(點選上方公眾號,可快速關註一起學Python)
來源:機器之心 連結:
https://mp.weixin.qq.com/s/AwCDt8XH1qGDOQznCGQJZQ
NLP 的研究,從詞嵌入到 CNN,再到 RNN,再到 Attention,以及現在正紅火的 Transformer,模型已有很多,程式碼庫也成千上萬。對於初學者如何把握其核心,並能夠自己用程式碼一一實現,殊為不易。如果有人能夠將諸多模型和程式碼去粗取精,只保留核心,並能夠「一鍵執行」,對於初學者不啻為天大的福音。
近日,來自韓國慶熙大學的 Tae Hwan Jung 在 Github 上建立了這樣一個專案:「nlp-tutorial」。
專案地址:https://github.com/graykode/nlp-tutorial
這個專案並不複雜,但卻包含了基本的嵌入式表徵模型、CNN、RNN、註意力模型、Transformer 等的 13 個重要模型的核心程式碼實現。整體而言,基本所有程式碼都是作者自己完成的,當然都會借鑒已有的實現。很多模型都同時有 TensorFlow 和 PyTorch 兩種版本,但像 Transformer 和 BERT 等擁有谷歌官方實現的模型,作者只提供了 PyTorch 實現。據作者介紹,隨後他計劃將新增 Keras 版本的實現。
引入矚目的是,這個專案中幾乎所有模型的程式碼實現長度都在 100 行左右(除了註釋和空行外),很多預處理、模型持久化和視覺化等操作都被簡化或刪除了。因此精簡後的程式碼非常適合學習,我們不需要從複雜的大型模型實踐中抽絲剝繭地找出核心部分,只要懂一點深度學習框架的入門者就能很容易理清整個模型的實現過程。
另外值得註意的是,每一個模型都只有一個檔案;如果你要訓練,那麼只需要「一鍵」執行即可。對於剛入行的小白簡直再美好不過了。
當然這裡還需要註意配置問題。據作者介紹,他的執行是在谷歌 Colab 上使用 GPU 跑的,這樣就免除了不同機器的環境配置問題。因此如果你想測試一下他的程式碼能不能正常執行,只需要直接將程式碼複製貼上到 Colab 即可。而對於想在本地執行程式碼的同學,環境配置也非常簡單,基本上所有程式碼都只依賴 Tensorflow 1.12.0+ 和 Pytorch 0.4.1+兩個庫,Python 也是常見的 3.5。
專案目錄
下麵為專案的基本框架以及每個模型的功能:
1、基本嵌入模型
-
NNLM – 預測下一個單詞
-
Word2Vec(Skip-gram) – 訓練詞嵌入並展示詞的類推圖
-
FastText(Application Level) – 情感分類
2、CNN
-
TextCNN – 二元情感分類
-
DCNN(進行中……)
3、RNN
-
TextRNN – 預測下一步
-
TextLSTM – 自動完成
-
Bi-LSTM – 在長句子中預測下一個單詞
4、註意力機制
-
Seq2Seq – 同類詞轉換
-
Seq2Seq with Attention – 翻譯
-
Bi-LSTM with Attention – 二元情感分類
5、基於 Transformer 的模型
-
Transformer – 翻譯
-
BERT – 分類是否是下一句和預測 Mask 掉的詞
模型示例
在這一部分中,我們將以帶註意力機制的 Bi-LSTM 與 Transformer 為例分別介紹 TensorFlow 和 PyTorch 的程式碼實現。當然我們也只會介紹模型部分的核心程式碼,其它訓練迭代和視覺化等過程可以查閱原專案。
基於註意力機制的雙向 LSTM
作者用不到 90 行程式碼簡單介紹瞭如何用雙向 LSTM 與註意力機制構建情感分析模型,即使使用 TensorFlow 這種靜態計算圖,Tae Hwan Jung 藉助高階 API 也能完成非常精簡程式碼。總的而言,模型先利用雙向 LSTM 抽取輸入詞嵌入序列的特徵,再使用註意力機制選擇不同時間步上比較重要的資訊,最後用這些資訊判斷輸入句子的情感傾向。
首先對於構建雙向 LSTM,我們只需要定義前向和後向 LSTM 單元(lstm_fw_cell 與 lstm_bw_cell),並傳入高階 API tf.nn.bidirectional_dynamic_rnn() 就行了:
# LSTM Model
X = tf.placeholder(tf.int32, [None, n_step])
Y = tf.placeholder(tf.int32, [None, n_class])
out = tf.Variable(tf.random_normal([n_hidden * 2, n_class]))
embedding = tf.Variable(tf.random_uniform([vocab_size, embedding_dim]))
input = tf.nn.embedding_lookup(embedding, X) # [batch_size, len_seq, embedding_dim]
