前言
上三篇文章我們介紹了檢視查詢計劃的方式,以及一些常用的連線運運算元、聯合運運算元的最佳化技巧。
本篇我們分析SQL Server的並行運算,作為多核計算機盛行的今天,SQL Server也會適時調整自己的查詢計劃,來適應硬體資源的擴充套件,充分利用硬體資源,最大限度的提高效能。
閑言少敘,直接進入本篇的正題。
技術準備
同前幾篇一樣,基於SQL Server2008R2版本,利用微軟的一個更簡潔的案例庫(Northwind)進行解析。
一、並行運運算元
在我們日常所寫的T-SQL陳述句,並不是所有的最優執行計劃都是一樣的,其最優的執行計劃的形成需要多方面的評估才可以,大部分根據SQL Server本身所形成的統計資訊,然後對形成的多個執行計劃進行評估,進而選出最優的執行方式。
在SQL Server根據庫內容形成的統計資訊進行評估的同時,還要參照當前執行的硬體資源,有時候它認為最優的方案可能當前硬體資源不支援,比如:記憶體限制、CPU限制、IO瓶頸等,所以執行計劃的優劣還要依賴於底層硬體。
當SQL Server發現某個處理的資料集比較大,耗費資源比較多時,但此時硬體存在多顆CPU時,SQL Server會嘗試使用並行的方法,把資料集拆分成若干個,若干個執行緒同時處理,來提高整體效率。
在SQL Server中可以透過如下方法,設定SQL Server可用的CPU個數
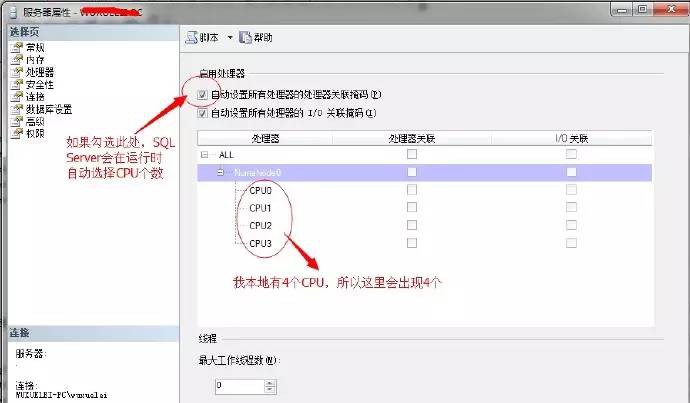
預設SQL Server會自動選擇CPU個數,當然不排除某些情況下,比如高併發的生產環境中,防止SQL Server獨佔所有CPU,所以提供了該配置的介面。
還有一個系統引數,就是我們熟知的MAXDOP引數,也可以更改此係統引數配置,該配置也可以控制每個運運算元的並行數(記住:這裡是每個運運算元的,而非全部的),我們來檢視該引數
