作者簡介:呂夏飛,西安郵電大學2018級陳莉君教授研究生,技術宅一枚,喜歡折騰各種新技術,江湖人稱C小子。
01
平均負載與CPU使用率
現實工作中,我們經常容易把平均負載和 CPU 使用率混淆,所以在這裡,進行一個區分。
可能你也會有這樣的疑惑,既然平均負載代表的是活躍行程數,那平均負載高了,是不是也就意味著 CPU 使用率高?
我們來看看平均負載的含義,平均負載是指單位時間內,處於可執行狀態和不可中斷狀態的行程數。所以,它不僅包括了正在使用 CPU 的行程,還包括等待 CPU 和等待 I/O 的行程。
而 CPU 使用率,是單位時間內 CPU 繁忙情況的統計,跟平均負載並不一定完全對應。比如:
• CPU 密集型行程,使用大量 CPU 會導致平均負載升高,此時這兩者是一致的;
• I/O 密集型行程,等待 I/O 也會導致平均負載升高,但 CPU 使用率不一定很高;
大量等待 CPU 的行程排程也會導致平均負載升高,此時的 CPU 使用率也會比較高。
02
平均負載案例分析
下麵,我們以三個示例分別來看這三種情況,並用 iostat、mpstat、pidstat 等工具,找出平均負載升高的根源。
實驗準備
下麵的案例都是基於 Ubuntu 18.04,案例環境如下所示。
• 機器配置:2 CPU,2GB 記憶體。
• 預先安裝 stress 和 sysstat 包,如 apt install stress sysstat。
首先介紹一下 stress 和 sysstat。
stress 是一個 Linux 系統壓力測試工具,這裡用作異常行程模擬平均負載升高的場景。而 sysstat 包含了常用的 Linux 效能工具,用來監控和分析系統的效能。我們的案例會用到這個包的兩個命令 mpstat 和 pidstat。
• mpstat 是一個常用的多核 CPU 效能分析工具,用來實時檢視每個 CPU 的效能指標,以及所有 CPU 的平均指標。
•pidstat 是一個常用的行程效能分析工具,用來實時檢視行程的 CPU、記憶體、I/O 以及背景關係切換等效能指標。
此外,每個場景都需要開三個終端,登入到同一臺 Linux 機器中。
註意,下麵的所有命令,預設以普通使用者執行。所以,如果遇到許可權不夠時,一定要執行 sudo su root 命令切換到 root 使用者。
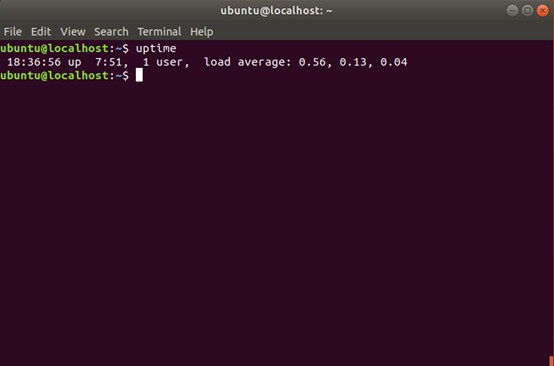
如果上面的環境準備都已經完成了,先用 uptime 命令,看一下測試前的平均負載情況:
場景一:CPU 密集型行程
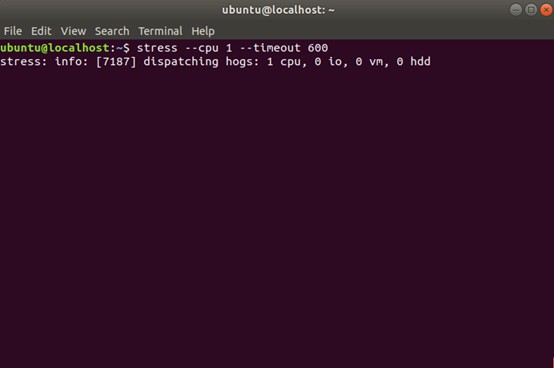
首先,在第一個終端執行 stress 命令,模擬一個 CPU 使用率 100% 的場景:
接著,在第二個終端執行 uptime 檢視平均負載的變化情況:
# -d 引數表示高亮顯示變化的區域
$ watch -d uptime

