今天教大家如何搭建一套資料分析平臺。
它可能是最簡單的搭建教程,有一點Python基礎都能完成。比起動輒研發數月的成熟系統,藉助開源工具,整個時間能壓縮在一小時內完成。
優秀的資料分析平臺,首先要滿足資料查詢、統計、多維分析、資料報表等功能。可惜很多分析師,工作的第一年,都是埋葬在SQL陳述句中,以SQL+Excel的形式完成工作,卻用不上高效率的工具。
說Excel也很好用的同學,請先迴避一下。
另外一方面,以網際網路為代表的公司越來越重視資料,資料獲取不再是難點,難點是怎樣敏捷分析獲得洞察。
市面上已經有不少公司推出企業級的分析平臺和BI,可惜它們都是收費的。我相信不少讀者聽說過,但一直沒有機會體驗,或者老闆們囊中羞澀。現在,完完全全能免費建立一套BI系統,即可以單機版用以分析,也能私有化部署到伺服器,成為自家公司的分析工具。
這一切,只需要一小時。
Superset
Superset是一款輕量級的BI工具,由Airbnb的資料部門開源。整個專案基於Python框架,不是Python我也不會推薦了,它集成了Flask、D3、Pandas、SqlAlchemy等。

這是官網的案例(本來是動圖的,可惜壓縮後也超過微信圖片大小限制,吐槽下),想必設計介面已經能秒殺一批市面上的產品了,很多BI真的是濃烈的中國式報表風……因為它的前端基於D3,所以絕大部分的視覺化圖表都支援,甚至更強大。

Superset本身集成了資料查詢功能,查詢對分析師那是常有的事。它支援各類主流資料庫,包括MySQL、PostgresSQL、Oracle、Impala、SparkSQL等,深度支援Druid。
後臺支援許可權分配管理,針對資料源分配賬戶。所以它在部署伺服器後,分析師們可以透過它查詢資料,也能透過資料建立Dashboard報表。
介紹了這麼多,想必大家已經想要安裝了吧。
安裝
Superset同時支援Python2和Python3, 我這裡以Python3作為演示。它支援pip形式的下載,不過我不建議直接安裝,因為Superset的依賴包較多,如果直接安裝,很容易和現有的模組產生衝突。
這裡需要先搭建Python的虛擬環境。虛擬環境可以幫助我們在單機上建立多個版本的Python。簡而言之,即可以Python2和Python3共存,也能Python3.3、3.4、3.5共濟一堂,彼此間互相獨立。
虛擬環境的安裝方式很多,pyenv和virtualenv等。這裡用Anaconda自帶的conda工具。開啟電腦終端/cmd,輸入以下命令。

conda create -n superset python=3.4
conda create是建立虛擬環境的命令。-n是環境的命名引數,在這裡,我們建立了名為superset的環境,它安裝在Anaconda的envs目錄下。python版本為3.4(superset暫時不支援3.6)。
該命令只會安裝基礎包,如果需要額外安裝其他包,在命令列後加上想要的包名字即可,如python=3.4 numpy pandas。
安裝很迅速,完成後,我們的Python環境還是預設版本,現在需要啟用虛擬環境。
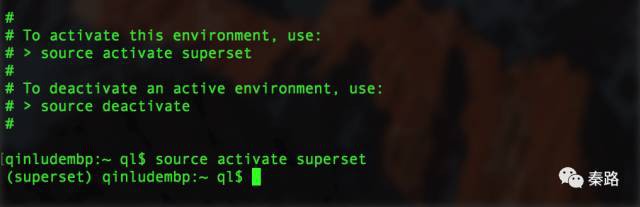
source activate superset
source activate是啟用命令,superset為想要啟用的虛擬環境名。windows和mac的命令不一樣,win只要activate superset 。如果要退出,則是source deactivate或者deactivate。
啟用成功後,命令列前面會多出一個字首(superset),表明切換到了新的虛擬環境。接下來安裝superset。
pip install superset
pip會自動安裝所有的依賴,速度可能有點慢,建議更改pip源。

命令列後加上 -i https://pypi.douban.com/simple ,我這裡用了豆瓣的映象源,速度嗖嗖的。
如果安裝過程中報錯,是部分程式缺失,像系統比較老舊的win使用者,需要安裝新版的visual c++,網上搜索教程即可。在官網的教程中,還要求pip install cryptography==1.7.2,我沒有安裝也沒有影響,供大家參考。其他報錯,都可以透過搜尋解決。
安裝成功後,需要進行初始化配置,也是在命令列輸入。
fabmanager create-admin –app superset
首先用命令列建立一個admin管理員賬戶,也是後續的登陸賬號。會依次提示輸入賬戶名,賬戶使用者的first name、last name、郵箱、以及確認密碼。fabmanager是flask的許可權管理命令,如果大家忘了密碼,也能重新設立。
superset db upgrade
初始化資料源。
superset load_examples
載入案例資料,這裡的案例資料是世界衛生組織的資料,也是上文演示的各類視覺化圖表,大家登陸後能夠直接看到。下載速度還行。
superset init
初始化預設的使用者角色和許可權。
superset runserver
最後一步驟,啟動Superset服務。因為我們是本地環境,所以在瀏覽器輸入 http://localhost:8088 即可。在runserver後面新增 -p XXXX 可更改為其他埠。

