前言
關於SQL Server調優系列是一個龐大的內容體系,非一言兩語能夠分析清楚,本篇先就在SQL 調優中所最常用的查詢計劃進行解析,力圖做好基礎的掌握,夯實基本功!而後再談談整體的陳述句調優。
透過本篇瞭解如何閱讀和理解查詢計劃、並且列舉一系列最常用的查詢執行運運算元。
技術準備
基於SQL Server2008R2版本,利用微軟的一個更簡潔的案例庫(Northwind)進行解析。
一、區別不同的運運算元
在所有T-SQL陳述句在執行的時候,都會將陳述句分解為一些基本的結構單元,這些結構單元統稱為:運運算元。每一個運運算元都實現一個單獨的基本操作,比如:表掃描、索引查詢、索引掃描、過濾等。每個運運算元可以迴圈迭代,也可以延續子運運算元,這樣就可以組成查詢樹,即:查詢計劃。
每個T-SQL陳述句都會透過多種運運算元進行組合形成不同的查詢計劃,並且這些查詢計劃對於結果的篩選都是有效的,但在執行的時候,SQL Server的查詢最佳化器會自動為我們找到一個最優的。
每一個運運算元都會有源資料的傳入和結果資料的輸出,源資料的輸入可以來源於其它的運運算元或者直接從資料源表中讀取,經過本身的運算進行結果的輸出。所以每一個運運算元是獨立的。互不關心的。
如下例子
SELECT COUNT(*) FROM Orders
此陳述句會生成兩個簡單的運運算元
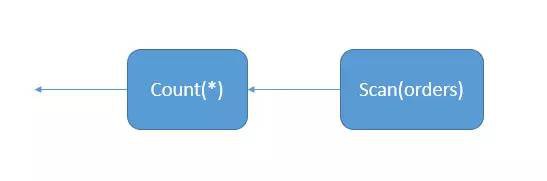
當然,在SQL Server中上述的兩個運運算元有它自己的表達方式,Count(*)是流聚合運運算元進行的。
每一個運運算元會有三個屬性影響其執行的效率
1、記憶體消耗
所有的運運算元都需要一定量的固定記憶體用以完成執行。當一個T-SQL陳述句經過編譯後生成查詢計劃後,SQL Server會為認為最優的查詢計劃嘗試去固定記憶體,目的是為了再次執行的時候不需要再重新申請記憶體而浪費時間,加快執行速度。
然後,有一些運運算元需要額外的記憶體空間來儲存行資料,這樣的運運算元所需要的記憶體量通常就和處理的資料行數成正比。如果出現如下幾種情況則會導致記憶體不能申請到,而影響執行效能
