點選上方“芋道原始碼”,選擇“置頂公眾號”
技術文章第一時間送達!
原始碼精品專欄
來源:http://t.cn/RcvTbjD
使用Java後端技術的目的就是構建業務應用,為使用者提供線上或者離線服務。因此,一個業務應用需要哪些技術、依賴哪些基礎設施就決定了需要掌握的後端技術有哪些。縱觀整個網際網路技術體系再結合公司的目前狀況,筆者認為必不可少或者非常關鍵的後端基礎技術/設施如下圖所示:
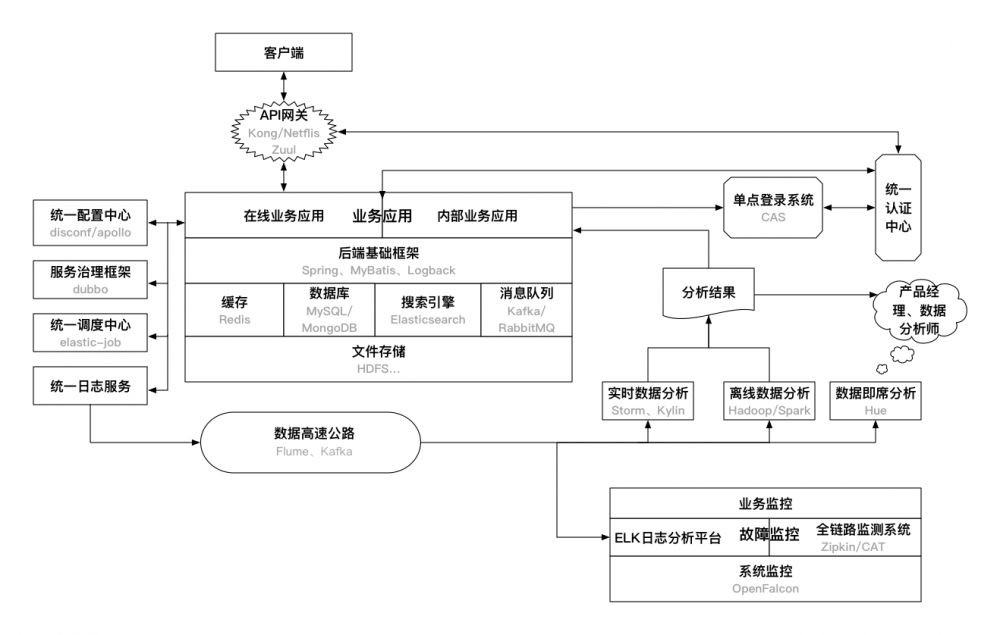
這裡的後端基礎設施主要指的是應用線上上穩定執行需要依賴的關鍵元件或者服務。開發或者搭建好以上的後端基礎設施,一般情況下是能夠支撐很長一段時間內的業務的。此外,對於一個完整的架構來說,還有很多應用感知不到的系統基礎服務,如負載均衡、自動化部署、系統安全等,並沒有包含在本章的描述範圍內。
1.1.1 統一請求入口-API閘道器
在移動APP的開發過程中,通常後端提供的介面需要以下功能的支援:
-
負載均衡
-
API訪問許可權控制
-
使用者鑒權
一般的做法,使用Nginx做負載均衡,然後在每個業務應用裡做API介面的訪問許可權控制和使用者鑒權,更最佳化一點的方式則是把後兩者做成公共類庫供所有業務呼叫。但從總體上來看,這三種特性都屬於業務的公共需求,更可取的方式則是整合到一起作為一個服務,既可以動態地修改許可權控制和鑒權機制,也可以減少每個業務整合這些機制的成本。這種服務就是API閘道器,可以選擇自己實現。也可以使用開源軟體實現,如Kong和Netflix Zuul。API閘道器一般架構如下圖所示:

但是以上方案的一個問題是由於所有API請求都要經過閘道器,它很容易成為系統的效能瓶頸。因此,可以採取的方案是:去掉API閘道器,讓業務應用直接對接統一認證中心,在基礎框架層面保證每個API呼叫都需要先透過統一認證中心的認證,這裡可以採取快取認證結果的方式避免對統一認證中心產生過大的請求壓力。
1.1.2 業務應用和後端基礎框架
業務應用分為:線上業務應用和內部業務應用。
-
線上業務應用:直接面向網際網路使用者的應用、介面等,典型的特點就是:請求量大、高併發、對故障的容忍度低。
-
內部業務應用:主要面向公司內部使用者的應用。比如,內部資料管理平臺、廣告投放平臺等。相比起線上業務應用,其特點: 資料保密性高、壓力小、併發量小、允許故障的發生。
業務應用基於後端的基礎框架開發,針對Java後端來說,應該有以下幾個框架:
-
MVC框架:統一開發流程、提高開發效率、遮蔽一些關鍵細節的Web/後端框架。典型的如SpringMVC、Jersey以及國人開發的JFinal以及阿裡的WebX。
-
IOC框架:實現依賴註入/控制反轉的框架。Java中最為流行的Spring框架的核心就是IOC功能。
-
ORM框架:能夠遮蔽底層資料庫細節,提供統一的資料訪問介面的資料庫操作框架,額外地能夠支援客戶端主從、分庫、分表等分散式特性。MyBatis是目前最為流行的ORM框架。此外,Spring ORM中提供的JdbcTemplate也很不錯。當然,對於分庫分表、主從分離這些需求,一般就需要自己實現,開源的則有阿裡的TDDL、噹噹的sharding-jdbc(從datasource層面解決了分庫分表、讀寫分離的問題,對應用透明、零侵入)。此外,為了在服務層面統一解決分庫分表、讀寫分離、主備切換、快取、故障恢復等問題,很多公司都是有自己的資料庫中介軟體的,比如阿裡的Cobar、360的Atlas(基於MySQL-Proxy)、網易的DDB等;開源的則有MyCat(基於Cobar)和Kingshard,其中Kingshard已經有一定的線上使用規模。MySQL官方也提供了MySQL Proxy, 可以使用lua指令碼自定義主從、讀寫分離、分割槽這些邏輯,但其效能較差,目前使用較少。
