資料技術嘉年華等你來
預告:11.16-17日,北京市東三環中路61號富力萬麗酒店,相聚資料技術嘉年華,(99元票務)免費購票倒計時,點選檢視大會詳情。
張甦老師帶來主題“雙劍合璧帶你走進MySQL和MongoDB的世界”,敬請期待~
點選“閱讀原文”免費購票。
前段時間筆者的客戶遇到了一個主從延遲導致的業務故障,故障的原因本來是較為簡單易查的,但是由於客戶環境的安全、保密性要求,監控和指標只能間接獲知,資訊比較片段化與遲緩。
不過這反而致使整個排查過程變得更加有分享和借鑒價值。在這裡分享給大家希望可以讓大家避免踩坑。
當時涉及到了主從延遲,慢查詢,cursor的不當使用等mongodb問題,本文將從這幾個方面全面復盤整個故障的排查過程,其中包含瞭如下內容:
-
背景(簡單介紹背景情況)
-
臨時應對與考量(該情況下快速恢復業務的選擇)
-
深究與排查
-
主從延遲分析與排查,並透過部分mongo原始碼佐證推斷
-
透過慢查詢定位異常業務
-
根據遲來的監控指標確認cursor的異常並分析
-
-
驗證與總結
背景
9月初我們的某客戶反饋,部署在其私有雲中的Teambition系統存在異常。該客戶透過呼叫系統的開放API包裝了一層業務向內部提供,此時兩個連續介面呼叫之間出現了資料一致性異常,導致包裝的上層業務無法正常使用,而此時Teambition系統本身業務使用均正常。
接到反饋後我們與對方同步了其包裝的業務邏輯,大體為:
-
呼叫介面A(可簡單認為insert了一條資料a)
-
呼叫介面B(可簡單認為insert了一條資料b,但在insert之前檢查了介面A傳回的資料a的_id)
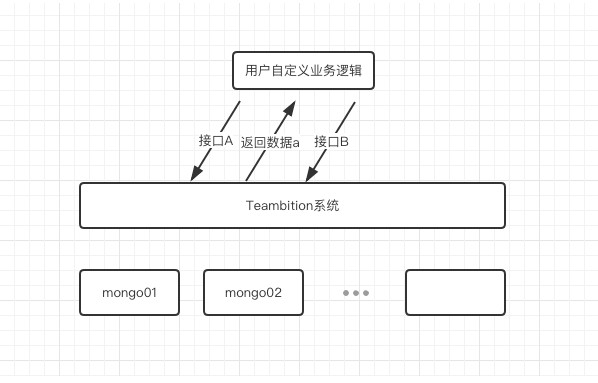
現象為在第二步的過程中,無法查詢到第一步中”新建的任務_id”。考慮到該客戶使用的是MongoDB複製集架構,並且第二個介面的query使用了SecondaryPreferred,由於此時我們無法連線到資料庫檢視指標也無法檢視到客戶處該mongodb叢集的監控資訊,根據已有資訊初步判斷故障原因可能為“主從延遲”導致的資料一致性問題。
臨時應對與考量
我們知道MongoDB的主從同步為非同步同步,主從節點之間延遲在所難免,但是正常情況下延遲時間大多為毫秒級別,大多不會影響到正常業務。此時的現象透露著一個資訊,該MongoDB叢集存在異常,但是由於第一時間無法獲取叢集狀態,具體的異常暫時無從得知。
由於該上層業務重要性較高,擺在面前的首要情況是恢復該業務的可用性,綜合考慮後,得出瞭如下的幾種處理方式:
-
取消SecondaryPreferred,以保證呼叫介面正常
-
不調整介面B的邏輯,在上層呼叫介面A和B之間加一層保護,透過業務的手段避免在短時間內進行連續的呼叫,透過業務形態的微調拉長A與B介面呼叫之間的時間軸,如:先交由使用者配置所需欄位,在提交時再進行任務_id的判斷與系結。
-
解決主從延遲。
在上述三種方案中,我們選擇了方案1“取消SecondaryPreferred”來作為應急處理方案。原因如下:
-
MongoDB的讀寫分離並不是真正意義上的將讀寫壓力完全分離,Primary上的寫最終還是以oplog的形式在從上進行了回放,讀寫分離的效果有限,所以在判斷叢集整體壓力處於合理範圍內,我們考慮取消
SecondaryPreferred,將介面B的請求發向Primary。
-
方案2需要客戶包裝上層業務進行修改,而客戶的介面呼叫場景極多,故而放棄。(雖然放棄該方案,但是需要提醒的是,在任何涉及到資料一致性要求的業務場景都需要充分考慮到異常和可能性,在業務層盡可能的規避。這也是為什麼有主從延遲的時候Teambition系統本身並未)
-
由於短時間內我們無法檢視客戶處mongodb叢集的狀態與監控指標,方案3實現週期長於前兩者,故而放棄。
在我們將SecondaryPreferred的配置取消後,上層業務恢復了正常。我們也輾轉獲得了客戶處mongodb叢集的部分監控資訊、狀態等。
梳理後總結為:
-
流量穩定無暴增
-
QPS處於低位執行,且業務場景讀遠大與寫
-
Connections連線數穩定,並無暴增暴減
-
Resident Memory穩定,且整體eviction狀態良好
-
Cache Activitiy穩定無暴增
-
主從延遲不穩定,有時飆升至5s
-
存在local.oplog.rs的slow query
在此,我們對故障的排查進行一次復盤。
首先從最直觀的問題進行入手,觀察到 db.printSlaveReplicationInfo()傳回的結果和客戶處叢集的視覺化監控顯示主從延遲不穩定,會不時飆升至5s,如:

