

Ceph專案始於2004年,是為優秀的效能、可靠性和可擴充套件性而設計的統一的分散式儲存系統。
在使用RADOS系統時,客戶端程式透過與OSD或者Monitor的互動獲取ClusterMap,然後直接在本地進行計算,得出物件的儲存位置後,便直接與對應的OSD通訊,完成資料的各種操作。可見,在此過程中,只要保證ClusterMap不頻繁更新,則客戶端顯然可以不依賴於任何元資料伺服器,不進行任何查表操作,便完成資料訪問流程。
在RADOS的執行過程中,Cluster Map的更新完全取決於系統的狀態變化,而導致這一變化的常見事件只有兩種(OSD出現故障或者RADOS規模擴大)。而正常應用場景下,這兩種事件發生的頻率顯然遠遠低於客戶端對資料進行訪問的頻率。
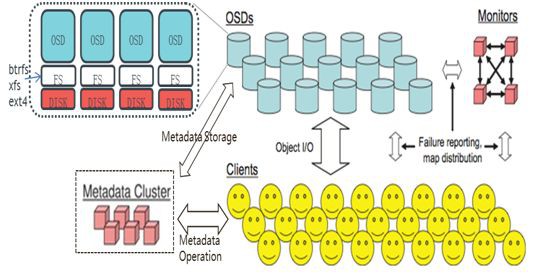
OSD依賴底層檔案系統Xattrs來記錄物件狀態和元資料,Xattr必須提供足夠的容量大小,ext4僅4KB,xfs 64KB,而btrfs沒有限制,Btrfs不夠穩定,ext4 Xattr太小,生產部署推薦xfs測試推薦btrfs。
-
Client:部署在Linux伺服器上,實現資料切片,透過Crush演演算法定位物件位置,併進行物件資料的讀寫。
-
OSD:儲存資料,處理資料複製,恢復,回填,重新調整,並向Monitor報告一些檢測資訊。單叢集至少需要2個OSD,一般情況下一個OSD對應一塊物理硬碟,部署btrfs、xfs或ext4的本地檔案系統。
-
Monitor:實現OSD叢集的狀態監控,維護OSD(守護行程)對映,分組(PG)對映,和CRUSH對映。
-
Metadata Cluster:元資料叢集,用於管理檔案元資料,僅CephFS需要。
Ceph系統的邏輯架構和概念對理解資料佈局和架構十分重要,所以有必要在此進行說明。
-
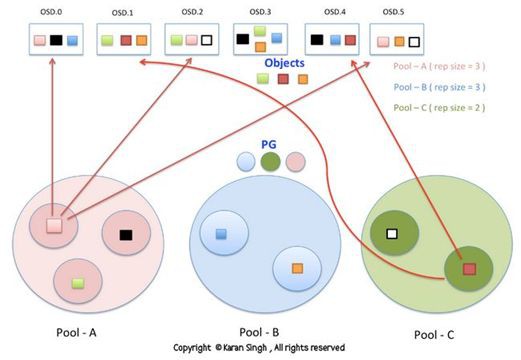
一個Cluster可邏輯上劃分為多個Pool。
-
一個 Pool 包含若干個邏輯PG(Placement Group),同時可定義Pool內的副本數量。
-
一個物理檔案會被切分為多個Object。
-
每個Object會被對映到一個PG,一個PG內可包含多個Object。
-
一個PG對映到一組OSD,其中第一個OSD是主(Primary),其餘的是從(Secondary),承擔相同PG的OSD間透過心跳來相互監控存活狀態。
-
許多 PG 可以對映到某個OSD。
-
引入PG的概念後,OSD只和PG相關,簡化了OSD的資料儲存;同時實現了Object到OSD的動態對映,OSD的新增和故障不影響Object的對映。
在Ceph的現有機制中,一個OSD平時需要和與其共同承載同一個PG的其他OSD交換資訊,以確定各自是否工作正常,是否需要進行維護操作。由於一個OSD上大約承載數百個PG,每個PG內通常有3個OSD,因此,一段時間內,一個OSD大約需要進行數百至數千次OSD資訊交換。
然而,如果沒有PG的存在,則一個OSD需要和與其共同承載同一個Object的其他OSD交換資訊。由於每個OSD上承載的Object很可能高達數百萬個,因此,同樣長度的一段時間內,一個OSD大約需要進行的OSD間資訊交換將暴漲至數百萬乃至數千萬次。而這種狀態維護成本顯然過高。
資料定址流程可分三個對映過程,首先要將使用者要操作的File,對映為RADOS能夠處理的Object。就是簡單的按照Object的Size對File進行切分,相當於RAID中的條帶化過程。接著把Object對映到PG,在File被對映為一個或多個Object之後,就需要將每個Object獨立地對映到一個PG中去。第三次對映就是將作為Object的邏輯組織單元的PG對映到資料的實際儲存單元OSD。