進入登陸介面,輸入登陸密碼,大功告成。
使用
先別急著使用,因為Superset是英文,我們先把它漢化了。Superset自身支援語言切換。
進入到Superset所在目錄檔案,按我之前的步驟,應該在anaconda/envs/superset/lib/python3.4/site-packages/superset中,路徑視各位情況可能有差異。
在目錄下有一個叫config.py的檔案,開啟它,找到Setup default language這一行,修改變數。

BABEL_DEFAULT_LOCALE調整為zh,這樣介面預設為中文。languages字典中zh前面的註釋#去掉。儲存後退出。
接下來還是在Superset的目錄下新建立檔案夾,按translations/zh/LC_MESSAGES的路徑依次建立三個。Superset官網提供了漢化包,在最大的同性交友網站github上下載,目錄為:
https://github.com/apache/incubator-superset/blob/master/superset/translations/zh/LC_MESSAGES/messages.mo
網址路徑有點長,下載後把mo檔案放在LC_MESSAGES檔案下。清除瀏覽器的快取,重新登陸localhost。
搞定!
需要註意的是,它並非完全漢化,而是漢化了superset相關的部分。部分文字被寫入在flask app的檔案中,漢化起來比較麻煩。
Superset分為多個模組,安全模組是賬號管理相關,包括角色串列,檢視許可權控制,操作日誌等。管理模組沒什麼用,主要是設計元素。
資料源可以訪問和連線資料庫,切片是各類資料視覺化,均是單圖;看板即為Dashboard,是切片的集合,Superset提供了三個初始案例,SQL工具箱是資料查詢平臺。

麻雀雖小,五臟俱全,對於大部分中小型的企業,Superset足以應付資料分析工作。
先學習連線資料庫,這裡以我電腦中的資料庫為準,如果大家學習過早前的教程,那麼資料庫中都應該有資料分析師的練習資料,我這裡不重覆了,可以看歷史文章。也可用自帶的衛生資料照著練習。
Superset使用了sqlalchemy框架,使用前需要安裝資料庫驅動程式,先退出runserver,進入superset虛擬環境,安裝Python中的MySQL驅動程式。
pip install pymysql
MySQL的驅動程式很多,除了pymysql,還有mysqlclient等。安裝好後,進入資料源,新建一個database連線。

在SQLAlchemy URL中加入資料庫的地址,格式為:
mysql+pymysql://root:xxxx@localhost:3306/qin?charset=utf8
mysql是資料庫型別,pymysql是驅動程式,表示用pymysql連線mysql資料庫,+號不能省略。
另外,root是資料庫登陸賬號,xxxx為密碼,這個按大家自己設立的來。localhost是資料庫地址,因為我的是本地環境,所以localhost即可,也可以是127.0.0.1。3306是埠,一般預設這個。qin是需要連線的資料庫,也是我自己設的名字。後面帶引數charset=utf8,表示編碼,因為表裡面有中文。
其他資料庫的連線大同小異,圖中綠色的連線是相關教程。
如果大家在公司網路,擁有內網訪問資料庫的許可權,也可以嘗試連線,應該是可以的,這樣就能在個人電腦上實行敏捷的BI分析。
格式命名好後,點選測試,出現seems ok,表示成功訪問。在選項下麵還有個Expose in SQL Lab,允許我們在SQL工具箱查詢,要打上勾。
進入到SQL工具箱,左邊選擇table為DataAnalyst。
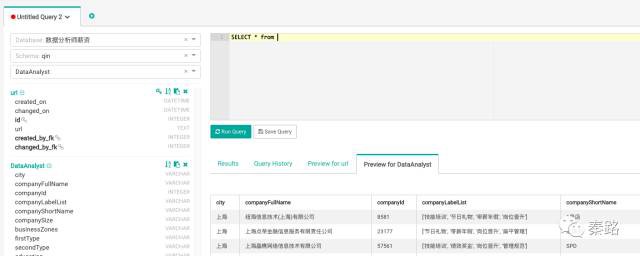
直接出來了資料庫的資料預覽。連查詢平臺的顏值都那麼高。大家的SQL技能應該都很不錯,有興趣可以在這裡練習一下,語法和MySQL一致。其他資料庫則是其他資料庫的語法。

