作者:foreach_break
網址:http://www.cnblogs.com/foreach-break/p/what-is-real-time-computing-and-how.html
點選“閱讀原文”可檢視本文網頁版
實時計算是什麼?
請看下麵的圖:
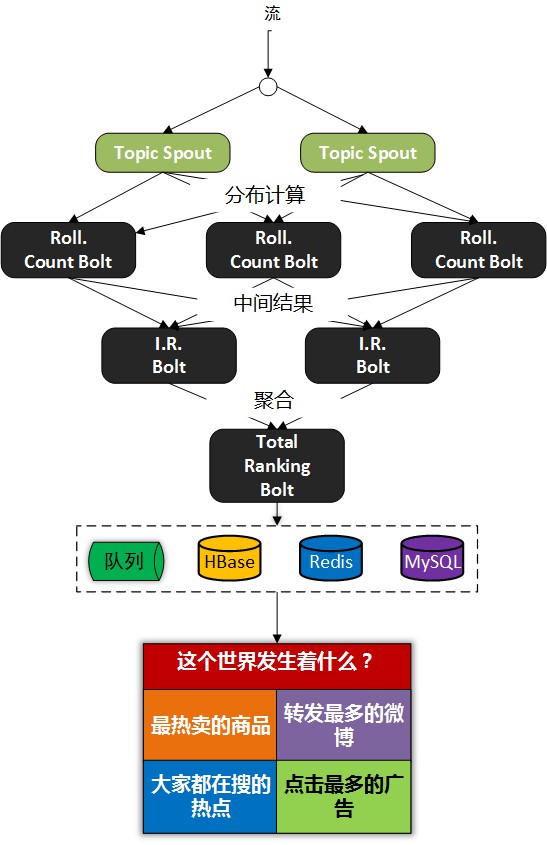
我們以熱賣產品的統計為例,看下傳統的計算手段:
- 將使用者行為、log等資訊清洗後儲存在資料庫中.
- 將訂單資訊儲存在資料庫中.
- 利用觸發器或者協程等方式建立本地索引,或者遠端的獨立索引.
- join訂單資訊、訂單明細、使用者資訊、商品資訊等等表,聚合統計20分鐘內熱賣產品,並傳回top-10.
- web或app展示.
這是一個假想的場景,但假設你具有處理類似場景的經驗,應該會體會到這樣一些問題和難處:
- 水平擴充套件問題(scale-out)
顯然,如果是一個具有一定規模的電子商務網站,資料量都是很大的。而交易資訊因為涉及事務,所以很難直接捨棄關係型資料庫的事務能力,遷移到具有更好的scale-out能力的NoSQL資料庫中。
那麼,一般都會做sharding。歷史資料還好說,我們可以按日期來歸檔,並可以透過批處理式的離線計算,將結果快取起來。
但是,這裡的要求是20分鐘內,這很難。 - 效能問題
這個問題,和scale-out是一致的,假設我們做了sharding,因為表分散在各個節點中,所以我們需要多次入庫,併在業務層做聚合計算。
問題是,20分鐘的時間要求,我們需要入庫多少次呢?
10分鐘呢?
5分鐘呢?
實時呢?
而且,業務層也同樣面臨著單點計算能力的侷限,需要水平擴充套件,那麼還需要考慮一致性的問題。
所以,到這裡一切都顯得很複雜。 - 業務擴充套件問題
假設我們不僅僅要處理熱賣商品的統計,還要統計廣告點選、或者迅速根據使用者的訪問行為判斷使用者特徵以調整其所見的資訊,更加符合使用者的潛在需求等,那麼業務層將會更加複雜。
也許你有更好的辦法,但實際上,我們需要的是一種新的認知:
這個世界發生的事,是實時的。
所以我們需要一種實時計算的模型,而不是批處理模型。
我們需要的這種模型,必須能夠處理很大的資料,所以要有很好的scale-out能力,最好是,我們都不需要考慮太多一致性、複製的問題。
那麼,這種計算模型就是實時計算模型,也可以認為是流式計算模型。
現在假設我們有了這樣的模型,我們就可以愉快地設計新的業務場景:
- 轉發最多的微博是什麼?
- 最熱賣的商品有哪些?
- 大家都在搜尋的熱點是什麼?
- 我們哪個廣告,在哪個位置,被點選最多?
或者說,我們可以問:
這個世界,在發生什麼?
最熱的微博話題是什麼?
我們以一個簡單的滑動視窗計數的問題,來揭開所謂實時計算的神秘面紗。
假設,我們的業務要求是:
統計20分鐘內最熱的10個微博話題。
解決這個問題,我們需要考慮:
- 資料源
這裡,假設我們的資料,來自微博長連線推送的話題。 - 問題建模
我們認為的話題是#號擴起來的話題,最熱的話題是此話題出現的次數比其它話題都要多。
比如:@foreach_break : 你好,#世界#,我愛你,#微博#。
“世界”和“微博”就是話題。 - 計算引擎
我們採用storm。 - 定義時間
如何定義時間?
