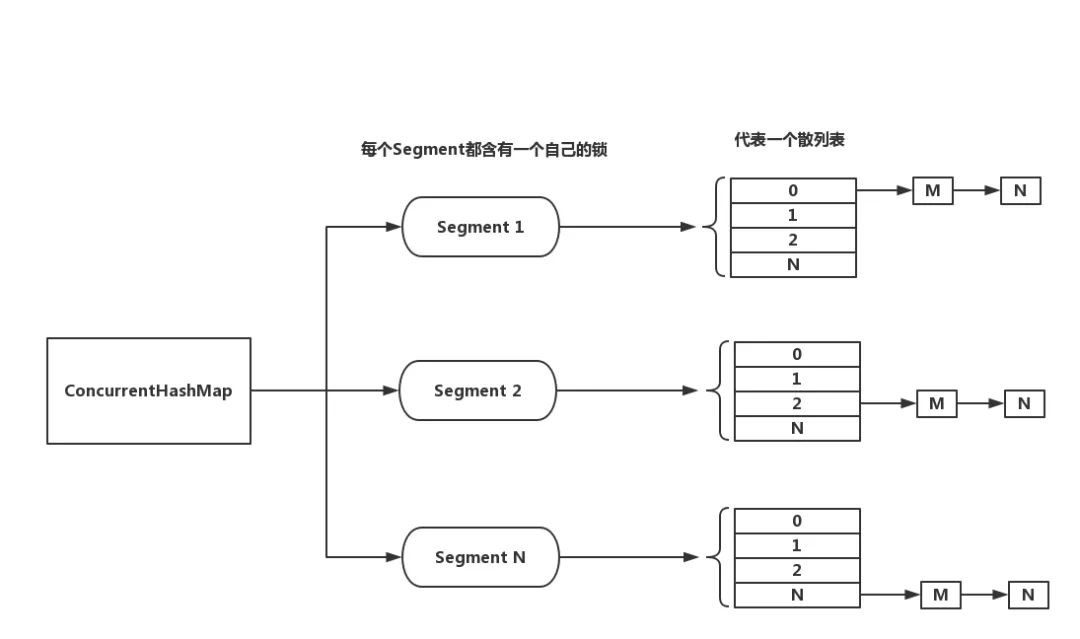
理想情況下,一個預設的ConcurrentHashMap可以同時接受16個執行緒進行寫操作(如果都是對不同Segment進行操作的話)。
分段鎖對於size()這樣的全域性操作來說就沒有任何作用了,想要得出Entry的數量就需要遍歷所有Segment,獲得所有的鎖,然後再統計總數。事實上,ConcurrentHashMap會先試圖使用無鎖的方式統計總數,這個嘗試會進行3次,如果在相鄰的2次計算中獲得的Segment的modCount次數一致,代表這兩次計算過程中都沒有發生過修改操作,那麼就可以當做最終結果傳回,否則,就要獲得所有Segment的鎖,重新計算size。
本文主要討論的是Java 8的ConcurrentHashMap,它與Java 7的實現差別較大。完全放棄了段的設計,而是變回與HashMap相似的設計,使用buckets陣列與分離連結法(同樣會在超過閾值時樹化,對於構造紅黑樹的邏輯與HashMap差別不大,只不過需要額外使用CAS來保證執行緒安全),鎖的粒度也被細分到每個陣列元素(個人認為這樣做的原因是因為HashMap在Java 8中也實現了不少最佳化,即使碰撞嚴重,也能保證一定的效能,而且Segment不僅臃腫還有弱一致性的問題存在),所以它的併發級別與陣列長度相關(Java 7則是與段數相關)。
/**
* The array of bins. Lazily initialized upon first insertion.
* Size is always a power of two. Accessed directly by iterators.
