導讀:知乎儲存平臺團隊基於開源Redis 元件打造的知乎 Redis 平臺,經過不斷的研發迭代,目前已經形成了一整套完整自動化運維服務體系,提供很多強大的功能。本文作者是是該系統的負責人,文章深入介紹了該系統的方方面面,作為後端程式員值得仔細研究。
作者簡介:陳鵬,現知乎儲存平臺組 Redis 平臺技術負責人,2014 年加入知乎技術平臺組從事基礎架構相關係統的開發與運維,從無到有建立了知乎 Redis 平臺,承載了知乎高速增長的業務流量。
背景
知乎作為知名中文知識內容平臺,每日處理的訪問量巨大,如何更好的承載這樣巨大的訪問量,同時提供穩定低時延的服務保證,是知乎技術平臺同學需要面對的一大挑戰。
知乎儲存平臺團隊基於開源Redis 元件打造的 Redis 平臺管理系統,經過不斷的研發迭代,目前已經形成了一整套完整自動化運維服務體系,提供一鍵部署叢集,一鍵自動擴縮容, Redis 超細粒度監控,旁路流量分析等輔助功能。
目前,Redis 在知乎規模如下:
● 機器記憶體總量約70TB,實際使用記憶體約40TB;
● 平均每秒處理約1500萬次請求,峰值每秒約2000萬次請求;
● 每天處理約1萬億餘次請求;
● 單叢集每秒處理最高每秒約400萬次請求;
● 叢集實體與單機實體總共約800個;
● 實際執行約16000個Redis 實體;
● Redis 使用官方3.0.7版本,少部分實體採用4.0.11版本。
Redis at Zhihu
根據業務的需求,我們將實體區分為單機(Standalone)和叢集(Cluster)兩種型別,單機實體通常用於容量與效能要求不高的小型儲存,而叢集則用來應對對效能和容量要求較高的場景。
單機(Standalone)
對於單機實體,我們採用原生主從(Master-Slave)樣式實現高可用,常規樣式下對外僅暴露 Master 節點。由於使用原生 Redis,所以單機實體支援所有 Redis 指令。
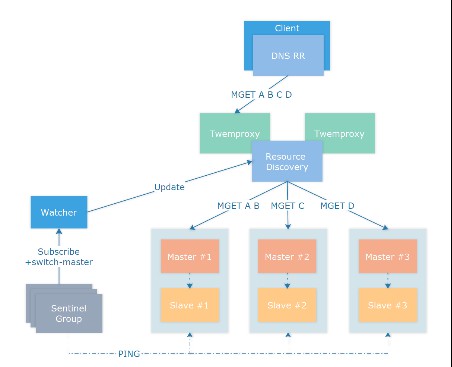
對於單機實體,我們使用Redis 自帶的哨兵(Sentinel)叢集對實體進行狀態監控與 Failover。Sentinel 是 Redis 自帶的高可用元件,將 Redis 註冊到由多個 Sentinel 組成的 Sentinel 叢集後,Sentinel 會對 Redis 實體進行健康檢查,當 Redis 發生故障後,Sentinel 會透過 Gossip 協議進行故障檢測,確認宕機後會透過一個簡化的 Raft 協議來提升 Slave 成為新的 Master。
通常情況我們僅使用1 個 Slave 節點進行冷備,如果有讀寫分離請求,可以建立多個Read only slave 來進行讀寫分離。

如圖所示,透過向Sentinel 叢集註冊 Master 節點實現實體的高可用,當提交 Master 實體的連線資訊後,Sentinel 會主動探測所有的 Slave 實體並建立連線,定期檢查健康狀態。客戶端透過多種資源發現策略如簡單的 DNS 發現 Master 節點,將來有計劃遷移到如 Consul 或 etcd 等資源發現元件 。
當Master 節點發生宕機時,Sentinel 叢集會提升 Slave 節點為新的 Master,同時在自身的 pubsub channel +switch-master 廣播切換的訊息,具體訊息格式為:
switch-master
watcher 監聽到訊息後,會去主動更新資源發現策略,將客戶端連線指向新的 Master 節點,完成 Failover,具體 Failover 切換過程詳見 Redis 官方檔案。
Redis Sentinel Documentation [1]