時間的定義是一件很難的事情,取決於所需的精度是多少。
根據實際,我們一般採用tick來表示時刻這一概念。
在storm的基礎設施中,executor啟動階段,採用了定時器來觸發“過了一段時間”這個事件。
如下所示:
(defn setup-ticks! [worker executor-data]
(let [storm-conf (:storm-conf executor-data)
tick-time-secs (storm-conf TOPOLOGY-TICK-TUPLE-FREQ-SECS)
receive-queue (:receive-queue executor-data)
context (:worker-context executor-data)]
(when tick-time-secs (if (or (system-id? (:component-id executor-data))
(and (= false (storm-conf TOPOLOGY-ENABLE-MESSAGE-TIMEOUTS))
(= :spout (:type executor-data))))
(log-message "Timeouts disabled for executor " (:component-id executor-data) ":" (:executor-id executor-data))
(schedule-recurring
(:user-timer worker)
tick-time-secs
tick-time-secs (fn []
(disruptor/publish
receive-queue [[nil (TupleImpl. context [tick-time-secs] Constants/SYSTEM_TASK_ID Constants/SYSTEM_TICK_STREAM_ID)]]
)))))))
之前的博文中,已經詳細分析了這些基礎設施的關係,不理解的童鞋可以翻看前面的文章。
每隔一段時間,就會觸發這樣一個事件,當流的下游的bolt收到一個這樣的事件時,就可以選擇是增量計數還是將結果聚合併傳送到流中。
bolt如何判斷收到的tuple表示的是“tick”呢?
負責管理bolt的executor執行緒,從其訂閱的訊息佇列消費訊息時,會呼叫到bolt的execute方法,那麼,可以在execute中這樣判斷:
public static boolean isTick(Tuple tuple) { return tuple != null
&& Constants.SYSTEM_COMPONENT_ID .equals(tuple.getSourceComponent())
&& Constants.SYSTEM_TICK_STREAM_ID.equals(tuple.getSourceStreamId());
}
結合上面的setup-tick!的clojure程式碼,我們可以知道SYSTEM_TICK_STREAM_ID在定時事件的回呼中就以建構式的引數傳遞給了tuple,那麼SYSTEM_COMPONENT_ID是如何來的呢?
可以看到,下麵的程式碼中,SYSTEM_TASK_ID同樣傳給了tuple:
;; 請註意SYSTEM_TASK_ID和SYSTEM_TICK_STREAM_ID(TupleImpl. context [tick-time-secs] Constants/SYSTEM_TASK_ID Constants/SYSTEM_TICK_STREAM_ID)
然後利用下麵的程式碼,就可以得到SYSTEM_COMPONENT_ID:
public String getComponentId(int taskId) { if(taskId==Constants.SYSTEM_TASK_ID) { return Constants.SYSTEM_COMPONENT_ID;
} else { return _taskToComponent.get(taskId);
}
}
滑動視窗
有了上面的基礎設施,我們還需要一些手段來完成“工程化”,將設想變為現實。
這裡,我們看看Michael G. Noll的滑動視窗設計。
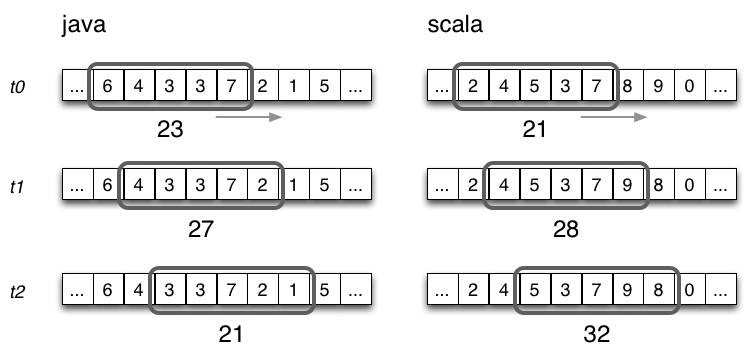
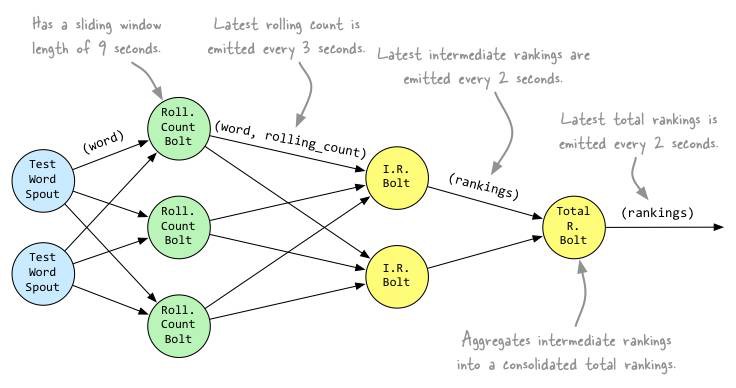
Topology
String spoutId = "wordGenerator";
String counterId = "counter";
String intermediateRankerId = "intermediateRanker";
String totalRankerId = "finalRanker"; // 這裡,假設TestWordSpout就是我們傳送話題tuple的源
builder.setSpout(spoutId, new TestWordSpout(), 5); // RollingCountBolt的時間視窗為9秒鐘,每3秒傳送一次統計結果到下游
builder.setBolt(counterId, new RollingCountBolt(9, 3), 4).fieldsGrouping(spoutId, new Fields("word")); // IntermediateRankingsBolt,將完成部分聚合,統計出top-n的話題