*/
transient volatile Node
[] table;
定址
ConcurrentHashMap的雜湊函式與HashMap並沒有什麼區別,同樣是把key的hash code的高16位與低16位進行異或運算(因為ConcurrentHashMap的buckets陣列長度也永遠是一個2的N次方),然後將擾亂後的hash code與陣列的長度減一(實際可訪問到的最大索引)進行與運算,得出的結果即是標的所在的位置。
// 2^31 – 1,int型別的最大值
// 該掩碼表示節點hash的可用位,用來保證hash永遠為一個正整數
static final int HASH_BITS = 0x7fffffff;
static final int spread(int h) {
return (h ^ (h >>> 16)) & HASH_BITS;
}
下麵是查詢操作的原始碼,實現比較簡單。
public V get(Object key) {
Node
[] tab; Node e, p; int n, eh; K ek; int h = spread(key.hashCode());
if ((tab = table) != null && (n = tab.length) > 0 &&
(e = tabAt(tab, (n – 1) & h)) != null) {
if ((eh = e.hash) == h) {
// 先嘗試判斷連結串列頭是否為標的,如果是就直接傳回
if ((ek = e.key) == key || (ek != null && key.equals(ek)))
return e.val;
}
else if (eh < 0)
// eh < 0代表這是一個特殊節點(TreeBin或ForwardingNode)
// 所以直接呼叫find()進行遍歷查詢
return (p = e.find(h, key)) != null ? p.val : null;
// 遍歷連結串列
while ((e = e.next) != null) {
if (e.hash == h &&
((ek = e.key) == key || (ek != null && key.equals(ek))))
return e.val;
}
}
return null;
}
一個普通的節點(連結串列節點)的hash不可能小於0(已經在spread()函式中修正過了),所以小於0的只可能是一個特殊節點,它不能用while迴圈中遍歷連結串列的方式來進行遍歷。
TreeBin是紅黑樹的頭部節點(紅黑樹的節點為TreeNode),它本身不含有key與value,而是指向一個TreeNode節點的連結串列與它們的根節點,同時使用CAS(ConcurrentHashMap並不是完全基於互斥鎖實現的,而是與CAS這種樂觀策略搭配使用,以提高效能)實現了一個讀寫鎖,迫使Writer(持有這個鎖)在樹重構操作之前等待Reader完成。
ForwardingNode是一個在資料轉移過程(由擴容引起)中使用的臨時節點,它會被插入到頭部。它與TreeBin(和TreeNode)都是Node類的子類。
為了判斷出哪些是特殊節點,TreeBin和ForwardingNode的hash域都只是一個虛擬值:
static class Node
implements Map.Entry { final int hash;
final K key;
volatile V val;
volatile Node
next; Node(int hash, K key, V val, Node
next) { this.hash = hash;
this.key = key;
this.val = val;
this.next = next;
}
public final V setValue(V value) {
throw new UnsupportedOperationException();
}
……
/**
* Virtualized support for map.get(); overridden in subclasses.
*/
Node
find(int h, Object k) { Node
e = this; if (k != null) {
do {
K ek;
if (e.hash == h &&
((ek = e.key) == k || (ek != null && k.equals(ek))))
return e;
} while ((e = e.next) != null);
}
return null;
}
}
/*
* Encodings for Node hash fields. See above for explanation.
*/
static final int MOVED = -1; // hash for forwarding nodes
static final int TREEBIN = -2; // hash for roots of trees
static final int RESERVED = -3; // hash for transient reservations
static final class TreeBin
extends Node { ….
TreeBin(TreeNode
b) { super(TREEBIN, null, null, null);
….
}
….
}
static final class ForwardingNode
extends Node { final Node
[] nextTable; ForwardingNode(Node
[] tab) { super(MOVED, null, null, null);
this.nextTable = tab;
}
…..
