前言
經過前幾篇的分析,其實大體已經初窺到SQL Server統計資訊的重要性了,所以本篇就要祭出這個神器了。
該篇內容會很長,坐好板凳,瓜子零食之類…
不廢話,進正題
技術準備
資料庫版本為SQL Server2008R2,利用微軟的以前的案例庫(Northwind)進行分析,部分內容也會應用微軟的另一個案例庫AdventureWorks
相信瞭解SQL Server的朋友,對這兩個庫都不會太陌生。
概念理解
關於SQL Server中的統計資訊,在聯機叢書中是這樣解釋的
查詢最佳化的統計資訊是一些物件,這些物件包含與值在表或索引檢視的一列或多列中的分佈有關的統計資訊。查詢最佳化器使用這些統計資訊來估計查詢結果中的基數或行數。透過這些基數估計,查詢最佳化器可以建立高質量的查詢計劃。例如,查詢最佳化器可以使用基數估計選擇索引查詢運運算元而不是耗費更多資源的索引掃描運運算元,從而提高查詢效能。
其實關於統計資訊的作用通俗點將就是:SQL Server透過統計資訊理解庫中每張表的資料內容項分佈,知道裡面資料“長得啥德行,做到心中有數”,這樣每次查詢陳述句的時候就可以根據表中的資料分佈,基本能定位到要查詢資料的內容位置。
比如,我記得我以前有篇文章寫過一個相同的查詢陳述句,但是產生了完全不同的查詢計劃,這裡回顧下,基本如下:
SELECT * FROM Person.Contact
WHERE FirstName LIKE ‘K%’SELECT * FROM Person.Contact
WHERE FirstName LIKE ‘Y%’
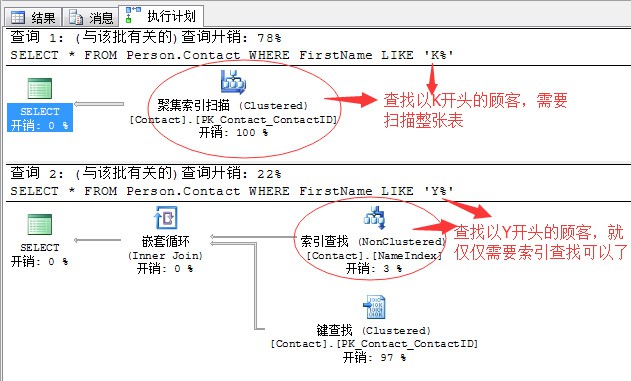
完全相同的查詢陳述句,只是查詢條件不同,一個查詢以K開頭的顧客,一個查詢以Y開頭的顧客,卻產生了完全不同的查詢計劃。
其實,這裡的原因就是統計資訊在作祟。
我們知道,在這張表的FirstName欄位存在一個非聚集索引,標的就是為了提升如上面的查詢陳述句的效能。
但是這張表裡面FirstName欄位中的資料內容以K開頭的顧客存在1255行,也就是如果利用非聚集索引查詢的方式,需要產生1225次IO操作,這可能不是最糟的,糟的還在後面,因為我們獲取的資料欄位並不全部在FirstName欄位中,而需要額外的書簽查詢來獲取,而這個書簽查詢會產生的大量的隨機IO操作。記住:這裡是隨機IO。關於這裡的查詢方式在我們第一篇文章中就有介紹。
所以相比利用非聚集索引所帶來的消耗相比,全部的所以索引掃描來的更划算,因為它依次掃描就可以獲取想要的資料。
而以Y開頭的就只有37行,37行資料完全透過非聚集索引獲取,再加一部分的書簽查詢很顯然是一個很划算的方式。因為它資料量少,產生的隨機IO量相對也會少。
所以,這裡的問題來了:
SQL Server是如何知道這張表裡FirstName欄位中以K開頭的顧客會比較多,而以Y開頭反而少呢?。
這裡就是統計資訊在作祟了,它不但知道FirstName欄位中各行資料的內容“長啥樣”,並且還是知道每行資料的分佈情況。
