唯一性索引(Unique Index),有時也稱Primary Key索引,顧名思義就是對於這個索引欄位每個doc的值都是唯一的,如各種id欄位:product id,customer id, campaign id和bidword id等。這種型別的索引一般用來進行高效的查詢,最典型的應用場景就是進行附表join查詢,即對主表中查到的每一個doc,都在附表中查詢其對應的附表doc資訊。所以,對這種型別的索引進行最佳化會對整體查詢效能有很好的提升,特別是在主表查詢的結果很多的情況下。本文主要總結一下對於這種型別索引的最佳化實踐,包括全量和實時增量的情況。
我們知道,在全量建索引時,在記憶體中一般用開鏈的雜湊表來儲存Token的Hash值及其倒排鏈的資訊。假設有N個不同的tokens,那麼這個hash陣列的大小一般是取第一個大於N*(5/3)的質數P。結構如下圖所示:
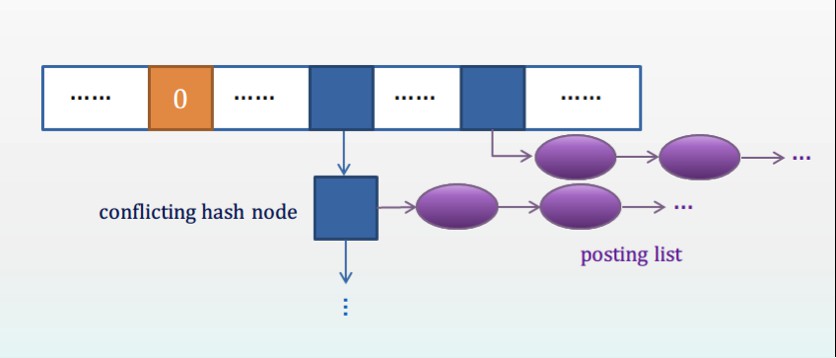
圖1: 全量索引在記憶體中的開鏈雜湊表結構圖
當一個段的索引建完以後,這個記憶體中的Hash表裡面的tokens的雜湊值及包含其倒排鏈和occ鏈等元資訊的keyword terms一般被轉成如下的三種資料結構之一存在檔案中:
1. Closed Hash Table
2. Skip List
3. Tiered Dictionary
這幾種資料結構的目的都是為了在查詢時先mmap了這些檔案以後,能對於一個給定的query keyword,快速根據其雜湊值找到其對應的keyword term,進而定位到相應的倒排鏈和occ鏈等資訊。不同的資料結構在不同的場景(資料特點)下對於記憶體空間的使用以及查詢效能的影響也是不同的。下麵先簡要分析一下以上這幾種常用資料結構的特點,然後再談談對於Unique型別的索引所採用的最佳化資料結構。
為了便於分析,假設我們有100萬個不同的Tokens,每個Token的Hash值需用8個bytes表示(uint64_t)。Tokens對應的keyword terms 100萬個,同時在一般情況下,每個keyword term的第一個元素就是其對應的token的hash值。在記憶體中建索引的時候,這個開鏈hash表陣列的大小P取大於N*(5/3)的第一個質數,即3145739。
Closed Hash Table(閉鏈雜湊表)
提到雜湊表,不少人想到就是快,時間複雜度為O(1), 其實未必如此,這個在後面的最佳化討論中再深入。對於閉鏈hash,其大小一般也是取第一個大於N*(5/3)的質數P來申請空間,所以空間佔用一般會比較大。對於以上例子,即N=100萬,那麼這個Hash陣列大小為P,為原始keyword terms大小的3.15倍。閉鏈Hash表事實上就是環形陣列,如下圖所示:
