前言
上幾篇文章我們介紹瞭如何檢視查詢計劃的方式、常用運運算元(連線運運算元、聯合運運算元)的介紹、並行運算的方式(1、2),有興趣的可以點選檢視。 本篇將分析在SQL Server中,如何利用先有索引項進行查詢效能最佳化,透過瞭解這些索引項的應用方式可以指導我們如何建立索引、調整我們的查詢陳述句,達到效能最佳化的目的。 閑言少敘,進入本篇的正題。
技術準備 基於SQL Server2008R2版本,利用微軟的一個更簡潔的案例庫(Northwind)進行解析。
簡介 所謂的索引應用就是在我們日常寫的T-SQL陳述句中,如何利用現有的索引項,再分析的話就是我們所寫的查詢條件,其實大部分情況也無非以下幾種:
1、等於謂詞:select …where…column=@parameter
2、比較謂詞:select …where…column> or < or <> or <= or >= @parameter
3、範圍謂詞:select …where…column in or not in or between and @parameter
4、邏輯謂詞:select …where…一個謂詞 or、and 其它謂詞 or、and 更多謂詞…. 我們就依次分析上面幾種情況下,如何利用索引進行查詢最佳化的
一、動態索引查詢
所謂的動態索引查詢就是SQL Server在執行陳述句的時候,才格式化查詢條件,然後根據查詢條件的不同自動的去匹配索引項,達到效能提升的目的。 來舉個例子
SET SHOWPLAN_TEXT ON
GO
SELECT OrderID
FROM Orders
WHERE ShipPostalCode IN (N’05022′,N’99362′)
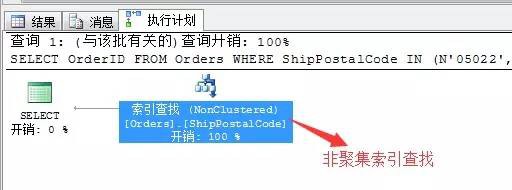
因為我們在表Orders的列ShipPostalCode列中建立了非聚集索引列,所以這裡查詢的計劃利用了索引查詢的方式。這也是需要建立索引的地方。 我們來利用文字的方式來檢視該陳述句的詳細的執行計劃指令碼,陳述句比較長,我用記事本換行,格式化檢視
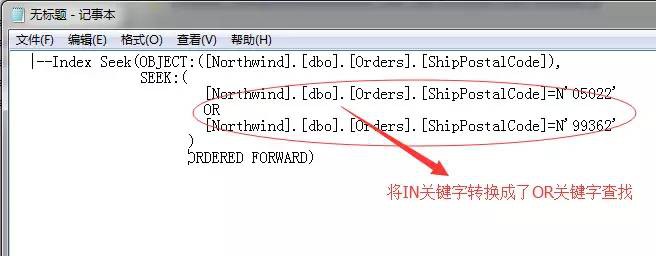
我們知道這張表的該列裡存在一個非聚集索引,所以在查詢的時候要儘量使用,如果透過索引掃描的方式消耗就比價大了,所以SQL Server儘量想採取索引查詢的方式,其實IN關鍵字和OR關鍵字邏輯是一樣的。
於是上面的查詢條件就轉換成了:
[Northwind].[dbo].[Orders].[ShipPostalCode]=N’05022′
OR
[Northwind].[dbo].[Orders].[ShipPostalCode]=N’99362′
這樣就可以採用索引查找了,先查詢第一個結果,然後再查詢第二個,而這個過程在SQL Server中就被稱為:動態索引查詢。
是不是有點智慧的感覺了….
