作者:Woodytu
網址:http://www.cnblogs.com/woodytu/p/4681759.html
點選“閱讀原文”可檢視本文網頁版
在今天的文章裡我想討論下SQL Server裡一個特別的T-SQL語言結構——自SQL Server 2005引入的PIVOT運運算元。我經常取用這個與語言結構是SQL Server裡最危險的一個——很快你就會知道為什麼。在我們進入特定問題和陷阱前,首先我想給你下使用SQL Server裡的PIVOT能實現什麼的一個基本概述。
概述
SQL Server裡PIVOT運運算元背後的基本思想是在T-SQL查詢期間,你可以旋轉行為列。運運算元本身是SQL Server 2005後引入的,主要用在基於建立在物體屬性值模型(Entity Attribute Value model (EAV))原則上的資料庫。EAM模型背後的想法是你可以擴充套件資料庫物體,而不需要進行資料庫架構的修改。因此EAV模型儲存物體的所有屬性以鍵/值對儲存在一個表裡。我們來看下麵一個簡單的鍵/值對模型的表。
CREATE TABLE EAVTable
(
RecordID INT NOT NULL,
Element CHAR(100) NOT NULL,
Value SQL_VARIANT NOT NULL, PRIMARY KEY (RecordID, Element)
)GO-- Insert some recordsINSERT INTO EAVTable (RecordID, Element, Value) VALUES(1, 'FirstName', 'Woody'),
(1, 'LastName', 'Tu'),
(1, 'City', 'Linhai'),
(1, 'Country', 'China'),
(2, 'FirstName', 'Bill'),
(2, 'LastName', 'Gates'),
(2, 'City', 'Seattle'),
(2, 'Country', 'USA')GO
如你所見,我們插入2個資料庫物體到表裡,每個物體包含多個屬性。在表裡每個屬性只是額外的記錄。如果你像擴充套件物體更多的屬性,你只插入額外的記錄到表裡,而沒有必要進行資料庫架構修改——這就是開放資料庫架構的“威力”……
查詢這樣的EAV表顯然很困難,因為你處理的是平鍵/值對的資料結構。因此你要旋轉表內容,行旋轉為列。你可以進行用自帶的PIVOT運運算元進行這個旋轉,或者透過傳統的CASE運算式進行純手工來實現。在我們進入PIVOT細節前,我想給你展示下透過手工使用T-SQL和一些CASE運算式來實現。如果你手工進行旋轉,你的T-SQL查詢需要實現3個階段:
- 分組階段(Grouping Phase)
- 攤開階段(Spreading Phase)
- 聚合階段(Aggregation Phase)
在分組階段(Grouping Phase)我們壓縮我們的EAV表為不同的資料庫物體。在這裡我們在RecordID列進行一個GROUP BY。在第2階段的,攤開階段(Spreading Phase),我們使用多個CASE運算式來旋轉行為列。最後在聚合階段(Aggregation Phase)我們使用MAX運算式來為每個行和列傳回不同值。我們來看下列T-SQL程式碼。
-- Pivot the data with a handwritten T-SQL statement. -- Make sure you have an index defined on the grouping column. SELECT RecordID, -- Spreading and aggregation phase MAX(CASE WHEN Element = 'FirstName' THEN Value END) AS 'FirstName', MAX(CASE WHEN Element = 'LastName' THEN Value END) AS 'LastName', MAX(CASE WHEN Element = 'City' THEN Value END) AS 'City', MAX(CASE WHEN Element = 'Country' THEN Value END) AS 'Country' FROM EAVTable GROUP BY RecordID -- Grouping phase GO
從程式碼裡可以看到,很容易區分每個階段,還有它們如何對映到T-SQL查詢。下圖給你展示了查詢結果,最後我們把行轉為了列。
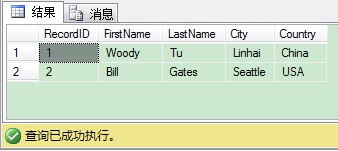
PIVOT運運算元
自SQL Server 2005起(差不多10年前了!),微軟在T-SQL裡引入PIVOT運運算元。使用那個運運算元你可以進行同樣的轉換(行到列),只要一個原生運運算元即可。聽起來很簡單,很有前景,不是麼?下列程式碼顯示了使用原生PIVOT運運算元進行同樣的轉換。
-- Perform the same query with the native PIVOT operator. -- The grouping column is not specified explicitly, it's the remaining column -- that is not referenced in the spreading and aggregation elements. SELECT RecordID, FirstName, LastName, City, Country FROM EAVTable PIVOT(MAX(Value) FOR Element IN (FirstName, LastName, City, Country)) AS t GO
當你執行那個查詢時,你會收到和剛才圖片一樣的結果。但當你看PIVOT運運算元語法時,和手動方法相比,你會看到一個很大的區別:
你只能指定分攤和聚合元素!不能明確定義分組元素!
分組元素是你在PIVOT運運算元裡沒有取用的剩下列。在我們的例子裡,我們沒有在PIVOT運運算元裡沒有取用RecordID列,因此這個列在分組階段(Grouping Phase)被使用。如果我們隨後修改資料庫架構,這會帶來有趣的副作用,例如對基本表增加額外列:
-- Add a new column to the table ALTER TABLE EAVTable ADD SomeData CHAR(1) GO
然後我們對其賦值:
UPDATE dbo.EAVTable SET SomeData=LEFT(CAST(Value AS VARCHAR(1)),1)
現在當你執行用PIVOIT運運算元的同個查詢時(在那somedata列都有非NULL值),你會拿回完全不同的結果,因為排序階段現在是在RecordID和SomeData列(我們剛加的)上。
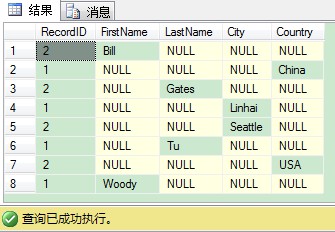
相比如果我們重新執行我們剛開始寫的手工T-SQL查詢會發生什麼。它還是傳回同樣正確的結果。這是在SQL Server裡,PIVOT運運算元的其中一個最大的副作用:分組元素不能明確定義。為了剋服這個問題,最佳實踐是使用只傳回需要列的表運算式。使用這個方法,如果你隨後修改表架構還是沒有問題,因從表運算式預設情況下額外的列還是沒有傳回。我們來看下列的程式碼:
-- Use a table expression to state explicitly which columns you want to -- return from the base table. Therefore you can always control on which -- columns the PIVOT operator is performing the grouping. SELECT RecordID, FirstName, LastName, City, Country FROM ( -- Table Expression SELECT RecordID, Element, Value FROM EAVTable ) AS t PIVOT(MAX(Value) FOR Element IN (FirstName, LastName, City, Country)) AS t1 GO
從程式碼裡可以看到,我透過一個表運算式輸送給PIVOT運運算元。而且在表運算式裡,你從表裡只選擇需要的列。這就意味著以後你可以修改表架構也會破壞PIVOT查詢的結果。
小結
我希望這篇文章已向你展示了在SQL Server裡,為什麼PIVOT運運算元是非常危險的。這個語法本身帶來了非常高效的程式碼,但作為副作用你不能直接指定分組元素。因次你應該確保使用一個表運算式來定義輸送給PIVOT運運算元的列來保證給出結果的確定性。
用PIVOT運運算元你有什麼經歷?你是否喜歡它?如果你不喜歡它,你想要什麼改變?
感謝關註!