系統級效能最佳化通常包括兩個階段:效能剖析(performance profiling)和程式碼最佳化。效能剖析的標的是尋找效能瓶頸,查詢引發效能問題的原因及熱點程式碼。程式碼最佳化的標的是針對具體效能問題而最佳化程式碼或編譯選項,以改善軟體效能。本篇主要講效能分析中常用的工具——perf。
perf是一款Linux效能分析工具。Linux效能計數器是一個新的基於內核的子系統,它提供一個效能分析框架,比如硬體(CPU、PMU(Performance Monitoring Unit))功能和軟體(軟體計數器、tracepoint)功能。透過perf,應用程式可以利用PMU、tracepoint和核心中的計數器來進行效能統計。它不但可以分析制定應用程式的效能問題(per thread),也可以用來分析核心的效能問題。
總之perf是一款很牛逼的綜合性分析工具,大到系統全域性性效能,再小到行程執行緒級別,甚至到函式及彙編級別。
調優方向
可以從以下三種事件為調優方向:
-
Hardware Event由PMU部件產生,在特定的條件下探測效能事件是否發生以及發生的次數。比如cache命中。
-
Software Event是核心產生的事件,分佈在各個功能模組中,統計和作業系統相關效能事件。比如行程切換,tick數等。
-
Tracepoint Event是核心中靜態tracepoint所觸發的事件,這些tracepoint用來判斷程式執行期間內核的行為細節(這些tracepint的對應的sysfs節點在/sys/kernel/debug/tracing/events目錄下)。比如slab分配器的分配次數等。
perf 的使用
| 序號 | 命令 | 作用 |
| 1 | annotate | 解析perf record生成的perf.data檔案,顯示被註釋的程式碼。 |
| 2 | archive | 根據資料檔案記錄的build-id,將所有被取樣到的elf檔案打包。利用此壓縮包,可以再任何機器上分析資料檔案中記錄的取樣資料。 |
| 3 | bench | perf中內建的benchmark,目前包括兩套針對排程器和記憶體管理子系統的benchmark。 |
| 4 | buildid-cache | 管理perf的buildid快取,每個elf檔案都有一個獨一無二的buildid。buildid被perf用來關聯效能資料與elf檔案。 |
| 5 | buildid-list | 列出資料檔案中記錄的所有buildid。 |
| 6 | diff | 對比兩個資料檔案的差異。能夠給出每個符號(函式)在熱點分析上的具體差異。 |
| 7 | evlist | 列出資料檔案perf.data中所有效能事件。 |
| 8 | inject | 該工具讀取perf record工具記錄的事件流,並將其定向到標準輸出。在被分析程式碼中的任何一點,都可以向事件流中註入其它事件。 |
| 9 | kmem | 針對核心記憶體(slab)子系統進行追蹤測量的工具 |
| 10 | kvm | 用來追蹤測試執行在KVM虛擬機器上的Guest OS。 |
| 11 | list | 列出當前系統支援的所有效能事件。包括硬體效能事件、軟體效能事件以及檢查點。 |
| 12 | lock | 分析核心中的鎖資訊,包括鎖的爭用情況,等待延遲等。 |
| 13 | mem | 記憶體存取情況 |
| 14 | record | 收集取樣資訊,並將其記錄在資料檔案中。隨後可透過其它工具對資料檔案進行分析。 |
| 15 | report | 讀取perf record建立的資料檔案,並給出熱點分析結果。 |
| 16 | sched | 針對排程器子系統的分析工具。 |
| 17 | script | 執行perl或python寫的功能擴充套件指令碼、生成指令碼框架、讀取資料檔案中的資料資訊等。 |
| 18 | stat | 執行某個命令,收集特定行程的效能概況,包括CPI、Cache丟失率等。 |