a、如果伺服器上正在執行其它的類似的記憶體消耗巨大的查詢,導致系統記憶體剩餘不足的時候,當前的查詢就得延遲進行,直接影響效能。
b、當併發量過大的的情況下,多個查詢競爭有限的記憶體資源,伺服器會適當的控制併發和減少吞吐量來維護機器效能,這時候同樣也會影響效能
c、如果當前申請的到可用記憶體很少的情況下,SQL Server會在執行過程中和磁碟進行交換資料,通常是使用Tempdb臨時庫進行操作,而這個過程會很慢。更有甚者,會耗盡Tempdb上的磁碟空間以失敗結束
通常比較消耗記憶體的運運算元主要有分類、雜湊連線以及雜湊聚合等連線操作。
2、阻斷運算和非阻斷運算
所謂阻斷和非阻斷的區別就是:運運算元是否在輸入資料的時候能夠直接輸出結果資料。
a、當一個運運算元在消耗輸入行的同時生成輸出行,這種運運算元就是非阻斷式的。
比如我們經常使用的 Select Top …操作,此操作就是輸入行的同時進行輸出行操作,所以此操作就是非阻斷式的。
b、當一個運運算元所產生的輸出結果需要等待所有的資料輸入的時候,這個操作運算就是阻斷運算的。
比如上面我們舉的例子Count(*)操作,此操作就需要等待所有的資料行輸入才能計算出,所以為阻斷式運算,另外還有分組計算。
提示:並不是所有的阻斷式操作就需要消耗記憶體,比如Count(*)就為阻斷式,但它不消耗記憶體,但大部分阻斷式操作都會消耗記憶體。
在大部分的OLTP系統中,我們要儘量的使用非阻斷式操作來代替阻斷式操作,這樣才能更好的提高相應時間,比如有時候我們用EXISTS子查詢來判斷,比用SELECT count(*)>0的速度要理想的多。
二、檢視查詢計劃
在SQL Server2005版本以上,系統提供了三種展示方式:影象方式、文字方式和XML方式。
1、影象方式
影象方式這種方式是最為常見的一種方式,清晰、簡潔、易懂。非常適合入門級,當然也有它自身的缺點比如複雜的T-SQL陳述句會產生較大的影象,檢視必須收縮操作,比較麻煩。
SSMS預設給我們提供了檢視該查詢計劃的便捷按鈕,需要檢視某一條陳述句的時候,只需要點選上就可以