其實,這就好比在圖書庫中,每個書架就是一張表,而每本書就是一行資料,索引就好像圖書館書籍串列,比如按類區分,而統計資訊就好像是每類書籍的多少以及存放書架位置。所以你借一本書的時候,需要藉助索引來檢視,然後利用統計資訊指導位置,這樣才能獲取書本。
希望這樣解釋,看官已經明白了統計資訊的作用了。
這裡多談點,有很多童鞋沒有深入瞭解索引和統計資訊的作用前提下,在看過很多調優的文章之後,只深諳了一句話:調優嘛,建立索引就行了。
我不否認建立索引這種方式調優方式的作用性,但是很多時候關於建索引的技巧卻不瞭解。更巧的是大部分情況下屬於誤打誤撞建立完索引後,效能果真提升了,而有時候建立的索引卻毫無用處,只會影響表的其它操作的效能(尤其是Insert),更有甚者會產生死鎖情況。
而且,關於索引項的作用,其實很多的情況下,並不想你想象的那麼美好,後續文章我們會分析那些索引失效的原因。
所以遇到問題,其實還要透過表象理解其本質,這樣才能做到真正的有的放矢,有把握的解決問題。
解析統計資訊
我們來詳細分析一下統計資訊中的內容項,我們知道在上面的陳述句中,在表Customers中ContactName列中存在一個非聚集索引項,所以在該列存在統計資訊,我們可以透過如下指令碼檢視該表的統計資訊串列
sp_helpstats Customers

然後透過以下命令來檢視該統計資訊的詳細內容,程式碼如下
DBCC SHOW_STATISTICS(Customers,ContactName)
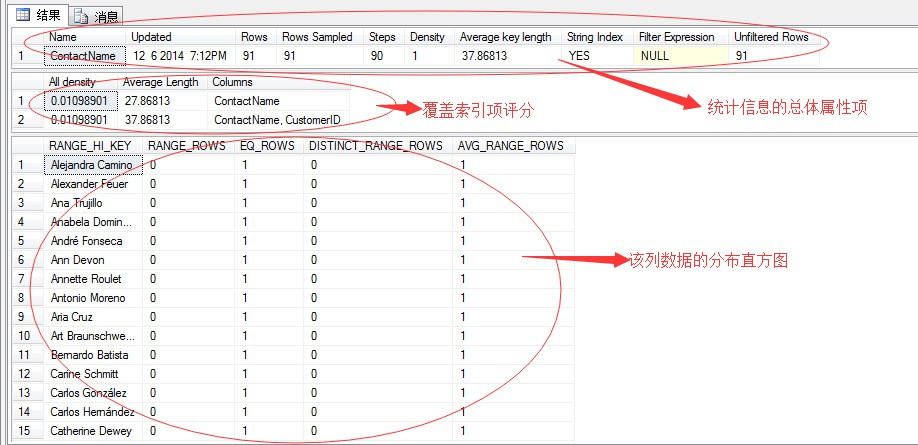
每一個統計資訊的內容都包含以上三部分的內容。
我們依次來分析下,透過這三部分內容SQL Server如何瞭解該列資料的內容分佈的。
a、統計資訊的總體屬性項
該部分包含以下幾列:
Name:統計資訊的名稱。
Updated:統計資訊的最近一次更新時間,這個時間資訊很重要,根據它我們能知道該統計資訊什麼時候更新的,是不是最新的,是不是存在統計資訊更新不及時造成統計的當前資料分佈不準確等問題。
Rows:描述當前表中的總行數。
Rows Sampled:統計資訊的抽樣資料。當資料量比較多的時候,統計資訊的獲取是採用的抽樣的方式統計的,如果資料量比較就會透過掃描全部獲取比較精確的統計值。比如,上面的例子中抽樣資料就為91行。
Steps:步長值。也就是SQL Server統計資訊的根據資料行的分組的個數。這個步長值也是有SQL Server自己確定的,因為步長越小,描述的資料越詳細,但是消耗也越多,所以SQL Server會自己平衡這個值。
Density:密度值,也就是列值字首的大小。
Average Key length:所有列的平均長度。
String Index:表示統計值是否為字串的統計資訊。這裡字串的評估目的是為了支援LIKE關鍵字的搜尋。
Filter Expression:過濾運算式,這個是SQL Server2008以後版本的新特性,支援新增過濾運算式,更加細粒度進行統計分析。
Unfiltered Rows:沒有經過運算式過濾的行,也是新特性。
經過上面部分的資料,統計資訊已經分析出該列資料的最近更新時間、資料量、資料長度、資料型別等資訊值。
b、統計資訊的改寫索引項
