

-
使用者模組
-
商品模組(庫存)
-
訂單模組
-
支付模組



-
Infrastructure(基礎實施層)
-
Domain(領域層)
-
Application(應用層)
-
Interfaces(表示層,也叫使用者介面層或是介面層)
-
微服務結合 DDD
-
劃分“戰略建模”,從一種宏觀的角度去審核整個專案,劃分出“界限背景關係”,形成具有上帝視角的“背景關係對映圖”。
-
還有一個建模是“戰術建模”,在我們的“戰略建模”劃分出來的“界限背景關係”中進行“聚合”,“物體”,“值物件”,並按照模組分組。


-
銷售域
-
商品域
-
使用者域
-
訂單域
-
支付域




-
一致性(C):在分散式系統中的所有資料備份,在同一時刻是否同樣的值。(等同於所有節點訪問同一份最新的資料副本)
-
可用性(A):在叢集中一部分節點故障後,叢集整體是否還能響應客戶端的讀寫請求。(對資料更新具備高可用性)
-
分割槽容錯性(P):以實際效果而言,分割槽相當於對通訊的時限要求。系統如果不能在時限內達成資料一致性,就意味著發生了分割槽的情況,必須就當前操作在 C 和 A 之間做出選擇。
-
Basically Available(基本可用)
-
Soft state(軟狀態)
-
Eventually consistent(最終一致性)

-
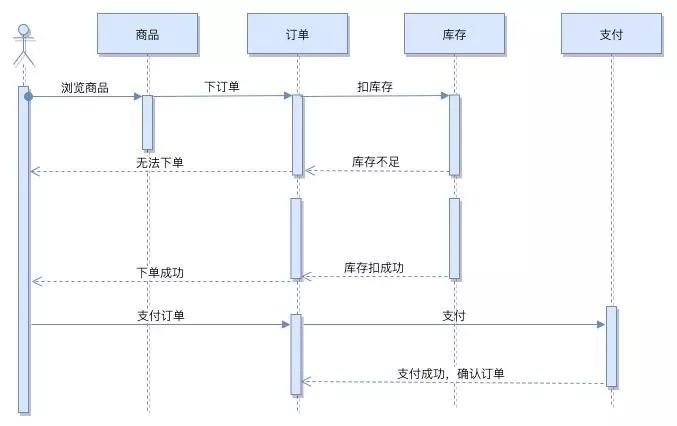
檢視商品詳情(或購物車)
-
計算商品價格和目前商品存在庫存(生成訂單詳情)
-
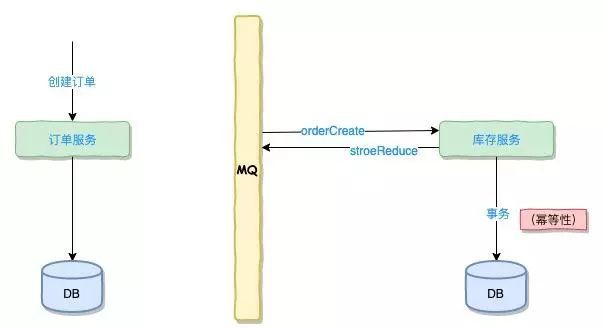
商品扣庫存(呼叫商品庫存服務)
-
訂單確認(生成有效訂單)

-
如果扣減庫存成功,將訂單狀態改為 “確認訂單” ,下單成功。
-
如果扣減庫存失敗,將訂單狀態改為 “失效訂單” ,下單失敗。

-
Try 階段:Try 只是一個初步的操作,進行初步的確認,它的主要職責是完成所有業務的檢查,預留業務資源。
-
Confirm 階段:Confirm 是在 Try 階段檢查執行完畢後,繼續執行的確認操作,必須滿足冪等性操作,如果 Confirm 中執行失敗,會有事務協調器觸發不斷的執行,直到滿足為止。
-
Cancel:是取消執行,在 Try 沒透過並釋放掉 Try 階段預留的資源,也必須滿足冪等性,跟 Confirm 一樣有可能被不斷執行。


-
這個就涉及 TCC 的事務協調器了,事務協調器就 Confirm 或 Cancel 沒有得到傳回的時候,會啟用定時器不斷的進行 Confirm 或 Cancel 的重試。
這個也就是我們強調,Confirm,Cancel 介面必須是冪等性的一個原因了。
-
還有同學會問了,為什麼事務協調器知道 Confirm,或 Cancel 沒有完成。
這個就涉及到了 TCC 也做了一張本地訊息表,會記錄一次事務,包括主事務,子事務,事務的完成情況都會記錄在這種表中(當然未必是表,可能是 ZK,Redis 等等介質),然後啟用一個定時器去檢查這種表。
-
還有同學會問,事務怎麼傳遞,這個就涉及使用的 TCC 的框架了,一般來說用的都是隱式傳參的方式。
在主事務建立的時候用隱式傳參呼叫子事務,子事務包含 Try,Confirm,Cancel 都會記錄到事務表裡面。