實際使用中需要註意以下幾點:
● 只讀Slave 節點可以按照需求設定 slave-priority 引數為0,防止故障切換時選擇了只讀節點而不是熱備 Slave 節點;
● Sentinel 進行故障切換後會執行 CONFIG REWRITE 命令將SLAVEOF 配置落地,如果 Redis 配置中禁用了 CONFIG 命令,切換時會發生錯誤,可以透過修改 Sentinel 程式碼來替換 CONFIG 命令;
● Sentinel Group 監控的節點不宜過多,實測超過 500 個切換過程偶爾會進入 TILT 樣式,導致Sentinel 工作不正常,推薦部署多個 Sentinel 叢集並保證每個叢集監控的實體數量小於 300 個;
● Master 節點應與 Slave 節點跨機器部署,有能力的使用方可以跨機架部署,不推薦跨機房部署 Redis 主從實體;
● Sentinel 切換功能主要依賴 down-after-milliseconds 和failover-timeout 兩個引數,down-after-milliseconds 決定了Sentinel 判斷 Redis 節點宕機的超時,知乎使用 30000 作為閾值。而 failover-timeout 則決定了兩次切換之間的最短等待時間,如果對於切換成功率要求較高,可以適當縮短failover-timeout 到秒級保證切換成功,具體詳見Redis 官方檔案[2];
● 單機網路故障等同於機器宕機,但如果機房全網發生大規模故障會造成主從多次切換,此時資源發現服務可能更新不夠及時,需要人工介入。
叢集(Cluster)
當實體需要的容量超過20G 或要求的吞吐量超過 20萬請求每秒時,我們會使用叢集(Cluster)實體來承擔流量。叢集是透過中介軟體(客戶端或中間代理等)將流量分散到多個 Redis 實體上的解決方案。
知乎的Redis 叢集方案經歷了兩個階段:客戶端分片與 Twemproxy 代理
客戶端分片(before 2015)
早期知乎使用redis-shard 進行客戶端分片,redis-shard 庫內部實現了 CRC32、MD5、SHA1三種雜湊演演算法,支援絕大部分Redis 命令。使用者只需把 redis-shard 當成原生客戶端使用即可,無需關註底層分片。

基於客戶端的分片樣式具有如下優點:
● 基於客戶端分片的方案是叢集方案中最快的,沒有中介軟體,僅需要客戶端進行一次雜湊計算,不需要經過代理,沒有官方叢集方案的MOVED/ASK 轉向;
● 不需要多餘的Proxy 機器,不用考慮 Proxy 部署與維護;
● 可以自定義更適合生產環境的雜湊演演算法。
但是也存在如下問題:
● 需要每種語言都實現一遍客戶端邏輯,早期知乎全站使用Python 進行開發,但是後來業務線增多,使用的語言增加至 Python,Golang,Lua,C/C++,JVM 系(Java,Scala,Kotlin)等,維護成本過高;
● 無法正常使用MSET、MGET 等多種同時操作多個Key 的命令,需要使用 Hash tag 來保證多個 Key 在同一個分片上;
● 升級麻煩,升級客戶端需要所有業務升級更新重啟,業務規模變大後無法推動;
● 擴容困難,儲存需要停機使用指令碼Scan 所有的 Key 進行遷移,快取只能透過傳統的翻倍取模方式進行擴容;
● 由於每個客戶端都要與所有的分片建立池化連線,客戶端基數過大時會造成Redis 端連線數過多,Redis 分片過多時會造成 Python 客戶端負載升高。
具體特點詳見zhihu/redis-shard[3]。早期知乎大部分業務由Python 構建,Redis 使用的容量波動較小, redis-shard 很好地應對了這個時期的業務需求,在當時是一個較為不錯解決方案。
