在eBay,我們運轉著多個由幾千個節點構成的Hadoop叢集,提供給成千上萬的人使用。在這些Hadoop叢集中我們儲存了幾千PB的資料。我們在本文探討瞭如何基於資料使用頻率來最佳化大資料儲存。實驗表明該方法有效降低了經濟成本。
Hadoop 及其承諾
眾所周知,商用硬體可以組裝起來建立擁有大資料儲存和計算能力的Hadoop叢集。將資料拆分成多個部分,分別儲存在每個單獨的機器上,資料處理邏輯也在同樣的機器上執行。

例如:一個1000個節點組成的Hadoop叢集,單節點容量有20TB,最多可以儲存20PB的資料。因此,所有的這些機器擁有足夠的計算能力來履行Hadoop的口號:“take compute to data”。
資料的溫度
叢集中通常儲存著各種不同型別的資料集,不同的團隊透過該叢集可以共享地處理他們不同型別的工作任務。透過資料管道,每個資料集每時每刻都會得到增長。
資料集有一個共同特點就是初始的使用量會很大。在此期間,資料集被認為是“熱(HOT)”的。我們透過分析發現,隨著時間的推移,使用率會有一定程度的下降,儲存的資料每週僅僅就被訪問幾次,逐漸就變為“溫(WARM)”資料。在此後90天中,當資料使用率跌至一個月幾次時,它就被定義為“冷(COLD)”資料。
因此資料在最初幾天被認為是“熱”的,此後第一個月仍然保持為“溫”的。在這期間,任務或應用會使用幾次該資料。隨著資料的使用率下降得更多,它就變“冷”了,在此後90天內或許只被使用寥寥幾次。最終,當資料一年只有一兩次使用頻率、極少用到時,它的“溫度”就是“冰凍”的了。
| Data Age | Usage Frequency | Temperature |
| Age < 7 days | 20 times a day | HOT |
| 7 days > Age < 1 month | 5 times a week | WARM |
| 1 month < Age < 3 months | 5 times a month | COLD |
| 3 months < Age < 3 years | 2 times a year | FROZEN |
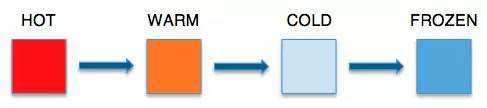
一般來講,溫度與每個資料集都緊密相關。在這個例子中,溫度是與資料的年齡成反比的。一個特定資料集的溫度也受其他因素影響的。你也可以透過演演算法決定資料集的溫度。
HDFS的分層儲存
HDFS從Hadoop2.3開始支援分層儲存
它是如何工作的呢?
正常情況下,一臺機器新增到叢集後,將會有指定的本地檔案系統目錄來儲存這塊副本。用來指定本地儲存目錄的引數是dfs.datanode.dir。另一層中,比如歸檔(ARCHIVE)層,可以使用名為StorageType的列舉來新增。為了表明這個本地目錄屬於歸檔層,該本地目錄配置中會帶有[ARCHIVE]的字首。理論上,hadoop叢集管理員可以定義多個層級。
比如說:如果在一個已有1000個節點,其總儲存容量為20PB的叢集上,增加100個節點,其中每個節點有200TB的儲存容量。相比已有的1000個節點,這些新增節點的計算能力就相對較差。接下來,我們在所有本地目錄的配置中增加ARCHIVE的字首。那麼現在位於歸檔層的這100個節點將會有20PB的儲存量。最後整個叢集被劃分為兩層——磁碟(DISK)層和歸檔(ARCHIVE)層,每一層有20PB的容量,總容量為40PB。

基於溫度將資料對映到儲存層
在這個例子中,我們將在擁有更強計算能力節點的DISK層儲存高頻率使用的“熱(HOT)”資料。