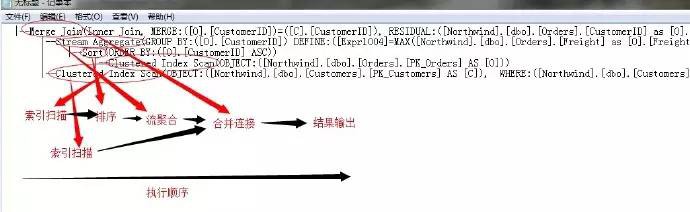
我們來看一個影象方式展示的查詢計劃圖
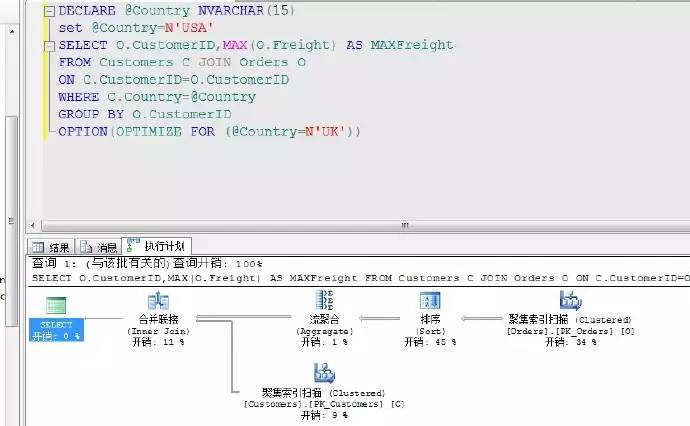
以上查詢陳述句所產生的實際執行計劃,將其分成了各個不同的運運算元進行組合,從最右側的聚集索引掃描(index scan)然後經過一系列的運運算元加工形成最左側的結果輸出(select)。
需要註意的是圖中箭頭的方向指向的是資料的流向,箭頭線的粗細表示了資料量的多少。
在圖形化執行計劃中,每一個不同的運運算元都有它自身的屬性值,我們可以把滑鼠移至運運算元圖示上檢視
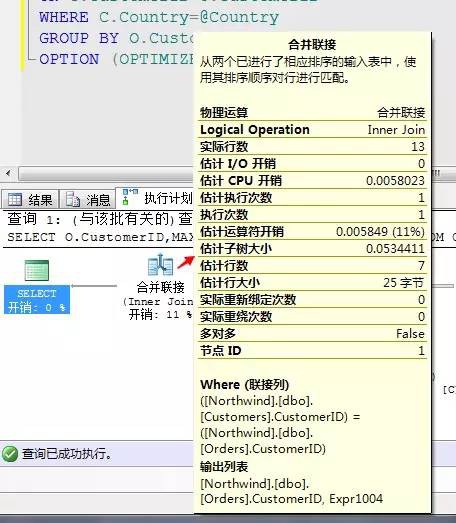
當然也可以直接在圖示上右鍵,檢視屬性,進入到屬性面板,檢視更詳細的屬性值
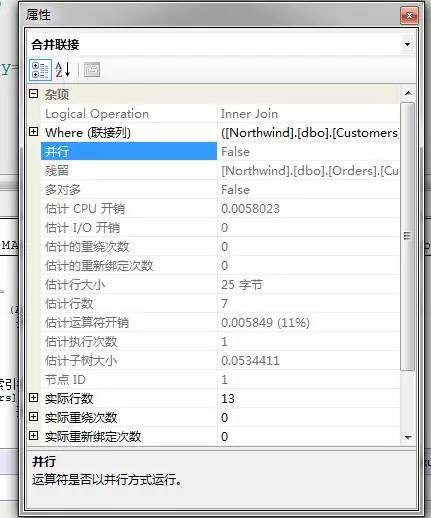
關於這裡面各個運運算元的詳細指標值,我們在後面介紹,不過這裡面有幾個關鍵的值這裡可以說是先稍微提一下,關於影響此陳述句的整體的效能引數,我們可以選擇最開始的Select運運算元,右鍵檢視屬性值
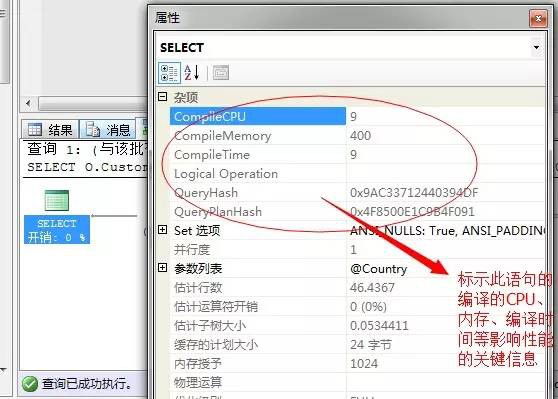
此運運算元包含了整條陳述句的編譯時間、所需記憶體、快取計劃大小、並行度、記憶體授權、編譯執行所需要的引數以及變數值等資訊。
此方式作為一種相對直觀的方式展示給使用者,所以在我們陳述句調優中佔據很大的指導地位,我們知道一條T-SQL陳述句可能會生成很多不同的執行計劃,而SQL Server會幫助我們選擇最優的執行計劃,當然我們也可以利用它選擇的執行計劃去調整自己的陳述句達到最佳化的目的。
鑒於以上標的,SSMS為我們提供了“評估執行計劃”選項,此選項只為評估指導使用,並未實際執行,所以它不包含實際行等具體資訊
2、文字方式
此方式在SSMS中預設沒有提供快捷鍵,我們需要自己用陳述句開啟,開啟的方式有兩種
a、只開啟執行計劃,不包括詳細的評估值
SET SHOWPLAN_TEXT ON
b、開啟所有的執行計劃明細,包括各個屬性的評估值