lstm_fw_cell = tf.nn.rnn_cell.LSTMCell(n_hidden)
lstm_bw_cell = tf.nn.rnn_cell.LSTMCell(n_hidden)
# output : [batch_size, len_seq, n_hidden], states : [batch_size, n_hidden]
output, final_state = tf.nn.bidirectional_dynamic_rnn(lstm_fw_cell,lstm_bw_cell, input, dtype=tf.float32)
第二個比較重要的步驟是構建註意力模組,註意力機制其實就是衡量不同時間步(不同單詞)對最終預測的重要性,它的過程也就計算重要性並根據重要性合成背景關係語意特徵兩部分。下圖展示了全域性註意力的具體過程,它確定不同時間步的權重(alpha),並加權計算得出背景關係向量(context vextor)。如果讀者希望詳細瞭解 Attention,查閱下圖的來源論文就好了,當然也可以跳過原理直接進入實戰部分~

選自論文:Notes on Deep Learning for NLP, arXiv: 1808.09772。
如下所示,模型主要根據前面雙向 LSTM 輸出的結果(output)與最終隱藏狀態之間的餘弦相似性計算怎樣為輸出結果 output 加權,加權得到的背景關係向量 context 可進一步用於計算最終的預測結果。
# Attention
output = tf.concat([output[0], output[1]], 2) # output[0] : lstm_fw, output[1] : lstm_bw
final_hidden_state = tf.concat([final_state[1][0], final_state[1][1]], 1) # final_hidden_state : [batch_size, n_hidden * num_directions(=2)]
final_hidden_state = tf.expand_dims(final_hidden_state, 2) # final_hidden_state : [batch_size, n_hidden * num_directions(=2), 1]
attn_weights = tf.squeeze(tf.matmul(output, final_hidden_state), 2) # attn_weights : [batch_size, n_step]
soft_attn_weights = tf.nn.softmax(attn_weights, 1)
context = tf.matmul(tf.transpose(output, [0, 2, 1]), tf.expand_dims(soft_attn_weights, 2)) # context : [batch_size, n_hidden * num_directions(=2), 1]
context = tf.squeeze(context, 2) # [batch_size, n_hidden * num_directions(=2)]
model = tf.matmul(context, out)
當然,實際上這個模型還有更多關於損失函式、最最佳化器和訓練過程等模組的定義,感興趣的讀者可以在 Colab 上跑一跑。
Transformer
機器之心曾解讀過基於 TensorFlow 的 Transformer 程式碼,總體而言程式碼量還是比較大的,其中包括了各模組的視覺化與預處理過程。對 Transformer 原理及實現程式碼感興趣的讀者可查閱以下文章:
-
基於註意力機制,機器之心帶你理解與訓練神經機器翻譯系統
Transformer 比較重要的結構主要是經過縮放的點乘註意力和 Multi-head 註意力,其它前饋網路、位置編碼等結構主要起到協助作用,它們共同可以構建 Transformer。在 Tae Hwan Jung 的實現中,他只使用了兩百行程式碼就完成了核心過程,而且大量使用類和實體的結構更能理清整體架構。這一部分主要介紹點乘註意力和 Multi-head 註意力兩個類。
首先對於點乘註意力,它率先形式化地定義了整個註意力過程,過程和上面雙向 LSTM 案例使用的註意力機制基本差不多,只不過 Transformer 會有一個縮放過程。如下所示,scores 即表示模型對輸入(Value/V)所加的權重,最後算出來的為背景關係資訊 context。
class ScaledDotProductAttention(nn.Module):
def __init__(self):
super(ScaledDotProductAttention, self).__init__()