}
可見性
我們在get()函式中並沒有發現任何與鎖相關的程式碼,那麼它是怎麼保證執行緒安全的呢?一個操作ConcurrentHashMap.get(“a”),它的步驟基本分為以下幾步:
-
根據雜湊函式計算出的索引訪問table。
-
從table中取出頭節點。
-
遍歷頭節點直到找到標的節點。
-
從標的節點中取出value並傳回。
所以只要保證訪問table與節點的操作總是能夠傳回最新的資料就可以了。ConcurrentHashMap並沒有採用鎖的方式,而是透過volatile關鍵字來保證它們的可見性。在上文貼出的程式碼中可以發現,table、Node.val和Node.next都是被volatile關鍵字所修飾的。
volatile關鍵字保證了多執行緒環境下變數的可見性與有序性,底層實現基於記憶體屏障(Memory Barrier)。
為了最佳化效能,現代CPU工作時的指令執行順序與應用程式的程式碼順序其實是不一致的(有些編譯器也會進行這種最佳化),也就是所謂的亂序執行技術。亂序執行可以提高CPU流水線的工作效率,只要保證資料符合程式邏輯上的正確性即可(遵循happens-before原則)。不過如今是多核時代,如果隨便亂序而不提供防護措施那是會出問題的。每一個cpu上都會進行亂序最佳化,單cpu所保證的邏輯次序可能會被其他cpu所破壞。
記憶體屏障就是針對此情況的防護措施。可以認為它是一個同步點(但它本身也是一條cpu指令)。例如在IA32指令集架構中引入的SFENCE指令,在該指令之前的所有寫操作必須全部完成,讀操作仍可以亂序執行。LFENCE指令則保證之前的所有讀操作必須全部完成,另外還有粒度更粗的MFENCE指令保證之前的所有讀寫操作都必須全部完成。
記憶體屏障就像是一個保護指令順序的柵欄,保護後面的指令不被前面的指令跨越。將記憶體屏障插入到寫操作與讀操作之間,就可以保證之後的讀操作可以訪問到最新的資料,因為屏障前的寫操作已經把資料寫回到記憶體(根據快取一致性協議,不會直接寫回到記憶體,而是改變該cpu私有快取中的狀態,然後通知給其他cpu這個快取行已經被修改過了,之後另一個cpu在讀操作時就可以發現該快取行已經是無效的了,這時它會從其他cpu中讀取最新的快取行,然後之前的cpu才會更改狀態並寫回到記憶體)。
例如,讀一個被volatile修飾的變數V總是能夠從JMM(Java Memory Model)主記憶體中獲得最新的資料。因為記憶體屏障的原因,每次在使用變數V(透過JVM指令use,後面說的也都是JVM中的指令而不是cpu)之前都必須先執行load指令(把從主記憶體中得到的資料放入到工作記憶體),根據JVM的規定,load指令必鬚髮生在read指令(從主記憶體中讀取資料)之後,所以每次訪問變數V都會先從主記憶體中讀取。相對的,寫操作也因為記憶體屏障保證的指令順序,每次都會直接寫回到主記憶體。
不過volatile關鍵字並不能保證操作的原子性,對該變數進行併發的連續操作是非執行緒安全的,所幸ConcurrentHashMap只是用來確保訪問到的變數是最新的,所以也不會發生什麼問題。
出於效能考慮,Doug Lea(java.util.concurrent包的作者)直接透過Unsafe類來對table進行操作。
Java號稱是安全的程式語言,而保證安全的代價就是犧牲程式員自由操控記憶體的能力。像在C/C++中可以透過操作指標變數達到操作記憶體的目的(其實操作的是虛擬地址),但這種靈活性在新手手中也經常會帶來一些愚蠢的錯誤,比如記憶體訪問越界。
Unsafe從字面意思可以看出是不安全的,它包含了許多本地方法(在JVM平臺上執行的其他語言編寫的程式,主要為C/C++,由JNI實現),這些方法支援了對指標的操作,所以它才被稱為是不安全的。雖然不安全,但畢竟是由C/C++實現的,像一些與作業系統互動的操作肯定是快過Java的,畢竟Java與作業系統之間還隔了一層抽象(JVM),不過代價就是失去了JVM所帶來的多平臺可移植性(本質上也只是一個c/cpp檔案,如果換了平臺那就要重新編譯)。
對table進行操作的函式有以下三個,都使用到了Unsafe(在java.util.concurrent包隨處可見):
@SuppressWarnings(“unchecked”)
static final
Node tabAt(Node [] tab, int i) { // 從tab陣列中獲取一個取用,遵循Volatile語意
// 引數2是一個在tab中的偏移量,用來尋找標的物件
return (Node
)U.getObjectVolatile(tab, ((long)i << ASHIFT) + ABASE); }
static final
boolean casTabAt(Node [] tab, int i, Node
c, Node v) { // 透過CAS操作將tab陣列中位於引數2偏移量位置的值替換為v
// c是期望值,如果期望值與實際值不符,傳回false
// 否則,v會成功地被設定到標的位置,傳回true
return U.compareAndSwapObject(tab, ((long)i << ASHIFT) + ABASE, c, v);
}
static final
void setTabAt(Node [] tab, int i, Node v) { // 設定tab陣列中位於引數2偏移量位置的值,遵循Volatile語意
U.putObjectVolatile(tab, ((long)i << ASHIFT) + ABASE, v);
}
如果對Unsafe感興趣,可以參考這篇文章:Java Magic. Part 4: sun.misc.Unsafe
初始化
ConcurrentHashMap與HashMap一樣是Lazy的,buckets陣列會在第一次訪問put()函式時進行初始化,它的預設建構式甚至是個空函式。
/**
* Creates a new, empty map with the default initial table size (16).