主從複製延遲是一個非常嚴重且影響業務的指標,此處顯示的5s的時間在有讀寫分離的場景中已經可以認為是非常影響業務的。
不過我們也需要額外註意,該值不為0並不能100%代表系統存在主從延遲問題。我們先來看看db.printSlaveReplicationInfo()的結果是如何獲取的。
在mongodb原始碼中定義了這樣的計算方式

我們可以看到,基準時間是primary節點的optimeDate(將其定義為startOptimeDate),各個從節點的延遲是按照startOptimeDate – st(也就是各個從節點的optimeDate)進行計算(不包括arbiter)。
看起來該值的計算並沒有什麼問題,但是在某類場景下,db.printSlaveReplicationInfo()的傳回值(即主從延遲)並沒有那麼貼切。如:
-
叢集正處於寫操作極為空閑的階段
-
在ISODate(“2018-10-24T07:00:05Z”)進行了一個寫操作a(insert/update/delete)
-
而後在ISODate(“2018-10-24T07:00:30Z”)才進行了下一個寫操作b
-
此時我們正好在1ms後於primary節點中執行了db.printSlaveReplicationInfo()
-
此時primary的optimeDate為ISODate(“2018-10-24T07:00:30Z”),而由於我們執行該命令的時候各個從節點完成同步,所以各個從節點的optimeDate為ISODate(“2018-10-24T07:00:05Z”)。於是乎我們得到了這樣的傳回

看起來從節點落後了主節點25秒的時間,十分嚴重。但是由於場景的特殊性,此時落後的是1個寫操作,並且因為執行時間的原因,該寫操作後續很快也完成了同步。此時的25secs對於叢集來說影響甚微。
回歸到此次故障的場景,雖然db.printSlaveReplicationInfo()存在不準確的可能,但是以當時的pqs情況來判斷,應該是真實出現了主從延遲。
接下來嘗試分析為何會出現主從延遲,從之前梳理的叢集狀態來看,除去主從延遲和local.oplog.rs的slow query,其他指標均十分健康(並不是)。
一般主從延遲有以下幾種可能原因:
-
叢集節點間網路延遲(客戶網路工程師反饋節點間網路正常,該可能排除)
-
從節點的磁碟效能不足(客戶在當時並未提供io和吞吐情況,不過按照當時的低位qps,不應當會有磁碟效能問題,暫時排除)
-
主節點有大量併發寫導致從節點無法及時追上(當時qps處於低位,replWriter為預設執行緒數,不應存在瓶頸,暫時排除)
-
主節點上存在某些異常的慢查詢,影響了從節點上producer thread拉取oplog的效率,從而導致延遲(最有可能)
接下來我們將目光聚焦到了local.oplog.rs的慢查詢上。
主要的慢查詢主要的條件為如下,大多為getmore。

可以看到上述慢查詢有幾個特點:
-
是針對oplog.rs的慢查詢
-
型別為getmore
-
體現了若干遊標定義
從上面的特點我們可以判斷這類陳述句不會是正常業務場景,也不是A或B介面觸發的,回顧下整個服務體系中會對oplog.rs有如此查詢的為trace oplog的場景,來源於一個從mongodb同步資料到elasticsearch的應用。該應用會實時trace oplog 併進行同步。檢查了下服務程式碼,部分如下:

我們知道oplog是沒有嚴格意義上的索引,所以這類遊標在第一次建立的時候會比較耗時,持續trace到最後的末尾的時候會處於tailabled和awaitData狀態,此時實時trace資料的getmore就應該處於相對穩定的快速狀態。
而當時系統內大量的getmore成為了slow query,考慮到當時整體qps情況,我們 對slow query和程式碼進行仔細的檢視。發現了端倪:
slow query內getmore存在這個屬性。

而程式碼中游標加入了這個屬性

當時只是感覺到該服務使用遊標的方式存在不妥,還未能完整與現象關聯起來,記得上文中提到當時的整體常用監控指標都十分“健康”(這裡埋下了一個伏筆),此時從客戶處有獲知了另一個監控指標–cursor數,客戶告知當時主節點cursor總數為7200k+個。
至此,我們大體推斷出了根因。
-
同步業務程式碼在建立cursor時,使用了tailable,awaitData,且noCursorTimeout的定義,致使cursor在業務沒有主動close的情況下,將永久存在。(並且此時cursor監聽在primary節點中,後續我們新增了hidden member用於該業務的請求)。
-
此前該業務出現過異常,從而導致服務不斷異常與重啟,累積了7200k+個notimeout的cursor,而每個cursor是有額外記憶體的消耗,從而導致主節點記憶體被無效的cursor佔用(此處佔用的記憶體不是wt cache,而是剩餘的ram,所以此時監控的wt cache的相關指標都是正常的),但是每個請求除了利用wt cache外還是會產生外部ram的消耗,如connection,結果集臨時儲存等。此時從節點producer thread來拉取oplog的效率降低,進一步造成了主從延遲的產生。
在初步獲取到了結論後,我們開始進行相應的驗證。
驗證1:大量cursor導致wt cache外的ram資源緊張,進而造成主從延遲。
為了釋放cursor我們將節點實體重啟並關閉同步服務,持續觀察後,確認主從延遲情況不再出現恢復正常。將SecondaryPreferred重新啟用,業務也一切正常。
驗證2:在tailable,awaitData和noCursorTimeout定義下,服務異常重啟會導致cursor不被釋放,進而造成cursor堆積。
由於該服務採用pm2進行服務執行態管理,我們不斷向其傳送異常關閉的signal,pm2在其error後不斷重啟。期間觀察db.serverStatus().metrics.cursor狀態,發現db.serverStatus().metrics.cursor.open.noTimeout值持續上升堆積。確認了cursor堆積的原因。
讓我們來梳理下這次故障的前因後果。
-
同步服務中不當的使用了noCursorTimeout的cursor。
-
該服務異常重啟多次造成了primary中cursor的堆積。
-
cursor的堆積造成了異常的記憶體消耗(wt cache外的記憶體),進而影響到了從節點producer thread的效率,從而導致了主從延遲的產生。
-
而上層業務將A、B2個介面的呼叫包裝後的場景由於SecondaryPreferred的原因,導致B介面異常,最終影響了業務的正常對外服務。
至此,這個問題算是完整落下帷幕,總結一下踩的坑以及如何避免
-
使用cursor時候不要使用noCursorTimeout能力,為cursor設定合理的timeout,由應用來控制timeout後的重試機制。以此來保證cursor的合理利用。
-
由於該叢集環境的監控以及狀態無法直接檢視只能透過客戶轉述,這個過程遺漏了很多資訊也造成了很多時間的浪費,在有可能的情況下,mongodb的使用者還是需要對mongodb的全面指標進行監控,魔鬼往往隱藏在細節中。
-
避免對local庫內表的操作,如果有騷操作的需求,必須明白自己在做什麼,同時將騷操作安排在隱藏節點中進行(如果此次最初我們的業務使用的是隱藏節點,該問題就不會直接影響到業務)且新版本可以使用changestream來滿足類似trace oplog的需求。
-
db.printSlaveReplicationInfo()所體現的主從延遲並不一定真的代表延遲,但是該監控指標任何時候都需要提起120%的關註度。
-
合理利用讀寫分離,MongoDB的讀寫分離並不是真正意義上的將讀寫壓力完全分離,需要明確業務對於資料一致性的需求,一致性要求強的場景避免SecondaryPreferred或者透過業務形態的調整避免該問題。
end / 作者簡介 /
周李洋(eshujiushiwo): Teambition運維負責人 MongoDB Master MongoDB中文社群聯席主席 MongoDB上海使用者組發起人 MongoDB Certified Professional DTCC 演講嘉賓 關註資料庫技術,自動化運維,容器,servicemesh等領域
轉載自:Mongoing中文社群。

Percona釋出XtraBackup for MySQL 8.0