builder.setBolt(intermediateRankerId, new IntermediateRankingsBolt(TOP_N), 4).fieldsGrouping(counterId, new Fields( "obj")); // TotalRankingsBolt, 將完成完整聚合,統計出top-n的話題
builder.setBolt(totalRankerId, new TotalRankingsBolt(TOP_N)).globalGrouping(intermediateRankerId);
上面的topology設計如下:
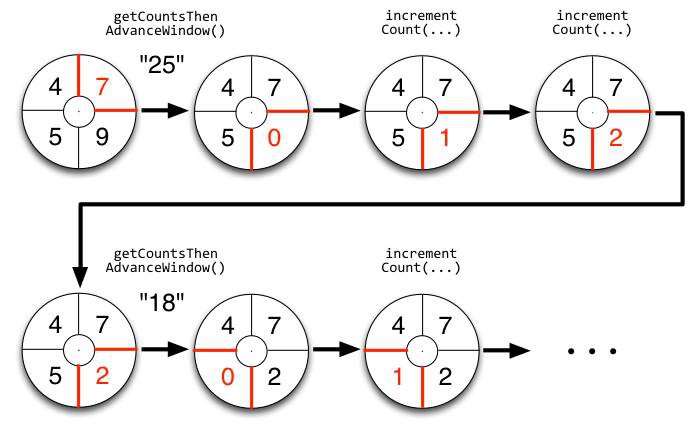
將聚合計算與時間結合起來
前文,我們敘述了tick事件,回呼中會觸發bolt的execute方法,那可以這麼做:
RollingCountBolt:
@Override
public void execute(Tuple tuple) { if (TupleUtils.isTick(tuple)) {
LOG.debug("Received tick tuple, triggering emit of current window counts"); // tick來了,將時間視窗內的統計結果傳送,並讓視窗滾動
emitCurrentWindowCounts();
} else { // 常規tuple,對話題計數即可
countObjAndAck(tuple);
}
} // obj即為話題,增加一個計數 count++
// 註意,這裡的速度基本取決於流的速度,可能每秒百萬,也可能每秒幾十.
// 記憶體不足? bolt可以scale-out.
private void countObjAndAck(Tuple tuple) {
Object obj = tuple.getValue(0);
counter.incrementCount(obj);
collector.ack(tuple);
}
// 將統計結果傳送到下游
private void emitCurrentWindowCounts() {
Map
上面的程式碼可能有點抽象,看下這個圖就明白了,tick一到,視窗就滾動:
IntermediateRankingsBolt & TotalRankingsBolt:
public final void execute(Tuple tuple, BasicOutputCollector collector) { if (TupleUtils.isTick(tuple)) {
getLogger().debug("Received tick tuple, triggering emit of current rankings"); // 將聚合併排序的結果傳送到下游
emitRankings(collector);
} else { // 聚合併排序
updateRankingsWithTuple(tuple);
}
}
其中,IntermediateRankingsBolt和TotalRankingsBolt的聚合排序方法略有不同:
IntermediateRankingsBolt的聚合排序方法:
// IntermediateRankingsBolt的聚合排序方法:
@Override
void updateRankingsWithTuple(Tuple tuple) { // 這一步,將話題、話題出現的次數提取出來
Rankable rankable = RankableObjectWithFields.from(tuple); // 這一步,將話題出現的次數進行聚合,然後重排序所有話題
super.getRankings().updateWith(rankable);
}
TotalRankingsBolt的聚合排序方法:
// TotalRankingsBolt的聚合排序方法
@Override
void updateRankingsWithTuple(Tuple tuple) { // 提出來自IntermediateRankingsBolt的中間結果
Rankings rankingsToBeMerged = (Rankings) tuple.getValue(0); // 聚合併排序
super.getRankings().updateWith(rankingsToBeMerged); // 去0,節約記憶體
super.getRankings().pruneZeroCounts();
}
而重排序方法比較簡單粗暴,因為只求前N個,N不會很大:
private void rerank() {
Collections.sort(rankedItems);
Collections.reverse(rankedItems);
}
結語
下圖可能就是我們想要的結果,我們完成了t0 – t1時刻之間的熱點話題統計,其中的foreach_break僅僅是為了防盜版 : ].
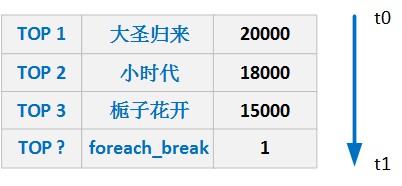
文中對滑動視窗計數的概念和關鍵程式碼做了較為詳細解釋,如果還有不理解,請參考storm的原始碼.
希望你瞭解了什麼是實時計算 :]