傳統的Container由於隔離性差而不適合作為Sandbox執行不受信工作負載,VM可以提供很好隔離但卻額外消耗較多的記憶體。Google開源的gVisor為我們提供另外一種選擇:在犧牲掉一定效能的情況下,它只額外消耗非常少量的記憶體,卻可以提供了類似等級的隔離性。在本文裡我們深入gVisor,最後瞭解一下我們增強gVisor以支援資源控制的方案。
gVisor為在Container中執行不受信程式碼提供了新的解決思路,gVisor是一個Sandbox方案和實現。
雖然Container上可以透過Namespace和Cgroup做資源的限制,但Container裡的應用程式依然可以訪問很多系統資源。事實上跟沒有跑在Container裡的應用程式一樣,Container裡的應用程式可以直接透過Linux內核的系統呼叫陷入到核心。任何一個被允許(透過Seccomp過濾系統呼叫)的系統呼叫的缺陷都可以被惡意的應用程式利用。
主流的Sandbox基於VM虛擬機器的方案,將潛在惡意的應用程式隔離在獨立的虛擬機器中,例如Kata Linux,該專案與Docker和Kubernetes都有整合。基於VM的方案提高了很好的隔離,但相應額外消耗的記憶體會多一些。在有需要執行大量Container的場景下的額外資源消耗不能被忽略。
gVisor提供了另外一種Sandbox思路,gVisor非常輕量級,額外的記憶體消耗非常小,但同時提供了和VM方案相當隔離等級。該分享裡介紹的基於Ptrace的gVisor,系統呼叫的效能比較差,應用程式的相容性也差一些。gVisor可以和Docker很好的整合,但和Kubernetes的整合還處於實驗階段。在和Docker整合的時候,gVisor遵循了OCI(Open Containers Initiative)標準,所以可以作為Docker的一個Runtime執行。

以非特權使用者執行的gVisor透過截獲應用程式的系統呼叫,將應用程式和核心之間完全隔離。gVisor沒有簡單的把應用程式發出的系統呼叫直接作用到核心,而是實現了大多數的系統呼叫,透過對系統呼叫模擬,讓應用程式間接的訪問到系統資源。gVisor模擬系統呼叫本身時對作業系統執行系統呼叫,透過使用Seccomp對這些系統呼叫做過濾。那麼gVisor是如何截獲應用程式的系統呼叫的呢?
gVisor存在兩種執行樣式,這次分享只介紹了基於Ptrace的gVisor。
為了理解gVisor如何攔截系統呼叫,需要先瞭解一下Ptrace:Ptrace是Linux提供的一個系統呼叫介面,透過Ptrace,可以在兩個行程之間建立Tracer和Tracee之間的關係。Tracer可以控制Tracee,例如當Tracee收到訊號的時候主動進入stopped狀態,此時Tracer可以選擇是否對Tracee做一些操作(比如設定Tracee的暫存器背景關係或者記憶體中內容等),在操作執行後,Tracer可以選擇是否讓Tracee繼續執行。
Tracee除了可以在接受到訊號時候進入stopped狀態外,也可以被Tracer告知在即將進入系統呼叫時或者即將離開系統呼叫時進入stopped狀態。具體說Ptrace可以透過PTRACE_SYSEMU控制Tracee在即將進去系統調動時stop。gVisor也正是透過該命令來截獲應用程式的系統呼叫。
Sentry是透過Ptrace來控制應用程式,那麼應用程式是如何變為Tracee的呢?