*/
public ConcurrentHashMap() {
}
但是有一點需要註意,ConcurrentHashMap是工作在多執行緒併發環境下的,如果有多個執行緒同時呼叫了put()函式該怎麼辦?這會導致重覆初始化,所以必須要有對應的防護措施。
ConcurrentHashMap宣告了一個用於控制table的初始化與擴容的實體變數sizeCtl,預設值為0。當它是一個負數的時候,代表table正處於初始化或者擴容的狀態。-1表示table正在進行初始化,-N則表示當前有N-1個執行緒正在進行擴容。
在其他情況下,如果table還未初始化(table == null),sizeCtl表示table進行初始化的陣列大小(所以從建構式傳入的initialCapacity在經過計算後會被賦給它)。如果table已經初始化過了,則表示下次觸發擴容操作的閾值,演演算法stzeCtl = n – (n >>> 2),也就是n的75%,與預設負載因子(0.75)的HashMap一致。
private transient volatile int sizeCtl;
初始化table的操作位於函式initTable(),原始碼如下:
/**
* Initializes table, using the size recorded in sizeCtl.
*/
private final Node
[] initTable() { Node
[] tab; int sc; while ((tab = table) == null || tab.length == 0) {
// sizeCtl小於0,這意味著已經有其他執行緒進行初始化了
// 所以當前執行緒讓出CPU時間片
if ((sc = sizeCtl) < 0)
Thread.yield(); // lost initialization race; just spin
// 否則,透過CAS操作嘗試修改sizeCtl
else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {
try {
if ((tab = table) == null || tab.length == 0) {
// 預設建構式,sizeCtl = 0,使用預設容量(16)進行初始化
// 否則,會根據sizeCtl進行初始化
int n = (sc > 0) ? sc : DEFAULT_CAPACITY;
@SuppressWarnings(“unchecked”)
Node
[] nt = (Node [])new Node,?>[n]; table = tab = nt;
// 計算閾值,n的75%
sc = n – (n >>> 2);
}
} finally {
// 閾值賦給sizeCtl
sizeCtl = sc;
}
break;
}
}
return tab;
}
sizeCtl是一個volatile變數,只要有一個執行緒CAS操作成功,sizeCtl就會被暫時地修改為-1,這樣其他執行緒就能夠根據sizeCtl得知table是否已經處於初始化狀態中,最後sizeCtl會被設定成閾值,用於觸發擴容操作。
擴容
ConcurrentHashMap觸發擴容的時機與HashMap類似,要麼是在將連結串列轉換成紅黑樹時判斷table陣列的長度是否小於閾值(64),如果小於就進行擴容而不是樹化,要麼就是在新增元素的時候,判斷當前Entry數量是否超過閾值,如果超過就進行擴容。
private final void treeifyBin(Node
[] tab, int index) { Node
b; int n, sc; if (tab != null) {
// 小於MIN_TREEIFY_CAPACITY,進行擴容
if ((n = tab.length) < MIN_TREEIFY_CAPACITY)
tryPresize(n << 1);
else if ((b = tabAt(tab, index)) != null && b.hash >= 0) {
synchronized (b) {
// 將連結串列轉換成紅黑樹…
}
}
}
}
…
final V putVal(K key, V value, boolean onlyIfAbsent) {
…
addCount(1L, binCount); // 計數
return null;
}
private final void addCount(long x, int check) {
// 計數…