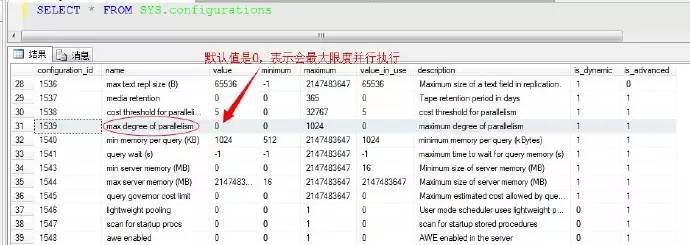
這個並行運運算元的設定數,指定的是每個運運算元的最大並行數,所以有時候我們利用檢視系統任務數的DMV檢視sys.dm_os_tasks來檢視,很可能看到大於並行度的執行緒資料量,也就是說執行緒資料可能超過並行度,原因就是兩個運運算元重新劃分了資料,分配到不同的執行緒中。
這裡如沒特殊情況的話,建議採用預設設定最佳。
我們舉一個分組的例子,來理解並行運算
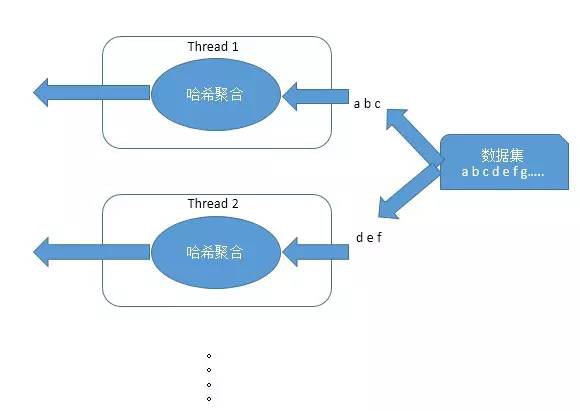
採用並行運算出了提升效能還有如下幾個優點:
不依賴於執行緒的數量,在執行時自動的新增或移除執行緒,在保證系統正常吞吐率的前提下達到一個效能最優值
能夠適應傾斜和負載均衡,比如一個執行緒執行速度比其它執行緒慢,這個執行緒要掃描或者執行的數量會自動減少,而其它跑的快的執行緒會相應提高任務數,所以總的執行時間就會平穩的減少,而非一個執行緒阻塞整體效能。
下麵我們來舉個例子,詳細的說明一下
並行計劃一般應用於資料量比較大的表,小表採用序列的效率是最高的,所以這裡我們新建一個測試的大表,然後插入部分測試資料,我們插入250000行,整體表超過6500頁,指令碼如下
–新建表,建立主鍵,形成聚集索引
CREATE TABLE BigTable
(
[KEY] INT,
DATA INT,
PAD CHAR(200),
CONSTRAINT [PK1] PRIMARY KEY ([KEY])
)
GO
–批次插入測試資料250000行
SET NOCOUNT ON
DECLARE @i INT
BEGIN TRAN
SET @i=0
WHILE @i<250000
BEGIN