| 19 | test | perf對當前軟硬體平臺進行健全性測試,可用此工具測試當前的軟硬體平臺是否能支援perf的所有功能。 |
| 20 | timechart | 針對測試期間系統行為進行視覺化的工具 |
| 21 | top | 類似於linux的top命令,對系統效能進行實時分析。 |
| 22 | trace | 關於syscall的工具。 |
| 23 | probe | 用於定義動態檢查點。 |
全域性性概況:
perf list檢視當前系統支援的效能事件;
perf bench對系統效能進行摸底;
perf test對系統進行健全性測試;
perf stat對全域性效能進行統計;
全域性細節:
perf top可以實時檢視當前系統行程函式佔用率情況;
perf probe可以自定義動態事件;
特定功能分析:
perf kmem針對slab子系統效能分析;
perf kvm針對kvm虛擬化分析;
perf lock分析鎖效能;
perf mem分析記憶體slab效能;
perf sched分析核心排程器效能;
perf trace記錄系統呼叫軌跡;
最常用功能perf record,可以系統全域性,也可以具體到某個行程,更甚具體到某一行程某一事件;可宏觀,也可以很微觀。
pref record記錄資訊到perf.data;
perf report生成報告;
perf diff對兩個記錄進行diff;
perf evlist列出記錄的效能事件;
perf annotate顯示perf.data函式程式碼;
perf archive將相關符號打包,方便在其它機器進行分析;
perf script將perf.data輸出可讀性文字;
視覺化工具perf timechart
perf timechart record記錄事件;
perf timechart生成output.svg檔案;
火焰圖
火焰圖(Flame Graph)是由Linux效能最佳化大師Brendan Gregg發明的,和所有其他的trace和profiling方法不同的是,Flame Graph以一個全域性的視野來看待時間分佈,它從底部往頂部,列出所有可能的呼叫棧。其他的呈現方法,一般只能列出單一的呼叫棧或者非層次化的時間分佈。
以典型的分析CPU時間花費到哪個函式的on-cpu火焰圖為例來展開。CPU火焰圖中的每一個方框是一個函式,方框的長度,代表了它的執行時間,所以越寬的函式,執行越久。火焰圖的樓層每高一層,就是更深一級的函式被呼叫,最頂層的函式,是葉子函式。
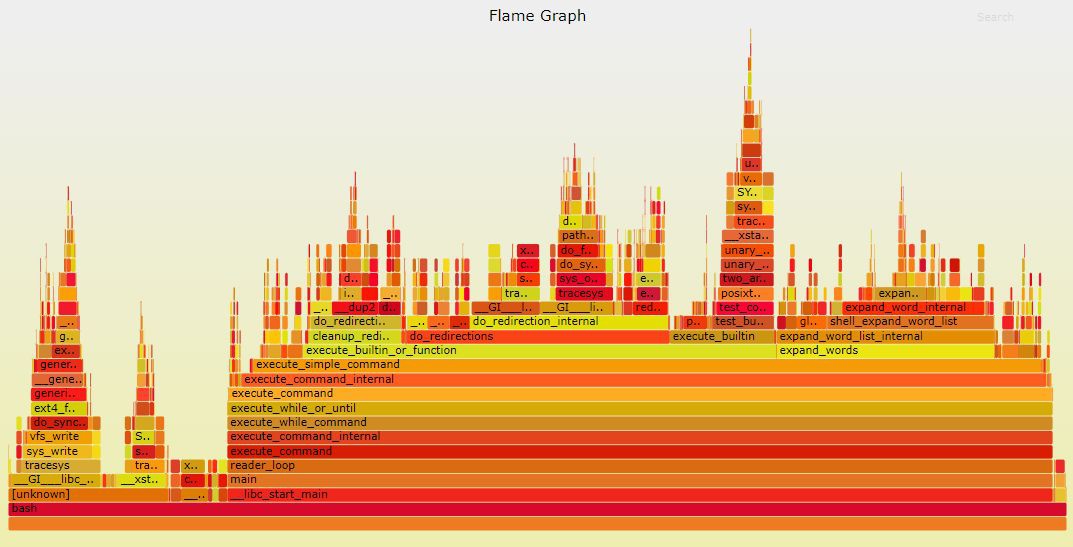
火焰圖的生成過程是:
-
先trace系統,獲取系統的profiling資料
-
用指令碼來繪製
指令碼獲取:git clone https://github.com/brendangregg/FlameGraph
下麵透過實體來體驗以下火焰圖的生成過程:
#include
func_d()
{
int i;
for(i=0;i<50000;i++);
}
func_a()
{
int i;
for(i=0;i<100000;i++);
func_d();
}
func_b()
{
int i;
for(i=0;i<200000;i++);
}
func_c()
{
int i;
for(i=0;i<300000;i++);
}
void* thread_fun(void* param)
{
while(1) {
int i;
for(i=0;i<100000;i++);
func_a();
func_b();
func_c();
}
}
int main(void)
{
pthread_t tid1,tid2;
int ret;
ret=pthread_create(&tid1;,NULL,thread_fun,NULL);
if(ret==-1){
...
