

在碎片化閱讀充斥眼球的時代,越來越少的人會去關註每篇論文背後的探索和思考。
在這個欄目裡,你會快速 get 每篇精選論文的亮點和痛點,時刻緊跟 AI 前沿成果。
點選本文底部的「閱讀原文」即刻加入社群,檢視更多最新論文推薦。
本期推薦的論文筆記來自 PaperWeekly 社群使用者 @TwistedW。由 DeepMind 帶來的 BigGAN 可謂是筆者見過最好的 GAN 模型了,這裡的 Big 不單單是指模型引數和 Batch 的大,似乎還在暗示讓人印象深刻,文章也確實做到了這一點。
文章的創新點是將正交正則化的思想引入 GAN,透過對輸入先驗分佈 z 的適時截斷大大提升了 GAN 的生成效能,在 ImageNet 資料集下 Inception Score 竟然比當前最好 GAN 模型 SAGAN 提高了 100 多分(接近 2 倍),簡直太秀了。
如果你對本文工作感興趣,點選底部閱讀原文即可檢視原論文。
關於作者:武廣,合肥工業大學碩士生,研究方向為影象生成。
■ 論文 | Large Scale GAN Training for High Fidelity Natural Image Synthesis
■ 連結 | https://www.paperweekly.site/papers/2366
■ 作者 | Andrew Brock / Jeff Donahue / Karen Simonyan
豐富的背景和紋理影象的生成是各類生成模型追求的終極標的,ImageNet 的生成已然成為檢驗生成模型好壞的一個指標。
在各類生成模型中,GAN 是這幾年比較突出的,18 年新出的 SNGAN [1]、SAGAN [2] 讓 GAN 在 ImageNet 的生成上有了長足的進步,其中較好的 SAGAN 在 ImageNet 的128×128 影象生成上的 Inception Score (IS) [3] 達到了 52 分。BigGAN 在 SAGAN 的基礎上一舉將 IS 提高了 100 分,達到了 166 分(真實圖片也才 233 分),可以說 BigGAN 是太秀了,在 FID [4] 指標上也是有很大的超越。
論文引入
BigGAN 現在已經掛在了 arXiv 上,在此之前,BigGAN 正處於 ICLR 2019 的雙盲審階段,大家也都在猜測 BigGAN 這樣的大作是誰帶來的。現在根據 arXiv 上的資訊,這篇文章的作者是由英國赫瑞瓦特大學的 Andrew Brock 以及 DeepMind 團隊共同帶來。
拿到這篇論文看了一下摘要,我的第一反應是假的吧?What?仔細閱讀,對比了實驗才感嘆 GAN 已經能做到這種地步了!我們來看一下由 BigGAN 生成的影象:

是不是覺得生成的太逼真了,的確如此,影象的背景和紋理都生成的如此逼真真的是讓人折服。其實我更想說,BigGAN 做的這麼優秀有點太秀了吧!好了,我們進入正題。
隨著 GAN、VAE 等一眾生成模型的發展,影象生成在這幾年是突飛猛進,14 年還在生成手寫數字集,到 18 年已經將 ImageNet 生成的如此逼真了。
這中間最大的貢獻者應該就是 GAN 了,GAN 的對抗思想讓生成器和判別器在博弈中互相進步,從而生成的影象清晰逼真。SAGAN 已經將 ImageNet 在生成上的 IS 達到了 52 分,在定性上我感覺 SAGAN 已經把 ImageNet 生成的可以看了,我認為已經很優秀了。BigGAN 的生成讓我只能用折服來感嘆,BigGAN 為啥能實現這麼大的突破?
其中一個很大的原因就是 BigGAN 如它題目 Large Scale GAN Training for High Fidelity Natural Image Synthesis 描述的 Large Scale,在訓練中 Batch 採用了很大的 Batch,已經達到了 2048(我們平常訓練 Batch 正常都是 64 居多),在摺積的通道上也是變大了,還有就是網路的引數變多了,在 2048 的 Batch 下整個網路的引數達到了接近 16 億(看了一下自己還在用的 GTX 1080 突然沉默了)。
這個就是 BigGAN 之所以稱為 BigGAN 的原因,我想 BigGAN 的題目不僅僅在說明網路的龐大,還想暗示這篇文章會給人帶來很大的印象,確實我是被“嚇”到了。 這麼大的提升當然不可能是一味的增大 Batch 和網路引數能實現的,其中包括了 Batch 的加大、先驗分佈 z 的適時截斷和處理、模型穩定性的控制等,我們在後續展開說明。
按照原文,總結一下 BigGAN 的貢獻:
-
透過大規模 GAN 的應用,BigGAN 實現了生成上的巨大突破;
-
採用先驗分佈 z 的“截斷技巧”,允許對樣本多樣性和保真度進行精細控制;
-
在大規模 GAN 的實現上不斷剋服模型訓練問題,採用技巧減小訓練的不穩定。
BigGAN提升生成之路
BigGAN 在 SAGAN 的基礎上架構模型,SAGAN 不熟悉的可參看我之前的論文解讀 [5],BigGAN 同樣採用 Hinge Loss、BatchNorm 和 Spectral Norm 和一些其它技巧。在 SAGAN 的基礎上,BigGAN 在設計上做到了 Batch size 的增大、“截斷技巧”和模型穩定性的控制。
Batch size的增大
SAGAN 中的 Batch size 為 256,作者發現簡單地將 Batch size 增大就可以實現效能上較好的提升,文章做了實驗驗證:

可以看到,在 Batch size 增大到原來 8 倍的時候,生成效能上的 IS 提高了 46%。文章推測這可能是每批次改寫更多樣式的結果,為生成和判別兩個網路提供更好的梯度。增大 Batch size 還會帶來在更少的時間訓練出更好效能的模型,但增大 Batch size 也會使得模型在訓練上穩定性下降,後續再分析如何提高穩定性。
在實驗上,單單提高 Batch size 還受到限制,文章在每層的通道數也做了相應的增加,當通道增加 50%,大約兩倍於兩個模型中的引數數量。這會導致 IS 進一步提高 21%。文章認為這是由於模型的容量相對於資料集的複雜性而增加。有趣的是,文章在實驗上發現一味地增加網路深度並不會帶來更好的結果,反而在生成效能上會有一定的下降。
由於 BigGAN 是訓練 ImageNet 的各個類,所以透過加入條件標簽 c 實現條件生成,如果在 BatchNorm 下嵌入條件標簽 c 將會帶來很多的引數增加,文章採用了共享嵌入,而不是為每個嵌入分別設定一個層,這個嵌入線性投影到每個層的 bias 和 weight,該思想借鑒自 SNGAN 和 SAGAN,降低了計算和記憶體成本,並將訓練速度(達到給定效能所需的迭代次數)提高了 37%。
BigGAN 在先驗分佈 z 的嵌入上做了改進,普遍的 GAN 都是將 z 作為輸入直接嵌入生成網路,而 BigGAN 將噪聲向量 z 送到 G 的多個層而不僅僅是初始層。文章認為潛在空間 z 可以直接影響不同解析度和層次結構級別的特徵,對於 BigGAN 的條件生成上透過將 z 分成每個解析度的一個塊,並將每個塊連線到條件向量 c 來實現,這樣提供約 4% 的適度效能提升,並將訓練速度提高 18%。
按照上述思想看一下 BigGAN 的生成網路詳細結構:
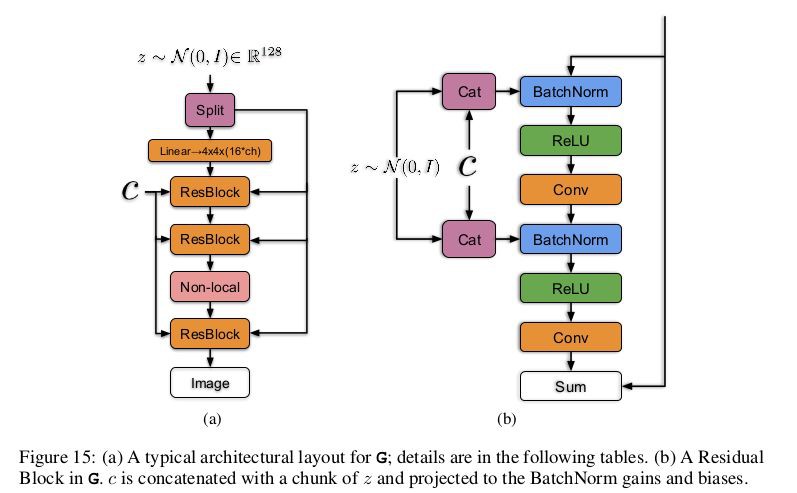
如左圖所示將噪聲向量 z 透過 split 等分成多塊,然後和條件標簽 c 連線後一起送入到生成網路的各個層中,對於生成網路的每一個殘差塊又可以進一步展開為右圖的結構。可以看到噪聲向量 z 的塊和條件標簽 c 在殘差塊下是透過 concat 操作後送入 BatchNorm 層,其中這種嵌入是共享嵌入,線性投影到每個層的 bias 和 weight。
“截斷技巧”
對於先驗分佈z,一般情況下都是選用標準正態分佈 N(0,I) 或者均勻分佈 U[−1,1],文章對此存在疑惑,難道別的分佈不行嗎?透過實驗,為了適合後續的“截斷”要求,文章最終選擇了 z∼N(0,I)。
所謂的“截斷技巧”就是透過對從先驗分佈 z 取樣,透過設定閾值的方式來截斷 z 的取樣,其中超出範圍的值被重新取樣以落入該範圍內。這個閾值可以根據生成質量指標 IS 和 FID 決定。
透過實驗可以知道透過對閾值的設定,隨著閾值的下降生成的質量會越來越好,但是由於閾值的下降、取樣的範圍變窄,就會造成生成上取向單一化,造成生成的多樣性不足的問題。往往 IS 可以反應影象的生成質量,FID 則會更假註重生成的多樣性。我們透過下圖理解一下這個截斷的含義:

隨著截斷的閾值下降,生成的質量在提高,但是生成也趨近於單一化。所以根據實驗的生成要求,權衡生成質量和生成多樣性是一個抉擇,往往閾值的下降會帶來 IS 的一路上漲,但是 FID 會先變好後一路變差。
還有在一些較大的模型不適合截斷,在嵌入截斷噪聲時會產生飽和偽影,如上圖 (b) 所示,為了抵消這種情況,文章透過將 G 調節為平滑來強制執行截斷的適應性,以便 z 的整個空間將對映到良好的輸出樣本。為此,文章採用正交正則化 [6],它直接強制執行正交性條件:

其中 W 是權重矩陣,β 是超引數。這種正則化通常過於侷限,文章為了放鬆約束,同時實現模型所需的平滑度,發現最好的版本是從正則化中刪除對角項,並且旨在最小化濾波器之間的成對餘弦相似性,但不限制它們的範數:

其中 1 表示一個矩陣,所有元素都設定為 1。透過上面的 Table1 中的 Hier. 代表直接截斷,Ortho. 表示採用正則正交,可以看出來正則正交在效能上確實有所提升。
我認為 BigGAN 中的“截斷技巧”很像 Glow [7] 中的退火技巧,BigGAN 透過控制取樣的範圍達到生成質量上的提高,Glow 是透過控制退火繫數(也是控制取樣範圍)達到生成影象平滑性的保證。
模型穩定性的控制
對於 G 的控制:
在探索模型的穩定性上,文章在訓練期間監測一系列權重、梯度和損失統計資料,以尋找可能預示訓練崩潰開始的指標。實驗發現每個權重矩陣的前三個奇異值 σ0,σ1,σ2 是最有用的,它們可以使用 Alrnoldi 迭代方法 [8] 進行有效計算。
實驗如下圖 (a) 所示,對於奇異值 σ0,大多數 G 層具有良好的光譜規範,但有些層(通常是 G 中的第一層而非摺積)則表現不佳,光譜規範在整個訓練過程中增長,在崩潰時爆炸。

