今天來加個餐,緊急糾正一個錯誤。先和大家說一聲抱歉:D
昨晚睡覺前,慣例開啟「訂閱號助手」回覆一些留言。有一位小夥伴提了一個問題,問題來源於《分散式系統關註點》專題的第17篇《先寫DB還是「快取」?》中。
下麵就是提出問題的這位小夥伴,@L。這次非常感謝他。
文章的原文是這樣的:
————-原文開始————-
先DB再快取
資料庫操作成功,快取操作的失敗的情況該怎麼解?(主要在用到redis,memcached這種行程外快取的時候,由於網路因素,失敗的可能性大增)
辦法也是有的,在運算元據庫的時候帶一個事務,如果快取操作失敗則事務回滾。大致的程式碼意思如下:
begin transvar isDbSuccess = write db;if(isDbSuccess){var isCacheSuccess = write cache;if(isCacheSuccess){return success;}else{rollback db;return fail;}}else{return fail;}catch(Exception ex){rollback db;}end trans
如此一來就萬無一失了嗎?並不是。除了由於事務的引入,增加了資料庫的壓力之外,在極端場景下可能會出現rollback db失敗的情況。是不是很頭疼?
解決這個問題的方式就是write cache的時候做delete操作,而不是set操作。如此一來,用多一次cache miss的代價來換rollback db失敗的問題。
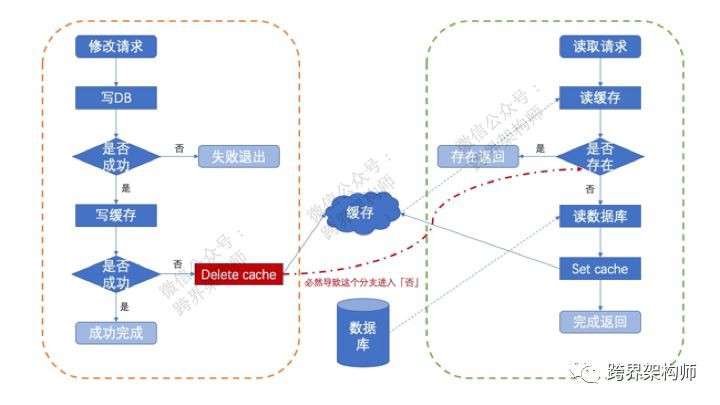
就像圖上所示,哪怕rollback失敗了,透過一次cache miss重新從db中載入舊值。
————-原文結束————-
如果沒看出來問題或者已經遺忘的小夥伴可以去原文地址看下:分散式系統關註點——先寫DB還是「快取」?
也不知道當時咋了,腦子昏了。其實這裡的「rollback db失敗」表述應該換成「commit db失敗」。
而且順帶圖也畫錯了……
正確邏輯圖應該是這樣。
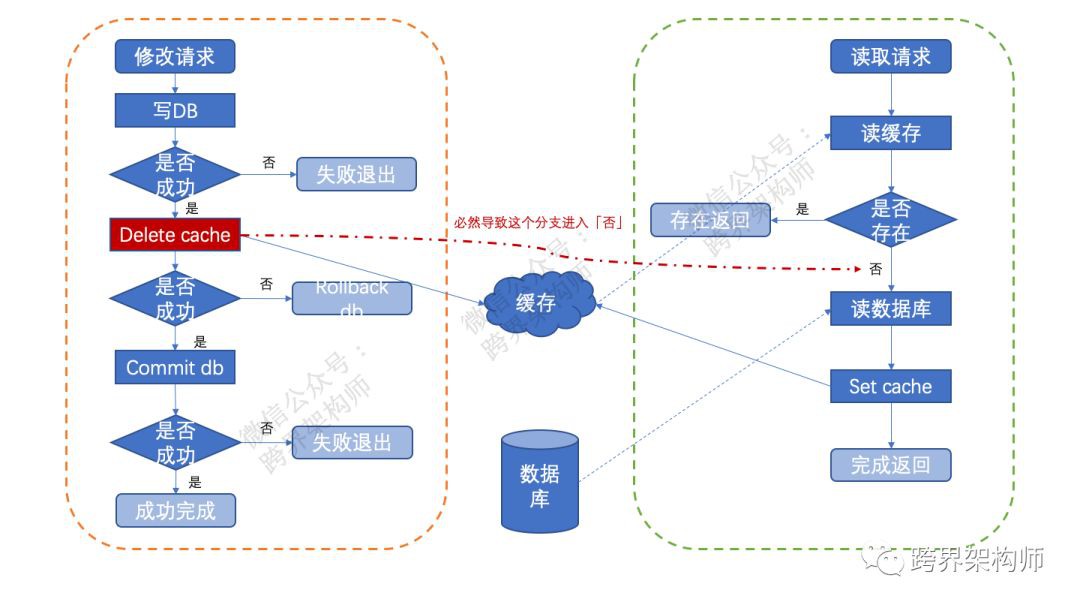
雖然資料庫操作有XA規範的保證,但是由於需要進行二次確認,而確認又需要經過網路,所以在網路不穩定的情況下,的確會出現commit失敗的情況。
這個時候delete的好處就出來了。
假如真的commit失敗了,最多就是從db裡再撈一份舊資料出來。
而如果使用set的話,快取中就會存在臟資料了,必須得再多做一次set,將舊資料set回去。並且,這個操作還有可能出現失敗。
好了,這次要說的就那麼多,週五早上8點再見吧:D
推薦閱讀:
原創不易,如果你覺得這篇文章還不錯,就「在看」或者「分享」一下吧。鼓勵我的創作 :)
如果有希望我寫一下什麼主題的話,歡迎在後臺給我留言哦~

朋友會在“發現-看一看”看到你“在看”的內容