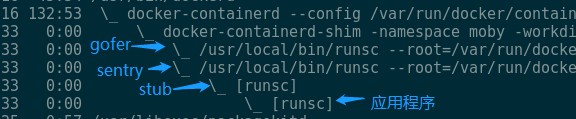
當gVisor以Docker的Runtime啟動的時候,可以看到類似的行程間關係:docker-containerd-shim是容器的啟動器;sentry是gVisor用於截獲系統呼叫模擬內核的程式,他也正是Tracer。Stub可以暫時不用理會,stub的子行程正是我們想要放到Sandbox裡的應用程式。Sentry建立stub,隨後stub建立應用程式行程,sentry透過Ptrace attach到了stub和應用程式上。當應用程式在將要執行系統呼叫的時候會主動stop,此時也正是sentry攔截和模擬系統呼叫的點。
這跟用gdb除錯程式C/C++程式類似,透過命令列給gdb指定一個要除錯的標的程式的時候,該程式會以子行程的方式執行,gdb作為Tracer attach到應用程式上來對應用程式進行控制。類似gdb,sentry也以類似的方式啟動應用程式,只是sentry先啟動了一個stub,然後讓stub以它的子行程方式啟動了應用程式。
應用程式被建立並變為Tracee後,接下來就是sentry如何完成應用程式的啟動流程了。
應用程式被初始attach到sentry後,sentry負責啟動應用程式。
在作業系統啟動應程式場景裡,應用程式的二進位制檔案由作業系統載入,譬如分配虛擬記憶體空間用來存放二進制中的程式碼段、資料段、共享庫或者初始化應用程式的棧空間。gVisor啟動應用程式的場景下,類似的過程由sentry完成:
為了瞭解sentry是如何初始化應用程式的虛擬記憶體空間,需要先瞭解一下上文提到的stub行程。
Stub行程的一個重要的作用是作為應用程式的初始模板,以該模板建立應用程式。事實上stub作為sentry的子行程,在啟動後會主動將虛擬記憶體地址空間裡幾乎所有的memory region(透過檢視/proc/${pid}/maps檢視一個行程虛擬記憶體地址空間裡的所有memory region)甚至將程式碼段和資料段也unmmap掉了。只保留兩個memory region:
其中第一個region存放了最簡化的程式碼,即上圖中第一個段,執行該程式碼甚至不需要棧空間,所以連棧段也被unmap掉了。
這樣的空洞的虛擬內容地址空間正好可以作為一個模板虛擬記憶體地址空間。當stub以子行程的方式啟動應用程式後,應用程式的虛擬記憶體地址空間的layout與stub的一樣。應用程式在創建出來後會立即被sentry attach,此時正是sentry做應用程式初始化的過程:sentry初始設定應用程式的RIP(指令執行暫存器)的初始值為應用程式二進制中讀出來的應用程式入口地址,該地址一般位於應用程式虛擬地址空間的較低位置,並透過PTRACE_SYSEMU指示應用程式開始執行,直到遇到以下兩種事件的時候進入stop狀態:
-
將要執行一個系統呼叫
-
收到了來自核心或者行程發給它的訊號
因為應用程式的初始執行位置在使用者態的虛擬記憶體地址裡沒有對應的memory region,所以應用程式會收到來自核心發來的SIGSEGV訊號(段錯誤)。這裡的場景非常類似通常的page fault,當一個應用程式試圖訪問的地址位於某個虛擬記憶體地址段內,但該段沒有對應物理記憶體頁的時候,作業系統會因此陷入page fault,在page fault的handler中為該虛擬記憶體地址段對映物理頁。
事實上,在sentry在啟動應用程式執行環境之前,已經應用程式“分配”了一個虛擬記憶體地址段(這個分配並不是使用mmap或者brk真正的在應用程式的虛擬地址空間中分配地址段,該分配是一個提前佔位)。上面說到當應用程式執行指令地址上因為沒有實際分配虛擬記憶體地址段,所以收到來自內核的SIGSEGV,並且進入stopped狀態,此時sentry會透過mmap在該地址上真實分配一個虛擬地址記憶體段(類比作業系統為虛擬記憶體地址段上分配物理頁),並且因為mmap的源檔案是二進位制檔案本身,所以當sentry在處理完SIGSEGV指示應用程式繼續執行的後,應用程式將實際執行到該二進制中的程式碼。
至此應用程式就已經啟動起來了。接下來需要瞭解就是sentry如何控制應用程式的執行了。
應用程式被啟動起來後,在執行的過程中可能會陸續遇到新的SIGSEGV(譬如程式讀寫地址段,或者棧空間的擴充套件),或者執行系統呼叫。
在“應用程式如何被啟動”裡實際上已經描述了SIGSEGV訊號處理的一種場景,即只讀地址且有對映檔案的場景,其他的場景譬如匿名地址段或者棧空間的區別在於該地址段沒有mmap實際的檔案,而是mmap了一個sentry提前準備好的“空白”檔案中。