1.File ->Object對映
這次對映的目的是,將使用者要操作的File,對映為RADOS能夠處理的Object。其對映十分簡單,本質上就是按照object的最大size對file進行切分,相當於RAID中的條帶化過程。這種切分的好處有二。
-
一是讓大小不限的File變成最大Size一致、可以被RADOS高效管理的Object。
-
二是讓對單一File實施的序列處理變為對多個Object實施的並行化處理。
2.Object -> PG對映
在File被對映為一個或多個Object之後,就需要將每個Object獨立地對映到一個PG中去。這個對映過程也很簡單,如圖中所示,其計算公式是(Hash(OID) & Mask -> PGID)。
3. PG -> OSD對映
第三次對映就是將作為Object的邏輯組織單元的PG對映到資料的實際儲存單元OSD。如圖所示,RADOS採用一個名為CRUSH的演演算法,將PGID代入其中,然後得到一組共N個OSD。這N個OSD即共同負責儲存和維護一個PG中的所有Object。
1.File —— 此處的file就是使用者需要儲存或者訪問的檔案。對於一個基於Ceph開發的物件儲存應用而言,這個file也就對應於應用中的“物件”,也就是使用者直接操作的“物件”。將使用者操作的File切分為RADOS層面的Object,每個Object一般為2MB或4MB,大小可設定。
2. Ojbect —— 此處的object是RADOS所看到的“物件”。Object與上面提到的file的區別是,Object的最大Size由RADOS限定(通常為2MB或4MB),以便實現底層儲存的組織管理。因此,當上層應用向RADOS存入Size很大的File時,需要將File切分成統一大小的一系列Object(最後一個的大小可以不同)進行儲存。為避免混淆,在本文中將儘量避免使用中文的“物件”這一名詞,而直接使用File或Object進行說明。每個Object透過雜湊演演算法對映到唯一的PG。
3. PG(Placement Group)—— 顧名思義,PG的用途是對Object的儲存進行組織和位置對映。具體而言,一個PG負責組織若干個Object(可以為數千個甚至更多),但一個object只能被對映到一個PG中,即,PG和object之間是“一對多”對映關係。同時,一個PG會被對映到N個OSD上,而每個OSD上都會承載大量的PG,即,PG和OSD之間是“多對多”對映關係。在實踐當中,N至少為2,如果用於生產環境,則至少為3。一個OSD上的PG則可達到數百個。
事實上,PG數量的設定牽扯到資料分佈的均勻性問題。關於這一點,下文還將有所展開。每個PG透過CRUSH演演算法對映到實際儲存單元OSD,PG和OSD間是多對多的對映關係.
4. OSD —— 即Object Storage Device,OSD的數量事實上也關係到系統的資料分佈均勻性,因此其數量不應太少。在實踐當中,至少也應該是數十上百個的量級才有助於Ceph系統的設計發揮其應有的優勢。OSD在物理上可劃分為多個故障域(機房、機架、伺服器),可透過策略配置使PG的不同副本位於不同的故障域中。
關於Ceph技術文章,請搜尋參閱本號歷史相關發文。另外,筆者對之前的Ceph分析文章進行了更新,具體透過原文連結檢視“Ceph技術架構、生態和特性詳細對比分析(第2版)”詳情。
溫馨提示:
請搜尋“ICT_Architect”或“掃一掃”二維碼關註公眾號,點選原文連結獲取更多技術文章。

求知若渴, 虛心若愚

