作者:Faizan Shaikh ;翻譯:季洋;校對:王雨桐;
本文約2700字,建議閱讀10+分鐘。
本文將展示如何使用開源工具完成一個人臉識別的演演算法。
引言
“計算機視覺和機器學習已經開始騰飛,但是大多數人並不清楚計算機在識別一張圖片的時候,它到底看到了什麼。”
——麥克.克裡奇
計算機視覺這個精彩領域在最近幾年突飛猛進,目前已經具備了一定的規模。大量的應用已經在全世界被廣泛使用 —— 而這也僅僅是個開始!
在這個領域中,我最贊賞的一件事就是對開源的接納。即使是那些技術大佬們也樂於與大家分享新的突破和創新,從而使這些技術不再“曲高和寡”。
其中一項技術就是人臉識別,它可以解決很多現實問題(如果被正確又合乎倫理地使用)。本文將展示如何使用開源工具完成一個人臉識別的演演算法。以下是的一個有趣的演示,這也為接下來的內容做好鋪墊:

所以,你準備好了嗎?精彩才剛剛開始!
提示:如果你想要瞭解計算機視覺的複雜性, 下麵這個深度學習的計算機視覺是很好的起步課程。
Computer Vision using Deep Learning
https://trainings.analyticsvidhya.com/courses/course-v1:AnalyticsVidhya+CVDL101+CVDL101_T1 /about
內容
-
人臉識別中有前景的應用
-
系統準備—— 硬體/軟體要求
-
-
硬體安裝
-
軟體安裝
-
-
探究Python的實現
-
-
簡單演練
-
人臉識別案例
-
人臉識別中有前景的應用
我找到了一些經典的人臉識別技術應用案例。你一定碰到過類似的例子,但並沒有意識到這些場景背後到底使用了什麼技術!
例如,對於每一張上傳到平臺的影象,Facebook都用自動生成的標簽建議替代手動給影象加標簽。Facebook使用了一個簡單的人臉識別演演算法來分析影象中人臉的畫素,同時將它和相關使用者做比較。我們將學習如何建立一個人臉識別模型,但是在我們描述相關的技術細節之前,先來探討一些其它的應用案例。
我們現在常常用最新的“人臉解鎖”功能來解鎖手機。這是一個很小的人臉識別技術案例,以幫助維護個人資料安全。同樣的想法可以應用於更大範圍,使相機能夠在抓取影象的同時識別人臉。

人臉識別技術還應用於廣告、醫療、銀行等行業中,只是不太被人所知。在大多數公司,甚至在很多會議中,進入時都需要佩戴身份識別卡。但是我們能否找到一種無需佩戴任何身份識別卡就能進出的方法呢?人臉識別非常有助於這個想法的實現。人們只需要看著鏡頭,系統就會自動判斷他是否具備許可權。
另一個有趣的人臉識別應用是計算參與活動(如會議或音樂會)的人數。這並不是手動計算參加者的數量,我們可以安裝一個攝像機,它能夠捕捉參加者影像並計算人員總數。如此可以使得過程自動化,同時也能節省大量人力。這個技術非常實用,不是嗎?

你可以想出更多類似的應用 ——在下麵的留言中和我們分享吧!
本文將側重於人臉識別的實踐應用,對演演算法如何運作只作註釋。如果你想瞭解更多,可以瀏覽下麵這篇文章:
Understanding and Building an Object Detection Model from Scratch in Python
https://www.analyticsvidhya.com/blog/2018/06/understanding-building-object-detection-model-python/
系統準備 —— 硬體/軟體要求
現在你知道了人臉識別技術可以實現的應用,讓我們看看如何能夠透過可用的開源工具來實現它。這就能體現領域的優勢了 —— 分享開原始碼的意願和行動都是其他領域無法比擬的。
針對本文,以下列出了我使用的和推薦使用的系統配置如下:
-
一個網路攝像頭(羅技 Logitech C920)用來搭建一個實時人臉識別器,並將其安裝在聯想E470 ThinkPad系列筆記本(英特爾酷睿5第7代核心Core i5 7th Gen)。你也可以使用膝上型電腦自帶的攝像頭,或電視監控系統攝像頭。在任意系統上做實時的影片分析都可以,並不一定是我正在使用的配置。
-
使用圖形處理器(GPU)來加速影片處理會更好。
-
在軟體方面,我們使用Ubuntu 18.04作業系統安裝所有必要的軟體。
為了確保搭建模型前的每件事都安排妥當,接下來我們將詳細探討如何配置。
步驟一:硬體安裝
首要的事就是檢查網路攝像頭是否正確安裝。在Ubuntu上有一個簡單小技巧 —— 看一下相應的裝置在作業系統中是否已經被註冊。你可以照著以下的步驟來做:
步驟1.1:在連線網路攝像頭到膝上型電腦之前,透過在命令提示符視窗輸入命令ls /dev/video* 來檢查所有連線上的影片裝置。這將列出那些已經連線入系統的影片裝置。