所以有時候我們寫陳述句的時候,儘量要使用SQL Server的這點智慧了,讓其能自動的查詢到索引,提升效能。
有時候偏偏我們寫的陳述句讓SQL Server的智慧消失,舉個例子:
–引數化查詢條件
DECLARE @Parameter1 NVARCHAR(20),@Parameter2 NVARCHAR(20)
SELECT @Parameter1=N’05022′,@Parameter2=N’99362′
SELECT OrderID
FROM Orders
WHERE ShipPostalCode IN (@Parameter1,@Parameter2)
我們將這兩個靜態的篩序值改成引數,有時候我們寫的儲存過程灰常喜歡這麼做!我們來看這種方式的生成的查詢計劃
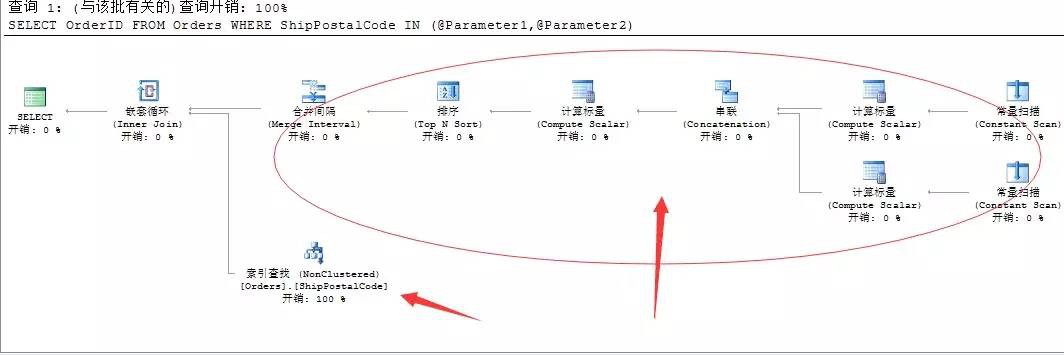
本來很簡單的一個非聚集索引查詢搞定的執行計劃,我們只是將這兩個數值沒有直接寫入IN關鍵字中,而是利用了兩個變數來代替。
看看上面SQL Server生成的查詢計劃!尼瑪…這都是些啥???還用起來巢狀迴圈,我就查詢了一個Orders表…你巢狀迴圈個啥….上面動態索引查詢的能力去哪了??? 好吧,我們用文字查詢計劃來檢視下,這個簡單的陳述句到底在幹些啥…
|–Nested Loops(Inner Join, OUTER REFERENCES:([Expr1009], [Expr1010], [Expr1011]))
|–Merge Interval
| |–Sort(TOP 2, ORDER BY:([Expr1012] DESC, [Expr1013] ASC, [Expr1009] ASC, [Expr1014] DESC))
| |–Compute Scalar(DEFINE:([Expr1012]=((4)&[Expr1011]) = (4) AND NULL = [Expr1009], [Expr1013]=(4)&[Expr1011], [Expr1014]=(16)&[Expr1011]))
| |–Concatenation
| |–Compute Scalar(DEFINE:([Expr1004]=[@Parameter2], [Expr1005]=[@Parameter2], [Expr1003]=(62)))
| | |–Constant Scan
| |–Compute Scalar(DEFINE:([Expr1007]=[@Parameter1], [Expr1008]=[@Parameter1], [Expr1006]=(62)))
| |–Constant Scan