if (check >= 0) {
Node
[] tab, nt; int n, sc; // s(元素個數)大於等於sizeCtl,觸發擴容
while (s >= (long)(sc = sizeCtl) && (tab = table) != null &&
(n = tab.length) < MAXIMUM_CAPACITY) {
// 擴容標誌位
int rs = resizeStamp(n);
// sizeCtl為負數,代表正有其他執行緒進行擴容
if (sc < 0) {
// 擴容已經結束,中斷迴圈
if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||
sc == rs + MAX_RESIZERS || (nt = nextTable) == null ||
transferIndex <= 0)
break;
// 進行擴容,並設定sizeCtl,表示擴容執行緒 + 1
if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1))
transfer(tab, nt);
}
// 觸發擴容(第一個進行擴容的執行緒)
// 並設定sizeCtl告知其他執行緒
else if (U.compareAndSwapInt(this, SIZECTL, sc,
(rs << RESIZE_STAMP_SHIFT) + 2))
transfer(tab, null);
// 統計個數,用於迴圈檢測是否還需要擴容
s = sumCount();
}
}
}
可以看到有關sizeCtl的操作牽涉到了大量的位運算,我們先來理解這些位運算的意義。首先是resizeStamp(),該函式傳回一個用於資料校驗的標誌位,意思是對長度為n的table進行擴容。它將n的前導零(最高有效位之前的零的數量)和1 << 15做或運算,這時低16位的最高位為1,其他都為n的前導零。
static final int resizeStamp(int n) {
// RESIZE_STAMP_BITS = 16
return Integer.numberOfLeadingZeros(n) | (1 << (RESIZE_STAMP_BITS - 1));
}
初始化sizeCtl(擴容操作被第一個執行緒首次進行)的演演算法為(rs << RESIZE_STAMP_SHIFT) + 2,首先RESIZE_STAMP_SHIFT = 32 - RESIZE_STAMP_BITS = 16,那麼rs << 16等於將這個標誌位移動到了高16位,這時最高位為1,所以sizeCtl此時是個負數,然後加二(至於為什麼是2,還記得有關sizeCtl的說明嗎?1代表初始化狀態,所以實際的執行緒個數是要減去1的)代表當前有一個執行緒正在進行擴容,
這樣sizeCtl就被分割成了兩部分,高16位是一個對n的資料校驗的標誌位,低16位表示參與擴容操作的執行緒個數 + 1。
可能會有讀者有所疑惑,更新進行擴容的執行緒數量的操作為什麼是sc + 1而不是sc – 1,這是因為對sizeCtl的操作都是基於位運算的,所以不會關心它本身的數值是多少,只關心它在二進位制上的數值,而sc + 1會在低16位上加1。

tryPresize()函式跟addCount()的後半段邏輯類似,不斷地根據sizeCtl判斷當前的狀態,然後選擇對應的策略。
private final void tryPresize(int size) {
// 對size進行修正
int c = (size >= (MAXIMUM_CAPACITY >>> 1)) ? MAXIMUM_CAPACITY :
tableSizeFor(size + (size >>> 1) + 1);
int sc;
// sizeCtl是預設值或正整數
// 代表table還未初始化
// 或還沒有其他執行緒正在進行擴容
while ((sc = sizeCtl) >= 0) {
Node
[] tab = table; int n; if (tab == null || (n = tab.length) == 0) {
n = (sc > c) ? sc : c;
// 設定sizeCtl,告訴其他執行緒,table現在正處於初始化狀態
if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {
try {
if (table == tab) {
@SuppressWarnings(“unchecked”)