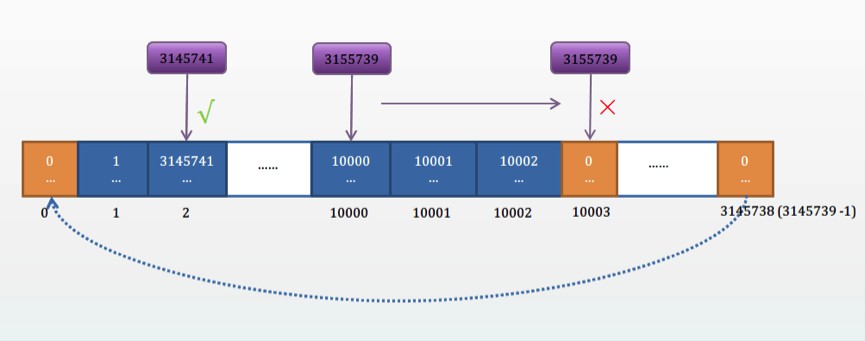
圖2: 閉鏈Hash表結構圖
當查詢一個token倒排鏈等資訊的時候,首先計算其hash值,比如H,然後用H模P得到一個值作為下標,然後看這個閉鏈hash陣列在這個下標下的元素是否是空值,如果為空(對於上圖來說,就是元素的hash值為0),則直接傳回表示沒有查到;若不為空,則看看這個元素的hash值是否和查詢值相等,若相等則找到傳回,若不等則繼續跟這個元素的後面元素依次進行比較,最後要麼找到,要麼碰到一個空元素說明沒有查詢到。
Skip List(跳錶)
跳錶,顧名思義,是能在查詢的時候能快速跳過很多元素,然後在一個相對小的範圍內搜尋給定的一個query keyword的hash值對應的keyword term資訊。跳錶的實現原理是:
1.首先確定用一個小的陣列, 就叫做跳錶陣列吧,來儲存跳錶資訊,這個陣列的size一般取為keyword terms個數N的1/64 (假設此值為M),或者稍微大點,陣列中每個元素的大小為4個位元組(uint32_t)。
2.然後,將keyword terms按token的hash值從小到大排好序儲存在一個陣列中,假設這個陣列叫K,同時根據最大和最小的兩個token的hash值將所有的hash值值域均分成M個區間。
3.讓跳錶陣列的第i個元素儲存hash值的第i個區間裡面的最小的一個hash值對應的keyword term在陣列K中的下標值(哈,這句話有點繞), 若hash值第i個區間裡面沒有值,則存一個無效的下標值-1.
所以一個跳錶的結構如下圖所示:
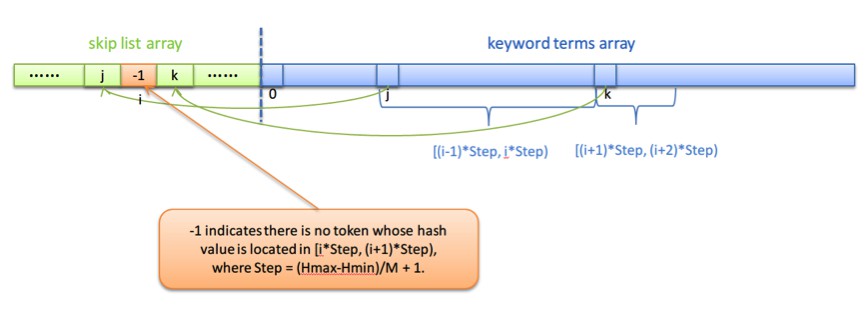
圖3: 跳錶結構圖
在查詢的時候,執行如下步驟:
1.先計算出query keyword的Hash值H,然後用(H-Hmin)/Step得到skip list陣列中的下標i。
2.檢視下標i裡面的元素值是否為-1,若為-1,則說明沒有查到直接傳回,若不為-1,就記錄此元素值,假設為j;然後繼續在skip list陣列中查詢i下標以後的元素中第一個不為-1的元素值,若找到則記錄此元素值為k,如找不到則將k值設為N,即keyword terms陣列的最後一個元素下標位置+1。
3.最後在keyword terms陣列K的[j,k]位置中二分查詢hash值為H的keyword item。
註意由於按Hash值的值域進行分段跳躍,所以每個雜湊值區間裡面的元素個數是很可能是分佈不均的,故每次二分查詢的區間大小是不固定的。
Tiered Dictionary(分層詞典)
Tiered dictionary的思路是分層查詢定位。即,先二分查詢一個小詞典定位到一個大致的小範圍,然後再在小範圍內再繼續搜尋keyword term。實現的原理是:
1.先將所有的keyword terms按它們的hash值從小打大排序後儲存在一個陣列中。
2.將上面的陣列分成若干個blocks,每個block包含相同個數的keyword terms,記做B個(比如說B就取128個),當然最後一個block的元素個數可能少於B個。
3.將上面每個block的最後一個keyword item元素的hash值抽出來依次儲存在另外一個小的字典陣列中。
所以,序列化好的tiered dictionary結構圖如下:
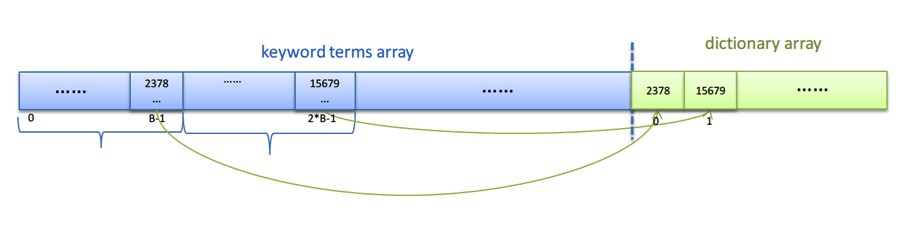
圖4: Tiered dictionary結構圖
那麼對於任一個查詢詞,假設hash值為H,查詢其對應的keyword term就比較簡單了:
1.先在字典陣列中找到第一個大於或等於H的元素下標,若無此下標,即字典陣列中的都有元素的hash值都小於H,那麼說明沒有查到結果,直接傳回;否則,可以根據此下標定位到這個元素在keyword terms陣列中所屬於的block。
2.在1確定的block中二分查詢H對應的keyword term。
相對於skip list,tiered dictionary的查詢比較穩定,因為它可以保證第二次搜尋總是在一個元素較少的block中查詢,而skip list無法做到這一點,這個前面提到過;但是skip list有時候可以在第一步查skip list小陣列的時候就可以確定這個元素不存在,而tiered dictionary一般情況下做不到這點。
全量Unique索引最佳化
像很多資料結構的演演算法一樣,在記憶體空間使用和查詢時間之間往往需要一個權衡,Unique索引的最佳化也是這樣,當然我們的標的還是在盡可能的在佔用較少記憶體的情況下,使得查詢速度更快。
不同於一般的欄位索引,一次查詢只查詢一次,用在附表Join時候的Unique索引在一次查詢中可能會被查詢上萬次(每個主表的doc結果都需要進行一次附表Unique索引查詢),這就決定了查詢速度是Unique索引實現的第一標的。我們看到,不管是skip list還是tiered dictionary,大部分時候都需要二分查詢,特別是有時候對於不在裡面的元素,二分查詢比較的次數反而更多,這就決定了對於Unique索引如用這兩種資料結構,線上查詢的效能是很不高的,雖然它們倆是比較省記憶體的。
當然,我們最想達到的標的就是隻比較一次,或者很有限幾次就能確定一個hash值是否在一個段的某個unique索引中。我們很顯然會想到雜湊表,比如實現簡單的閉鏈雜湊表。的確,有些搜尋引擎的索引也是這麼做的。但是,對於閉鏈雜湊表的實現,這裡面有一個大坑!