至於“溫(WARM)”資料,我們將其大部分的副本儲存在磁碟層。對於複製因子(replication factor)為3的資料,我們將在磁碟層儲存其兩個副本,在歸檔層儲存一個副本。
如果資料已經變“冷(COLD)”,那麼我們至少將在磁碟層儲存其每個塊的一個副本。餘下的副本都放入歸檔層。
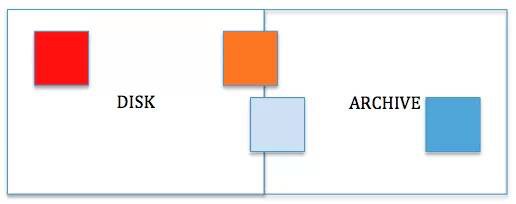
當一個資料集為認為是“冰凍(FROZEN)”的,這就意味著它幾乎已經不被使用,將其儲存在具有大量CPU、能執行眾多工節點或容器的節點上是不明智的。我們會把它儲存到一個具有最小計算能力的節點上。因此,所有處於“冰凍(FROZEN)”狀態塊的全部副本都可以被移動到歸檔層。
跨層的資料流
當資料第一次新增到叢集中,它將被儲存到預設的磁碟層。基於資料的溫度,它的一個或多個副本將被移動到歸檔層。移動器就是用來把資料從一個層移動到另一層的。移動器的工作原理類似平衡器,除了它可以跨層地移動塊的副本。移動器可接受一條HDFS路徑,一個副本數目和目的地層資訊。然後它將基於所述層的資訊識別將要被移動的副本,並排程資料在源資料節點到目的資料節點的移動。
Hadoop 2.6中支援分層儲存的變化
Hadoop 2.6中有許多的改進使其能夠進一步支援分層儲存。你可以附加一個儲存策略到某個目錄來指明它是“熱(HOT)”的,“溫(WARM)”的,“冷(COLD)”的, 還是“冰凍(FROZEN)”的。儲存策略定義了每一層可儲存的副本數量。我可以改變目錄的儲存策略並啟動該目錄的移動器來使得策略生效。
使用資料的應用
基於資料的溫度,資料的部分或者全部副本可能儲存在任一層中。但對於透過HDFS來使用資料的應用而言,其位置是透明的。
雖然“冰凍”資料的所有副本都在歸檔層,應用依然可以像訪問HDFS的任何資料一樣來訪問它。由於歸檔層中的節點並沒有計算能力,執行在磁碟層的對映(map)任務將從歸檔層的節點上讀取資料,但這會導致增加應用的網路流量消耗。如果這種情況頻繁地發生,你可以指定該資料為“溫/冷”,並讓移動器移回一個或多個副本到磁碟層。
確定資料溫度以及完成指定的副本移動至預先定義的分層儲存可以全部自動化。
eBay的分層儲存
eBay在其中一個具有非常大規模的叢集上使用了分層儲存。該叢集擁有40PB的資料。我們又額外增加了10PB計算能力受限的儲存容量。每一個新的機器都可以儲存220TB。我們把增加的儲存標記為歸檔層,並把一些目錄標識為“溫”、“冷”或者“冰凍”。然後根據它們的溫度,移動所有或部分的副本到歸檔層。
每GB歸檔層的價格要比磁碟層價格低四倍。這種差異主要是由於在歸檔層的機器具有非常有限的計算能力,故降低了成本。
總結
無計算能力的儲存比有計算能力的儲存要便宜。我們可以依據資料的溫度來確保具計算能力的儲存能得到充分地使用。因為每一個分塊的資料都會被覆制多次(預設是3次),根據資料的溫度,許多副本都會被移動到低成本的儲存中。HDFS支援分層儲存並提供必要的工具來進行跨層的資料移動。eBay已經在其一個非常大規模的叢集上啟用了分層儲存,用來進行資料存檔。
Benoy Antony 是Apache Hadoop委員會的一名成員,他關註於HDFS和Hadoop安全性的研究。作為一名軟體工程師,Benoy就職於eBay資料基礎設施和服務部門。
英文出處:ebaytechblog
譯文出處:伯樂線上 – 無名俠女譚
譯文連結: http://blog.jobbole.com/85549/
http://blog.jobbole.com/85549/