INSERT BigTable VALUES(@i,@i,NULL)
SET @i=@i+1
IF @i%1000=0
BEGIN
COMMIT TRAN
BEGIN TRAN
END
END
COMMIT TRAN
GO
我們來執行一個簡單查詢的指令碼
SELECT [KEY],[DATA]
FROM BigTable

這裡對於這種查詢指令碼,沒有任何篩選條件的情況下,沒必要採用並行掃描,因為採用序列掃描的方式得到資料的速度反而比並行掃描獲取的快,所以這裡採用了clustered scan的方式,我們來加一個篩選條件看看
SELECT [KEY],[DATA]
FROM BigTable
WHERE DATA<1000
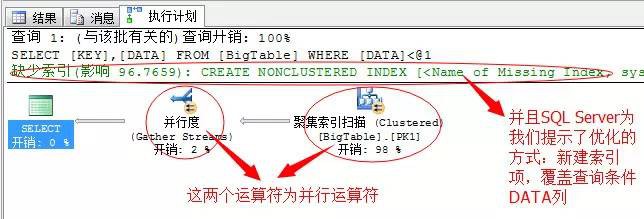
對於這個有篩選條件的T-SQL陳述句,這裡SQL Server果斷的採用的並行運算的方式,聚集索引也是並行掃描,因為我電腦為4個邏輯CPU(其實是2顆物理CPU,4執行緒),所以這裡使用的是4執行緒並行掃描四次表,每個執行緒掃描一部分資料,然後彙總。
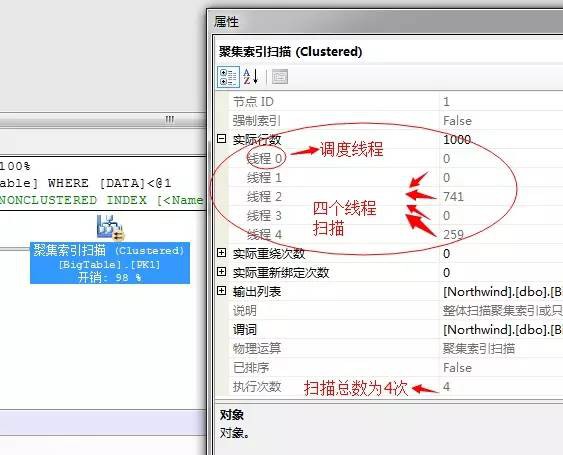
這裡總共用了4個執行緒,其中執行緒0為排程執行緒,負責排程所有的其它執行緒,所以它不執行掃描,而執行緒1到執行緒4執行了這1000行的掃描!當然這裡資料量比較少,有的執行緒分配了0個任務,但是總得掃描次數為4次,所以這4個執行緒是並行的掃描了這個表。
可能上面獲取的結果比較簡單,有的執行緒任務還沒有給分配滿,我們來找一個相對稍複雜的陳述句
SELECT MIN([DATA])
FROM BigTable
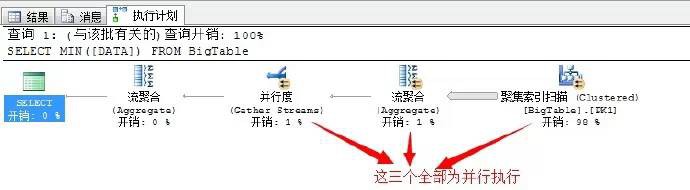
這個執行計劃挺簡單的,我們依次從右邊向左分析,依次執行為:
4個並行聚集索引掃描——>4個執行緒並行獲取出前當前執行緒的最小數——>執行4個最小數彙總——>執行流聚合獲取出4個數中的最小值——>輸出結果項。
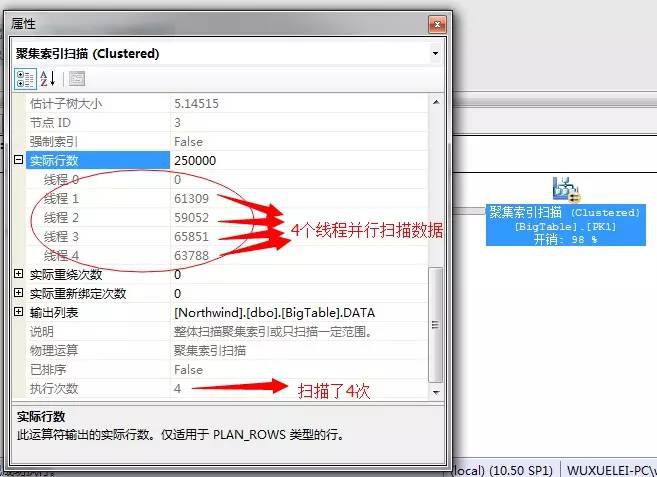
然後4個執行緒,每個執行緒一個流聚合獲取當前執行緒的最小數
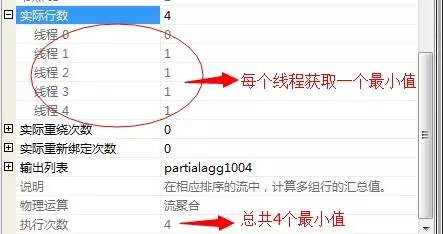
然後,將這個四個最小值經過下一個“並行度”的運運算元匯聚成一個表
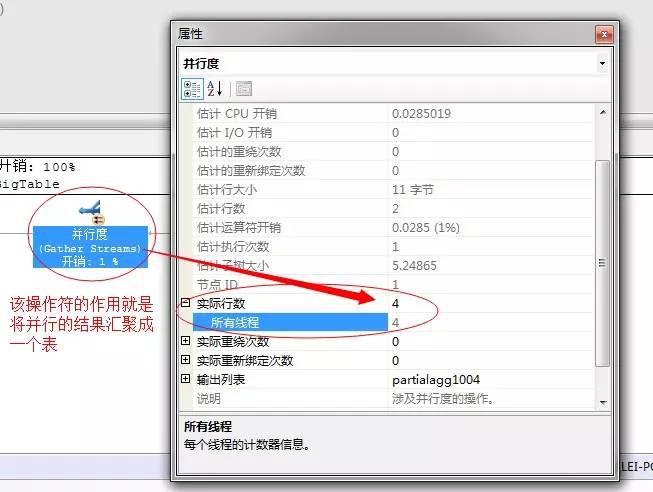
然後下一個就是流聚合,從這個4行資料中獲取出最小值,進行輸出,關於流聚合我們上一篇文章中已經介紹
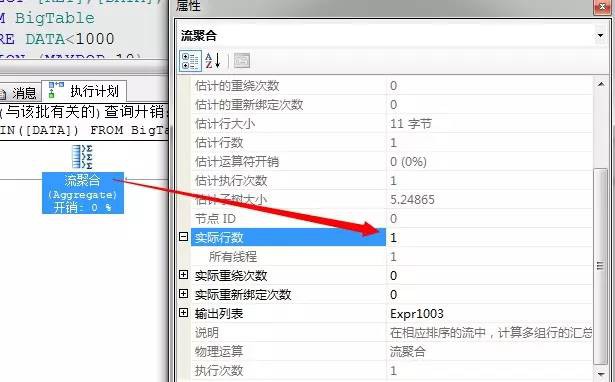
以上就一個一個標準的多執行緒並行運算的過程。
上面的過程中,因為我們使用的並行聚集索引掃描資料,4個執行緒基本上是平均分攤了任務量,也就是說每個執行緒掃描的資料量基本相等,下麵我們將一個執行緒使其處於忙碌狀態,看看SQL Server會不會將任務動態的平攤到其它幾個不忙碌的執行緒上。
我們在來新增一個大資料量表,指令碼如下
SELECT [KEY],[DATA],[PAD]
INTO BigTable2
FROM BigTable
我們來寫一個大量陳述句的查詢,使其佔用一個執行緒,並且我們這裡強制指定只用一個執行緒執行
SELECT MIN(B1.[KEY]+B2.[KEY])
FROM BigTable B1 CROSS JOIN BigTable2 B2
OPTION(MAXDOP 1)
以上程式碼想跑出結果,就我這個電腦配置估計少說五分鐘以上,並且我們還強行序列運算,速度可想而知,
我們接著執行上面的獲取最小值的陳述句,檢視執行計劃
