前言
上一篇我們分析了查詢最佳化器的工作方式,其中包括:查詢最佳化器的詳細執行步驟、篩選條件分析、索引項最佳化等資訊。
本篇我們分析在我們執行的過程中幾個關鍵指標值的檢測。
透過這些指標值來分析陳述句的執行問題,並且分析其最佳化方式。
透過本篇我們可以學習到調優中經常利用的幾個利器!
廢話少說,開始本篇的正題。
技術準備
資料庫版本為SQL Server2008R2,利用微軟的一個更簡潔的案例庫(Northwind)進行分析。
利器一、IO統計
透過這個IO統計能為我們分析出當前查詢陳述句所要掃描的資料頁的數量。這裡面有幾個重要的概念,我們依次分析。
方法很簡單,一行程式碼搞定:
SET STATISTICS IO ON
來看個例子
SET STATISTICS IO ON
GO
SELECT * FROM Person.Contact

這裡可以看到這個陳述句對於資料表的操作次數,基於資料頁的掃描項。
所謂的資料頁就是資料庫的底層資料儲存方式,SQL Server以資料頁的形式儲存錶行資料。每個資料頁為8K,
8K=8192位元組-96位元組(頁頭)-36位元組(行偏移)=8060位元組
也就說一個資料頁儲存的純資料內容為8060位元組。
我們依次來解釋上面出現幾個讀取的概念:
邏輯讀
表示處理查詢所需要訪問頁的總數。也就是說要完成一個查詢陳述句需要讀取的資料頁的總數。
這裡的資料頁有可能來自記憶體,也有可能來自硬碟讀取。
物理讀
這個就是說來自硬碟讀取的資料頁數。我們知道SQL Server每次都會將讀取的資料頁盡可能存在於記憶體中,以方便下一次直接讀取,提升讀取速度。
所以在這裡關於儲存於記憶體中的資料頁下次訪問的機率,提出了一個指標:快取命中率
快取命中率=(邏輯讀—物理讀)/邏輯讀
提出這個指標的提出其實就是為了衡量記憶體中快取的資料頁的有效性。比如:假如快取與記憶體中的資料頁就使用一次就不使用了,對於這種就應該及時從記憶體中清除掉,畢竟對於記憶體資源來說是非常昂貴的。應該用它來快取命中率高的資料頁。
預讀
預讀其實就是SQL陳述句在最佳化的時候預先讀取到記憶體中的資料頁數。這個預先讀取的資料頁是提前評估出來的,也就是上一篇我們文章中介紹的查詢最佳化器要做的事情。
當然,這些預讀的資料頁有時候不是所有的都要用到,但是它基本能涵蓋到查詢用到的資料頁。
這裡要提示一下,預讀資料是透過另外一個執行緒進行讀取的和陳述句最佳化執行緒非用同一執行緒,並行執行,目的是快速獲取資料,提升查詢獲取的速度。
從這個指標我們可以分析出很多問題,來舉個例子:
我們新新增一張測試表,指令碼如下
–執行下麵指令碼新生成一張表
SELECT *
INTO NewOrders
FROM Orders
GO
–新增加一列
ALTER TABLE NewOrders
ADD Full_Details CHAR(2000) NOT NULL DEFAULT ‘full details’
GO
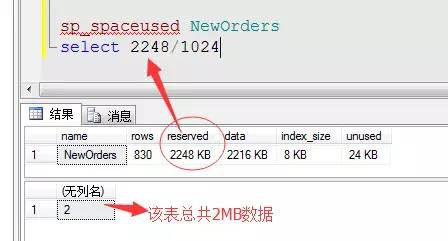