All density:反映索引列的稠密度值。這是一個非常重要的值,SQL Server會根據這個評分項來決定該索引的有效程度。
該分值的計算公式為:density=1/表中非重覆的行數。所以該稠密度值取值範圍為:0-1。
該值越小說明該列的索引項選擇性更強,也就說該索引更有效。理想的情況是全部為非重覆值,也就是說都是唯一值,這樣它的數最小。
舉個例子:比如上面的例子該列存在91行,假如顧客不存在重名的情況下,那麼該密度值就為1/91=0.010989,該列為性別列,那麼它只存在兩個值:男、女,那麼該列的密度值就為0.5,所以相比而言SQL Server在索引選擇的時候很顯然就會選擇ContactName(顧客名字)列。
簡單點講:就是當前索引的選擇性高,它的稠密度值就小,那麼它就重覆值少,這樣篩選的時候更容易找到重覆值。相反,重覆值多選擇性就差,比如性別,一次過濾只能過濾掉一半的記錄。
Average Length:索引的平均長度。
Columns:索引列的名稱。這裡因為我們是非聚集索引,所以會存在兩行,一行為ContactName索引列,一行為ContactName索引列和聚集索引的列值CustomerID組合列。希望能明白這裡,索引基礎知識。
透過以上部分資訊,SQL Server會知道該部分的資料獲取方式那個更快,更有效。
c、統計資訊的直方圖資訊
我們接著分析第三部分,該列直方圖資訊,透過這塊SQL Server能直觀“掌控”該列的資料分佈內容,我們來看
RANGE_HI_KEY:直方圖中每一組資料的最大值。這個好理解,如果資料量大的話,經過分組,這個值就是當前組的最大值。上面例子的統計資訊總共分了90組,總共才91行,也就是說,SQL Server為了準確的描述該列的值,大部分每個組只取了一個值,只有一個組取了倆值。
RANGE_ROWS:直方圖的沒組資料的區間行數(不包括最大值)。這裡我們說了總共就91行,它分了90組,所以有一組會存在兩個值,我們找到它:
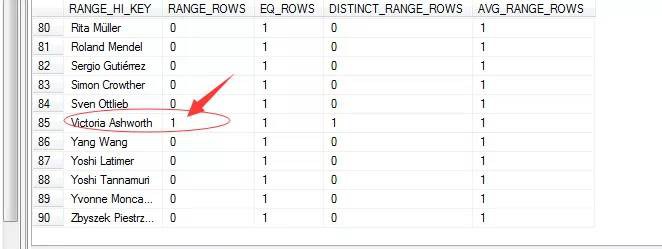
EQ_ROWS:這裡表示和上面最大值相等的行數目。因為我們不包含一樣的,所以這裡值都為 1
DISTINCT_RANGE_ROWS:直方圖每組資料區間的非重覆值的數目。上限值除外。
AVG_RANGE_ROWS:每個直方圖平均的行數。
經過最後一部分的描述,SQL Server已經完全掌控了該表中該欄位的資料內容分佈了。想獲取那些資料根據它就可以從容獲取到。
所以當我們每次寫的T-SQL陳述句,它都能根據統計資訊評估出要獲取的資料量多少,並且找到最合適的執行計劃來執行。
我也相信經過上面三部分的分析,關於文章開篇我們提到的那個關於‘K’和‘Y’的問題會找到答案了,這裡不解釋了。
當然,如果資料量特別大,統計資訊的維護也會有小小的失誤,而這時候就需要我們來站出來及時的彌補。
建立統計資訊
透過上面的介紹,其實我們已經看到了統計資訊的強大作用了,所以對於資料庫來說它的重要性就不言而喻了,因此,SQL Server會自動的建立統計資訊,適時的更新統計資訊,當然我們可以關閉掉,但是我非常不建議這麼做,原因很簡單:No Do No Die…