|–Index Seek(OBJECT:([Northwind].[dbo].[Orders].[ShipPostalCode]), SEEK:([Northwind].[dbo].[Orders].[ShipPostalCode] > [Expr1009] AND [Northwind].[dbo].[Orders].[ShipPostalCode] < [Expr1010]) ORDERED FORWARD)
挺複雜的是吧,其實我分析了一下指令碼,關於為什麼會生成這個計劃指令碼的原因,是為瞭解決如下幾個問題:
1、前面我們寫的指令碼在IN裡面寫的是兩個常量值,並且是不同的值,所以形成了兩個索引值的查詢透過OR關鍵字組合, 這種方式貌似沒問題,但是我們將這兩個數值變成了引數,這就引來了新的問題,假如這兩個引數我們輸入的是相等的,那麼利用前面的執行計劃就會生成如下
[Northwind].[dbo].[Orders].[ShipPostalCode]=N’05022′
OR
[Northwind].[dbo].[Orders].[ShipPostalCode]=N’05022′
這樣執行產生的輸出結果就是2條一樣的輸出值!…但是表裡面確實只有1條資料…所以這樣輸出結果不正確! 所以變成引數後首先解決的問題就是去重問題,2個一樣的變成1個。
2、上面變成引數,還引入了另外一個問題,加入我們兩個值有一個傳入的為Null值,或者兩個都為Null值,同樣輸出結果面臨著這樣的問題。所以這裡還要解決的去Null值的問題。 為瞭解決上面的問題,我們來粗略的分析一下執行計劃,看SQL Server如何解決這個問題的
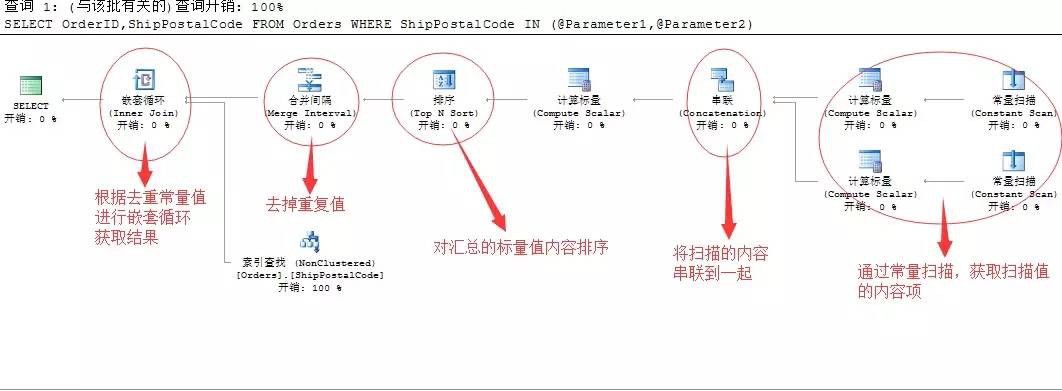
簡單點將就是透過掃描變數中的值,然後將內容進行彙總值,然後在進行排序,再將引數中的重覆值去掉,這樣獲取的值就是一個正確的值,最後拿這些去重後的引數值參與到巢狀迴圈中,和表Orders進行索引查詢。
但是分析的過程中,有一個問題我也沒看明白,就是最好的經過去重之後的常量彙總值,用來巢狀迴圈連線的時候,在下麵的索引查詢的時候的過濾條件變成了 and 查詢
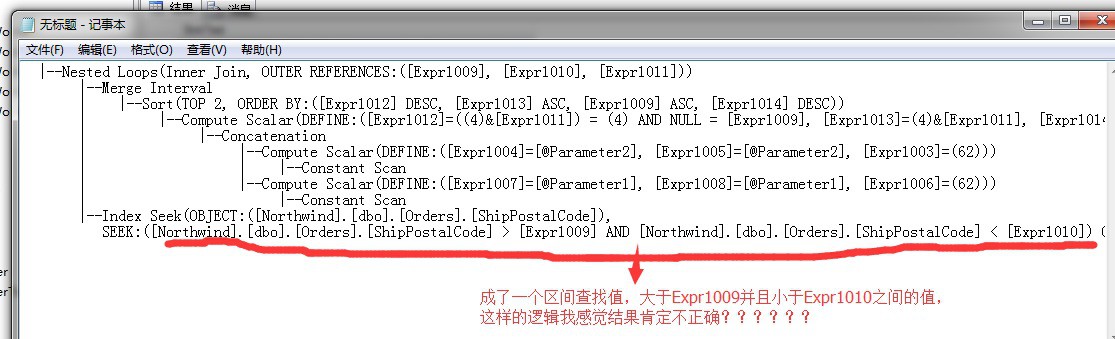
我將上面的最後的索引查詢條件,整理如下:
|–Index Seek(OBJECT:([Northwind].[dbo].[Orders].[ShipPostalCode]), SEEK:
(
[Northwind].[dbo].[Orders].[ShipPostalCode] > [Expr1009]
AND
[Northwind].[dbo].[Orders].[ShipPostalCode] < [Expr1010]
) ORDERED FORWARD)
這個地方怎麼搞的?我也沒弄清楚,還望有看明白童鞋的稍加指導下….