然後利用如下指令碼來看下這張表的大小
EXEC sp_spaceused NewOrders,TRUE
GO
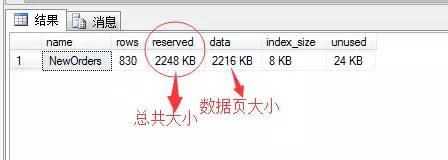
我們可以看到這張表資料頁的總大小為2216KB,我們知道一頁為8KB,可以推斷出這個表的資料頁有:
2216(資料頁總大小)/8(一個資料頁大小)=277頁
也就是說這個資料表有277個資料頁。
當然,我們也可以透過如下DMV檢視來檢視該頁的資料頁數
SELECT *
FROM SYS.dm_db_index_physical_stats
(DB_ID(‘Northwind’),object_id(‘NewOrders’),NULL,NULL,’detailed’)
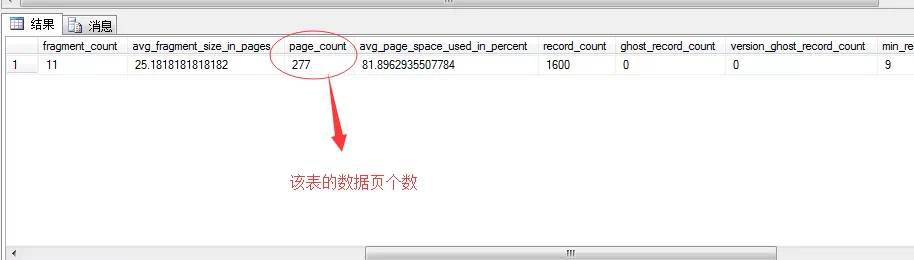
經過上面的分析,
我們可以推測,在查詢這張表做全表掃描的時候,理論的資料頁的邏輯讀數就應該為277次
透過如下陳述句驗證下
–先清空快取資料,生產機慎用
DBCC DROPCLEANBUFFERSSET STATISTICS IO ON
SELECT * FROM NewOrders
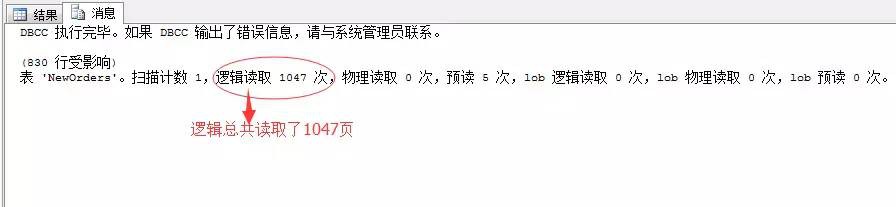
我去…
這裡的邏輯讀取為1047頁,和我們上面的推斷277頁不相符…擦…神馬原因!!!
這裡就是我們要分析的資料頁Forwarded record現象造成的。因為我們在新建立的表,在後面新新增的一列資料:Full_Details,型別為CHAR(2000)的資料列,當資料行中的變長列增長使得原有頁無法容納下資料行時,資料將會移動到新的頁中,併在原位置留下一個指向新頁的指標,這就是所謂的: Forwarded record
我們可以透過如下DMV檢視,檢視該表的Forwarded Record形成的頁有多少
SELECT *
FROM SYS.dm_db_index_physical_stats
(DB_ID(N’Northwind’),object_id(‘NewOrders’),NULL,NULL,’detailed’)

糾正一下:上圖的770資料頁為Forwarded Record頁,非拆分頁的概念(感謝院友 wy123 指出)。
看到了,這裡的Forwarded Record頁為770頁,那麼我們就可以推測出我們的邏輯讀數量來了
277(原資料頁)+770(Forwarded Record頁)=1047頁
所以上面的我們的問題就分析出原因了。
我們透過此表也展示了一個Forwarded Record頁的問題:會影響查詢效能。
解決的方式很多種,最簡單的方式就是重建聚集索引。
CREATE CLUSTERED INDEX orderID_C ON NewOrders(OrderID)
GO
DROP INDEX NewOrders.orderID_C
GO
SET STATISTICS IO ON
SELECT * FROM NewOrders
GO

