
本文將介紹騰訊 AI Lab 發表於 EMNLP 2018 的兩篇論文,論文關註的是文字到文字生成研究領域中的文字風格轉化及對話生成任務。其中,在文字風格的論文中,作者提出了一個新的序列編輯模型旨在解決如何生成與給定數值相匹配的句子的研究問題。而關於對話生成的論文中,作者提出了一個新的對話模型用於抑制對話生成模型中通用回覆的生成。
引言
隨著近年來端到端的深度神經網路的流行,文字生成逐漸成為自然語言處理中一個熱點研究領域。文字生成技術具有廣闊的應用前景,包括用於智慧對話系統,實現更為智慧的人機互動;我們還可以透過自動生成新聞、財報及其它型別的文字,提高撰文者的工作效率。
根據不同的輸入型別,文字生成可以大致劃分為三大類:文字到文字的生成,資料到文字的生成以及影象到文字的生成。每一類的文字生成技術都極具挑戰性,在近年來的自然語言處理及人工智慧領域的頂級會議中均有相當多的研究工作。
本次將介紹騰訊 AI Lab 在文字到文字生成研究領域中關於文字風格轉化及對話生成的兩篇論文。其中,文字風格的論文中,我們提出了一個新的序列編輯模型旨在解決如何生成與給定數值相匹配的句子的研究問題。而關於對話生成的論文中,我們提出了一個新的對話模型用於抑制對話生成模型中通用回覆的生成。以下我們將分別介紹兩篇論文。
QuaSE: 量化指導下的序列編輯


在這篇由騰訊 AI Lab 主導,與香港中文大學(The Chinese University of Hong Kong)合作完成的論文中,作者提出一種新的量化指標引導下的序列編輯模型,可以編輯生成與給定的量化指標相匹配的句子,未來可以擴充套件到諸如 CTR 引導下的新聞標題和摘要生成、廣告描述生成等業務場景中。
研究問題
論文的主要任務是給定一個句子以及其對應的分數,例如 Yelp 平臺上的使用者評價“The food is terrible”以及其評分 1,然後我們設定一個標的分數,讓模型能夠生成與標的分數相匹配的句子,並且原句的主要內容在新的句子中必須得以保持。例如,給定數值 3,生成“The food is OK”。給定數值 5,生成“The food is extremely delicious”。
任務的挑戰和特點主要有以下幾方面:
1. 給定的數值可以是連續的,例如 2.5, 3.7, 4.1 等,意味著很難像機器翻譯一樣能夠有人工標註的成對出現的訓練樣本;
2. 模型需要具有甄別句子中與數值相關的語意單元的能力;
3. 根據數值進行句子編寫時,必須保持原句的主要內容。
模型框架

▲ 圖1. QuaSE模型框架
圖 1 為我們提出的模型 QuaSE 的框架,包含單句建模以及序列編輯兩個部分的建模。左半部分為單句建模,其中 X 和 R 是觀測值,分別表示句子(例如使用者對餐廳的評價)以及其對應的數值(例如使用者評分)。Z 和 Y 是隱變數,是對句子內容以及句子數值相關屬性的建模表示。
受 Variational Auto-Encoders(VAE)模型的啟發,對於隱變數 Z 和 Y 的建模是透過生成模型的方式實現。我們設計了兩個 Encoder(E1 和 E2)和一個 Decoder (D),X 以 Z 和 Y 為條件進行生成。
模型的最佳化標的是使得生成的句子 X’ 能夠最大限度的重建輸入句子 X。同時,由於最佳化標的積分計算困難等原因,我們採用變分的方法探尋最佳化標的的下界。單句建模的最佳化標的為:

此外,我們還設計了一個回歸函式 F 來學習隱變數 Y 和數值 R 的對映關係。
對於序列編輯過程的建模,我們首先構建了一個偽平行句對資料集。例如,對於句子 x=“I will never come back to the restaurant.” 我們找到其偽平行句子為 x’=“I will definitely come back to the restaurant, recommend!” 其中 x 和 x’ 對應的數值分別是 1 和 5。
對於句子編輯的建模主要包含三個部分:
1. 建立句子 x 到句子 x’ 的內容變化與數值變化之間的關係。原句 x 到標的句 x’ 的變化肯定是增加或者減少了某些詞,從而使得在數值這個屬性上產生變化,即 y 到 y’ 的差別。對於這個變化對映我們設計了第一個標的函式 L_diff;
2. 我們提到 x 和 x’ 必須在主要內容方面繼續保持一致,例如必須都是在描述“restaurant”。所以我們引入第二個標的函式 L_sim 來使得 z 和 z’ 儘量的相似;
3. 我們知道生成過程是給定 z 和 y 來生成 x (p(x|z,y)),那麼改寫的過程可以是給定 z 和 y’ 來生成 x’ (p(x’|z,y’)),也可以同時是給定 z’ 和 y 來生成 x (p(x|z’,y)),這是個雙向過程。所以對於這兩個生成過程我們引入了第三個損失函式 L_d-rec。
最後,單句建模和編輯建模可以融合成一個統一的最佳化問題透過端到端的方法進行訓練。
實驗分析
我們使用 Yelp 上的使用者評論和打分資料進行實驗,實驗分為兩個部分。
第一個實驗主要是為了驗證給定任意數值的句子編輯能力。我們透過 MAE 和 Edit Distance 兩個指標來衡量句子編輯的效能。實驗結果如表 1 所示:

▲ 表1. Yelp資料集上的任意數值指導下的句子改寫
從表 1 中可以看出我們的模型編輯的句子質量更高,編輯後的句子的預測數值與給定的標的數值更接近。而且能夠保持原句的主要內容。
為了更加形象的說明句子編輯的效果,我們抽樣了一些樣本進行展示,如表 2:

▲ 表2. 序列編輯的示例展示
另外,我們註意到有相關做文字風格轉換的研究工作可以進行句子雙向生成,即給定負向情感句子生成正向情感句子,或反之。
所以,為了與該類模型比較句子編輯的效果,我們設計了第二個實驗與之對應,即從數值 1 的句子生成數值 5 的句子,或相反。我們用準確率來評價改寫的好壞。實驗結果如表 3 所示:

▲ 表3. 雙向文字風格轉換效果
實驗結果說明我們的模型在雙向文字風格轉換實驗中可以獲得更高的準確率。
此外,生成的句子質量很難以進行客觀評測,所以我們引入了人工評測的結果來衡量句子內容保持度以及句子質量的高低。人工評測結果如表 4 所示:

▲ 表4. 人工評測結果
可以看出我們的模型可以最大程度保持原句的內容,並且句子依然保持很好的流暢度。
基於統計重加權減少通用回覆


在這篇由騰訊 AI Lab 主導,與武漢大學、蘇州大學合作完成的論文中,作者提出一種適用於開放領域對話系統的新型神經對話模型(Neural Conversation Model),旨在解決生成模型中容易產生通用回覆(如“我不知道”,“我也是”)的問題。
論文方法
神經生成模型在機器翻譯中的成功應用,即神經機器翻譯(Neural Machine Translation, NMT),激發了研究人員對於神經對話模型的熱情。目前,最常用的神經對話模型為序列到序列(Sequence-to-sequence, Seq2Seq)模型:給定一個輸入序列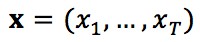 及輸出序列
及輸出序列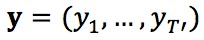 ,模型的引數用於最佳化 negative log likelihood:
,模型的引數用於最佳化 negative log likelihood:

然而在開放領域的對話中,我們經常發現對於一個輸入 x,如“你吃飯了嗎?”,若干意思完全不一致的回覆都是可以被接受的,如“剛吃完。”,“還沒呢,還不餓。”,“不急。你呢?”等等,因此從 x 到 y 是一對多的對映關係。甚至,同一個回覆經常可以適用於多個輸入,因此是從 x 到 y 是多對多的對映關係(如圖 1 所示)。