好了,我們繼續
上面的執行計劃中,提到了一個新的運運算元:合併間隔(merge interval operator)
我們來分析下這個運運算元的作用,其實在上面我們已經在執行計劃的圖中標示出該運運算元的作用了,去掉重覆值。
其實關於去重的操作有很多的,比如前面文章中我們提到的各種去重操作。
這裡怎麼又冒出個合併間隔去重?其實原因很簡單,因為我們在使用這個運運算元之前已經對結果進行了排序操作,排序後的結果項重覆值是緊緊靠在一起的,所以就引入了合併間隔的方式去處理,這樣效能是最好的。
更重要的是合併間隔這種運運算元應用場景不僅僅侷限於重覆值的去除,更重要的是還應用於重覆區間的去除。 來看下麵的例子
–引數化查詢條件
DECLARE @Parameter1 DATETIME,@Parameter2 DATETIME
SELECT @Parameter1=’1998-01-01′,@Parameter2=’1998-01-04′
SELECT OrderID
FROM ORDERS
WHERE OrderDate BETWEEN @Parameter1 AND DATEADD(DAY,6,@Parameter1)
OR OrderDate BETWEEN @Parameter2 AND DATEADD(DAY,6,@Parameter2)
我們看看這個生成的查詢計劃項
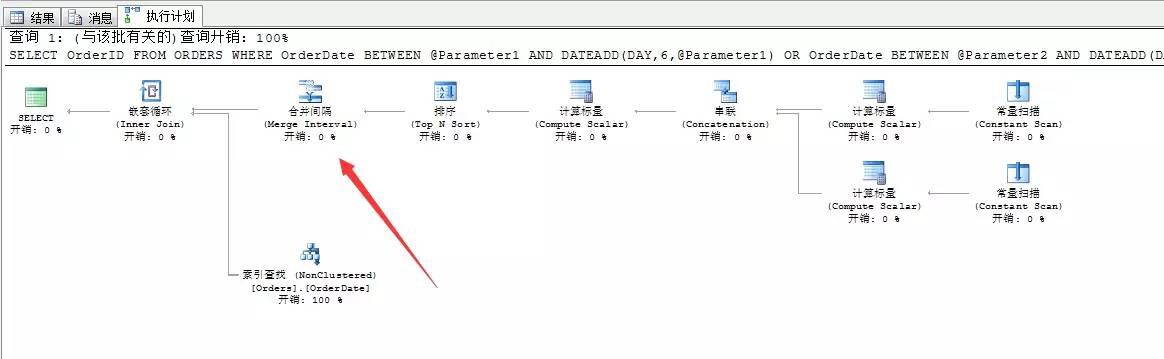
可以看到,SQL Server為我們生成的查詢計劃,和前面我們寫的陳述句是一模一樣的,當然我們的陳述句也沒做多少改動,改動的地方就是查詢條件上。
我們來分析下這個查詢條件:
WHERE OrderDate BETWEEN @Parameter1 AND DATEADD(DAY,6,@Parameter1)
OR OrderDate BETWEEN @Parameter2 AND DATEADD(DAY,6,@Parameter2)
很簡單的篩選條件,要獲取訂單日期在1998-01-01開始到1998-01-07內的值或者1998-01-04開始到1998-01-10內的值(不包含開始日期)
這裡用的邏輯謂詞為:OR…其實也就等同於我們前面寫的IN
但是我們這裡再分析一下,你會發現這兩個時間段是重疊的

這個重覆的區間值,如果用到前面的直接索引查詢,在這段區間之內的搜尋出來的範圍值就是重覆的,所以為了避免這種問題,SQL Server又引入了“合併間隔”這個運運算元。
其實,經過上面的分析,我們已經分析出這種動態索引查詢的優缺點了,有時候我們為了避免這種複雜的執行計劃生成,使用最簡單的方式就是直接傳值進入陳述句中(當然這裡需要重編譯),當然大部分的情況我們寫的程式都是隻定義的引數,然後進行的運算。可能帶來的麻煩就是上面的問題,當然有時候引數多了,為了合併間隔所應用的排序就消耗的記憶體就會增長。怎麼使用,根據場景自己酌情分析。
二、索引聯合 所謂的索引聯合,就是根據就是根據篩選條件的不同,拆分成不同的條件,去匹配不同的索引項。 舉個例子
SELECT OrderID
FROM ORDERS
WHERE OrderDate BETWEEN ‘1998-01-01’ AND ‘1998-01-07’