Twemproxy 叢集 (2015 – Now)
2015 年開始,業務上漲迅猛,Redis 需求暴增,原有的 redis-shard 樣式已經無法滿足日益增長的擴容需求,我們開始調研多種叢集方案,最終選擇了簡單高效的 Twemproxy 作為我們的叢集方案。
由Twitter 開源的 Twemproxy 具有如下優點:
● 效能很好且足夠穩定,自建記憶體池實現Buffer 復用,程式碼質量很高;
● 支援fnv1a_64、murmur、md5 等多種雜湊演演算法;
● 支援一致性雜湊(ketama),取模雜湊(modula)和隨機(random)三種分散式演演算法。
具體特點詳見twitter/twemproxygithub.com[4]
但是缺點也很明顯:
● 單核模型造成效能瓶頸;
● 傳統擴容樣式僅支援停機擴容。
對此,我們將叢集實體分成兩種樣式,即快取(Cache)和儲存(Storage):
如果使用方可以接收透過損失一部分少量資料來保證可用性,或使用方可以從其餘儲存恢復實體中的資料,這種實體即為快取,其餘情況均為儲存。
我們對快取和儲存採用了不同的策略:
儲存
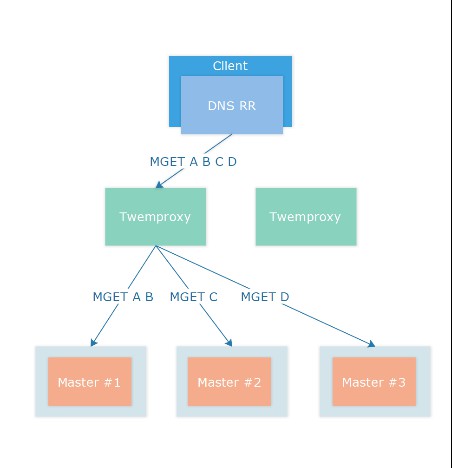
對於儲存我們使用fnv1a_64 演演算法結合modula 樣式即取模雜湊對Key 進行分片,底層 Redis 使用單機樣式結合 Sentinel 叢集實現高可用,預設使用 1 個 Master 節點和 1 個 Slave 節點提供服務,如果業務有更高的可用性要求,可以拓展 Slave 節點。
當叢集中Master 節點宕機,按照單機樣式下的高可用流程進行切換,Twemproxy 在連線斷開後會進行重連,對於儲存樣式下的叢集,我們不會設定 auto_eject_hosts, 不會剔除節點。
同時,對於儲存實體,我們預設使用noeviction 策略,在記憶體使用超過規定的額度時直接傳回OOM 錯誤,不會主動進行 Key 的刪除,保證資料的完整性。
由於Twemproxy 僅進行高效能的命令轉發,不進行讀寫分離,所以預設沒有讀寫分離功能,而在實際使用過程中,我們也沒有遇到叢集讀寫分離的需求,如果要進行讀寫分離,可以使用資源發現策略在 Slave 節點上架設 Twemproxy 叢集,由客戶端進行讀寫分離的路由。
快取
考慮到對於後端(MySQL/HBase/RPC 等)的壓力,知乎絕大部分業務都沒有針對快取進行降級,這種情況下對快取的可用性要求較資料的一致性要求更高,但是如果按照儲存的主從樣式實現高可用,1 個 Slave 節點的部署策略線上上環境只能容忍 1 臺物理節點宕機,N 臺物理節點宕機高可用就需要至少 N 個 Slave 節點,這無疑是種資源的浪費。
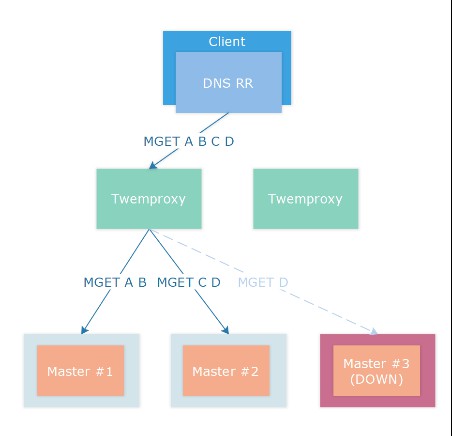
所以我們採用了Twemproxy 一致性雜湊(Consistent Hashing)策略來配合 auto_eject_hosts 自動彈出策略組建Redis 快取叢集。
對於快取我們仍然使用使用fnv1a_64 演演算法進行雜湊計算,但是分佈演演算法我們使用了ketama 即一致性雜湊進行Key 分佈。快取節點沒有主從,每個分片僅有 1 個 Master 節點承載流量。
Twemproxy 配置 auto_eject_hosts 會在實體連線失敗超過server_failure_limit 次的情況下剔除節點,併在server_retry_timeout 超時之後進行重試,剔除後配合ketama 一致性雜湊演演算法重新計算雜湊環,恢復正常使用,這樣即使一次宕機多個物理節點仍然能保持服務。