步驟1.2:連線網路攝像頭並再次執行這一命令。

如果網路攝像頭被成功連線,將顯示一個新的裝置。
步驟1.3:另一件你可以做的事是使用任一網路攝像頭軟體來檢查攝像頭能否正常工作,Ubuntu中你可以用“Cheese”來檢查。
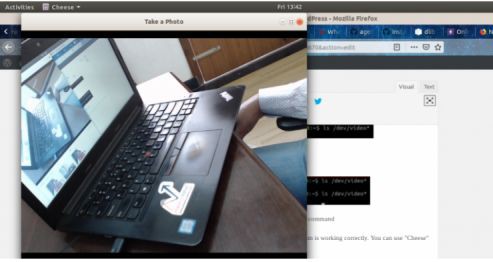
這裡我們可以看出網路攝像頭已經安裝成功啦!硬體部分完成!
步驟二:軟體安裝
步驟2.1:安裝Python
本文中的程式碼是用Python 3.5編寫。儘管有多種方法來安裝Python,我還是建議使用Anaconda —— 資料科學中最受歡迎的Python發行版。
Anaconda下載連結:
https://www.anaconda.com/download/
步驟2.2:安裝OpenCV
OpenCV(Open Source Computer Vision) 是一個旨在建立計算機視覺應用的軟體庫。它包含大量預先寫好的影象處理功能。要安裝OpenCV,需要一個該軟體庫的pip安裝:
pip3 install opencv-python
步驟2.3:安裝face_recognition應用程式介面
最後,我們將會使用face_recognition,它號稱是世界上最簡單的人臉識別應用程式Python介面。安裝如下:
pip install dlib pip install face_recognition
讓我們開始探索它的實現吧。
既然你已經配置好了系統,是時候探究真正的使用了。首先,我們將快速地建立程式,然後分段來解釋我們做了什麼。
簡單流程
首先,建立一個face_detector.py檔案同時複製下麵的程式碼:
# import librariesimport cv2import face_recognition# Get a reference to webcam video_capture = cv2.VideoCapture(“/dev/video1”)# Initialize variablesface_locations = []while True: # Grab a single frame of video ret, frame = video_capture.read() # Convert the image from BGR color (which OpenCV uses) to RGB color (which face_recognition uses) rgb_frame = frame[:, :, ::-1] # Find all the faces in the current frame of video face_locations = face_recognition.face_locations(rgb_frame) # Display the results for top, right, bottom, left in face_locations: # Draw a box around the face cv2.rectangle(frame, (left, top), (right, bottom), (0, 0, 255), 2) # Display the resulting image cv2.imshow(‘Video’, frame) # Hit ‘q’ on the keyboard to quit! if cv2.waitKey(1) & 0xFF == ord(‘q’): break# Release handle to the webcamvideo_capture.release()cv2.destroyAllWindows()
然後,用如下命令執行這個Python檔案:
python face_detector.py
如果一切執行正確,會彈出一個新視窗,以執行實時的人臉識別。

總結一下,以上的程式碼做了這些:
-
首先,我們配置了執行影像分析的硬體。
-
接下來我們逐幀地捕捉實時影像。
-
然後我們處理每一幀並且提取影象中所有人臉的位置。
-
最後,我們以影片形式描繪出這些幀,同時標註人臉的位置。
這很簡單,不是嗎? 如果你想深入瞭解更多細節,我已經對各程式碼段做了詳盡註解。你可以隨時回顧我們做了什麼。
人臉識別案例
有趣的事情並沒有結束!我們還能做一件很酷的事情 —— 結合以上程式碼實現一個完整的案例。並且不需要從零開始,我們僅僅需要對程式碼做一些小的改動。
例如,你想搭建一個自動的攝像頭定位系統,來實時跟蹤演講者的位置。根據他的位置,系統會轉動攝像頭使得演講者總是處於影片的中間。
我們怎麼做到這一點?第一步就是要搭建一個可辨識影片中人(們)的系統,並且重點放在演講者的位置。