Node
[] nt = (Node [])new Node,?>[n]; table = nt;
// 計算下次觸發擴容的閾值
sc = n – (n >>> 2);
}
} finally {
// 將閾值賦給sizeCtl
sizeCtl = sc;
}
}
}
// 沒有超過閾值或者大於容量的上限,中斷迴圈
else if (c <= sc || n >= MAXIMUM_CAPACITY)
break;
// 進行擴容,與addCount()後半段的邏輯一致
else if (tab == table) {
int rs = resizeStamp(n);
if (sc < 0) {
Node
[] nt; if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||
sc == rs + MAX_RESIZERS || (nt = nextTable) == null ||
transferIndex <= 0)
break;
if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1))
transfer(tab, nt);
}
else if (U.compareAndSwapInt(this, SIZECTL, sc,
(rs << RESIZE_STAMP_SHIFT) + 2))
transfer(tab, null);
}
}
}
擴容操作的核心在於資料的轉移,在單執行緒環境下資料的轉移很簡單,無非就是把舊陣列中的資料遷移到新的陣列。但是這在多執行緒環境下是行不通的,需要保證執行緒安全性,在擴容的時候其他執行緒也可能正在新增元素,這時又觸發了擴容怎麼辦?有人可能會說,這不難啊,用一個互斥鎖把資料轉移操作的過程鎖住不就好了?這確實是一種可行的解決方法,但同樣也會帶來極差的吞吐量。
互斥鎖會導致所有訪問臨界區的執行緒陷入阻塞狀態,這會消耗額外的系統資源,核心需要儲存這些執行緒的背景關係並放到阻塞佇列,持有鎖的執行緒耗時越長,其他競爭執行緒就會一直被阻塞,因此吞吐量低下,導致響應時間緩慢。而且鎖總是會伴隨著死鎖問題,一旦發生死鎖,整個應用程式都會因此受到影響,所以加鎖永遠是最後的備選方案。
Doug Lea沒有選擇直接加鎖,而是基於CAS實現無鎖的併發同步策略,令人佩服的是他不僅沒有把其他執行緒拒之門外,甚至還邀請它們一起來協助工作。
那麼如何才能讓多個執行緒協同工作呢?Doug Lea把整個table陣列當做多個執行緒之間共享的任務佇列,然後只需維護一個指標,當有一個執行緒開始進行資料轉移,就會先移動指標,表示指標劃過的這片bucket區域由該執行緒負責。
這個指標被宣告為一個volatile整型變數,它的初始位置位於table的尾部,即它等於table.length,很明顯這個任務佇列是逆向遍歷的。
/**
* The next table index (plus one) to split while resizing.
*/
private transient volatile int transferIndex;
/**
* 一個執行緒需要負責的最小bucket數
*/
private static final int MIN_TRANSFER_STRIDE = 16;
/**
* The next table to use; non-null only while resizing.
*/
private transient volatile Node
[] nextTable;
一個已經遷移完畢的bucket會被替換成ForwardingNode節點,用來標記此bucket已經被其他執行緒遷移完畢了。我們之前提到過ForwardingNode,它是一個特殊節點,可以透過hash域的虛擬值來識別它,它同樣重寫了find()函式,用來在新陣列中查詢標的。
資料遷移的操作位於transfer()函式,多個執行緒之間依靠sizeCtl與transferIndex指標來協同工作,每個執行緒都有自己負責的區域,一個完成遷移的bucket會被設定為ForwardingNode,其他執行緒遇見這個特殊節點就跳過該bucket,處理下一個bucket。
transfer()函式可以大致分為三部分,第一部分對後續需要使用的變數進行初始化:
/**
* Moves and/or copies the nodes in each bin to new table. See
* above for explanation.
