點選上方藍字關註“汪宇傑部落格”

識別一段文字的語言有多種途徑,在這個以AI為熱點的時代,我們也可以給自己的應用強行加上AI,然後就能加上“智慧”的名字“自主研發成功”後去吹牛逼。今天我帶大家來看看如何使用微軟智慧雲Azure提供的AI認知服務來識別一段文字的語言。
本文的前提條件是你得有一個Azure國際版的訂閱,免費試用的也行。

新建Azure認知服務賬戶
點選”Create a resouce“,然後搜尋”Translator“,選擇”Translator Text“,這是Azure認知服務的其中一種應用,主要用途是做翻譯,但我們也能用來識別文字的語言。

在Name中指定一個名稱,可以任意,不影響程式開發。選擇一個Pricing tier,這裡我選的F0是免費的。Resource group也可以任意指定,不會影響程式開發。
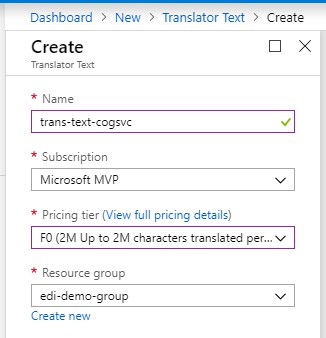
建立完成後,到Keys中複製一個Key,Key1和Key2都可以使用,作用是完全一樣的,沒有什麼講究。

.NET Core 呼叫認知服務
Azure認知服務提供了REST介面,所以我們在.NET Core裡可以像使用任何REST API一樣,構造請求,並解析傳回的JSON字串。
TextLanguageDetector
新建一個名為TextLanguageDetector的類。用來封裝呼叫Azure認知服務的操作。定義屬性Host、Route、SubscriptionKey。其中SubscriptionKey就是之前從Azure Portal裡複製的那個Key。這個需要讓呼叫者根據自己的Azure賬戶自由調整,所以留在建構式引數裡。Host和Route是固定的,因此可以寫死在程式裡。
public class TextLanguageDetector
{
public string Host { get; } = “https://api.cognitive.microsofttranslator.com”;
public string Route { get; } = “/detect?api-version=3.0”;
public string SubscriptionKey { get; }
public TextLanguageDetector(string subscriptionKey)
{
SubscriptionKey = subscriptionKey;
}
public async Task DetectAsync(string text)
{
// …
}
}
DetectAsync方法接受的是需要識別的文字,傳回的DetectResult型別也是我們自己定義的,它的定義稍後再看。我們先看看該方法的具體實現:
if (string.IsNullOrWhiteSpace(text))
{
throw new ArgumentNullException(nameof(text));
}
object[] body = { new { Text = text } };
var requestBody = JsonConvert.SerializeObject(body);
using (var client = new HttpClient())
using (var request = new HttpRequestMessage())
{
request.Method = HttpMethod.Post;
request.RequestUri = new Uri(Host + Route);
request.Content = new StringContent(requestBody, Encoding.UTF8, “application/json”);
request.Headers.Add(“Ocp-Apim-Subscription-Key”, SubscriptionKey);
var response = await client.SendAsync(request);
var jsonResponse = await response.Content.ReadAsStringAsync();
return new DetectResult(jsonResponse);
}
非常簡明直接。使用POST動作向認知服務的終端地址提交一個構造的Body,內容Text為方法的輸入引數,即要識別的文字。API的認證方式使用SubscriptionKey。最終拿到的jsonResponse是識別結果,轉為DetectResult型別。
假設識別的是簡體中文,並且沒有發生異常,那麼Azure認知服務的傳回Json會是這樣:
[
{
“language”: “zh-Hans”,
“score”: 1.0,
“isTranslationSupported”: true,
“isTransliterationSupported”: true,
“alternatives”: [
{
“language”: “ja”,
“score”: 1.0,
“isTranslationSupported”: true,
“isTransliterationSupported”: true
}
]
}
]
language是語言程式碼,zh-Hans就是簡體中文。score表示AI認為有多大的可能性是該語言,1.0就是非常確信。對於文字“予力地球上每一人、每一組織,成就不凡”的識別結果,出現了兩種確信的語言:簡體中文和日語。但日語是alternatives的,所以AI基本斷定,該語言為簡體中文。具體的語言程式碼和語言名稱對應關係可以從這裡找到:
var cultures = CultureInfo.GetCultures(CultureTypes.AllCultures);

構造DetectResult
為了讓我們程式對呼叫者更加友好,我們不會只傳回Json。我根據Azure認知服務可能傳回的兩種情況:成功、失敗,構造了DetectResult型別:
public class DetectResult
{
public string RawJson { get; set; }
public bool IsSuccess => !RawJson.Contains(“\”error\””);
public string ErrorMessage
{
get
{
var obj = JsonConvert.DeserializeObject(RawJson);
return obj.error.message.ToString();
}
}
public DetectResult(string rawJson)
{
RawJson = rawJson;
}
public List ToCogResults()
{
return IsSuccess ? JsonConvert.DeserializeObject>(RawJson) : null;
}
}
RawJson用來存放認知服務傳回的Json本身,可以讓呼叫者去做一些更加高階的自定義解析。IsSuccess表示呼叫是否有成功,如果不成功的話使用者可以檢查ErrorMessage獲得具體錯誤訊息。成功的話可以呼叫ToCogResults()方法把結果解析到TextCogResult型別裡去。這個方法傳回的是一個List,因為輸入的文字不一定只有一種語言。
public class TextCogResult
{
public string Language { get; set; }
public float Score { get; set; }
//public bool IsTranslationSupported { get; set; }
//public bool IsTransliterationSupported { get; set; }
public Alternative[] Alternatives { get; set; }
}
public class Alternative
{
public string Language { get; set; }
public float Score { get; set; }
//public bool IsTranslationSupported { get; set; }
//public bool IsTransliterationSupported { get; set; }
}
以上的所有程式碼都可以封裝到一個.NET Standard類庫裡,這樣就可以跨.NET Framework, .NET Core或者Xamarin使用了。
為了方便大家,我已經釋出了可以直接使用的NuGet包
https://www.nuget.org/packages/AzureAILanguageDetector
應用程式
以.NET Core控制檯應用為例,呼叫TextLanguageDetector並輸出語言的本地名稱和英語名稱:
var texts = new[]
{
“Empower every person and every organization on the planet to achieve more”,
“予力地球上每一人、每一組織,成就不凡”
};
var dt = new TextLanguageDetector(“你的Key”);
foreach (var text in texts)
{
var result = dt.DetectAsync(text).Result;
if (result.IsSuccess)
{
var r = result.ToCogResults();
var cultures = CultureInfo.GetCultures(CultureTypes.AllCultures);
var ctr = cultures.FirstOrDefault(c => c.Name == r.First().Language);
if (ctr != null) Console.WriteLine($”{ctr.EnglishName} – {ctr.NativeName}”);
}
else
{
Console.WriteLine(result.ErrorMessage);
}
}
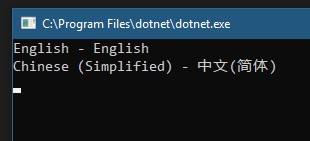
本文示例程式碼:https://github.com/EdiWang/DotNet-Samples/tree/master/CogSvcLngDetect
參考資料:https://docs.microsoft.com/en-us/azure/cognitive-services/translator/quickstart-csharp-detect