SELECT MIN([DATA])
FROM BigTable
我們在執行計劃中,檢視到了聚集索引掃描的執行緒數量
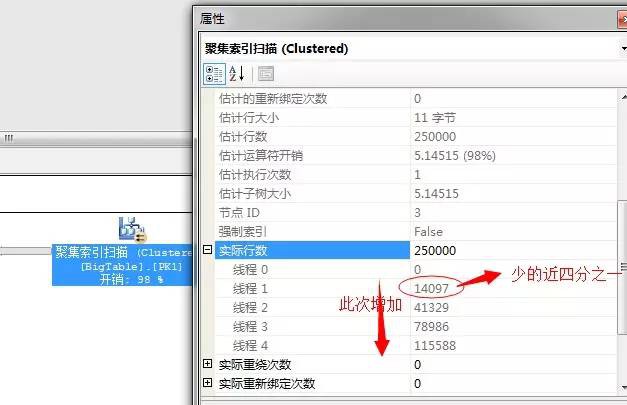
可以看到,執行緒1已經數量減少了近四分之的資料,並且從執行緒1到執行緒4,所掃描的資料量是依次增加的。
我們上面的陳述句很明確的指定了MAXDOP為1,理論上講只可能會影響一個執行緒,為什麼這幾個執行緒都影響呢?其實這個原因很簡單,我的電腦是物理CPU只有兩核,所謂的執行緒數只是超執行緒,所以非傳統意義上的真正的4核數,所以執行緒之間是互相影響的。
我們來看一個並行連線操作的例子,我們檢視並行巢狀迴圈是怎樣利用資源的
SELECT B1.[KEY],B1.DATA,B2.DATA
FROM BigTable B1 JOIN BigTable2 B2
ON B1.[KEY]=B2.[KEY]
WHERE B1.DATA<100
上面的陳述句中,我們在BigTable中Key列存在聚集索引,而查詢條件中DATA列不存在,所以這裡肯定為聚集索引掃描,對資料進行查詢
來看執行計劃
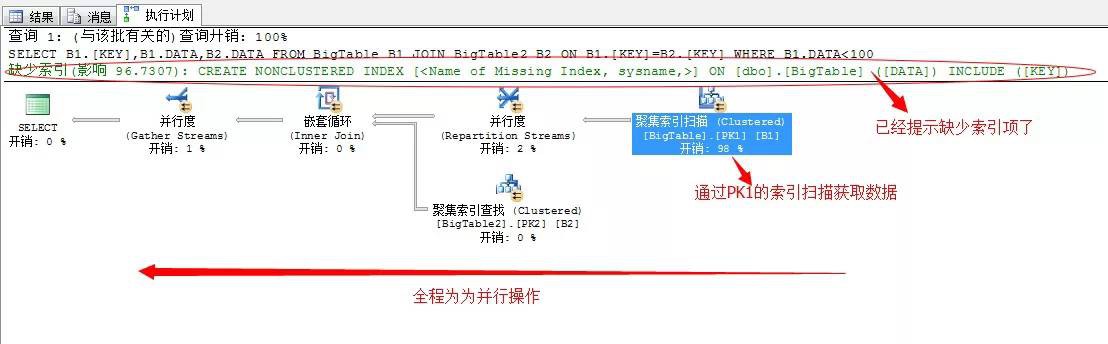
我們依次來分析這個流程,結合文字的執行計劃分析更為準確,從右邊依次向左分析

第一步,就是利用全表透過聚集索引掃描獲取出資料,因為這裡採用的並行的聚集索引掃描,我們來看並行的執行緒數和掃描數
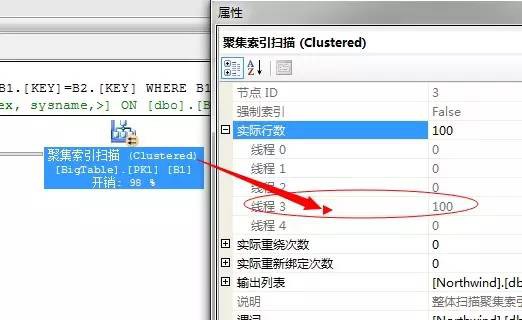
四個執行緒掃描,這裡執行緒3獲取出資料100行資料。
然後將這100行資料,重新分配執行緒,這裡每個執行緒平均分配到25行資料
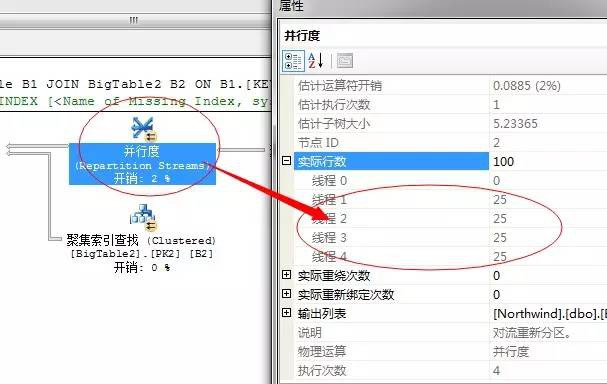
