
作者丨蔣錸
學校丨北京航空航天大學在校博士,大不列顛哥倫比亞大學聯合培養博士
研究方向丨計算機視覺
本文概述了來自北京航空航天大學徐邁老師組 ECCV 2018 的工作 DeepVS: A Deep Learning Based Video Saliency Prediction Approach。全文主要貢獻點有三:
-
建立了大規模普適影片的眼動資料庫,包含了 158 子類的 538 個影片,以及詳盡的資料分析;
-
構造了基於運動物體的靜態結構 OM-CNN 用於檢測幀內顯著性;
-
構造了動態結構 SS-ConvLSTM 用於預測影片顯著性的幀間轉移,同時考慮到了顯著性的稀疏先驗和中心先驗。
■ 論文 | DeepVS: A Deep Learning Based Video Saliency Prediction Approach
■ 連結 | https://www.paperweekly.site/papers/2329
■ 原始碼 | https://github.com/remega/OMCNN_2CLSTM

▲ 圖1. 本文海報
背景
和圖片顯著性檢測不同,現在很少有基於深度學習的影片顯著性檢測方法。這其中有很大一部分原因是由於缺乏眼動資料,而採集人眼在影片中的視覺關註點是一件開銷很大的事情。
如圖 2 所示,已有的資料普遍規模較小,且存在一些如解析度不高,關註點取樣率低的問題。而大規模眼動資料庫如 Hollywood(Mathe and Sminchisescu, 2015)中的影片是任務驅使的(task-driven),均是用於動作識別任務的電影片段,而不是普適性影片(general videos)。相比於任務驅使的顯著性檢測,普適性影片的顯著性檢測有更多應用場景,然而此類顯著性檢測方法和資料庫都十分匱乏。
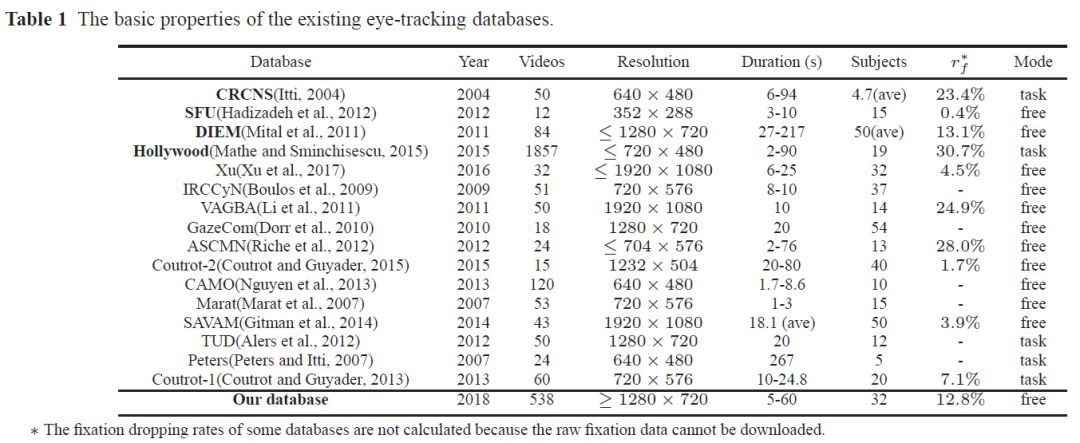
▲ 圖2. 已有眼動資料庫總結
資料庫與分析
為了保證影片內容的豐富性,我們粗糙構造了基於影片內容關鍵字的動態樹,並基於此在 Youtube 上下載影片,並基於實際情況修改動態樹。最終動態樹結構見圖 3,共計 158 個影片子類,538 個影片片段(部分實體見圖 4)。

▲ 圖3. 動態樹

▲ 圖4. LEDOV影片庫樣例
之後,使用 Tobii TX300 眼動儀採集 32 個被試者在這些影片上的人眼視覺關註點,共計採集 5,058,178 個關註點。
基於採集到的眼動資料,我們進行了資料分析,得到了 3 個非常直觀的發現:1)顯著性與物體相關性較高;2)顯著性與運動的物體以及物體中的運動部位相關性高;3)顯著性在幀間會存在平滑的轉移。資料分析見圖 5。

▲ 圖5. 資料庫分析
方法
為此,我們根據第一二點發現提出了 CNN 結構,OM-CNN(結構見圖 6)。

▲ 圖6. OM-CNN結構
此網路由 Objectness subnet 與 Motion subnet 構成,其中 Objectness subnet 使用了 YOLO 的結構和預訓練引數,用於提取帶有物體資訊的空間特徵。Motion subnet 使用 FlowNet 的結構和預訓練引數,用於提取帶有運動資訊的空間特徵。
為了讓網路在提取運動特徵的時候更加關註在物體區域上(發現 2),我們利用 Objectness subnet 的輸出特徵作為輸入,生成了一個 cross-net mask 作用在 Motion subnet 的摺積層上。我們認為,在訓練過程中 cross-net mask 可以很好的表示物體區域。