-
快取框架:對Redis、Memcached這些快取軟體操作的統一封裝,能夠支援客戶端分散式方案、主從等。一般使用Spring的RedisTemplate即可,也可以使用Jedis做自己的封裝,支援客戶端分散式方案、主從等。
-
JavaEE應用效能檢測框架:對於線上的JavaEE應用,需要有一個統一的框架整合到每一個業務中檢測每一個請求、方法呼叫、JDBC連線、Redis連線等的耗時、狀態等。Jwebap是一個可以使用的效能檢測工具,但由於其已經很多年沒有更新,有可能的話建議基於此專案做二次開發。
一般來說,以上幾個框架即可以完成一個後端應用的雛形。
1.1.3 快取、資料庫、搜尋引擎、訊息佇列
快取、資料庫、搜索引擎、訊息佇列這四者都是應用依賴的後端基礎服務,他們的效能直接影響到了應用的整體效能,有時候你程式碼寫的再好也許就是因為這些服務導致應用效能無法提升上去。
-
快取: 快取通常被用來解決熱點資料的訪問問題,是提高資料查詢效能的強大武器。在高併發的後端應用中,將資料持久層的資料載入到快取中,能夠隔離高併發請求與後端資料庫,避免資料庫被大量請求擊垮。目前常用的除了在記憶體中的本地快取,比較普遍的集中快取軟體有Memcached和Redis。其中Redis已經成為最主流的快取軟體。
-
資料庫:資料庫可以說是後端應用最基本的基礎設施。基本上絕大多數業務資料都是持久化儲存在資料庫中的。主流的資料庫包括傳統的關係型資料庫(MySQL、PostgreSQL)以及最近幾年開始流行的NoSQL(MongoDB、HBase)。其中HBase是用於大資料領域的列資料庫,受限於其查詢效能,一般並不用來做業務資料庫。
-
搜尋引擎:搜尋引擎是針對全文檢索以及資料各種維度查詢設計的軟體。目前用的比較多的開源軟體是Solr和Elasticsearch,都是基於Lucence來實現的,不同之處主要在於termIndex的儲存、分散式架構的支援等。Elasticsearch由於對叢集的良好支援以及高效能的實現,已經逐漸成為搜尋引擎的主流開源方案。
-
訊息佇列:資料傳輸的一種方式就是透過訊息佇列。目前用的比較普遍的訊息佇列包括為日誌設計的Kafka以及重事務的RabbitMQ等。在對訊息丟失不是特別敏感且並不要求訊息事務的場景下,選擇Kafka能夠獲得更高的效能;否則,RabbitMQ則是更好的選擇。此外,ZeroMQ則是一種實現訊息佇列的網路程式設計Pattern庫,位於Socket之上,MQ之下。
1.1.4 檔案儲存
不管是業務應用、依賴的後端服務還是其他的各種服務,最終還是要依賴於底層檔案儲存的。通常來說,檔案儲存需要滿足的特性有:可靠性、容災性、穩定性,即要保證儲存的資料不會輕易丟失,即使發生故障也能夠有回滾方案,也要保證高可用。在底層可以採用傳統的RAID作為解決方案,再上一層,目前Hadoop的HDFS則是最為普遍的分散式檔案儲存方案,當然還有NFS、Samba這種共享檔案系統也提供了簡單的分散式儲存的特性。