在“gVisor如何攔截系統呼叫”中描述了系統呼叫的攔截,當應用程式在進入系統呼叫之前會自動進入stopped狀態,此時sentry讀取應用程式的系統呼叫號以及系統呼叫入參,試圖模擬該系統呼叫。以檔案的讀sys_read為例,sys_read的作用是找到指定的檔案,開啟並讀取檔案內容,並將記憶體寫入到應用程式系統呼叫引數指定的虛擬記憶體地址上。Sentry在接到這個的系統呼叫時,會將檔案讀取請求透過9p協議發給之前提到的gofer行程(sentry和gofer之間有建立socket pair傳輸9p協議),由gofer行程執行真正的檔案讀取且將讀到的內容透過9p協議傳回給sentry。sentry把讀取到的檔案內容寫入到應用程式的虛擬記憶體中(如果該地址沒有對應的虛擬記憶體地址段,則分配後再複製),隨後sentry將系統呼叫的實際模擬結果寫入到應用程式的暫存器中,然後讓應用程式繼續執行。恢復執行後的應用程式因為得到了系統呼叫的結果,所以在應用程式在分不清實際上系統呼叫是直接由作業系統執行了還是由sentry做的模擬的情況下,系統呼叫得到了滿足。
“應用程式的執行”中對於檔案讀系統呼叫處理的描述實際上也描述了對應用程式檔案系統訪問的控制,實際上在“應用程式啟動”中為了省略的根檔案系統掛載的描述,在根檔案系統掛載的模擬中也涉及到了透過9p協議對檔案系統的訪問。檔案寫的處理也非常類似。
除了檔案讀寫外,還有很多其他的系統呼叫,譬如共享記憶體或其他IPC,鎖,建立執行緒或者行程,傳送訊號,socket,execv,epoll,eventfd,pid namespace等,gVisor都進行了模擬,涉及到了作業系統的方方面面。這裡僅僅介紹了socket相關的系統呼叫:
Sentry在使用者態實現了基本的TCP/IP協議棧,在啟動應用程式之前,gVisor會啟動一個臨時的start行程,在start行程會進入到docker建立的network namespace,start行程從該network namespace中獲取veth pair中屬於gVisor的一端的veth裝置,建立AF_PACKET的socket系結到該veth裝置上來接管該裝置上的網路流量(同時也將ip從該裝置上去掉了),並將該socket傳遞給sentry行程。後續當sentry截獲了應用程式的socket系統呼叫後,最終透過該socket將網路包實際從veth裝置上發送出去;從該veth裝置上接收到的網路包在經過sentry網路協議棧後遞交給應用程式的socket層。
gVisor具備沙盒的能力,但是缺少Cgroup提供的資源使用量的限制的功能。在官方的Roadmap中計劃提供Cgroup支援。但此時為了能夠使用gVisor執行工作負載,需要讓gVisor具備資源使用量限制的功能。
Docker透過Runtime支援資源使用量限制,gVisor則是Docker的另外一個Runtime名叫runsc。透過瞭解Docker原生的Runtime即runC,可以為gVisor中支援Cgroup提供思路。Docker透過OCI(Open Containers Initiative)spec跟Runtime之間進行互動,符合該標準的Runtime可以透過Docker的命令來啟動。OCI spec裡規範了應用程式啟動資源使用量的限制的描述,Docker在啟動Runtime的時候,將OCI spec內容傳遞給Runtime,由Runtime負責給應用程式應用這些資源限制:
runC由docker shim啟動,首先會建立一個init行程,該行程最終會透過execv轉變為我們希望啟動的應用程式,在init行程執行execv之前,runC會為init行程建立Cgroup,將實際上init行程放入到該Cgroup中。此後init行程透過execv變為應用程式,應用程式以及後來由它建立的子行程也都會進入到該Cgroup中,從而達到資源限制的功能。
gVisor的啟動流程中類似也可以嵌入類似的邏輯:runsc啟動流程中首先會建立gofer和boot行程,在boot行程真正啟動應用程式之前,runsc為boot行程建立新的Cgroup,並將boot行程放入到該Cgroup中,後續boot行程以及被它Ptrace的應用程式就都會處於該Cgroup中,從而達到資源限制的效果。
Kubernetes應用實戰培訓將於2018年10月12日在深圳開課,3天時間帶你係統學習Kubernetes。本次培訓包括:容器基礎、Docker基礎、Docker進階、Kubernetes架構及部署、Kubernetes常用物件、Kubernetes網路、儲存、服務發現、Kubernetes的排程和服務質量保證、監控和日誌、Helm、專案實踐等,點選下方圖片檢視詳情。

長按二維碼向我轉賬

受蘋果公司新規定影響,微信 iOS 版的贊賞功能被關閉,可透過二維碼轉賬支援公眾號。
![]()
微信掃一掃
使用小程式