為瞭解決 G 上的訓練崩潰,透過適當調整奇異值 σ0 以抵消光譜爆炸的影響。首先,文章調整每個權重的頂部奇異值 σ0,朝向固定值![]() 或者朝向第二個奇異值的比例 r,即朝向 r⋅sg(σ1),其中 sg 是控制梯度的操作,適時停止。另外的方法是使用部分奇異值的分解來代替 σ0,在給定權重 W,它的第一個奇異值向量 μ0 和 ν0 以及固定的
或者朝向第二個奇異值的比例 r,即朝向 r⋅sg(σ1),其中 sg 是控制梯度的操作,適時停止。另外的方法是使用部分奇異值的分解來代替 σ0,在給定權重 W,它的第一個奇異值向量 μ0 和 ν0 以及固定的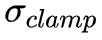 ,將權重限制在:
,將權重限制在:
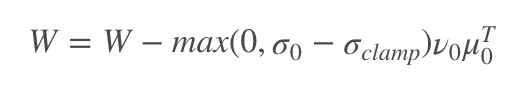
其中固定的設定為![]() 或者 r⋅sg(σ1),上述整個操作就是為了將權重的第一個奇異值 σ0 控制住,放置突然性的爆炸。
或者 r⋅sg(σ1),上述整個操作就是為了將權重的第一個奇異值 σ0 控制住,放置突然性的爆炸。
實驗觀察到在進行權重限制的操作下,在有無光譜歸一化的操作下,都在一定程度上防止了 σ0 或者![]() 的爆炸,但是即使在某些情況下它們可以一定程度上地改善網路效能,但沒有任何組合可以防止訓練崩潰(得到的結論就是崩潰無法避免)。
的爆炸,但是即使在某些情況下它們可以一定程度上地改善網路效能,但沒有任何組合可以防止訓練崩潰(得到的結論就是崩潰無法避免)。
一頓操作後,文章得出了調節 G 可以改善模型的穩定性,但是無法確保一直穩定,從而文章轉向對 D 的控制。
對於 D 的控制:
和 G 的切入點相同,文章依舊是考慮 D 網路的光譜,試圖尋找額外的約束來尋求穩定的訓練。如上圖 3 中 (b) 所示,與 G 不同,可以看到光譜是有噪聲的,但是整個過程是平穩增長在崩潰時不是一下爆炸而是跳躍一下。
文章假設這些噪聲是由於對抗訓練最佳化導致的,如果這種頻譜噪聲與不穩定性有因果關係,那麼相對採用的反制是使用梯度懲罰,透過採用 R1 零中心梯度懲罰:

其中在 γ 為 10 的情況下,訓練變得穩定並且改善了 G 和 D 中光譜的平滑度和有界性,但是效能嚴重降低,導致 IS 減少 45%。減少懲罰可以部分緩解這種惡化,但會導致頻譜越來越不良。即使懲罰強度降低到 1(沒有發生突然崩潰的最低強度),IS 減少了 20%。
使用正交正則化,DropOut 和 L2 的各種正則思想重覆該實驗,揭示了這些正則化策略的都有類似行為:對 D 的懲罰足夠高,可以實現訓練穩定性但是效能成本很高。
如果對 D 的控制懲罰力度大,確實可以實現訓練的穩定,但是在影象生成效能上也是下降的,而且降的有點多,這種權衡就是很糾結的。
實驗還發現 D 在訓練期間的損失接近於零,但在崩潰時經歷了急劇的向上跳躍,這種行為的一種可能解釋是 D 過度擬合訓練集,記憶訓練樣本而不是學習真實影象和生成影象之間的一些有意義的邊界。
為了評估這一猜測,文章在 ImageNet 訓練和驗證集上評估判別器,並測量樣本分類為真實或生成的百分比。雖然在訓練集下精度始終高於 98%,但驗證準確度在 50-55% 的範圍內,這並不比隨機猜測更好(無論正則化策略如何)。這證實了 D 確實記住了訓練集,也符合 D 的角色:不斷提煉訓練資料併為 G 提供有用的學習訊號。
模型穩定性不僅僅來自 G 或 D,而是來自他們透過對抗性訓練過程的相互作用。雖然他們的不良調節癥狀可用於追蹤和識別不穩定性,但確保合理的調節證明是訓練所必需的,但不足以防止最終的訓練崩潰。
可以透過約束 D 來強制執行穩定性,但這樣做會導致效能上的巨大成本。使用現有技術,透過放鬆這種調節並允許在訓練的後期階段發生崩潰(人為把握訓練實際),可以實現更好的最終效能,此時模型被充分訓練以獲得良好的結果。
BigGAN實驗
BigGAN 實驗主要是在 ImageNet 資料集下做評估,實驗在 ImageNet ILSVRC 2012(大家都在用的 ImageNet 的資料集)上 128×128,256×256 和 512×512 解析度評估模型。實驗在定性上的效果簡直讓人折服,在定量上透過和最新的 SNGAN 和 SAGAN 在 IS 和 FID 做對比,也是碾壓對方。

為了進一步說明 G 網路並非是記住訓練集,在固定 z 下透過調節條件標簽 c 做插值生成,透過下圖的實驗結果可以發現,整個插值過程是流暢的,也能說明 G 並非是記住訓練集,而是真正做到了影象生成。

當然模型也有生成上不合理的影象,但是不像以前 GAN 一旦生成不合理的影象,往往是扭曲和透明化的圖,BigGAN 訓練不合理的影象也保留了一定的紋理和辨識度,確實可以算是很好的模型了。
實驗更是在自己的訓練樣本下訓練,殘暴的在 8500 類下 29 億張圖片訓練,和 ImageNet 相似也是取的了很好的效果。
再來說一下實驗環境,實驗整體是在 SAGAN 基礎上架構,訓練採用 Google 的 TPU。一塊 TPU 的效能可以趕得上十幾甚至更多 GPU 的效能,龐大的訓練引數也是讓人害怕,至少我估計我的電腦是跑不動的了。
文章的另一大亮點是把實驗的 NG 結果做了分析,把自己趟的坑和大家分享了,這個真是很良心有沒有,我們擷取其中一些坑分享一下:
-
一味加深網路可能會妨礙生成的效能;
-
共享類的思想在控制超引數上是很麻煩的,雖然可能會提高訓練速度;
-
WeightNorm 替換 G 中的 BatchNorm 並沒有達到好的效果;
-
除了頻譜規範化之外,嘗試將 BatchNorm 新增到 D(包括類條件和無條件),但並未取的好的效果;
-
在 G 或 D 或兩者中使用 5 或 7 而不是 3 的濾波器大小,5 的濾波器可能會有些許提升,但是計算成本也上去了;
-
嘗試在 128×128 的 G 和 D 中改變摺積濾波器的擴張,但發現在任一網路中即使少量的擴張也會降低效能;
-
嘗試用 G 中的雙線性上取樣代替最近領近的上取樣,但這降低了效能。
這篇論文的實驗包括附錄是相當充分的,可以看得出來是花了很長時間在模型訓練和改進上的,DeepMind 作為 Google 旗下的 AI 團隊展示了“壕氣”,為這片論文表示深深的敬意。
最後分享一下 BigGAN 驚艷的生成效果:



總結
BigGAN 實現了 GAN 在 ImageNet 上的巨大飛躍,GAN 的潛力被開發到一個新的階段,IS 或 FID 還能否進一步提升,再提升的話將是幾乎接近真實的存在了。透過大 Batch,大引數,“截斷技巧”和大規模 GAN 訓練穩定性控制,實現了 BigGAN 的壯舉。同時龐大的計算量也是讓人害怕,但是隨著硬體的發展,可能很快 AI 大計算會普及開,還是抱有很大的期待。
參考文獻
[1]. Takeru Miyato, Toshiki Kataoka, Masanori Koyama, and Yuichi Yoshida. Spectral normalization for generative adversarial networks. In ICLR, 2018.
[2]. Han Zhang, Ian Goodfellow, Dimitris Metaxas, and Augustus Odena. Self-attention generative adversarial networks. In arXiv preprint arXiv:1805.08318, 2018.
[3]. Tim Salimans, Ian Goodfellow, Wojciech Zaremba, Vicki Cheung, Alec Radford, and Xi Chen. Improved techniques for training GANs. In NIPS, 2016.
[4]. Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, Gu ̈nter Klambauer, and Sepp Hochreiter. GANs trained by a two time-scale update rule converge to a local nash equilibrium. In NIPS, 2017.
[5]. https://www.paperweekly.site/papers/notes/414
[6]. Andrew Brock, Theodore Lim, J.M. Ritchie, and Nick Weston. Neural Photo Editing with Introspective Adversarial Networks. In ICLR, 2017.
[7]. Kingma, D. P., and Dhariwal, P. 2018. Glow: Generative flow with invertible 1×1 convolutions.
[8]. Gene Golub and Henk Van der Vorst. Eigenvalue computation in the 20th century. Journal of Computational and Applied Mathematics, 123:35–65, 2000.
本文由 AI 學術社群 PaperWeekly 精選推薦,社群目前已改寫自然語言處理、計算機視覺、人工智慧、機器學習、資料挖掘和資訊檢索等研究方向,點選「閱讀原文」即刻加入社群!

點選標題檢視更多論文解讀:
 #投 稿 通 道#
#投 稿 通 道#
讓你的論文被更多人看到
如何才能讓更多的優質內容以更短路徑到達讀者群體,縮短讀者尋找優質內容的成本呢? 答案就是:你不認識的人。
總有一些你不認識的人,知道你想知道的東西。PaperWeekly 或許可以成為一座橋梁,促使不同背景、不同方向的學者和學術靈感相互碰撞,迸發出更多的可能性。
PaperWeekly 鼓勵高校實驗室或個人,在我們的平臺上分享各類優質內容,可以是最新論文解讀,也可以是學習心得或技術乾貨。我們的目的只有一個,讓知識真正流動起來。
? 來稿標準:
• 稿件確系個人原創作品,來稿需註明作者個人資訊(姓名+學校/工作單位+學歷/職位+研究方向)
• 如果文章並非首發,請在投稿時提醒並附上所有已釋出連結
• PaperWeekly 預設每篇文章都是首發,均會新增“原創”標誌
? 投稿郵箱:
• 投稿郵箱:hr@paperweekly.site
• 所有文章配圖,請單獨在附件中傳送
• 請留下即時聯絡方式(微信或手機),以便我們在編輯釋出時和作者溝通
?
現在,在「知乎」也能找到我們了
進入知乎首頁搜尋「PaperWeekly」
點選「關註」訂閱我們的專欄吧
關於PaperWeekly
PaperWeekly 是一個推薦、解讀、討論、報道人工智慧前沿論文成果的學術平臺。如果你研究或從事 AI 領域,歡迎在公眾號後臺點選「交流群」,小助手將把你帶入 PaperWeekly 的交流群裡。

▽ 點選 | 閱讀原文 | 下載論文