此外,如果檔案儲存確實成為了應用的瓶頸或者必須提高檔案儲存的效能從而提升整個系統的效能時,那麼最為直接和簡單的做法就是拋棄傳統機械硬碟,用SSD硬碟替代。像現在很多公司在解決業務效能問題的時候,最終的關鍵點往往就是SSD。這也是用錢換取時間和人力成本最直接和最有效的方式。在資料庫部分描述的SSDB就是對LevelDB封裝之後,利用SSD硬碟的特性的一種高效能KV資料庫。
至於HDFS,如果要使用上面的資料,是需要透過Hadoop的。類似xx on Yarn的一些技術就是將非Hadoop技術跑在HDFS上的解決方案。
1.1.5 統一認證中心
統一認證中心,主要是對APP使用者、內部使用者、APP等的認證服務,包括
-
使用者的註冊、登入驗證、Token鑒權
-
內部資訊系統使用者的管理和登入鑒權
-
APP的管理,包括APP的secret生成,APP資訊的驗證(如驗證介面簽名)等。
之所以需要統一認證中心,就是為了能夠集中對這些所有APP都會用到的資訊進行管理,也給所有應用提供統一的認證服務。尤其是在有很多業務需要共享使用者資料的時候,構建一個統一認證中心是非常必要的。此外,透過統一認證中心構建移動APP的單點登入也是水到渠成的事情:模仿Web的機制,將認證後的資訊加密儲存到本地儲存中供多個APP使用。
1.1.6 單點登入系統
目前很多大的線上Web網站都是有單點登入系統的,通俗的來說就是隻需要一次使用者登入,就能夠進入多個業務應用(許可權可以不相同),非常方便使用者的操作。而在移動網際網路公司中,內部的各種管理、資訊系統甚至外部應用同樣也需要單點登入系統。
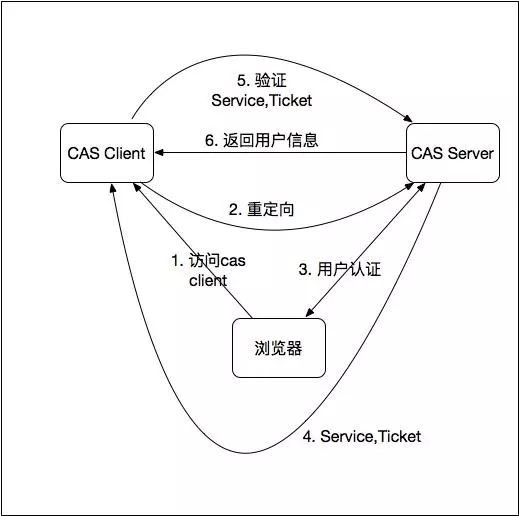
目前,比較成熟的、用的最多的單點登入系統應該是耶魯大學開源的CAS, 可以基於 https://github.com/apereo/cas/tree/master/cas-server-webapp 來定製開發的。
基本上,單點登入的原理都類似下圖所示:
1.1.7 統一配置中心
在Java後端應用中,一種讀寫配置比較通用的方式就是將配置檔案寫在Propeties、YAML、HCON等檔案中,修改的時候只需要更新檔案重新部署即可,可以做到不牽扯程式碼層面改動的目的。統一配置中心,則是基於這種方式之上的統一對所有業務或者基礎後端服務的相關配置檔案進行管理的統一服務, 具有以下特性:
-
能夠線上動態修改配置檔案並生效
-
配置檔案可以區分環境(開發、測試、生產等)
-
在Java中可以透過註解、XML配置的方式引入相關配置
百度開源的Disconf和攜程的Apollo是可以在生產環境使用的方案,也可以根據自己的需求開發自己的配置中心,一般選擇Zookeeper作為配置儲存。
1.1.8 服務治理框架
對於外部API呼叫或者客戶端對後端API的訪問,可以使用HTTP協議或者RESTful(當然也可以直接透過最原始的socket來呼叫)。但對於內部服務間的呼叫,一般都是透過RPC機制來呼叫的。目前主流的RPC協議有:
-
RMI
-
Hessian
-
Thrift
-
Dubbo
這些RPC協議各有優劣點,需要針對業務需求做出最好的選擇。
這樣,當你的系統服務在逐漸增多,RPC呼叫鏈越來越複雜,很多情況下,需要不停的更新檔案來維護這些呼叫關係。一個對這些服務進行管理的框架可以大大減少因此帶來的繁瑣的人力工作。