透過IO統計項,除了可以分析出上面的Forwarded Record頁造成的碎片外,更重要的地方使用來對比不同查詢陳述句之間的讀取次數,透過降低讀取的次數來最佳化陳述句。
關於預讀的情況,我們在前面已經分析了,其資料時透過另外一個執行緒在T-SQL查詢陳述句最佳化的時候進行資料的預載入。
所以這個執行緒在預讀資料的時候其實是有一個參考值的,根據這個參考值讀取出來的資料才能保證大部分資料是有用的,也就是提高上面提到的快取命中率。
關於這個參考值,我分析了下,其實是分為兩中情況分析的。
首先、如果是資料表為堆表,SQL Server獲取的方式只能透過全表掃描了。而此方式為了避免重覆讀取,增加消耗,所以一次的預讀並非讀取一個資料頁,
而是一段物理上的連續64個頁
來看聯機叢書的官方解釋:
預讀機制允許資料庫引擎從一個檔案中讀取最多 64 個連續頁 (512KB)。該讀取作為緩衝區高速快取中相應數量(可能是非相鄰的)緩衝區的一次散播-聚集讀取來執行。如果此範圍內的任何頁在緩衝區高速快取中已存在,當讀取完成時,所讀取的相應頁將被放棄。如果相應頁在快取中已存在,也可以從任何一端“裁剪”頁的範圍。
所以,如果我們的表在物理上不是連續頁,那麼讀取次數就不好怎麼確定了。
我們來看個堆表的例子
SET STATISTICS IO ON
–新建個測試表
SELECT * INTO NewOrders_TEST FROM NewOrders
SELECT * FROM NewOrders_TEST

這裡預讀的次數為8次,所以我估計底層的資料頁肯定不是連續的。所以造成了多出了3次。
我們可以DBCC IND()進行查詢下,來驗證下我的推斷。
DBCC IND(‘Northwind’,’NewOrders_TEST’,1)
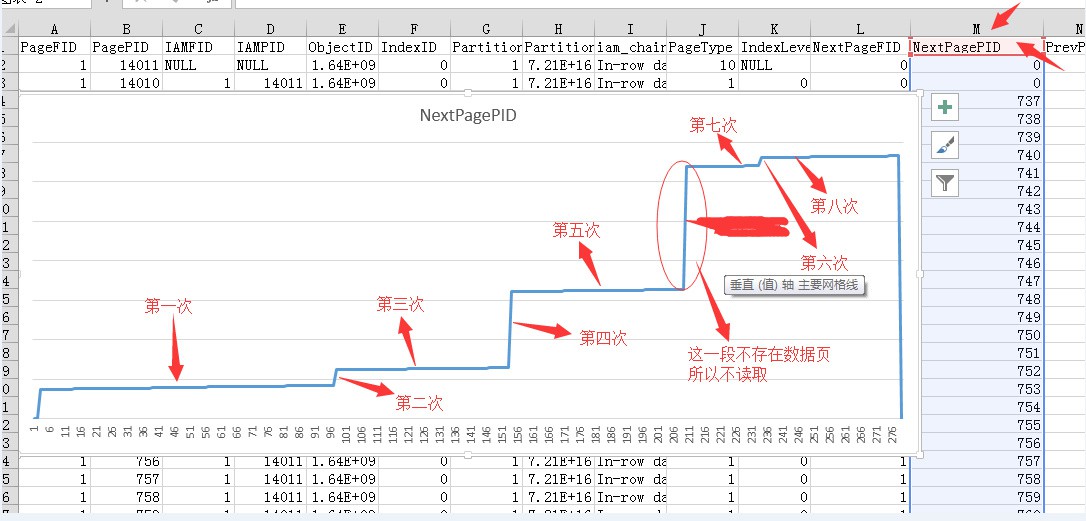
資料資訊比較多,我將其貼上到Excel中,然後做了一個折線圖,其中塗掉的部分其實是沒有資料頁的,所以不會產生一次讀取。
關於讀取順序標示的也有點問題,不過確定的總數肯定是8次…..
希望這種方式,各位看官能看懂了…希望我也表述明白了。
其次、如果表非堆表,也就是說存在聚集索引項,那麼好了,SQL Server很輕鬆的找到了它預讀的參考依據:統計資訊。
並且,我們知道資料以B-Tree數儲存,讀取的資料頁都存在與葉子節點。所以基本沒有了什麼連續讀取的感念。
一個葉子節點就是一個資料頁,一個資料頁就是一次預讀。
來看個例子:
我們將上面的表新增上聚集索引項,再一次清空快取,執行查詢,指令碼如下
CREATE CLUSTERED INDEX NewOrders_TESTIndex ON NewOrders_TEST(OrderID)
GO
SELECT * FROM NewOrders_TEST

這裡添加了聚集索引,SQL Server彷彿一下看到了救星,根據統計資訊,預讀資料就可以。
所以如果統計資訊有錯誤,就造成了預讀的亂讀取….然後嚴重降低了快取命中率…..然後嚴重增加了記憶體中換出換入的速度….增加了CPU….