OR ShippedDate BETWEEN ‘1998-01-01’ AND ‘1998-01-07’
這段程式碼是查詢出訂單中的訂單日期在1998年1月1日到1998年1月7日的或者發貨日期同樣在1998年1月1日到1998年1月7日的。
邏輯很簡單,我們知道在這種表裡面這兩個欄位都有索引項。所以這個查詢在SQL Server中就有了兩個選擇:
1、一次性的來個索引掃描根據匹配結果項輸出,這樣簡單有效,但是如果訂單表資料量比較大的話,效能就會很差,因為大部分資料就根本不是我們想要的,還要浪費時間去掃描。
2、就是透過兩列的索引欄位直接查詢獲取這部分資料,這樣可以直接減少資料表的掃描量,但是帶來的問題就是,如果分開掃描,有一部分資料就是重覆的:那些同時在1998年1月1日到1998年1月7日的訂單,發貨日期也在這段時間內,因為兩個掃描項都包含,所以再輸出的時候需要將這部分重覆資料去掉。
我們來看SQL Server如何選擇
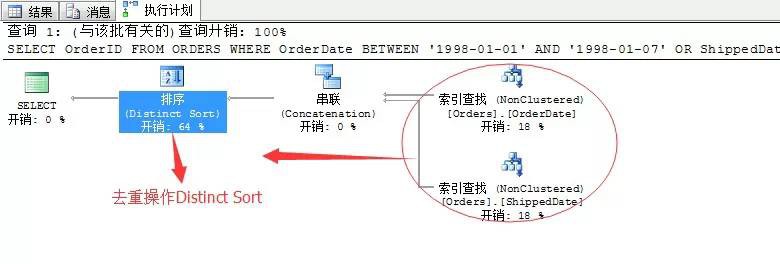 看來SQL Server經過
看來SQL Server經過
評估選擇了第2中方法。但是上面的方法也不盡完美,採用去重操作耗費了64%的資源。
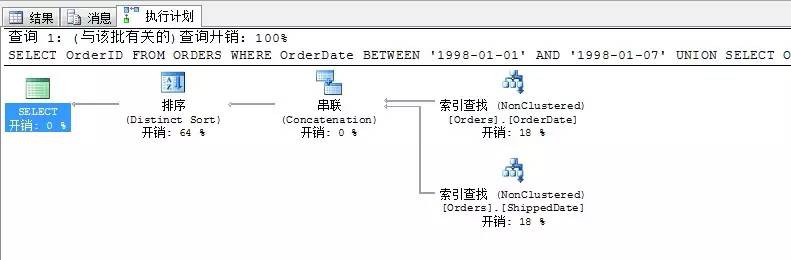
其實,上面的方法,我們根據生成的查詢計劃可以變通的使用以下邏輯,其效果和上面的陳述句是一樣的,並且生成的查詢計劃也一樣
SELECT OrderID
FROM ORDERS
WHERE OrderDate BETWEEN ‘1998-01-01’ AND ‘1998-01-07’
UNION
SELECT OrderID
FROM ORDERS
WHERE ShippedDate BETWEEN ‘1998-01-01’ AND ‘1998-01-07’
我們再來看一個索引聯合的例子
SELECT OrderID
FROM ORDERS
WHERE OrderDate = ‘1998-01-01’
OR ShippedDate = ‘1998-01-01’
我們將上面的Between and不等式篩選條件改成等式篩選條件,我們來看一下這樣形成的執行計劃
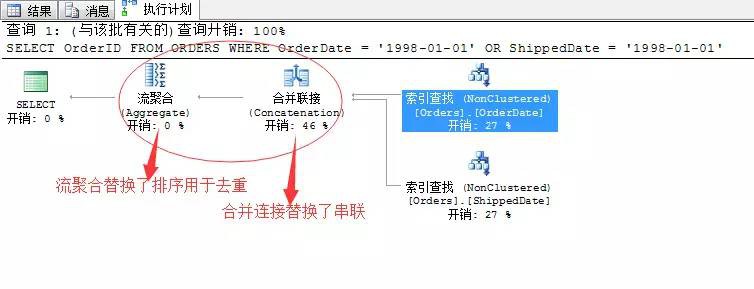
基本相同的陳述句,只是我們改變了不同的查詢條件,但是生成的查詢計劃還是變化蠻大的,有幾點不同之處:
1、前面的用between…and 的篩選條件,透過索引查詢傳回的值進行組合是用的串聯的方式,所謂的串聯就是兩個資料集拼湊在一起就行,無所謂順序連線什麼的。
2、前面的用between…and 的篩選條件,透過串聯拼湊的結果集去重的方式,是排序去重(Sort Distinct)…並且耗費了大量的資源。這裡採用了流聚合來乾這個事,基本不消耗
我們來分析以下產生著兩點不同的原因有哪些:
首先、這裡改變了篩選條件為等式連線,所透過索引查詢所產生的結果項是排序的,並且按照我們所要查詢的OrderID列排序,因此在兩個資料集進行彙總的時候,正適合合併連線的條件!需要提前排序。所以這裡最優的方式就是採用合併連線!