SET SHOWPLAN_ALL ON
文字方式展現的方式,沒有了明確的箭頭指示,改用豎線(|)標示子運運算元和當前運算的子父關係。並且資料流方向都是從子運運算元流向父運運算元的,雖然文字展現方式不夠直觀,但是如果掌握了文字的閱讀方式,此方式會更易閱讀,尤其在涉及很大的大型計劃的時候,此方式更容易儲存、處理、搜尋和比較。
我們來看一個列子
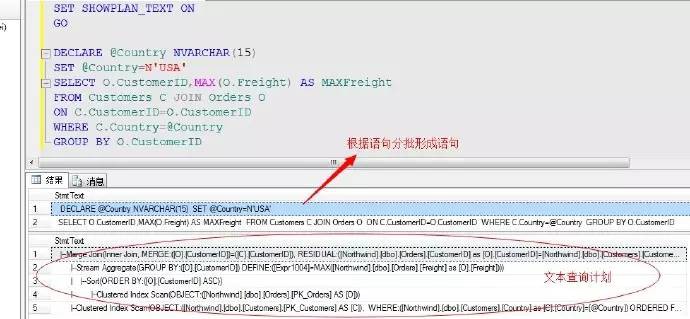
此種方式輸出的形式為文字方式,我們可以複製至文字編輯器中分析,方便於查詢分析等操作
以上是文字查詢計劃的分析方式,簡單點的就是從最裡面的運運算元開始執行,資料流方向也是依次從子運運算元流向父運運算元。
上面的方式看起來有點影象方式,分析起來簡單更易用。但是或許缺少的是每個運運算元的屬性運算資訊,我們透過b方法裡來檢視明細
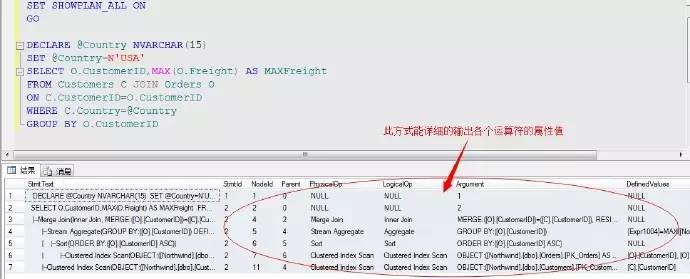
利用此方式可以直觀的分析出每個運運算元操作的屬性評估值。
3、XML方式
XML展現查詢計劃的方式是SQL Server2005中新加入的功能,此方式結合了文字方式和圖形計劃方式的優點。利用XML元素的方式展現查詢計劃。
更主要的特點是利用XML方式是一種規範的方式,可以利用程式設計的方式進行標準XML操作,利於查詢。並且在SQL Server2005中還加入的XML的資料型別,並且內建了XQuery功能進行查詢。此方式尤其對與超大型的查詢計劃檢視非常的方便。
透過以下陳述句開啟
SET STATISTICS XML ON
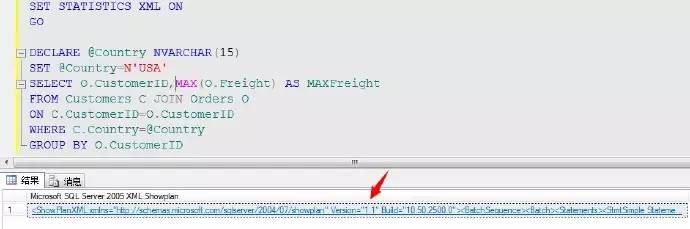
我們可以點選輸出的XML進行檢視

XML方式展現了非常詳細的查詢計劃資訊,我們可以簡單的分析下
StmtSimple:描述了T-SQL的執行文字,並且詳細分析了該陳述句的型別,以及各個屬性的評估值。
StatementSetOptions:描述該陳述句的各種屬性值的Set值
QueryPlan:是詳細的執行計劃,包括執行計劃的並行的執行緒數、編譯時間、記憶體佔有量等