傳統的ESB(企業服務匯流排)本質就是一個服務治理方案,但ESB作為一種proxy的角色存在於Client和Server之間,所有請求都需要經過ESB,使得ESB很容易成為效能瓶頸。因此,基於傳統的ESB,更好的一種設計如下圖所示: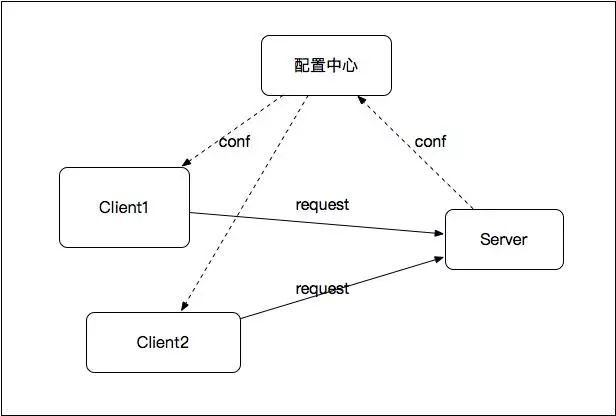
如圖,以配置中心為樞紐,呼叫關係只存在於Client和提供服務的Server之間,就避免了傳統ESB的效能瓶頸問題。對於這種設計,ESB應該支援的特性如下:
-
服務提供方的註冊、管理
-
服務消費者的註冊、管理
-
服務的版本管理、負載均衡、流量控制、服務降級、資源隔離
-
服務的容錯、熔斷
阿裡開源的Dubbo則對以上做了很好的實現,也是目前很多公司都在使用的方案;噹噹網的擴充套件專案Dubbox則在Dubbo之上加入了一些新特性。目前,Dubbo已經被阿裡貢獻給Apache,處於incubating狀態。在運維監控方面,Dubbo本身提供了簡單的管理控制檯dubbo-admin和監控中心dubbo-monitor-simple。Github上的dubboclub/dubbokeeper則是在其之上開發的更為強大的集管理與監控於一身的服務管理以及監控系統。
此外,Netflix的Eureka也提供了服務註冊發現的功能,其配合Ribbon可以實現服務的客戶端軟負載均衡,支援多種靈活的動態路由和負載均衡策略。
1.1.9 統一排程中心
在很多業務中,定時排程是一個非常普遍的場景,比如定時去抓取資料、定時掃清訂單的狀態等。通常的做法就是針對各自的業務依賴Linux的Cron機制或者Java中的Quartz。統一排程中心則是對所有的排程任務進行管理,這樣能夠統一對排程叢集進行調優、擴充套件、任務管理等。Azkaban和Yahoo的Oozie是Hadoop的流式工作管理引擎,也可以作為統一排程中心來使用。當然,你也可以使用Cron或者Quartz來實現自己的統一排程中心。
-
根據Cron運算式排程任務
-
動態修改、停止、刪除任務
-
支援任務分片執行
-
支援任務工作流:比如一個任務完成之後再執行下一個任務
-
任務支援指令碼、程式碼、url等多種形式
-
任務執行的日誌記錄、故障報警
對於Java的Quartz這裡需要說明一下:這個Quartz需要和Spring Quartz區分,後者是Spring對Quartz框架的簡單實現也是目前使用的最多的一種排程方式。但其並沒有做高可用叢集的支援。而Quartz雖然有叢集的支援,但是配置起來非常複雜。現在很多方案都是使用Zookeeper來實現Spring Quartz的分散式叢集。
此外,噹噹網開源的elastic-job則在基礎的分散式排程之上又加入了彈性資源利用等更為強大的功能。
1.1.10 統一日誌服務
日誌是開發過程必不可少的東西。列印日誌的時機、技巧是很能體現出工程師編碼水平的。畢竟,日誌是線上服務能夠定位、排查異常最為直接的資訊。
通常的,將日誌分散在各個業務中非常不方便對問題的管理和排查。統一日誌服務則使用單獨的日誌伺服器記錄日誌,各個業務透過統一的日誌框架將日誌輸出到日誌伺服器上。
可以透過實現Log4j或者Logback的Appender來實現統一日誌框架,然後透過RPC呼叫將日誌列印到日誌伺服器上。
1.1.11 資料基礎設施
