作者:兵小志大
連結:https://www.cnblogs.com/try-better-tomorrow/p/4987620.html
1.為什麼要分表:
當一張表的資料達到幾千萬時,你查詢一次所花的時間會變多,如果有聯合查詢的話,我想有可能會死在那兒了。分表的目的就在於此,減小資料庫的負擔,縮短查詢時間。
mysql中有一種機制是表鎖定和行鎖定,是為了保證資料的完整性。表鎖定表示你們都不能對這張表進行操作,必須等我對錶操作完才行。行鎖定也一樣,別的sql必須等我對這條資料操作完了,才能對這條資料進行操作。
2.mysqlproxy:amoeba
做mysql叢集,利用amoeba。
從上層的java程式來講,不需要知道主伺服器和從伺服器的來源,即主從資料庫伺服器對於上層來講是透明的。可以透過amoeba來配置。
3.大資料量並且訪問頻繁的表,將其分為若干個表
比如對於某網站平臺的資料庫表-公司表,資料量很大,這種能預估出來的大資料量表,我們就事先分出個N個表,這個N是多少,根據實際情況而定。
某網站現在的資料量至多是5000萬條,可以設計每張表容納的資料量是500萬條,也就是拆分成10張表,
那麼如何判斷某張表的資料是否容量已滿呢?可以在程式段對於要新增資料的表,在插入前先做統計表記錄數量的操作,當<500萬條資料,就直接插入,當已經到達閥值,可以在程式段新建立資料庫表(或者已經事先建立好),再執行插入操作。
4.利用merge儲存引擎來實現分表
如果要把已有的大資料量表分開比較痛苦,最痛苦的事就是改程式碼,因為程式裡面的sql陳述句已經寫好了。用merge儲存引擎來實現分表,這種方法比較適合.
舉例子:

—————————–華麗的分割線————————————–
資料庫架構
1、簡單的MySQL主從複製:
MySQL的主從複製解決了資料庫的讀寫分離,並很好的提升了讀的效能,其圖如下:

其主從複製的過程如下圖所示:

但是,主從複製也帶來其他一系列效能瓶頸問題:
1.寫入無法擴充套件
2.寫入無法快取
3.複製延時
4.鎖表率上升
5.表變大,快取率下降
那問題產生總得解決的,這就產生下麵的最佳化方案,一起來看看。
2、MySQL垂直分割槽
如果把業務切割得足夠獨立,那把不同業務的資料放到不同的資料庫伺服器將是一個不錯的方案,而且萬一其中一個業務崩潰了也不會影響其他業務的正常進行,並且也起到了負載分流的作用,大大提升了資料庫的吞吐能力。經過垂直分割槽後的資料庫架構圖如下:
然而,儘管業務之間已經足夠獨立了,但是有些業務之間或多或少總會有點聯絡,如使用者,基本上都會和每個業務相關聯,況且這種分割槽方式,也不能解決單張表資料量暴漲的問題,因此為何不試試水平分割呢?
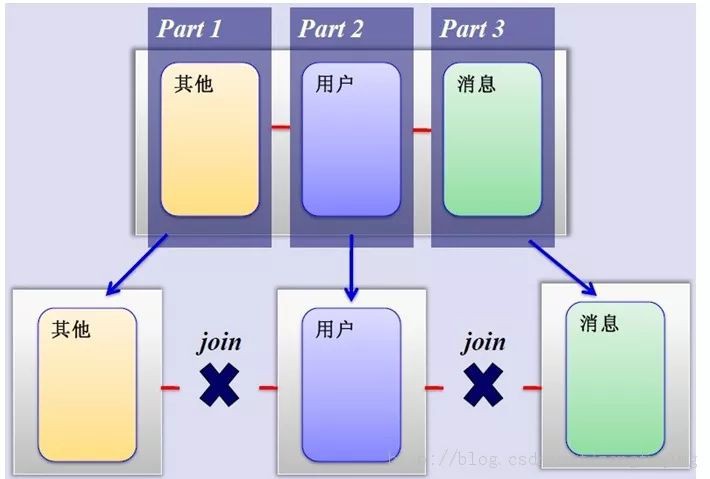
3、MySQL水平分片(Sharding)
這是一個非常好的思路,將使用者按一定規則(按id雜湊)分組,並把該組使用者的資料儲存到一個資料庫分片中,即一個sharding,這樣隨著使用者數量的增加,只要簡單地配置一臺伺服器即可,原理圖如下:

如何來確定某個使用者所在的shard呢,可以建一張使用者和shard對應的資料表,每次請求先從這張表找使用者的shardid,再從對應shard中查詢相關資料,如下圖所示:

單庫單表
單庫單表是最常見的資料庫設計,例如,有一張使用者(user)表放在資料庫db中,所有的使用者都可以在db庫中的user表中查到。
單庫多表
隨著使用者數量的增加,user表的資料量會越來越大,當資料量達到一定程度的時候對user表的查詢會漸漸的變慢,從而影響整個DB的效能。如果使用mysql,還有一個更嚴重的問題是,當需要新增一列的時候,mysql會鎖表,期間所有的讀寫操作只能等待。
可以透過某種方式將user進行水平的切分,產生兩個表結構完全一樣的user_0000,user_0001等表,user_0000+user_0001+…的資料剛好是一份完整的資料。
多庫多表
隨著資料量增加也許單臺DB的儲存空間不夠,隨著查詢量的增加單臺資料庫伺服器已經沒辦法支撐。這個時候可以再對資料庫進行水平區分。
分庫分表規則
設計表的時候需要確定此表按照什麼樣的規則進行分庫分表。例如,當有新使用者時,程式得確定將此使用者資訊新增到哪個表中;同理,當登入的時候我們得透過使用者的賬號找到資料庫中對應的記錄,所有的這些都需要按照某一規則進行。
路由
透過分庫分表規則查詢到對應的表和庫的過程。如分庫分表的規則是user_idmod4的方式,當使用者新註冊了一個賬號,賬號id的123,我們可以透過idmod4的方式確定此賬號應該儲存到User_0003表中。當使用者123登入的時候,我們透過123mod4後確定記錄在User_0003中。
分庫分表產生的問題,及註意事項
1.分庫分表維度的問題
假如使用者購買了商品,需要將交易記錄儲存取來,如果按照使用者的緯度分表,則每個使用者的交易記錄都儲存在同一表中,所以很快很方便的查詢到某使用者的購買情況,但是某商品被購買的情況則很有可能分佈在多張表中,查詢起來比較麻煩。反之,按照商品維度分表,可以很方便的查詢到此商品的購買情況,但要查詢到買人的交易記錄比較麻煩。
所以常見的解決方式有:
a.透過掃表的方式解決,此方法基本不可能,效率太低了。
b.記錄兩份資料,一份按照使用者緯度分表,一份按照商品維度分表。
c.透過搜尋引擎解決,但如果實時性要求很高,又得關係到實時搜尋。
2.聯合查詢的問題
聯合查詢基本不可能,因為關聯的表有可能不在同一資料庫中。
3.避免跨庫事務
避免在一個事務中修改db0中的表的時候同時修改db1中的表,一個是操作起來更複雜,效率也會有一定影響。
4.儘量把同一組資料放到同一DB伺服器上
例如將賣家a的商品和交易資訊都放到db0中,當db1掛了的時候,賣家a相關的東西可以正常使用。也就是說避免資料庫中的資料依賴另一資料庫中的資料。
一主多備
在實際的應用中,絕大部分情況都是讀遠大於寫。Mysql提供了讀寫分離的機制,所有的寫操作都必須對應到Master,讀操作可以在Master和Slave機器上進行,Slave與Master的結構完全一樣,一個Master可以有多個Slave,甚至Slave下還可以掛Slave,透過此方式可以有效的提高DB叢集的QPS.
所有的寫操作都是先在Master上操作,然後同步更新到Slave上,所以從Master同步到Slave機器有一定的延遲,當系統很繁忙的時候,延遲問題會更加嚴重,Slave機器數量的增加也會使這個問題更加嚴重。
此外,可以看出Master是叢集的瓶頸,當寫操作過多,會嚴重影響到Master的穩定性,如果Master掛掉,整個叢集都將不能正常工作。
所以,1.當讀壓力很大的時候,可以考慮新增Slave機器的分式解決,但是當Slave機器達到一定的數量就得考慮分庫了。2.當寫壓力很大的時候,就必須得進行分庫操作。
MySQL使用為什麼要分庫分表
可以用說用到MySQL的地方,只要資料量一大,馬上就會遇到一個問題,要分庫分表.
這裡取用一個問題為什麼要分庫分表呢?MySQL處理不了大的表嗎?
其實是可以處理的大表的.我所經歷的專案中單表物理上檔案大小在80G多,單表記錄數在5億以上,而且這個表
屬於一個非常核用的表:朋友關係表.
但這種方式可以說不是一個最佳方式.因為面臨檔案系統如Ext3檔案系統對大於大檔案處理上也有許多問題.
這個層面可以用xfs檔案系統進行替換.但MySQL單表太大後有一個問題是不好解決:表結構調整相關的操作基
本不在可能.所以大項在使用中都會面監著分庫分表的應用.
從Innodb本身來講資料檔案的Btree上只有兩個鎖,葉子節點鎖和子節點鎖,可以想而知道,當發生頁拆分或是新增
新葉時都會造成表裡不能寫入資料.
所以分庫分表還就是一個比較好的選擇了.
那麼分庫分表多少合適呢?
經測試在單表1000萬條記錄一下,寫入讀取效能是比較好的.這樣在留點buffer,那麼單表全是資料字型的保持在
800萬條記錄以下,有字元型的單表保持在500萬以下.
如果按100庫100表來規劃,如使用者業務:
500萬100100=50000000萬=5000億記錄.
心裡有一個數了,按業務做規劃還是比較容易的.
用知識的力量武裝,把生活的絢爛點亮!
●編號415,輸入編號直達本文
●輸入m獲取文章目錄

Web開發
更多推薦《18個技術類微信公眾號》
涵蓋:程式人生、演演算法與資料結構、駭客技術與網路安全、大資料技術、前端開發、Java、Python、Web開發、安卓開發、iOS開發、C/C++、.NET、Linux、資料庫、運維等。