*/
private final void transfer(Node
[] tab, Node [] nextTab) { int n = tab.length, stride;
// 根據當前機器的CPU數量來決定每個執行緒負責的bucket數
// 避免因為擴容執行緒過多,反而影響到效能
if ((stride = (NCPU > 1) ? (n >>> 3) / NCPU : n) < MIN_TRANSFER_STRIDE)
stride = MIN_TRANSFER_STRIDE; // subdivide range
// 初始化nextTab,容量為舊陣列的一倍
if (nextTab == null) { // initiating
try {
@SuppressWarnings(“unchecked”)
Node
[] nt = (Node [])new Node,?>[n << 1]; nextTab = nt;
} catch (Throwable ex) { // try to cope with OOME
sizeCtl = Integer.MAX_VALUE;
return;
}
nextTable = nextTab;
transferIndex = n; // 初始化指標
}
int nextn = nextTab.length;
ForwardingNode
fwd = new ForwardingNode (nextTab); boolean advance = true;
boolean finishing = false; // to ensure sweep before committing nextTab
第二部分為當前執行緒分配任務和控制當前執行緒的任務進度,這部分是transfer()的核心邏輯,描述瞭如何與其他執行緒協同工作:
// i指向當前bucket,bound表示當前執行緒所負責的bucket區域的邊界
for (int i = 0, bound = 0;;) {
Node
f; int fh; // 這個迴圈使用CAS不斷嘗試為當前執行緒分配任務
// 直到分配成功或任務佇列已經被全部分配完畢
// 如果當前執行緒已經被分配過bucket區域
// 那麼會透過–i指向下一個待處理bucket然後退出該迴圈
while (advance) {
int nextIndex, nextBound;
// –i表示將i指向下一個待處理的bucket
// 如果–i >= bound,代表當前執行緒已經分配過bucket區域
// 並且還留有未處理的bucket
if (–i >= bound || finishing)
advance = false;
// transferIndex指標 <= 0 表示所有bucket已經被分配完畢
else if ((nextIndex = transferIndex) <= 0) {
i = -1;
advance = false;
}
// 移動transferIndex指標
// 為當前執行緒設定所負責的bucket區域的範圍
// i指向該範圍的第一個bucket,註意i是逆向遍歷的
// 這個範圍為(bound, i),i是該區域最後一個bucket,遍歷順序是逆向的
else if (U.compareAndSwapInt
(this, TRANSFERINDEX, nextIndex,
nextBound = (nextIndex > stride ?
nextIndex – stride : 0))) {
bound = nextBound;
i = nextIndex – 1;
advance = false;
}
}
// 當前執行緒已經處理完了所負責的所有bucket
if (i < 0 || i >= n || i + n >= nextn) {
int sc;
// 如果任務佇列已經全部完成
if (finishing) {
nextTable = null;
table = nextTab;
// 設定新的閾值
sizeCtl = (n << 1) - (n >>> 1);
return;
}
// 工作中的擴容執行緒數量減1
if (U.compareAndSwapInt(this, SIZECTL, sc = sizeCtl, sc – 1)) {
// (resizeStamp << RESIZE_STAMP_SHIFT) + 2代表當前有一個擴容執行緒
// 相對的,(sc – 2) != resizeStamp << RESIZE_STAMP_SHIFT
// 表示當前還有其他執行緒正在進行擴容,所以直接傳回
if ((sc – 2) != resizeStamp(n) << RESIZE_STAMP_SHIFT)
return;
// 否則,當前執行緒就是最後一個進行擴容的執行緒
// 設定finishing標識
finishing = advance = true;
i = n; // recheck before commit
}
}
// 如果待處理bucket是空的
// 那麼插入ForwardingNode,以通知其他執行緒
else if ((f = tabAt(tab, i)) == null)
advance = casTabAt(tab, i, null, fwd);
// 如果待處理bucket的頭節點是ForwardingNode
// 說明此bucket已經被處理過了,跳過該bucket