對於hash table的實現,我們知道關鍵是hash function,記做H。好的H(x)的計算結果要分佈均勻(uniform distributed)、衝突少(less collisions)。但對於閉鏈hash table的實現,除了衝突少,H還有一個非常重要的要求,那就是H(x)的結果集要避免簇擁在一起(avoid clustering),即要避免H(x)計算得到的陣列下標是連在一起的,否則會發生非常悲慘的後果。這個其實不難理解,因為對於線性hash函式來說,閉鏈hash表在查詢的時候若發生衝突,是依次向後比較查詢,要麼找到相應元素,要麼碰到空元素沒有找到傳回。所以如果有大片的結果連在一起,如果查詢的元素不在裡面,同時又發生了衝突,查詢到第一個空元素有時候需要比較很多次。這種情況很容易發生,比如在bidword id很多是相連在一起的情況,同時我們又採用簡單取模的方式來計算hash陣列儲存下標。
當然,我們可以修改雜湊函式來避免簇擁,這個我們增量索引最佳化的時候會採用。對於全量,為了在記憶體使用和查詢效率上取得平衡,我們可以採用開鏈雜湊表的方式來解決,其實實現也不複雜。
最簡單的實現,就是將記憶體中的hash table裡面的conflicting hash nodes list一條一條的序列化,記憶體中的主索引陣列的元素分佈情況不變,同時將conflicting nodes直接鏈在原hash主陣列的後面。不過,為了鏈式儲存,序列化好的每個keyword item裡面會增加一個next指標和是否是每條鏈的最後一個節點的標記。儲存好的結果如下圖所示:
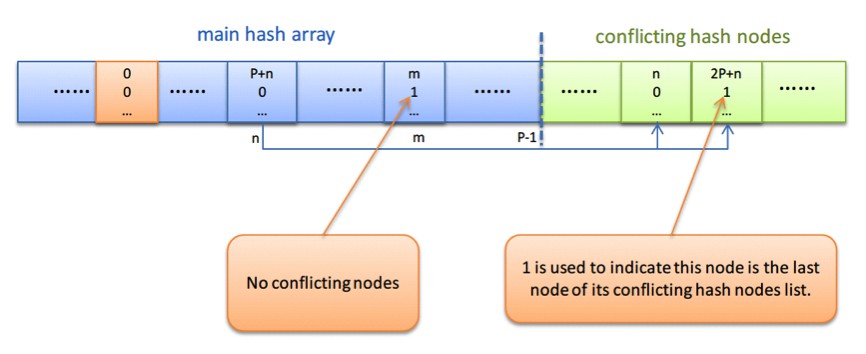
圖5: 開鏈Hash表結構圖
顯然,有了這樣的開鏈hash表結構,我們就可以保證每次都能在有限比較次數內確定一個hash值是否在索引中,而且最多比較次數就是最長的衝突鏈的長度。同時,我們知道一般用來建Unique索引的欄位值基本上都是以加一的方式遞增的,所以當雜湊函式取為H(x) = x % P(P是一個較大質數),衝突顯然是很少的。此外,在查詢沒有衝突的情況下,只需要比較一次就可以確定一個hash值是否在索引中;即使在比較查詢發現有衝突的時候,大的記憶體跳躍查詢也至多一次,因為除了第一個衝突節點,後面都所有其它的衝突節點都是儲存在一起的,所以查詢上具有較好的記憶體訪問區域性性,對CPU cache利用比較友好,從而查詢效能比較好。
測試和線上效果證明,對於P4P廣告bidword域的bid_adid Unique索引,當用以上的開鏈hash表儲存結構替代原來的skip list實現時,查詢效能提升3倍左右。
此外,在基本保持查詢效能最佳化效果不變的情況下,我們還可以對以上開鏈hash表儲存結構進行最佳化,從而佔用更少的記憶體空間。