OutputList:輸出引數串列
在中間這部分就是具體的不同的執行運運算元的資訊了,並且包括詳細的預估值等
ParameterList:輸出引數串列
XML方式提供的資訊是最為全面的,並且在SQL Server內部儲存的查詢計劃型別也為XML資料型別。
三、分析查詢計劃
當我們拿到一個陳述句的查詢計劃,我們應該會分析裡面的執行計劃的含義,以及各個運運算元的屬性值,學會如何調整各個運運算元的屬性值來整體的提高該陳述句的執行效率。
1、掃描以及查詢
對於掃描(scan)和查詢(seek)這兩種方式是資料庫裡面從基礎資料表裡獲取的資料的基本方式。
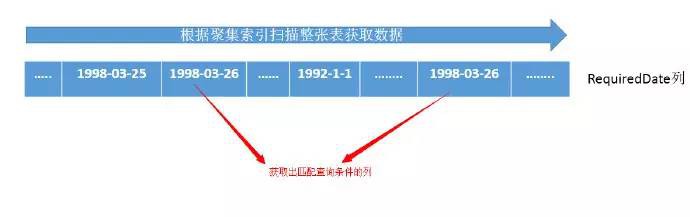
a、當一張表為堆表(沒有任何索引)的時候或者獲取的資料列不存在任何索引來供查詢,此種資料的獲取只能透過全表掃描過濾獲取,如果存在索引項會透過索引項的掃描來獲取資料,提高獲取資料的速度。
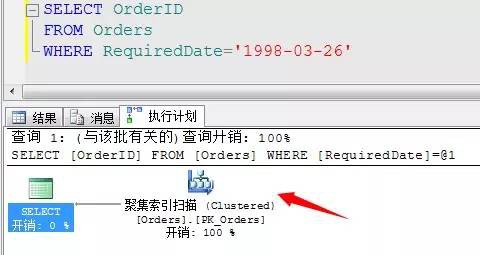
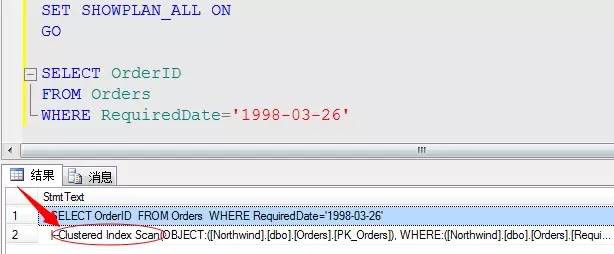
該方法是最為簡單的獲取資料的方式
b、如果當前搜尋的資料行存在索引項,那麼會採取索引查詢(seek)進行資料檢索。
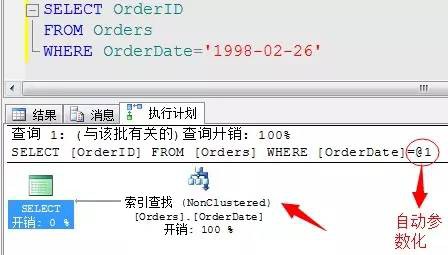
該條陳述句就是執行的索引查詢,因為在Orders表中的OrderDate列存在非聚集索引項。這裡順便提一下如果引入靜態變數,SQL Server會自動引數化該值,目的是為了減少編譯次數,重覆利用執行計劃。
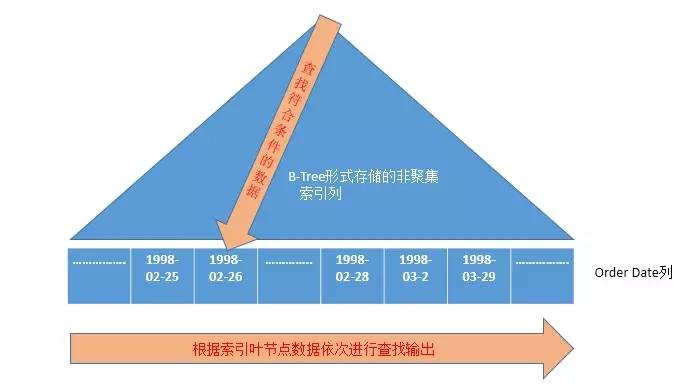
由於查詢只是搜尋符合條件的這些頁進行輸出操作,所以查詢效率只和符合條件的行數、頁數成正比,和整個表中的總行數沒有關係。
c、當所選的索引列不包含輸出列的時候,也就是說要篩選出的列項不為索引所改寫,對於這種情況又引出了另外一種查詢方式
書簽查詢(Bookmark Lookup)