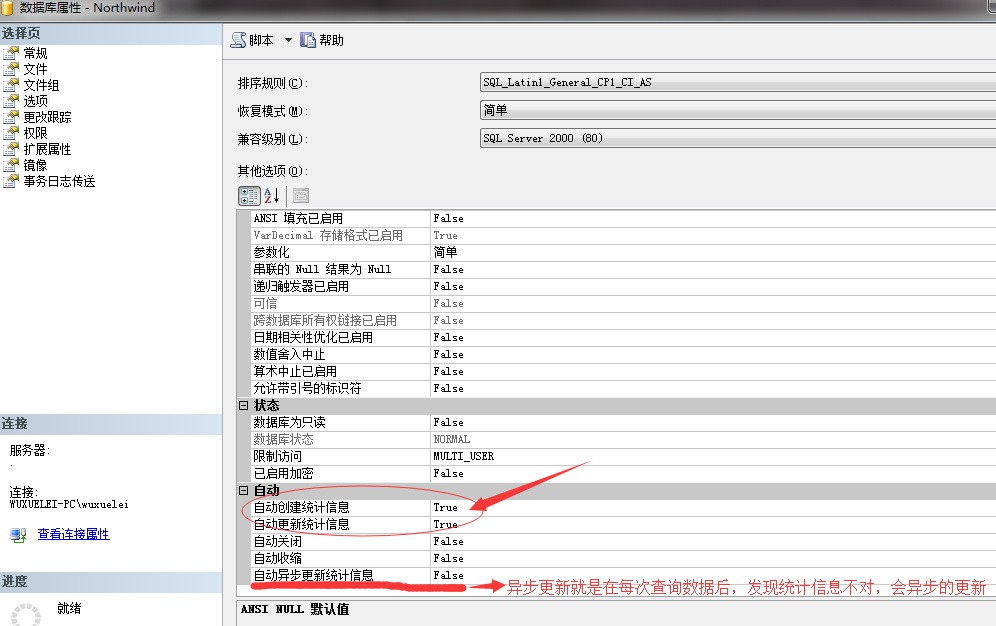
這兩項功能預設是開啟的,也就是說SQL Server會自己維護統計資訊的準確性。
在日常維護中,我們大可不必要去更改這兩項,當然也有比較極端的情況,因為我們知道更新統計資訊也是一個消耗,在非常的大的併發的系統中需要關掉自動更新功能,這種情況非常的少之又少,所以基本採用預設值就可以。
在以下情況下,SQL Server會自動的建立統計資訊:
1、在索引建立時,SQL Server會自動的在索引列上建立統計資訊。
2、當SQL Server想要使用某些列上的統計資訊,發現沒有的時候,這時候會自動建立統計資訊。
3、當然,我們也可以手動建立。
比如,自動建立的例子
select * into CustomersStats from Customers
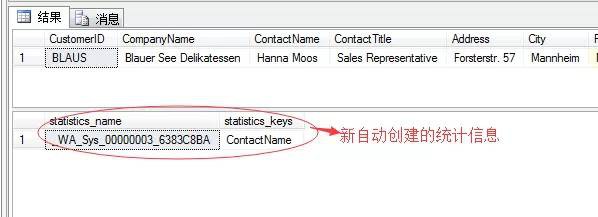
sp_helpstats CustomersStats
來新增一個查詢陳述句,然後再檢視統計資訊
select * from CustomersStats
where ContactName=’Hanna Moos’
go
sp_helpstats CustomersStats
go
當然,我們也可以根據自己的情況來手動建立,建立指令碼如下
USE [Northwind]
GO
CREATE STATISTICS [CoustomersOne] ON [dbo].[CustomersStats]([CompanyName])
GO
SQL Server也提供了GUI的影象化操作視窗,方便操作
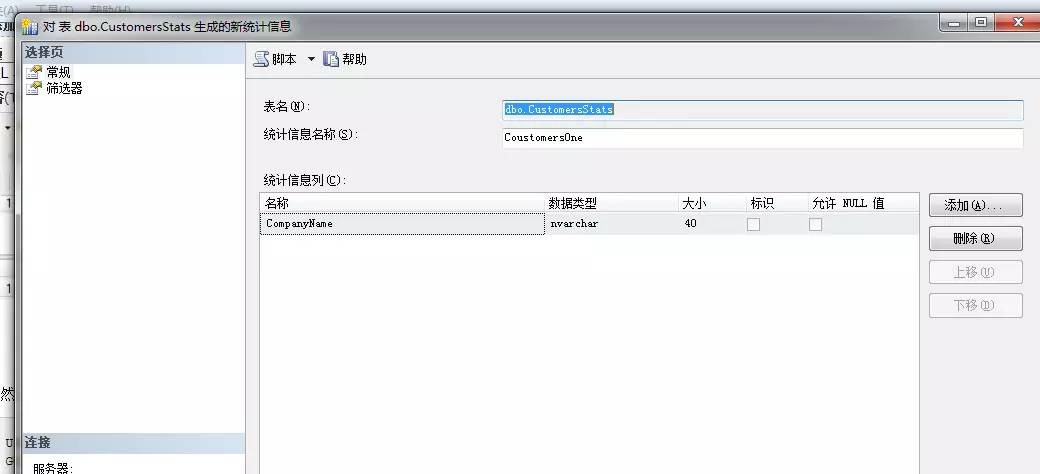
在以下情況下,SQL Server會自動的更新統計資訊:
1、如果統計資訊是定義在普通的表格上,那麼當發生以下任一種的變化後,統計資訊就會被觸發更新動作。
表格從沒有資料變成大於等於1條資料。
對於資料量小於500行的表格,當統計資訊的第一個欄位資料累計變化大於500以後。
對於資料量大於500行的表格,當統計資訊的第一個欄位資料累計變化大於500+(20%*表格總的資料量)以後。所以對於較大的表,只有1/5以上的資料發生變化後,SQL Server才會重新計算統計資訊。
2、臨時表上也可以有統計資訊。這也是很多情況下採用臨時表最佳化的原因之一。其維護策略基本和普通表格一樣,但是表變數不能建立統計資訊。
文章寫的有點糙….但篇幅已經稍長了….先到此吧…後續我再補充一部分關於統計資訊的內容。
關於調優內容太廣泛,我們放在以後的篇幅中介紹,有興趣的可以提前關註。
參考文獻
參照書籍《Microsoft SQL Server企業級平臺管理實踐》
參照書籍《SQL.Server.2005.技術內幕》系列
有問題可以留言或者私信,隨時恭候有興趣的童鞋加入SQL SERVER的深入研究。共同學習,一起進步。
原文出處: 指尖流淌-吳學雷的部落格
原文連結: http://www.cnblogs.com/zhijianliutang/p/4190669.html