else if ((fh = f.hash) == MOVED)
advance = true; // already processed
最後一部分是具體的遷移過程(對當前指向的bucket),這部分的邏輯與HashMap類似,拿舊陣列的容量當做一個掩碼,然後與節點的hash進行與操作,可以得出該節點的新增有效位,如果新增有效位為0就放入一個連結串列A,如果為1就放入另一個連結串列B,連結串列A在新陣列中的位置不變(跟在舊陣列的索引一致),連結串列B在新陣列中的位置為原索引加上舊陣列容量。
這個方法減少了rehash的計算量,而且還能達到均勻分佈的目的,如果不能理解請去看本文中HashMap擴容操作的解釋。
else {
// 對於節點的操作還是要加上鎖的
// 不過這個鎖的粒度很小,只鎖住了bucket的頭節點
synchronized (f) {
if (tabAt(tab, i) == f) {
Node
ln, hn; // hash code不為負,代表這是條連結串列
if (fh >= 0) {
// fh & n 獲得hash code的新增有效位,用於將連結串列分離成兩類
// 要麼是0要麼是1,關於這個位運算的更多細節
// 請看本文中有關HashMap擴容操作的解釋
int runBit = fh & n;
Node
lastRun = f; // 這個迴圈用於記錄最後一段連續的同一類節點
// 這個類別是透過fh & n來區分的
// 這段連續的同類節點直接被覆用,不會產生額外的複製
for (Node
p = f.next; p != null; p = p.next) { int b = p.hash & n;
if (b != runBit) {
runBit = b;
lastRun = p;
}
}
// 0被放入ln連結串列,1被放入hn連結串列
// lastRun是連續同類節點的起始節點
if (runBit == 0) {
ln = lastRun;
hn = null;
}
else {
hn = lastRun;
ln = null;
}
// 將最後一段的連續同類節點之前的節點按類別複製到ln或hn
// 連結串列的插入方向是往頭部插入的,Node建構式的第四個引數是next
// 所以就算遇到類別與lastRun一致的節點也只會被插入到頭部
for (Node
p = f; p != lastRun; p = p.next) { int ph = p.hash; K pk = p.key; V pv = p.val;
if ((ph & n) == 0)
ln = new Node
(ph, pk, pv, ln); else
hn = new Node
(ph, pk, pv, hn); }
// ln連結串列被放入到原索引位置,hn放入到原索引 + 舊陣列容量
// 這一點與HashMap一致,如果看不懂請去參考本文對HashMap擴容的講解
setTabAt(nextTab, i, ln);
setTabAt(nextTab, i + n, hn);
setTabAt(tab, i, fwd); // 標記該bucket已被處理
advance = true;
}
// 對紅黑樹的操作,邏輯與連結串列一樣,按新增有效位進行分類
else if (f instanceof TreeBin) {
TreeBin
t = (TreeBin )f; TreeNode
lo = null, loTail = null; TreeNode
hi = null, hiTail = null; int lc = 0, hc = 0;
for (Node
e = t.first; e != null; e = e.next) { int h = e.hash;
TreeNode
p = new TreeNode (h, e.key, e.val, null, null);
if ((h & n) == 0) {
if ((p.prev = loTail) == null)
lo = p;
else
loTail.next = p;
loTail = p;
++lc;
}
else {
if ((p.prev = hiTail) == null)
hi = p;
else
hiTail.next = p;
hiTail = p;
++hc;
}
}
// 元素數量沒有超過UNTREEIFY_THRESHOLD,退化成連結串列
ln = (lc <= UNTREEIFY_THRESHOLD) ? untreeify(lo) :
(hc != 0) ? new TreeBin
(lo) : t; hn = (hc <= UNTREEIFY_THRESHOLD) ? untreeify(hi) :
(lc != 0) ? new TreeBin
(hi) : t; setTabAt(nextTab, i, ln);
setTabAt(nextTab, i + n, hn);
setTabAt(tab, i, fwd);
advance = true;
}
系列
【關於投稿】
如果大家有原創好文投稿,請直接給公號傳送留言。
① 留言格式:
【投稿】+《 文章標題》+ 文章連結
② 示例:
【投稿】《不要自稱是程式員,我十多年的 IT 職場總結》:http://blog.jobbole.com/94148/
③ 最後請附上您的個人簡介哈~
看完本文有收穫?請轉發分享給更多人
關註「ImportNew」,提升Java技能