其實該方式是掃描和查詢之間的一個折中方式,我們知道,如果透過聚集索引掃描,則會獲取所有的列,但是這涉及表中的每一行資料,影響效能,相反如果只是透過聚集索引方式進行查詢,則有一些列不能獲取得到,如果這些列正是我們需要的,這就是不準確的,所以,鑒於此,引入了折中的方式:書簽查詢(Bookmark Lookup)
簡單點講:書簽查詢就是透過索引頁節點資料查詢相關的列資料。
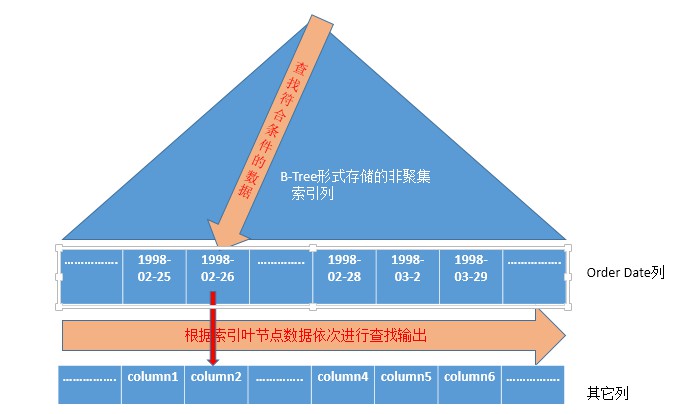
我們來看一個具體的查詢列子
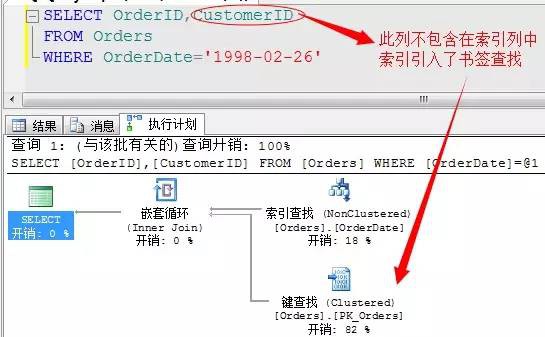
這裡需要解釋一下,在SQL Server2005 SP2版本以上,書簽查詢也被稱為鍵查詢,其實是一個概念。
這種方式有一些弊端,就是在進行書簽查詢的時候,如果透過非聚集索引的葉節點查詢到聚集索引資料,這種情況透過聚集索引能夠快速的獲取到資料,如果非聚集索引關鍵字和聚集索引關鍵字不存在任何關聯,這種情況下,書簽查詢就會執行隨機的I/O操作到聚集索引或者堆表中,而這種情況是非常耗時的,相比而言順序I/O掃描都要比隨機I/O掃描效能好很多。
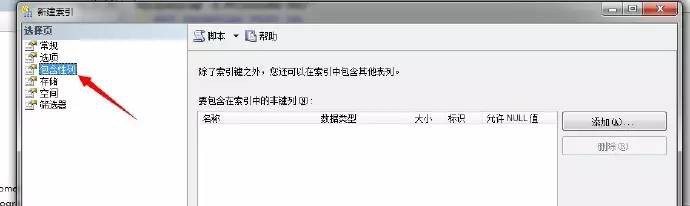
為瞭解決上面所述的問題,在SQL Server2005以後的版本中,在建立index的時候引入了INCLUDE關鍵字。透過建立索引的時候,直接將書簽要查詢的項直接包含進去,這樣就不會發生隨機I/O操作。此種方式的缺點會造成索引儲存增大一部分,但相比帶來的好處,基本可以忽略不計。
結語
此篇文章先到此吧,本篇主要介紹了關於T-SQL陳述句調優從執行計劃該如下下手,並介紹了幾個常見的簡單運運算元,下一篇將著重介紹我們最常用的一些運運算元和調優技巧,包括:連線運運算元、聚合運運算元、聯合運運算元、並行運算等吧,關於SQL Server效能調優的內容涉及面很廣,後續文章中依次展開分析。
原文出處: 指尖流淌-吳學雷的部落格
原文連結: http://www.cnblogs.com/zhijianliutang/p/4133226.html