▲ 圖7. Cross-net mask視覺化
圖 7 是對 cross-net mask 的一些視覺化結果,第一行是輸入幀,第二行是真實人眼關註點(Ground truth),第三行使我們演演算法的最終輸出,最後四行是在訓練過程中 cross-net mask 的變化。我們可以看到,cross-net mask 能逐漸定位到物體區域,且在之後訓練的過程中變化不大,與預期結果相似。
最終我們提取了兩個子網路的多尺度特徵,拼接在一起,來預測幀內的顯著性。值得註意的是,OM-CNN 與之後的動態結構是分開訓練的,此時的顯著圖僅用於訓練 OM-CNN,而 OM-CNN 的輸出特徵將被用於動態結構的輸入。
根據第三點發現,我們設計的動態結構 SS-ConvLSTM(見圖 8)。

▲ 圖8. SS-ConvLSTM結構
其主體結構是一個雙層的摺積 LSTM,用於產生畫素級的輸出。和傳統摺積 LSTM 不同的是,SS-ConvLSTM 考慮到了基於顯著性的先驗知識:中心先驗和稀疏先驗。中心先驗指的是人們在看影片或者圖片的時候往往容易關註到中心的位置。
為此,我們提出了 Center-bias Dropout(圖 9,詳細見原文)。

▲ 圖9. Center-bias Dropout
和普通 Dropout 不同,Center-bias Dropout 中所有畫素的 dropout rate 並不是相同的,而是基於一個 Center-bias map。簡單來說,中心區域畫素的 dropout rate 可以比邊界區域的 dropout rate 低很多。
稀疏先驗指的是人眼關註點會存在一定的稀疏性(見圖 11 第二行),而大部分已有演演算法忽視了這個稀疏性(見圖 11 的 4-13 行),產生過於稠密的顯著圖。為此,我們設計了基於稀疏性的損失函式(圖 10,詳細見原文)。

▲ 圖10. 基於稀疏性的損失函式
在這個損失函式中,不僅計算了顯著圖和人眼關註點圖的差異,同時計算了這兩張圖的灰度直方圖分佈的差異,使得訓練過程中,輸出顯著圖的稀疏度趨於真實情況。
結果
圖 11 與圖 12 分別展示 DeepVS 和 10 種對比演演算法在 LEDOV 上的主觀和客觀實驗結果。可以看到,DeepVS 生成的顯著圖更加接近人眼關註點。同時,在 AUC, NSS, CC, KL 這四種評價指標上,DeepVS 也優於對比演演算法。

▲ 圖11. 主觀實驗結果

▲ 圖12. 客觀實驗結果
原文也羅列了 DeepVS 和對比演演算法在另外兩個常用眼動資料庫 DIEM 和 SFU 上的實驗結果。DeepVS 仍超過所有對比演演算法,有不錯的泛化能力。圖 13 展示了 DeepVS 的溶解實驗,可以看出,DeepVS 中提出的網路結構或者元件均對最終的結果有所增益。

▲ 圖13. 溶解實驗

點選以下標題檢視更多論文解讀:
 #投 稿 通 道#
#投 稿 通 道#
讓你的論文被更多人看到
如何才能讓更多的優質內容以更短路徑到達讀者群體,縮短讀者尋找優質內容的成本呢? 答案就是:你不認識的人。
總有一些你不認識的人,知道你想知道的東西。PaperWeekly 或許可以成為一座橋梁,促使不同背景、不同方向的學者和學術靈感相互碰撞,迸發出更多的可能性。
PaperWeekly 鼓勵高校實驗室或個人,在我們的平臺上分享各類優質內容,可以是最新論文解讀,也可以是學習心得或技術乾貨。我們的目的只有一個,讓知識真正流動起來。
? 來稿標準:
• 稿件確系個人原創作品,來稿需註明作者個人資訊(姓名+學校/工作單位+學歷/職位+研究方向)
• 如果文章並非首發,請在投稿時提醒並附上所有已釋出連結
• PaperWeekly 預設每篇文章都是首發,均會新增“原創”標誌
? 投稿郵箱:
• 投稿郵箱:hr@paperweekly.site
• 所有文章配圖,請單獨在附件中傳送
• 請留下即時聯絡方式(微信或手機),以便我們在編輯釋出時和作者溝通
?
現在,在「知乎」也能找到我們了
進入知乎首頁搜尋「PaperWeekly」
點選「關註」訂閱我們的專欄吧
關於PaperWeekly
PaperWeekly 是一個推薦、解讀、討論、報道人工智慧前沿論文成果的學術平臺。如果你研究或從事 AI 領域,歡迎在公眾號後臺點選「交流群」,小助手將把你帶入 PaperWeekly 的交流群裡。

▽ 點選 | 閱讀原文 | 下載論文 & 原始碼