讓我們來看一下如何才能實現這個案例。本文將以一個Youtube上的影片為例,影片記錄了一個演講者在2017年資料駭客峰會(DataHack Summit 2017)上的演講。
首先,我們引入必要的程式碼庫:
import cv2 import face_recognition
然後,讀入影片並得到影片長度:
input_movie = cv2.VideoCapture(“sample_video.mp4”) length = int(input_movie.get(cv2.CAP_PROP_FRAME_COUNT))
隨後我們新建一個輸出檔案,使其擁有和輸入檔案相似的解析度和幀頻。
載入演講者的一個影像樣本,來識別影片中的主角:
image = face_recognition.load_image_file(“sample_image.jpeg”) face_encoding = face_recognition.face_encodings(image)[0] known_faces = [ face_encoding, ]
做完這些,現在我們可以執行一個迴圈來完成如下步驟:
-
從影片中提取一幀影像
-
找到所有的人臉並完成識別
-
新建一個影片,來將源幀影象和標註演講者臉部的位置合併起來
讓我們看看這部分程式碼:
# Initialize variablesface_locations = []face_encodings = []face_names = []frame_number = 0while True: # Grab a single frame of video ret, frame = input_movie.read() frame_number += 1 # Quit when the input video file ends if not ret: break # Convert the image from BGR color (which OpenCV uses) to RGB color (which face_recognition uses) rgb_frame = frame[:, :, ::-1] # Find all the faces and face encodings in the current frame of video face_locations = face_recognition.face_locations(rgb_frame, model=”cnn”) face_encodings = face_recognition.face_encodings(rgb_frame, face_locations) face_names = [] for face_encoding in face_encodings: # See if the face is a match for the known face(s) match = face_recognition.compare_faces(known_faces, face_encoding, tolerance=0.50) name = None if match[0]: name = “Phani Srikant” face_names.append(name) # Label the results for (top, right, bottom, left), name in zip(face_locations, face_names): if not name: continue # Draw a box around the face cv2.rectangle(frame, (left, top), (right, bottom), (0, 0, 255), 2) # Draw a label with a name below the face cv2.rectangle(frame, (left, bottom – 25), (right, bottom), (0, 0, 255), cv2.FILLED) font = cv2.FONT_HERSHEY_DUPLEX cv2.putText(frame, name, (left + 6, bottom – 6), font, 0.5, (255, 255, 255), 1) # Write the resulting image to the output video file print(“Writing frame {} / {}”.format(frame_number, length)) output_movie.write(frame)# All done!input_movie.release()cv2.destroyAllWindows()
這段程式碼將輸出如下類似的結果:
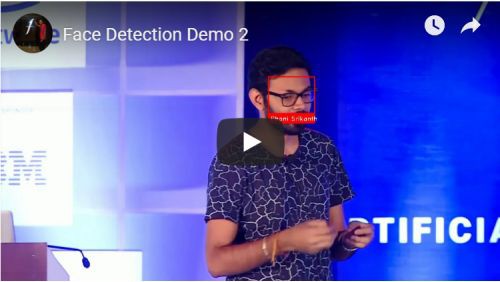
人臉識別真的是一件了不起的事情!
總結
恭喜!你現在已經掌握瞭如何為一些現實場景搭建人臉識別系統。深度學習是一個如此令人著迷的領域,而我非常期待看到它未來的發展。
在這篇文章中,我們學習瞭如何在真實情境中運用開源工具來構建實時人臉識別系統。我希望你能創造更多類似的應用,並且自己嘗試更多的案例。相信我,還有很多東西要學習,而他們真的很趣!
一如既往,如果你有任何問題或建議儘管在下麵的留言部分提出來吧!
原文標題:
Building a Face Detection Model from Video using Deep Learning (Python Implementation)
原文連結:
https://www.analyticsvidhya.com/blog/2018/12/introduction-face-detection-video-deep-learning-python/
譯者簡介:季洋,蘇州某IT公司技術總監,從業20年,現在主要負責Java專案的方案和管理工作。對大資料、資料挖掘和分析專案躍躍欲試卻苦於沒有機會和資料。目前正在摸索和學習中,也報了一些線上課程,希望對資料建模的應用場景有進一步的瞭解。不能成為巨人,只希望可以站在巨人的肩膀上瞭解資料科學這個有趣的世界。