到此,我們要獲取的結果已經均分成4個執行緒共同執行,每個執行緒分配了25行資料,下一步就是交給巢狀迴圈連線了,因為我們上面的陳述句中需要從BigTable2中獲取資料行,所以這裡選擇了巢狀迴圈,依次掃描BigTable2獲取資料。
關於巢狀迴圈連線運運算元,可以參照我的第二篇文章。
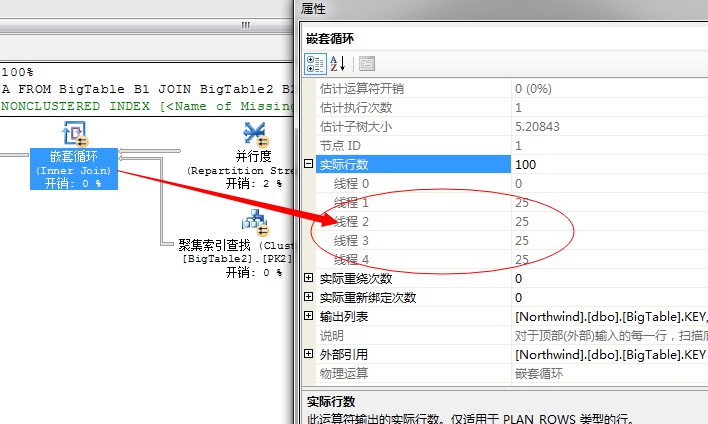
我們知道這是外表的迴圈數,也就是說這裡會有4個執行緒並行執行巢狀迴圈。如果每個執行緒均分25行,資料那麼內部表就要執行
4*25=100次。
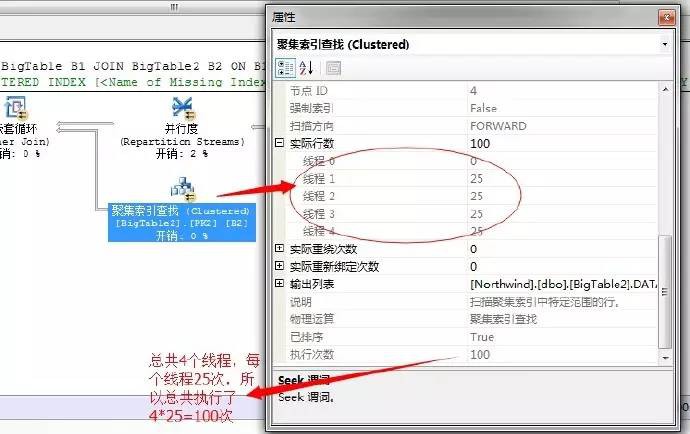
然後,執行完,巢狀掃描獲取結果後,下一步就是,將各個執行緒執行的結果透過並行運運算元彙總,然後輸出
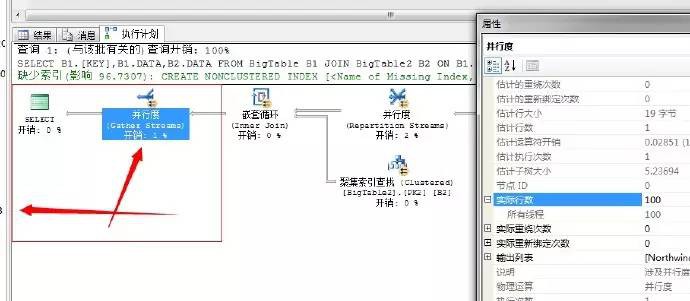
上述過程就是一個並行巢狀迴圈的執行流程。充分利用了四核的硬體資源。
參考文獻
微軟聯機叢書邏輯運運算元和物理運運算元取用
參照書籍《SQL.Server.2005.技術內幕》系列
結語
此篇文章先到此吧,文章短一點,便於理解掌握,後續關於並行操作還有一部分內容,後續文章補充吧,本篇主要介紹了查詢計劃中的並行運運算元,下一篇我們接著補充一部分SQL Server中的並行運算,然後分析下我們日常所寫的增刪改這些運運算元的最佳化項,有興趣可提前關註,關於SQL Server效能調優的內容涉及面很廣,後續文章中依次展開分析。
有問題可以留言或者私信,隨時恭候有興趣的童鞋加入SQL SERVER的深入研究。共同學習,一起進步。
原文出處: 指尖流淌-吳學雷的部落格
原文連結: http://www.cnblogs.com/zhijianliutang/p/4149850.html