資料是最近幾年非常火的一個領域。從《精益資料分析》到《增長駭客》,都是在強調資料的非凡作用。很多公司也都在透過資料推動產品設計、市場運營、研發等。這裡需要說明的一點是,只有當你的資料規模真的到了單機無法處理的規模才應該上大資料相關技術,千萬不要為了大資料而大資料。很多情況下使用單機程式+MySQL就能解決的問題非得上Hadoop即浪費時間又浪費人力。
這裡需要補充一點的是,對於很多公司,尤其是離線業務並沒有那麼密集的公司,在很多情況下大資料叢集的資源是被浪費的。因此誕了 xx on Yarn 一系列技術讓非Hadoop系的技術可以利用大資料叢集的資源,能夠大大提高資源的利用率,如Dockeron Yarn。
資料高速公路
接著上面講的統一日誌服務,其輸出的日誌最終是變成資料到資料高速公路上供後續的資料處理程式消費的。這中間的過程包括日誌的收集和傳輸。
-
收集:統一日誌服務將日誌列印在日誌服務上之後,需要日誌收集機制將其集中起來。目前,常見的日誌收集方案有:Scribe、Chukwa、Kakfa和Flume。對比如下圖所示:

此外,Logstash也是一個可以選擇的日誌收集方案,不同於以上的是,它更傾向於資料的預處理,且配置簡單、清晰,經常以ELK(Elasticsearch + Logstash + Kibana)的架構用於運維場景中。
-
傳輸:透過訊息佇列將資料傳輸到資料處理服務中。對於日誌來說,通常選擇Kafka這個訊息佇列即可。
此外,這裡還有一個關鍵的技術就是資料庫和資料倉庫間的資料同步問題,即將需要分析的資料從資料庫中同步到諸如Hive這種資料倉庫時使用的方案。可以使用Apache Sqoop進行基於時間戳的資料同步,此外,阿裡開源的Canal實現了基於binlog增量同步,更加適合通用的同步場景,但是基於Canal還是需要做不少的業務開發工作。
離線資料分析
離線資料分析是可以有延遲的,一般針對的是非實時需求的資料分析工作,產生的也是延遲一天的報表。目前最常用的離線資料分析技術除了Hadoop還有Spark。相比Hadoop,Spark效能上有很大優勢,當然對硬體資源要求也高。其中,Hadoop中的Yarn作為資源管理排程元件除了服務於MR還可以用於Spark(Spark on Yarn),Mesos則是另一種資源管理排程系統。
對於Hadoop,傳統的MR編寫很複雜,也不利於維護,可以選擇使用Hive來用SQL替代編寫MR。而對於Spark,也有類似Hive的Spark SQL。
此外,對於離線資料分析,還有一個很關鍵的就是資料傾斜問題。所謂資料傾斜指的是region資料分佈不均,造成有的結點負載很低,而有些卻負載很高,從而影響整體的效能。處理好資料傾斜問題對於資料處理是很關鍵的。
實時資料分析
相對於離線資料分析,實時資料分析也叫線上資料分析,針對的是對資料有實時要求的業務場景,如廣告結算、訂單結算等。目前,比較成熟的實時技術有Storm和Spark Streaming。相比起Storm,Spark Streaming其實本質上還是基於批次計算的。如果是對延遲很敏感的場景,還是應該使用Storm。除了這兩者,Flink則是最近很火的一個分散式實時計算框架,其支援Exactly Once的語意,在大資料量下具有高吞吐低延遲的優勢,並且能夠很好的支援狀態管理和視窗統計,但其檔案、API管理平臺等都還需要完善。