那麼前面我們用between…and 的篩選條件透過索引查詢獲取的結果項也是排序的,但是這裡它沒有按照OrderID排序,它是按照OrderDate或者ShippedDate列排序的,而我們的結果是要OrderID列,所以這裡的排序是沒用的……所以SQL Server只能選擇一個串聯操作,將結果匯聚到一起,然後在排序了……我希望這裡我已經講明白了…
其次、關於去重操作,毫無疑問採用流聚合(Aggregate)這種方式最好,消耗記憶體少,速度又快…但是前提是要提前排序…前面選用的排序去重(Sort Distinct)純屬無奈之舉…
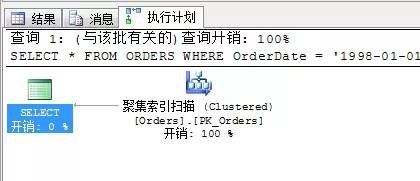
總結下:我們在寫陳述句的時候能確定為等式連線,最好採用等式連線。還有就是如果能確定輸出條件的最好能寫入,避免多餘的書簽查詢,還有萬惡的SELEECT *….
如果寫了萬惡的SELECT *…那麼你所寫的陳述句基本上就可以和非聚集索引查詢告別了….頂多就是聚集索引掃描或者RID查詢…
瞅瞅以下陳述句
SELECT *
FROM ORDERS
WHERE OrderDate = ‘1998-01-01’
OR ShippedDate = ‘1998-01-01’
最後,奉上一個AND的一個連線謂詞的操作方式,這個方式被稱為:索引交叉,意思就是說如果兩個或多個篩選條件如果採用的索引是交叉進行的,那麼使用一個就可以進行查詢。 來看個陳述句就明白了
SELECT OrderID
FROM ORDERS
WHERE OrderDate = ‘1998-01-01’
AND ShippedDate = ‘1998-03-05’
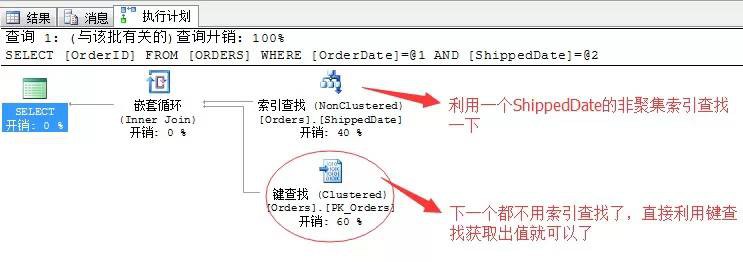
這裡我們採用了的謂詞連線方式為AND,所以在實際執行的時候,雖然兩列都存在非聚集索引,理論都可以使用,但是我們只要選一個最優的索引進行查詢,另外一個直接使用書簽查找出來就可以。省去了前面介紹的各種神馬排序去重….流聚合去重….等等不人性的操作。 看來AND連線符是一個很帥的運運算元…所以很多時候我們在嘗試寫OR的情況下,不如換個思路改用AND更高效。
參考文獻
微軟聯機叢書邏輯運運算元和物理運運算元取用
參照書籍《SQL.Server.2005.技術內幕》系列
結語 此篇文章主要介紹了索引運算的一些方式,主要是描述了我們平常在寫陳述句的時候所應用的方式,並且舉了幾個例子,算作拋磚引玉吧,其實我們平常所寫的陳述句中無非也就本篇文章中介紹的各種方式的更改,拼湊。而且根據此,我們該怎樣建立索引也作為一個指導項。 下一篇我們介紹子查詢一系列的內容,有興趣可提前關註,關於SQL Server效能調優的內容涉及面很廣,後續文章中依次展開分析。 有問題可以留言或者私信,隨時恭候有興趣的童鞋加入SQL SERVER的深入研究。共同學習,一起進步。
原文出處: 指尖流淌-吳學雷的部落格
原文連結: http://www.cnblogs.com/zhijianliutang/p/4158467.html