-
構建一個 HystrixCommand 物件,用於封裝請求,併在構造方法配置請求被執行需要的引數。
-
執行命令,Hystrix 提供了幾種執行命令的方法,比較常用到的是 Synchrous 和 Asynchrous。
-
判斷電路是否被開啟,如果被開啟,直接進入 Fallback 方法。
-
判斷執行緒池/佇列/訊號量是否已經滿,如果滿了,直接進入 Fallback 方法。
-
執行 Run 方法,一般是 HystrixCommand.run(),進入實際的業務呼叫,執行超時或者執行失敗丟擲未提前預計的異常時,直接進入 Fallback 方法。
-
無論中間走到哪一步都會進行上報 Metrics,統計出熔斷器的監控指標。
-
Fallback 方法也分實現和備用的環節。
-
最後是傳回請求響應。
-
Pull 樣式,服務定時去拉取配置中心的資料。
-
Push 樣式,服務一直連線到配置中心上,一旦配置有變成,配置中心將把變更的引數推送到對應的微服務上。

-
Pull 一般使用定時器拉取,就算某一個網路抖動沒有 Pull 成功,在下一次定時器的時候,終將能保證獲取最新的配置。
-
Push 可以避免 Pull 定時器存在的延時,基本可以做到實時獲取資料,但也有問題就是網路抖動的時候可能會丟失更新。

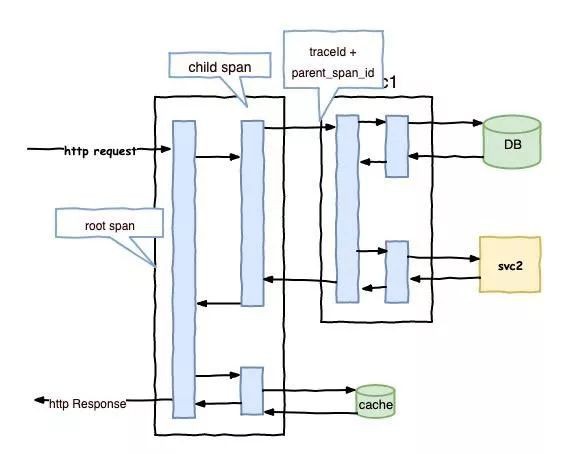
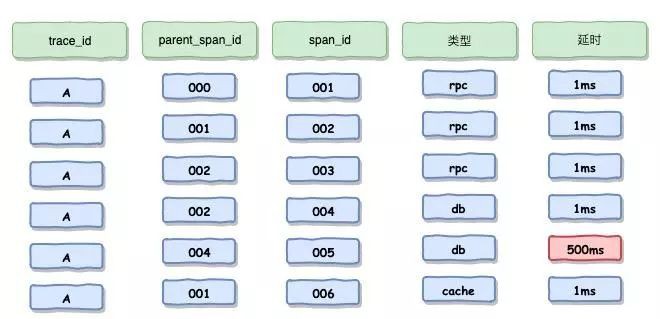

-
首先在實現方式上,Skywalking 基本對於程式碼做到了無入侵,採用 Java 探針和位元組碼增強的方式,而在 Cat 還採用了程式碼埋點,而 Zipkin 採用了攔截請求,Pinpoint 也是使用 Java 探針和位元組碼增強。
-
其次在分析的顆粒度上,Skywaling 是方法級,而 Zipkin 是介面級,其他兩款也是方法級。
-
在資料儲存上,Skywalking 可以採用日誌體系中比較出名的 ES,其他幾款,Zipkin 也可以使用 ES,Pinpoint 使用 Hbase,Cat 使用 MySQL 或 HDFS,相對複雜。由於目前公司對 ES 熟悉的人才比較有保證,選擇熟悉儲存方案也是考慮技術選型的重點。
-
還有就是效能影響,根據網上的一些效能報告,雖然未必百分百準備,但也具備參考價值,Skywalking 的探針對吞吐量的影響在 4 者中間是最效的,經過對 Skywalking 的一些壓測也大致證明。
-
監控系統哪去了(基礎設施監控,系統監控,應用監控,業務監控)
-
閘道器哪裡去了
-
統一的異常處理哪裡去了
-
API 檔案哪裡去了
-
容器化哪裡去了
-
服務編排哪裡去了
-
……

朋友會在“發現-看一看”看到你“在看”的內容