實時資料處理一般情況下都是基於增量處理的,相對於離線來說並非可靠的,一旦出現故障(如叢集崩潰)或者資料處理失敗,是很難對資料恢復或者修複異常資料的。因此結合離線+實時是目前最普遍採用的資料處理方案。Lambda架構就是一個結合離線和實時資料處理的架構方案。
此外,實時資料分析中還有一個很常見的場景:多維資料實時分析,即能夠組合任意維度進行資料展示和分析。目前有兩種解決此問題的方案:ROLAP和MOLAP。
-
ROLAP:使用關係型資料庫或者擴充套件的關係型資料庫來管理資料倉庫資料,以Hive、Spark SQL、Presto為代表。
-
MOLAP:基於資料立方體的多位儲存引擎,用空間換時間,把所有的分析情況都物化為物理表或者檢視。以Druid、Pinot和Kylin為代表,不同於ROLAP(Hive、Spark SQL), 其原生的支援多維的資料查詢。
如上一小節所述,ROLAP的方案大多數情況下使用者離線資料分析,滿足不了實時的需求,因此MOLAP是多維資料實時分析的常用方案。對於其中常用的三個框架,對比如下:
| . | 使用場景 | 語言 | 協議 | 特點 |
|---|---|---|---|---|
| Druid | 實時處理分析 | Java | JSON | 實時聚合 |
| Pinot | 實時處理分析 | Java | JSON | 實時聚合 |
| Kylin | OLAP分析引擎 | Java | JDBC/OLAP | 預處理、cache |
其中,Druid相對比較輕量級,用的人較多,比較成熟。
資料即席分析
離線和實時資料分析產生的一些報表是給資料分析師、產品經理參考使用的,但是很多情況下,線上的程式並不能滿足這些需求方的需求。這時候就需要需求方自己對資料倉庫進行查詢統計。針對這些需求方,SQL上手容易、易描述等特點決定了其可能是一個最為合適的方式。因此提供一個SQL的即席查詢工具能夠大大提高資料分析師、產品經理的工作效率。Presto、Impala、Hive都是這種工具。如果想進一步提供給需求方更加直觀的ui操作介面,可以搭建內部的Hue。

1.1.12 故障監控
對於面向使用者的線上服務,發生故障是一件很嚴重的事情。因此,做好線上服務的故障檢測告警是一件非常重要的事情。可以將故障監控分為以下兩個層面的監控:
-
系統監控:主要指對主機的頻寬、CPU、記憶體、硬碟、IO等硬體資源的監控。可以使用Nagios、Cacti等開源軟體進行監控。目前,市面上也有很多第三方服務能夠提供對於主機資源的監控,如監控寶等。對於分散式服務叢集(如Hadoop、Storm、Kafka、Flume等叢集)的監控則可以使用Ganglia。此外,小米開源的OpenFalcon也很不錯,涵蓋了系統監控、JVM監控、應用監控等,也支援自定義的監控機制。
-
業務監控:是在主機資源層面以上的監控,比如APP的PV、UV資料異常、交易失敗等。需要業務中加入相關的監控程式碼,比如在異常丟擲的地方,加一段日誌記錄。
監控還有一個關鍵的步驟就是告警。告警的方式有很多種:郵件、IM、簡訊等。考慮到故障的重要性不同、告警的合理性、便於定位問題等因素,有以下建議:
-
告警日誌要記錄發生故障的機器ID,尤其是在叢集服務中,如果沒有記錄機器ID,那麼對於後續的問題定位會很困難。
-
要對告警做聚合,不要每一個故障都單獨進行告警,這樣會對工程師造成極大的困擾。