在實際的生產環境中需要註意以下幾點:
● 剔除節點後,會造成短時間的命中率下降,後端儲存如MySQL、HBase 等需要做好流量監測;
● 線上環境快取後端分片不宜過大,建議維持在20G 以內,同時分片排程應盡可能分散,這樣即使宕機一部分節點,對後端造成的額外的壓力也不會太多;
● 機器宕機重啟後,快取實體需要清空資料之後啟動,否則原有的快取資料和新建立的快取資料會衝突導致臟快取。直接不啟動快取也是一種方法,但是在分片宕機期間會導致週期性server_failure_limit 次數的連線失敗;
● server_retry_timeout 和server_failure_limit 需要仔細敲定確認,知乎使用10min 和 3 次作為配置,即連線失敗 3 次後剔除節點,10 分鐘後重新進行連線。
Twemproxy 部署
在方案早期我們使用數量固定的物理機部署Twemproxy,透過物理機上的 Agent 啟動實體,Agent 在執行期間會對 Twemproxy 進行健康檢查與故障恢復,由於 Twemproxy 僅提供全量的使用計數,所以 Agent 執行時還會進行定時的差值計算來計算 Twemproxy 的 requests_per_second 等指標。
後來為了更好地故障檢測和資源排程,我們引入了Kubernetes,將 Twemproxy 和 Agent 放入同一個 Pod 的兩個容器內,底層 Docker 網段的配置使每個 Pod 都能獲得獨立的 IP,方便管理。
最開始,本著簡單易用的原則,我們使用DNS A Record 來進行客戶端的資源發現,每個 Twemproxy 採用相同的埠號,一個 DNS A Record 後面掛接多個 IP 地址對應多個 Twemproxy 實體。
初期,這種方案簡單易用,但是到了後期流量日益上漲,單叢集Twemproxy 實體個數很快就超過了 20 個。由於 DNS 採用的 UDP 協議有 512 位元組的包大小限制,單個 A Record 只能掛接 20 個左右的 IP 地址,超過這個數字就會轉換為 TCP 協議,客戶端不做處理就會報錯,導致客戶端啟動失敗。
當時由於情況緊急,只能建立多個Twemproxy Group,提供多個 DNS A Record 給客戶端,客戶端進行輪詢或者隨機選擇,該方案可用,但是不夠優雅。
如何解決Twemproxy 單 CPU 計算能力的限制
之後我們修改了Twemproxy 原始碼, 加入 SO_REUSEPORT 支援。

Twemproxy with SO_REUSEPORT on Kubernetes
同一個容器內由Starter 啟動多個 Twemproxy 實體並系結到同一個埠,由作業系統進行負載均衡,對外仍然暴露一個埠,但是內部已經由系統均攤到了多個 Twemproxy 上。
同時Starter 會定時去每個 Twemproxy 的 stats 埠獲取 Twemproxy 執行狀態進行聚合,此外 Starter 還承載了訊號轉發的職責。
原有的Agent 不需要用來啟動 Twemproxy 實體,所以 Monitor 呼叫 Starter 獲取聚合後的 stats 資訊進行差值計算,最終對外界暴露出實時的執行狀態資訊。
為什麼沒有使用官方Redis 叢集方案
我們在2015 年調研過多種叢集方案,綜合評估多種方案後,最終選擇了看起來較為陳舊的 Twemproxy 而不是官方 Redis 叢集方案與 Codis,具體原因如下:
● MIGRATE 造成的阻塞問題
Redis 官方叢集方案使用 CRC16 演演算法計算雜湊值並將 Key 分散到 16384 個 Slot 中,由使用方自行分配 Slot 對應到每個分片中,擴容時由使用方自行選擇 Slot 並對其進行遍歷,對 Slot 中每一個 Key 執行 MIGRATE 命令進行遷移。