def forward(self, Q, K, V, attn_mask=None):
scores = torch.matmul(Q, K.transpose(-1, -2)) / np.sqrt(d_k) # scores : [batch_size x n_heads x len_q(=len_k) x len_k(=len_q)]
if attn_mask is not None:
scores.masked_fill_(attn_mask, -1e9)
attn = nn.Softmax(dim=-1)(scores)
context = torch.matmul(attn, V)
return context, attn
最後,下圖展示了 Transformer 中所採用的 Multi-head Attention 結構,它其實就是多個點乘註意力並行地處理並最後將結果拼接在一起。一般而言,我們可以對三個輸入矩陣 Q、V、K 分別進行 h 個不同的線性變換,然後分別將它們投入 h 個點乘註意力函式並拼接所有的輸出結果。
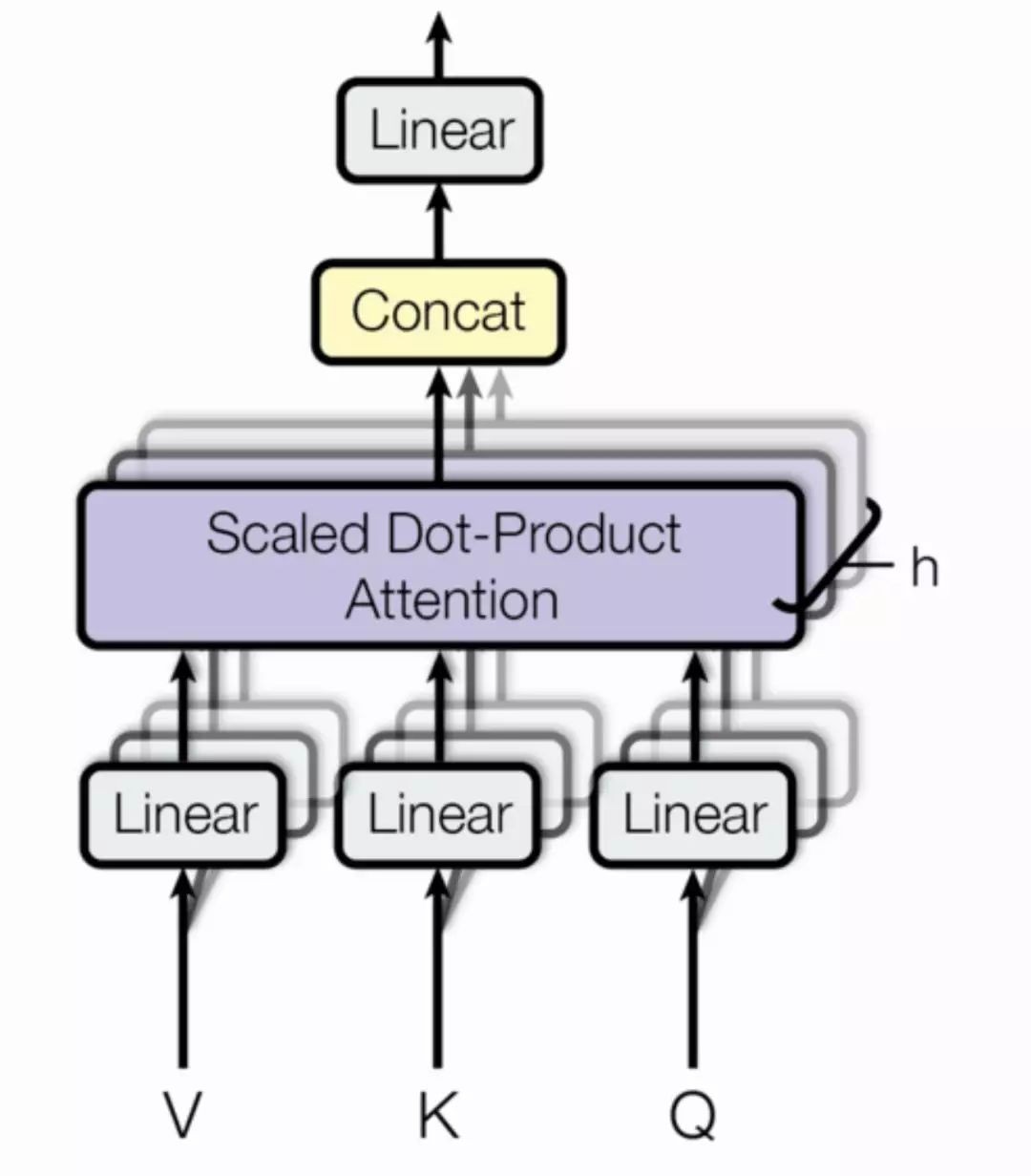
選自:Attention Is All You Need, arXiv: 1706.03762。
最後核心的 MultiHeadAttention 同樣很精簡,讀者可以感受一下:
class MultiHeadAttention(nn.Module):
def __init__(self):
super(MultiHeadAttention, self).__init__()
self.W_Q = nn.Linear(d_model, d_k * n_heads)
self.W_K = nn.Linear(d_model, d_k * n_heads)
self.W_V = nn.Linear(d_model, d_v * n_heads)
def forward(self, Q, K, V, attn_mask=None):
# q: [batch_size x len_q x d_model], k: [batch_size x len_k x d_model], v: [batch_size x len_k x d_model]
residual, batch_size = Q, Q.size(0)
# (B, S, D) -proj-> (B, S, D) -split-> (B, S, H, W) -trans-> (B, H, S, W)
q_s = self.W_Q(Q).view(batch_size, -1, n_heads, d_k).transpose(1,2) # q_s: [batch_size x n_heads x len_q x d_k]
k_s = self.W_K(K).view(batch_size, -1, n_heads, d_k).transpose(1,2) # k_s: [batch_size x n_heads x len_k x d_k]
v_s = self.W_V(V).view(batch_size, -1, n_heads, d_v).transpose(1,2) # v_s: [batch_size x n_heads x len_k x d_v]
if attn_mask is not None: # attn_mask : [batch_size x len_q x len_k]
attn_mask = attn_mask.unsqueeze(1).repeat(1, n_heads, 1, 1) # attn_mask : [batch_size x n_heads x len_q x len_k]
# context: [batch_size x n_heads x len_q x d_v], attn: [batch_size x n_heads x len_q(=len_k) x len_k(=len_q)]
context, attn = ScaledDotProductAttention()(q_s, k_s, v_s, attn_mask=attn_mask)
context = context.transpose(1, 2).contiguous().view(batch_size, -1, n_heads * d_v) # context: [batch_size x len_q x n_heads * d_v]
output = nn.Linear(n_heads * d_v, d_model)(context)
return nn.LayerNorm(d_model)(output + residual), attn # output: [batch_size x len_q x d_model]