我們發現主hash陣列裡面的每個空元素也佔用了一個keyword item的空間大小,但其實它們唯一的作用就是表明這個位置為空,所以我們可以用一個每個元素大小為32位(uint32_t)的陣列來表明hash結果資訊,其中1個bit用來表明此位置是否有hash結果,另外31個bit用來表示當有hash結果的時候,對應hash節點鏈在keyword items陣列中的開始下標。這樣就可以將整個keyword items按每條hash衝突鏈儲存在一起了,next指標也不需要了,只需要用一個bit來標識其是否是hash衝突鏈的最後一個節點就可以了,一般這個flag可以從32位的doc id上面取一位來標識。故,改進後的儲存結構為:
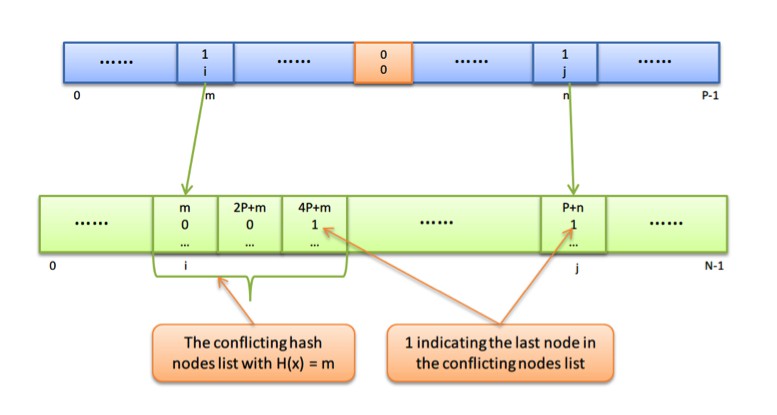
圖6: 記憶體使用最佳化後的開鏈Hash表結構圖
對於前面提到的那個例子,即有100萬個tokens,每個Unique索引的keyword item儲存token的雜湊值和doc id,且有20萬的hash結果是衝突的。那麼,上面改進後的索引結構使用的記憶體空間約是原來的46%,節省了一半以上的記憶體空間。
【註: (3145739*4 + 1000000*12)/((3145739+200000)*16) = 45.9%; 16是因為原來的keyword item多需要額外4個bytes的next成員】
實時增量Unique索引最佳化
以上談論的是對全量Unique索引的最佳化,實時增量索引是在記憶體中一條doc一條doc構建起來的,它不可能像全量時那樣有一個完整的記憶體雜湊表可以進行序列化儲存。但是由於一個segment的總共doc陣列數目是固定的,同時又是Unique索引,所以我們一般用閉鏈雜湊表來儲存實時增量的unique索引。
但我們前面提到過,閉鏈雜湊表的實現有一點要非常小心,那就是雜湊函式H在儲存衝突少的同時也應該避免雜湊結果的slots簇擁在一起。其實也就是讓空元素能夠均勻的分佈在雜湊陣列中,這樣即使在查詢碰到雜湊衝突的時候,也能夠很快完成比較退出,即要麼找到相應元素完成查詢,要麼很快就能碰到空元素表示查詢不到退出。
怎麼樣才能避免雜湊結果集簇擁在一起了呢?一個簡單有效的辦法為:
1.首先將閉鏈Hash陣列擴大幾部,比如說3倍,即3P大小。
2.將線性雜湊函式H(x) = x % P修改為:H(x) = 3 * ( x % P)。
3.當發生衝突的時候,依次+1探測去找空的slots進行儲存。
所以,修改後的實時增量段的Unique索引的儲存結構為:

圖7: 避免簇擁的閉鏈Hash表結構圖
顯然,修改後的演算法佔用了更多的記憶體空間。但由於是實時增量段,這些段的doc資料量一般比較小,而且會被定期合併生成和全量時候一樣的索引結構,所以多一點記憶體空間影響不是太大。但對於查詢效能的提升是非常大的,據測試和線上效果觀測,經過這樣的修改,查詢效能提升10倍以上。
原文出處: 淘寶搜尋技術部落格
原文連結:http://www.searchtb.com/2013/08/unique%E7%B4%A2%E5%BC%95%E4%BC%98%E5%8C%96%E5%AE%9E%E8%B7%B5.html