調研後發現,MIGRATE 命令實現分為三個階段:
1. DUMP 階段:由源實體遍歷對應 Key 的記憶體空間,將 Key 對應的 Redis Object 序列化,序列化協議跟 Redis RDB 過程一致;
2. RESTORE 階段:由源實體建立 TCP 連線到對端實體,並將 DUMP 出來的內容使用RESTORE 命令到對端進行重建,新版本的 Redis 會快取對端實體的連線;
3. DEL 階段(可選):如果發生遷移失敗,可能會造成同名的 Key 同時存在於兩個節點,
此時 MIGRATE 的REPLACE 引數決定是是否改寫對端的同名Key,如果改寫,對端的 Key 會進行一次刪除操作,4.0 版本之後刪除可以非同步進行,不會阻塞主行程。
經過調研,我們認為這種樣式並不適合知乎的生產環境。Redis 為了保證遷移的一致性, MIGRATE 所有操作都是同步操作,執行MIGRATE 時,兩端的Redis 均會進入時長不等的 BLOCK 狀態。
對於小Key,該時間可以忽略不計,但如果一旦 Key 的記憶體使用過大,一個 MIGRATE 命令輕則導致 P95 尖刺,重則直接觸發叢集內的 Failover,造成不必要的切換
同時,遷移過程中訪問到處於遷移中間狀態的Slot 的 Key 時,根據進度可能會產生 ASK 轉向,此時需要客戶端傳送 ASKING 命令到Slot 所在的另一個分片重新請求,請求時延則會變為原來的兩倍。
同樣,方案初期時的Codis 採用的是相同的 MIGRATE 方案,但是使用 Proxy 控制 Redis 進行遷移操作而非第三方指令碼(如 redis-trib.rb),基於同步的類似 MIGRATE 的命令,實際跟 Redis 官方叢集方案存在同樣的問題。
對於這種Huge Key 問題決定權完全在於業務方,有時業務需要不得不產生 Huge Key 時會十分尷尬,如關註串列。一旦業務使用不當出現超過 1MB 以上的大 Key 便會導致數十毫秒的延遲,遠高於平時 Redis 亞毫秒級的延遲。有時,在 slot 遷移過程中業務不慎同時寫入了多個巨大的 Key 到 slot 遷移的源節點和標的節點,除非寫指令碼刪除這些 Key ,否則遷移會進入進退兩難的地步。
對此,Redis 作者在 Redis 4.2 的 roadmap[5] 中提到了Non blocking MIGRATE 但是截至目前,Redis 5.0 即將正式釋出,仍未看到有關改動,社群中已經有相關的 Pull Request [6],該功能可能會在5.2 或者 6.0 之後併入 master 分支,對此我們將持續觀望。
● 快取樣式下高可用方案不夠靈活
還有,官方叢集方案的高可用策略僅有主從一種,高可用級別跟Slave 的數量成正相關,如果只有一個 Slave,則只能允許一臺物理機器宕機, Redis 4.2 roadmap 提到了 cache-only mode,提供類似於Twemproxy 的自動剔除後重分片策略,但是截至目前仍未實現。
● 內建Sentinel 造成額外流量負載
另外,官方Redis 叢集方案將 Sentinel 功能內建到 Redis 內,這導致在節點數較多(大於 100)時在 Gossip 階段會產生大量的 PING/INFO/CLUSTER INFO 流量,根據 issue 中提到的情況,200 個使用 3.2.8 版本節點搭建的 Redis 叢集,在沒有任何客戶端請求的情況下,每個節點仍然會產生 40Mb/s 的流量,雖然到後期 Redis 官方嘗試對其進行壓縮修複,但按照 Redis 叢集機制,節點較多的情況下無論如何都會產生這部分流量,對於使用大記憶體機器但是使用千兆網絡卡的使用者這是一個值得註意的地方。