▲ 圖1. 機器翻譯及對話語料中從輸入到輸出的對映關係對比
然而,Seq2Seq 模型的標的函式學習的是一個從 x 到 y 的一對一的對映關係,並且最佳化的標的函式由大量的預測高頻詞/短語的損失項所組成,導致最終收斂的模型易於生成高頻詞及他們的組合,生成通用回覆。
因此,本文在損失函式項中引入權重,使得 Seq2Seq 模型能最佳化更為多樣化的損失項。其中,我們發現若輸出為(包含)高頻序列,以及輸出序列長度過短或過長,此輸出序列的損失項最佳化都容易導致通用回覆,因此我們設計了有效的方法對這些損失項乘以一個較小的權重。有興趣的讀者可以閱讀我們的論文及具體的權重計算方式。
實驗分析
我們從各大中文社交網站(如微博等)中爬取並篩選了 700 萬高質量的對話句對進行實驗。其中,我們保留了 500 個輸入作為測試集,並且聘請了 3 個評測人員對各種對話生成模型的生成回覆進行了包括句子通順度(Fluency)、與輸入句子的相關性等方面的評測。
同時,我們也對比了多種權重設計方式的有效性,包括只使用句子頻次(Ours-RWE)、只使用句子長度(Ours-RWF)以及句子頻次、長度均使用(Ours-RWEF)。結果如表 1 所示。從中,我們可以看到,我們的方法在保持較高的句子通順度的時候,有效地提高了回覆的相關性。
我們還另外保留了 10 萬個輸入作為另一個較大的測試集。在這個測試集上,我們統計了各種對比模型中產出幾個常見的通用回覆的頻次。結果見表 2。由此表可見,我們提出的方法極大程度地減少了生成的通用回覆。
最後,我們在表 3 中給出一些具體的生成回覆。由此我們可以更為直觀地感受到所提出的方法確實能夠生成質量較高的回覆。

▲ 表1. 人工標註結果

▲ 表2. 通用回覆生成頻次對比

▲ 表3. 生成結果對比

點選以下標題檢視更多論文解讀:
 #投 稿 通 道#
#投 稿 通 道#
讓你的論文被更多人看到
如何才能讓更多的優質內容以更短路徑到達讀者群體,縮短讀者尋找優質內容的成本呢? 答案就是:你不認識的人。
總有一些你不認識的人,知道你想知道的東西。PaperWeekly 或許可以成為一座橋梁,促使不同背景、不同方向的學者和學術靈感相互碰撞,迸發出更多的可能性。
PaperWeekly 鼓勵高校實驗室或個人,在我們的平臺上分享各類優質內容,可以是最新論文解讀,也可以是學習心得或技術乾貨。我們的目的只有一個,讓知識真正流動起來。
? 來稿標準:
• 稿件確系個人原創作品,來稿需註明作者個人資訊(姓名+學校/工作單位+學歷/職位+研究方向)
• 如果文章並非首發,請在投稿時提醒並附上所有已釋出連結
• PaperWeekly 預設每篇文章都是首發,均會新增“原創”標誌
? 投稿郵箱:
• 投稿郵箱:hr@paperweekly.site
• 所有文章配圖,請單獨在附件中傳送
• 請留下即時聯絡方式(微信或手機),以便我們在編輯釋出時和作者溝通
?
現在,在「知乎」也能找到我們了
進入知乎首頁搜尋「PaperWeekly」
點選「關註」訂閱我們的專欄吧
關於PaperWeekly
PaperWeekly 是一個推薦、解讀、討論、報道人工智慧前沿論文成果的學術平臺。如果你研究或從事 AI 領域,歡迎在公眾號後臺點選「交流群」,小助手將把你帶入 PaperWeekly 的交流群裡。

▽ 點選 | 閱讀原文 | 獲取最新論文推薦