執行一段SQL陳述句,它支援下載為CSV,我沒試過支援最大檔案的大小,但作為日常的查詢平臺是綽綽有餘了。
選擇Visualize,進入切片繪圖樣式。

這裡自動匹配支援的圖表選項,包括Bar Chart條形圖,Pir Chart餅圖等。下麵的選項是定義維度,我們將city,education,postitionName,salary,workYear都勾選為維度。agg_func是聚合功能,這裡將職位ID求和,改成count(),點選生成圖表。

這裡按城市生成了各職位ID求和獲得的條形圖,也就是不同城市的分析師人數。
左邊Chart Options可以調整分析需要的維度。Metrics是分析的度量,這裡是count(positionId),Series是條形圖中的類別,Breakdowns可以認為是分組或者分桶。這裡將Series改成workYear,Breakdowns改成city,點選Query執行。

條形圖變更為按工作年限和城市細分的多維條形圖。點選Stacked Bars,則切換成堆積柱形圖。操作不難。

左側的選項欄還有其他功能,這裡就不多做介紹了,和市面上常見的BI沒有多大區別,琢磨一下也就會了。
Superset支援的圖表很豐富,如果具備開發能力,也能以D3和Flask為基礎做二次開發。Airbnb官方也會不斷加入新的圖表。不同圖表,其左側的操作選項也不同。
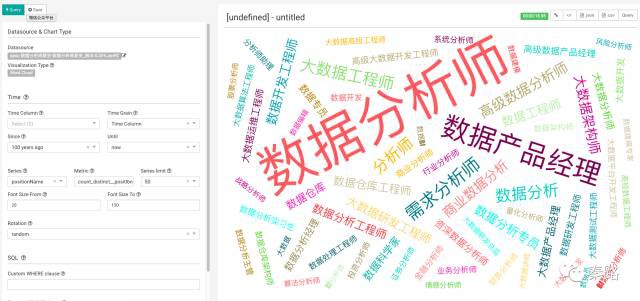
上圖是以資料分析師職位名稱為基礎繪製的詞雲圖,生成的速度會比較慢。我們選擇save儲存。完成的圖表均存放在切片下。

Dashboard透過多個切片組合完成,每個切片連線不同的資料源,這是BI的基本邏輯。進入看板介面,新建一個Dashboard。

設定看板相應的配置選項,因為我偷懶了,所以只做了兩個切片,大家有興趣可以繼續增加。其他選項忽略,都是自動生成的。點選save,到這一步,BI最重要的Dashboard就完成了。
瀏覽一下最終的成果吧。

關於Superset的新手教學結束了,要是部署到公司,賬號和許可權多研究下。它和市面上的其他BI沒有太多區別,不過它是我們用Python從零到有一手建立,這個感覺可比用Excel爽不少。雖然我的演示以單機版為主,將其建立在linux伺服器上大同小異。
從零開始搭建到現在,排除掉下載花費的時間,大家可以計算是不是真的只用一個小時就搭建好一個資料分析平臺?沒騙你們吧。
透過搭建Superset,資料分析新手對BI應該也有一個大概的瞭解,市面上的BI大同小異,只是側重點不同。在Superset的基礎上,往底層完成埋點採集和資料ETL,往上拓展報表監控,CRM等,這些也有不少開源軟體可用。至於機器學習,以及Hadoop和Spark更是一個大生態,把這些都算上,則是真正完整的大資料分析平臺了。
Superset也有缺陷,它使用的是ORM框架,雖然它能連線眾多的資料庫,但是它有一個關係對映過程,將SQL資料轉化為Python中的物件,這也造成它在大資料量的處理效率不如專業的BI軟體。在使用SQL工具箱時,應該儘量避免超大表之間的關聯,以及複雜的group by。
我個人的建議是,它只是一款輕量級的BI,複雜的資料關聯,應該在ETL過程中完成,Superset只需要執行最終結果表的讀取即可。它足夠支撐TB級別的資料源讀取。技術比較成熟的團隊,也能嘗試將Superset和Kylin整合,這樣OLAP的能力又能上一個臺階。
另外,Superset中的表都是獨立的,所以多圖表間的複雜聯動並不支援,僅支援過濾,這點比較可惜。不知道Airbnb後續會不會支援。
好訊息是,這個開源專案一直在更新,github什麼也有很多新的功能特性待開發,比如dashboard上加入tab切換欄等。可以star一下關註。
作者:秦路 ;轉自:秦路 公眾號;本文獲授權;
END
版權宣告:本號內容部分來自網際網路,轉載請註明原文連結和作者,如有侵權或出處有誤請和我們聯絡。
關聯閱讀:
原創系列文章:
資料運營 關聯文章閱讀:
資料分析、資料產品 關聯文章閱讀:
80%的運營註定了打雜?因為你沒有搭建出一套有效的使用者運營體系
合作請加qq:365242293
更多相關知識請回覆:“ 月光寶盒 ”;
資料分析(ID : ecshujufenxi )網際網路科技與資料圈自己的微信,也是WeMedia自媒體聯盟成員之一,WeMedia聯盟改寫5000萬人群。