好了,咱們繼續文章,上面我們提到的這個預讀資料行,可以在如下DMV中查到。
SELECT *
FROM SYS.dm_db_index_physical_stats
(DB_ID(N’Northwind’),object_id(‘NewOrders_TEST’),NULL,NULL,’detailed’)
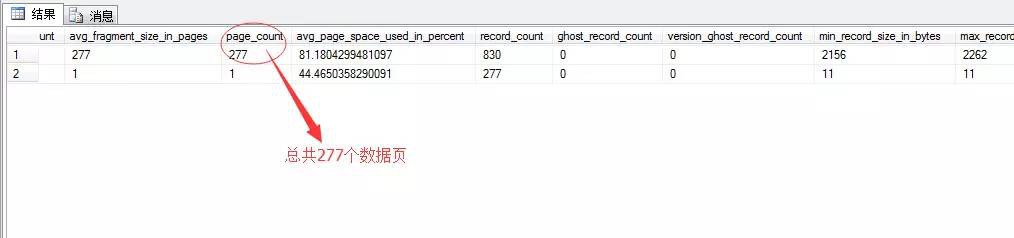
從這個DMV檢視中可以看到這種表統計資訊為277個資料頁,所以形成了277次預讀。
但是,事實這個資料表是279頁,也就是說統計的資訊有問題,造成了少讀讀取了2個資料頁,而為了彌補這個統計過失就出現了2次物理讀,重新從硬碟中獲取。
利器二、時間統計
關於時間統計這個很簡單,就是統計T-SQL執行陳述句執行時間項,包括CPU佔用時間、陳述句編譯時間、陳述句執行總時間等項。
使用方法也很簡單,一行程式碼
SET STATISTICS TIME ON
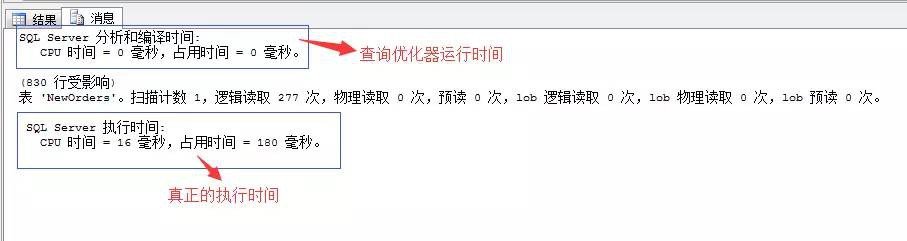
透過這個引數,可以分析出以上資訊,其作用主要是用來對比查詢陳述句調優中的執行時間,我們的標的就是降低執行時間。
舉例:我們透過開啟時間統計,來對比下,上面的查詢陳述句,在第一次執行和以後執行(資料已經快取)的時間對比,瞭解下快取的重要性
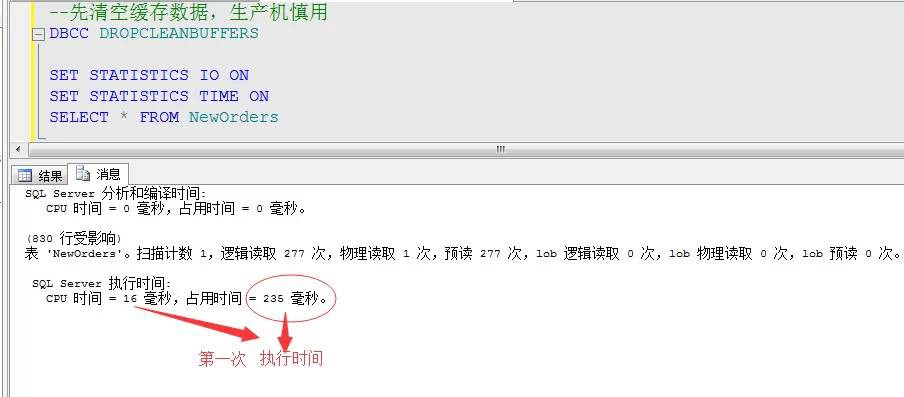
再次執行的時間
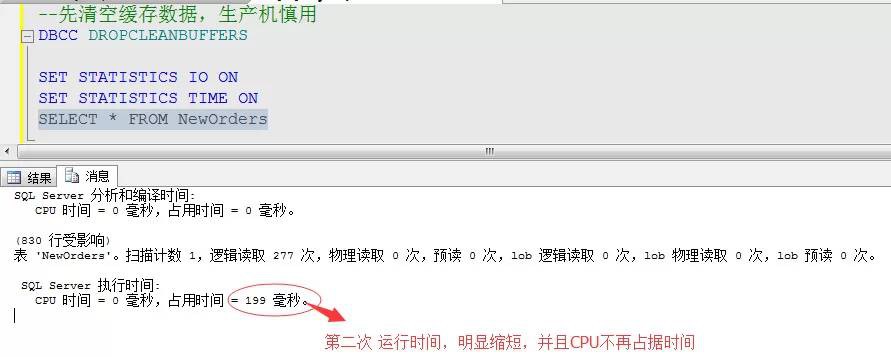
快取追蹤(補充於2014年12月25日)
當然我們也可以再深入一點,如果想檢視該部分資料在記憶體中快取的明細,可以透過如下DMV指令碼檢視
SELECT * FROM sys.dm_os_buffer_descriptors