}
ret=pthread_create(&tid2;,NULL,thread_fun,NULL);
...
if(pthread_join(tid1,NULL)!=0){
...
}
if(pthread_join(tid2,NULL)!=0){
...
}
return 0;
}先用類似perf top分析出來CPU時間主要花費在哪裡:
$ gcc test.c -pthread
$ ./a.out&
$ sudo perf top
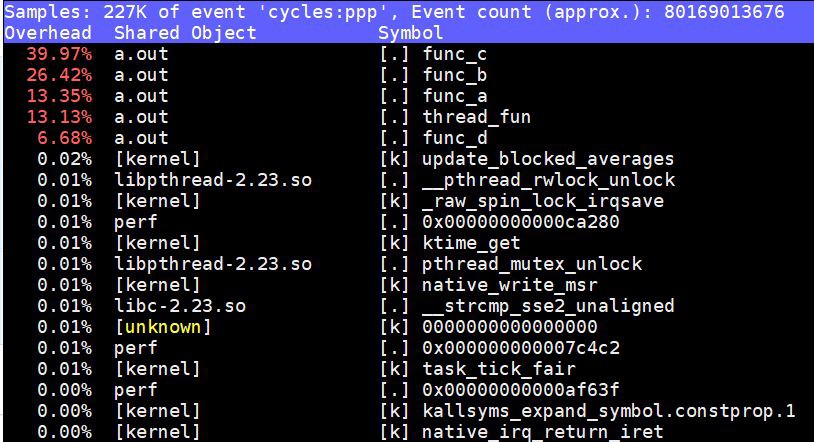
perf top提示出來了fun_a()、fun_b()、fun_c(), fun_d(),thread_func()這些函式內部的程式碼是CPU消耗大戶,但是它缺乏一個全域性的視野,我們無法看出全域性的呼叫棧,也弄不清楚這些函式之間的關係。火焰圖則不然,我們用下麵的命令可以生成火焰圖(以root許可權執行):
$ perf record -F 99 -a -g — sleep 60
$ perf script | ./stackcollapse-perf.pl > out.perf-folded
$ ./flamegraph.pl out.perf-folded > perf-kernel.svg
上述程式捕獲系統的行為60秒鐘,最後呼叫flamegraph.pl生成一個火焰圖perf-kernel.svg,用看圖片的工具就可以開啟這個svg。
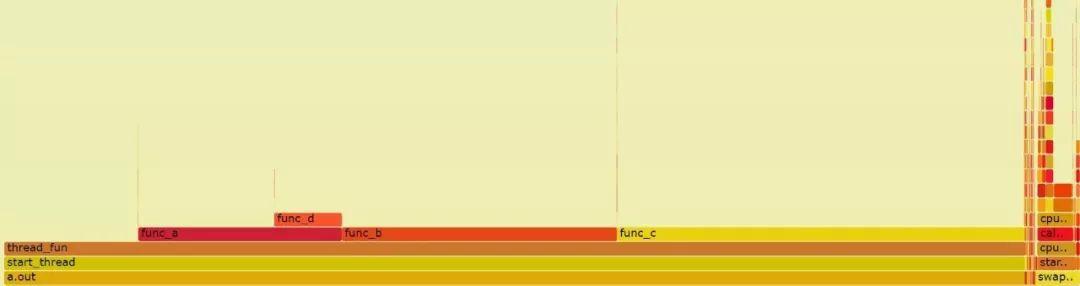
上述火焰圖顯示出了a.out中,thread_func()、func_a()、func_b()、fun_c()和func_d()的時間分佈。
從上述火焰圖可以看出,雖然thread_func()被兩個執行緒呼叫,但是由於thread_func()之前的呼叫棧是一樣的,所以2個執行緒的thread_func()呼叫是合併為同一個方框的。
除了on-cpu的火焰圖以外,off-cpu的火焰圖,對於分析系統堵在IO、SWAP、取得鎖方面的幫助很大,有利於分析系統在執行的時候究竟在等待什麼,系統資源之間的彼此伊伴。
比如,下麵的火焰圖顯示,nginx的吞吐能力上不來的很多程度原因在於sem_wait()等待訊號量。
關於火焰圖的更多細節和更多種火焰圖各自的功能,可以訪問:
http://www.brendangregg.com/flamegraphs.html