最後,在第三個終端執行 mpstat 檢視 CPU 使用率的變化情況:
# -P ALL 表示監控所有 CPU,後面數字 5 表示間隔 5 秒後輸出一組資料
$ mpstat -P ALL 5
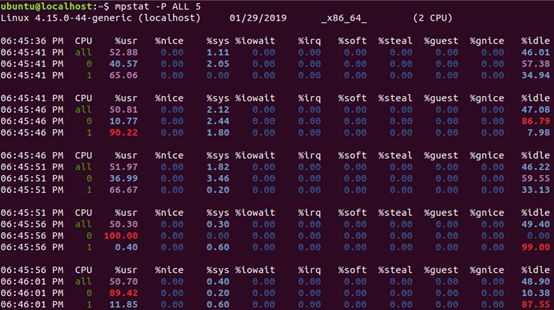
終端二中可以看到,1 分鐘的平均負載會慢慢增加到 1.00,而從終端三中還可以看到,正好有一個 CPU 的使用率為 100%,但它的 iowait 只有 0。這說明,平均負載的升高正是由於 CPU 使用率為 100% 。
那麼,到底是哪個行程導致了 CPU 使用率為 100% 呢?你可以使用 pidstat 來查詢:
# 間隔 5 秒後輸出一組資料
$ pidstat -u 5 1

從這裡可以明顯看到,stress 行程的 CPU 使用率為 99.60%,接近100%。
場景二:I/O 密集型行程
首先還是執行 stress 命令,但這次模擬 I/O 壓力,即不停地執行 sync:
$ stress -i 1 --timeout 600

註意:
在虛擬機器中$ stress -i 1 –timeout 600無法升高,與理論不符?
iowait無法升高的問題,是因為物理機中stress使用的是 sync() 系統呼叫,它的作用是掃清緩衝區記憶體到磁碟中。對於虛擬機器,緩衝區可能比較小,無法產生大的IO壓力,這樣大部分就都是系統呼叫的消耗了。所以,只會看到只有系統CPU使用率升高。解決方法是使用stress的下一代stress-ng,它支援更豐富的選項,比如 stress-ng -i 1 –hdd 1 –timeout 600(–hdd表示讀寫臨時檔案)。
stress-ng -i 1 --hdd 1 --timeout 600

在第二個終端執行 uptime 檢視平均負載的變化情況:
$ watch -d uptime

然後,第三個終端執行 mpstat 檢視 CPU 使用率的變化情況:
# 顯示所有 CPU 的指標,併在間隔 5 秒輸出一組資料
$ mpstat -P ALL 5 1

從這裡可以看到,1 分鐘的平均負載會慢慢增加到 0.95,接近1,其中一個 CPU 的系統 CPU 使用率升高到了 6.16,而 iowait 高達 87.44%。這說明,平均負載的升高是由於 iowait 的升高。
那麼到底是哪個行程,導致 iowait 這麼高呢?使用 pidstat 來查詢:
# 間隔 5 秒後輸出一組資料,-u 表示 CPU 指標
$ pidstat -u 5 1