-
要對告警做等級劃分,不能對所有告警都做同樣的優先順序處理。
-
使用微信做為告警軟體,能夠在節省簡訊成本的情況下,保證告警的到達率。
故障告警之後,那麼最最關鍵的就是應對了。對於創業公司來說,24小時待命是必備的素質,當遇到告警的時候,需要儘快對故障做出反應,找到問題所在,並能在可控時間內解決問題。對於故障問題的排查,基本上都是依賴於日誌的。只要日誌打的合理,一般情況下是能夠很快定位到問題所在的,但是如果是分散式服務,並且日誌資料量特別大的情況下,如何定位日誌就成為了難題。這裡有幾個方案:
-
建立ELK(Elasticsearch + Logstash + Kibana)日誌集中分析平臺,便於快速搜尋、定位日誌。搭配Yelp開源的Elastalert可以實現告警功能。
-
建立分散式請求追蹤系統(也可以叫全鏈路監測系統),對於分散式系統尤是微服務架構,能夠極大的方便在海量呼叫中快速定位並收集單個異常請求資訊,也能快速定位一條請求鏈路的效能瓶頸。唯品會的Mercury、阿裡的鷹眼、新浪的WatchMan、Twitter開源的Zipkin基本都是基於Google的Dapper論文而來,大眾點評的實時應用監控平臺CAT則在支援分散式請求追蹤(程式碼侵入式)的基礎上加入了細粒度的呼叫效能資料統計。此外,Apache正在孵化中的HTrace則是針對大的分散式系統諸如HDFS檔案系統、HBase儲存引擎而設計的分散式追蹤方案。而如果你的微服務實現使用了Spring Cloud,那麼Spring Cloud Sleuth
如果你對 Dubbo / Netty 等等原始碼與原理感興趣,歡迎加入我的知識星球一起交流。長按下方二維碼噢:

目前在知識星球更新了《Dubbo 原始碼解析》目錄如下:
01. 除錯環境搭建
02. 專案結構一覽
03. 配置 Configuration
04. 核心流程一覽
05. 拓展機制 SPI
06. 執行緒池
07. 服務暴露 Export
08. 服務取用 Refer
09. 註冊中心 Registry
10. 動態編譯 Compile
11. 動態代理 Proxy
12. 服務呼叫 Invoke
13. 呼叫特性
14. 過濾器 Filter
15. NIO 伺服器
16. P2P 伺服器
17. HTTP 伺服器
18. 序列化 Serialization
19. 叢集容錯 Cluster
20. 優雅停機
21. 日誌適配
22. 狀態檢查
23. 監控中心 Monitor
24. 管理中心 Admin
25. 運維命令 QOS
26. 鏈路追蹤 Tracing
… 一共 69+ 篇
目前在知識星球更新了《Netty 原始碼解析》目錄如下:
01. 除錯環境搭建
02. NIO 基礎
03. Netty 簡介
04. 啟動 Bootstrap
05. 事件輪詢 EventLoop
06. 通道管道 ChannelPipeline
07. 通道 Channel
08. 位元組緩衝區 ByteBuf
09. 通道處理器 ChannelHandler
10. 編解碼 Codec
11. 工具類 Util
… 一共 61+ 篇
目前在知識星球更新了《資料庫物體設計》目錄如下:
01. 商品模組
02. 交易模組
03. 營銷模組
04. 公用模組
… 一共 17+ 篇
原始碼不易↓↓↓↓↓
點贊支援老艿艿↓↓