WHERE DB_NAME(database_id)=’Northwind’
AND page_type=’DATA_PAGE’
ORDER BY page_id
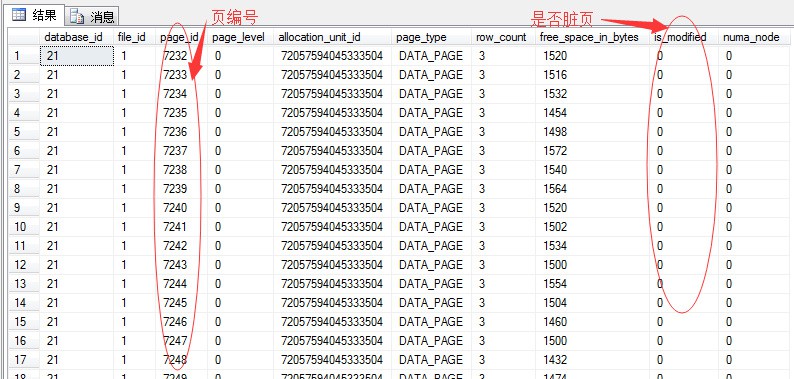
也可以透過該DMV分析出各個庫在記憶體中佔據的大小比例,指令碼如下:
–清除快取
dbcc dropcleanbuffers
–檢視快取內容中在記憶體大小
SELECT COUNT(*)*8/1024 as ‘Cached Size(MB)’
,CASE database_id
WHEN 32767 THEN ‘ResourceDB’
ELSE DB_NAME(database_id)
END AS ‘Database’
FROM sys.dm_os_buffer_descriptors
GROUP BY DB_NAME(database_id),database_id
ORDER BY ‘Cached Size(MB)’ DESC
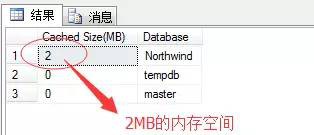
經過這次查詢,這張表已經全部快取到記憶體裡了,因為整張表總共就2MB的大小
文章已經有點長度了…先到此吧。
關於調優內容太廣泛,我們放在以後的篇幅中介紹,有興趣的可以提前關註。
參考文獻
微軟聯機叢書讀取頁
參照書籍《SQL.Server.2005.技術內幕》系列
有問題可以留言或者私信,隨時恭候有興趣的童鞋加入SQL SERVER的深入研究。共同學習,一起進步。
原文出處: 指尖流淌-吳學雷的部落格
原文連結: http://www.cnblogs.com/zhijianliutang/p/4179110.html