● slot 儲存開銷
最後,每個Key 對應的 Slot 的儲存開銷,在規模較大的時候會佔用較多記憶體,4.x 版本以前甚至會達到實際使用記憶體的數倍,雖然 4.x 版本使用 rax 結構進行儲存,但是仍然佔據了大量記憶體,從非官方叢集方案遷移到官方叢集方案時,需要註意這部分多出來的記憶體。
總之,官方Redis 叢集方案與 Codis 方案對於絕大多數場景來說都是非常優秀的解決方案,但是我們仔細調研發現並不是很適合叢集數量較多且使用方式多樣化的我們,場景不同側重點也會不一樣,但在此仍然要感謝開發這些元件的開發者們,感謝你們對 Redis 社群的貢獻。
擴容
靜態擴容
對於單機實體,如果透過排程器觀察到對應的機器仍然有空閑的記憶體,我們僅需直接調整實體的maxmemory 配置與報警即可。同樣,對於叢集實體,我們透過排程器觀察每個節點所在的機器,如果所有節點所在機器均有空閑記憶體,我們會像擴容單機實體一樣直接更新maxmemory 與報警。
動態擴容
但是當機器空閑記憶體不夠,或單機實體與叢集的後端實體過大時,無法直接擴容,需要進行動態擴容:
● 對於單機實體,如果單實體超過30GB 且沒有如 sinterstore 之類的多Key 操作我們會將其擴容為叢集實體;
● 對於叢集實體,我們會進行橫向的重分片,我們稱之為Resharding 過程。

Resharding 過程
原生Twemproxy 叢集方案並不支援擴容,我們開發了資料遷移工具來進行 Twemproxy 的擴容,遷移工具本質上是一個上下游之間的代理,將資料從上游按照新的分片方式搬運到下游。
原生Redis 主從同步使用 SYNC/PSYNC 命令建立主從連線,收到SYNC 命令的Master 會 fork 出一個行程遍歷記憶體空間生成 RDB 檔案併傳送給 Slave,期間所有傳送至 Master 的寫命令在執行的同時都會被快取到記憶體的緩衝區內,當 RDB 傳送完成後,Master 會將緩衝區內的命令及之後的寫命令轉發給 Slave 節點。
我們開發的遷移代理會向上遊傳送SYNC 命令模擬上游實體的Slave,代理收到 RDB 後進行解析,由於 RDB 中每個 Key 的格式與 RESTORE 命令的格式相同,所以我們使用生成 RESTORE 命令按照下游的Key 重新計算雜湊並使用 Pipeline 批次傳送給下游。
等待RDB 轉發完成後,我們按照新的後端生成新的 Twemproxy 配置,並按照新的 Twemproxy 配置建立 Canary 實體,從上游的 Redis 後端中取 Key 進行測試,測試 Resharding 過程是否正確,測試過程中的 Key 按照大小,型別,TTL 進行比較。
測試透過後,對於叢集實體,我們使用生成好的配置替代原有Twemproxy 配置並 restart/reload Twemproxy 代理,我們修改了 Twemproxy 程式碼,加入了 config reload 功能,但是實際使用中發現直接重啟實體更加可控。而對於單機實體,由於單機實體和叢集實體對於命令的支援不同,通常需要和業務方確定後手動重啟切換。
由於Twemproxy 部署於 Kubernetes ,我們可以實現細粒度的灰度,如果客戶端接入了讀寫分離,我們可以先將讀流量接入新叢集,最終接入全部流量。
這樣相對於Redis 官方叢集方案,除在上游進行 BGSAVE 時的fork 複製頁表時造成的尖刺以及重啟時造成的連線閃斷,其餘對於 Redis 上游造成的影響微乎其微。
這樣擴容存在的問題:
-