可以發現,還是 stress 行程導致的。
場景三:大量行程的場景
當系統中執行行程超出 CPU 執行能力時,就會出現等待 CPU 的行程。
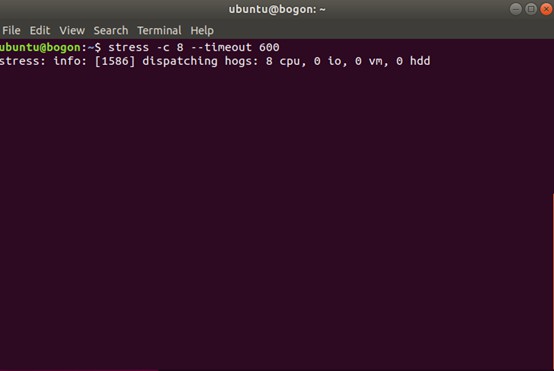
比如,我們還是使用 stress,但這次模擬的是 8 個行程:
$ stress -c 8 --timeout 600
由於系統只有 2 個 CPU,明顯比 8 個行程要少得多,因而,系統的 CPU 處於嚴重過載狀態,平均負載高達 7.76:
$ uptime
或者
$ watch -d uptime

接著再執行 pidstat 來看一下行程的情況:
# 間隔 5 秒後輸出一組資料
$ pidstat -u 5 1

可以看出,8 個行程在爭搶 2 個 CPU,每個行程等待 CPU 的時間(也就是程式碼塊中的 %wait 列)高達 76%左右。這些超出 CPU 計算能力的行程,最終導致 CPU 過載。
03
案例小結
分析完這三個案例,歸納一下平均負載的理解。
平均負載提供了一個快速檢視系統整體效能的手段,反映了整體的負載情況。但只看平均負載本身,並不能直接發現,到底是哪裡出現了瓶頸。所以,在理解平均負載時,需要註意:
• 平均負載高有可能是 CPU 密集型行程導致的;
• 平均負載高並不一定代表 CPU 使用率高,還有可能是 I/O 更繁忙了;
• 當發現負載高的時候,你可以使用 mpstat、pidstat 等工具,輔助分析負載的來源。
04
文章總結
什麼是平均負載
• 正確定義:單位時間內,系統中處於可執行狀態和不可中斷狀態的平均行程數。
• 錯誤定義:單位時間內的cpu使用率。
• 可執行狀態的行程:正在使用cpu或者正在等待cpu的行程,即ps aux命令下STAT處於R狀態的行程
• 不可中斷狀態的行程:處於核心態關鍵流程中的行程,且不可被打斷,如等待硬體裝置IO響應,ps命令D狀態的行程
• 理想狀態:每個cpu上都有一個活躍行程,即平均負載數等於cpu數
• 過載經驗值:平均負載高於cpu數量70%的時候
相關命令
• cpu核數: lscpu、 grep ‘model name’ /proc/cpuinfo | wc -l
• 顯示平均負載:uptime、top,顯示的順序是最近1分鐘、5分鐘、15分鐘,從此可以看出平均負載的趨勢
• watch -d uptime: -d會高亮顯示變化的區域
• strees: 壓測命令,–cpu cpu壓測選項,-i io壓測選項,-c 行程數壓測選項,–timeout 執行時間
• mpstat: 多核cpu效能分析工具,-P ALL監視所有cpu
• pidstat: 行程效能分析工具,-u 顯示cpu利用率
平均負載與cpu使用率的區別
CPU使用率:單位時間內cpu繁忙情況的統計
• 情況1:CPU密集型行程,CPU使用率和平均負載基本一致
• 情況2:IO密集型行程,平均負載升高,CPU使用率不一定升高
• 情況3:大量等待CPU的行程排程,平均負載升高,CPU使用率也升高
平均負載過高時調優
工具:stress、sysstat
CPU密集型行程case
• mpstat -P ALL 5:-P ALL表示監控所有CPU,5表示每5秒掃清一次資料,觀察是否有某個cpu的%usr會很高,但iowait應很低
• pidstat -u 5 1:每5秒輸出一組資料,觀察哪個行程%cpu很高,但是%wait很低,極有可能就是這個行程導致cpu飈高
IO密集型行程case
• mpstat -P ALL 5:觀察是否有某個cpu的%iowait很高,同時%usr也較高
• pidstat -u 5 1:觀察哪個行程%wait較高,同時%CPU也較高
大量行程case
• pidstat -u 5 1:觀察那些%wait較高的行程是否有很多
—— E N D ——