對上游傳送SYNC 後,上游fork 時會造成尖刺;
-
對於儲存實體,我們使用Slave 進行資料同步,不會影響到接收請求的 Master 節點;
-
對於快取實體,由於沒有Slave 實體,該尖刺無法避免,如果對於尖刺過於敏感,我們可以跳過 RDB 階段,直接透過 PSYNC 使用最新的SET 訊息建立下游的快取。
-
切換過程中有可能寫到下游,而讀在上游;
-
對於接入了讀寫分離的客戶端,我們會先切換讀流量到下游實體,再切換寫流量。
-
一致性問題,兩條具有先後順序的寫同一個Key 命令在切換代理後端時會透過 1)寫上游同步到下游 2)直接寫到下游兩種方式寫到下游,此時,可能存在應先執行的命令卻透過 1)執行落後於透過 2)執行,導致命令先後順序倒置。
-
這個問題在切換過程中無法避免,好在絕大部分應用沒有這種問題,如果無法接受,只能透過上游停寫排空Resharding 代理保證先後順序;
-
官方Redis 叢集方案和 Codis 會透過 blocking 的 migrate 命令來保證一致性,不存在這種問題。
實際使用過程中,如果上游分片安排合理,可實現數千萬次每秒的遷移速度,1TB 的實體 Resharding 只需要半小時左右。另外,對於實際生產環境來說,提前做好預期規劃比遇到問題緊急擴容要快且安全得多。
旁路分析
由於生產環境除錯需要,有時會需要監控線上Redis 實體的訪問情況,Redis 提供了多種監控手段,如 MONITOR 命令。
但由於Redis 單執行緒的限制,導致自帶的 MONITOR 命令在負載過高的情況下會再次跑高 CPU,對於生產環境來說過於危險,而其餘方式如 Keyspace Notify 只有寫事件,沒有讀事件,無法做到細緻的觀察。
對此我們開發了基於libpcap 的旁路分析工具,系統層面複製流量,對應用層流量進行協議分析,實現旁路 MONITOR,實測對於執行中的實體影響微乎其微。
同時對於沒有MONITOR 命令的 Twemproxy,旁路分析工具仍能進行分析,由於生產環境中絕大部分業務都使用 Kubernetes 部署於 Docker 內 ,每個容器都有對應的獨立 IP,所以可以使用旁路分析工具反向解析找出客戶端所在的應用,分析業務方的使用樣式,防止不正常的使用。
將來的工作
由於Redis 5.0 釋出在即,4.0 版本趨於穩定,我們將逐步升級實體到 4.0 版本,由此帶來的如 MEMORY 命令、Redis Module 、新的 LFU 演演算法等特性無論對運維方還是業務方都有極大的幫助。
最後
知乎架構平臺團隊是支撐整個知乎業務的基礎技術團隊,開發和維護著知乎幾乎全量的核心基礎元件,包括容器、Redis、MySQL、Kafka、LB、HBase 等核心基礎設施,團隊小而精,每個同學都獨當一面負責上面提到的某個核心系統。
隨著知乎業務規模的快速增長,以及業務複雜度的持續增加,我們團隊面臨的技術挑戰也越來越大,歡迎對技術感興趣、渴望技術挑戰的小夥伴加入我們,一起建設穩定高效的知乎雲平臺。有意向可移步知乎網站招聘頁投遞簡歷。
參考資料
1. Redis Official site https://redis.io/
2. Twemproxy Github Page twitter/twemproxy
3. Codis Github Page CodisLabs/codis
4. SO_REUSEPORT Man Page socket(7) – Linux manual page
5. Kubernetes Production-Grade Container Orchestration
相關閱讀:

高可用架構
改變網際網路的構建方式

長按二維碼 關註「高可用架構」公眾號
