這裡會列舉在C#中處理CLR異常方面的規範,幫助大家構建和開發一個執行良好和可靠的應用系統。

前言
迄今為止,CLR異常機制讓人關註最多的一點就是“效率”問題。其實,這裡存在認識上的誤區,因為正常控制流程下的程式碼執行並不會出現問題,只有引發異常時才會帶來效率問題。基於這一點,很多開發者已經達成共識:不應將異常機制用於正常控制流中。達成的另一個共識是:CLR異常機制帶來的“效率”問題不足以“抵消”它帶來的巨大收益。
CLR異常機制至少有以下幾個優點:
- 正常控制流會被立即中止,無效值或狀態不會在系統中繼續傳播。
- 提供了統一處理錯誤的方法。
- 提供了在建構式、運運算元多載及屬性中報告異常的便利機制。
- 提供了異常堆疊,便於開發者定位異常發生的位置。
另外,“異常”其名稱本身就說明瞭它的發生是一個小機率事件。所以,因異常帶來的效率問題會被限制在一個很小的範圍內。實際上,try catch所帶來的效率問題幾乎是可以忽略的。在某些特定的場合,如Int32的Parse方法中,確實存在著因為濫用而導致的效率問題。在這種情況下,我們就應該考慮提供一個TryParse方法,從設計的角度讓使用者選擇讓程式執行得更快。另一種規避因為異常而影響效率的方法是:Tester-doer樣式
正文
1.用丟擲異常代替傳回錯誤程式碼
在異常機製出現之前,應用程式普遍採用傳回錯誤程式碼的方式來通知呼叫者發生了異常。本建議首先闡述為什麼要用丟擲異常的方式來代替傳回錯誤程式碼的方式。對於一個成員方法而言,它要麼執行成功,要麼執行失敗。成員方法執行成功的情況很容易理解,但是如果執行失敗了卻沒有那麼簡單,因為我們需要將導致執行失敗的原因通知呼叫者。丟擲異常和傳回錯誤程式碼都是用來通知呼叫者的手段。
但是當我們想要告訴呼叫者更多細節的時候,就需要與呼叫者約定更多的錯誤程式碼。於是我們很快就會發現,錯誤程式碼飛速膨脹,直到看起來似乎無法維護,因為我們總在查詢並確認錯誤程式碼。
在沒有異常處理機制之前,我們只能傳回錯誤程式碼。但是,現在有了另一種選擇,即使用異常機制。如果使用異常機制,那麼最終的程式碼看起來應該是下麵這樣的:

使用CLR異常機制後,我們會發現程式碼變得更清晰、更易於理解了。至於效率問題,還可以重新審視“效率”的立足點:throw exception產生的那點效率損耗與等待網路連線異常相比,簡直微不足道,而CLR異常機制帶來的好處卻是顯而易見的。
這裡需要稍加強調的是,在catch(CommunicationExcep-tion)這個程式碼塊中,程式碼所完成的功能是“通知傳送”而不是“傳送”本身,因為我們要確保在catch和finally中所執行的程式碼是可以被執行的。換句話說,儘量不要在catch和finally中再讓程式碼“出錯”,那會讓異常堆疊資訊變得複雜和難以理解。
在本例的catch程式碼塊中,不要真的編寫傳送郵件的程式碼,因為傳送郵件這個行為可能會產生更多的異常,而“通知傳送”這個行為穩定性更高(即不“出錯”)。
以上透過實際的案例闡述了丟擲異常相比於傳回錯誤程式碼的優越性,以及在某些情況下錯誤程式碼將無用武之地,如建構式、運運算元多載及屬性。語法特性決定了其不能具備任何傳回值,於是異常機制被當做取代錯誤程式碼的首要選擇。
2.不要在不恰當的場合下引發異常
程式員,尤其是類庫開發人員,要掌握的兩條首要原則是:
正常的業務流程不應使用異常來處理。
不要總是嘗試去捕獲異常或引發異常,而應該允許異常向呼叫堆疊往上傳播。
那麼,到底應該在怎樣的情況下引發異常呢?
第一類情況 如果執行程式碼後會造成記憶體洩漏、資源不可用,或者應用程式狀態不可恢復,則應該引發異常。
在微軟提供的Console類中有很多類似這樣的程式碼:

在開頭首先提到的就是:對在可控範圍內的輸入和輸出不引發異常。沒錯,區別就在於“可控”這兩個字。所謂“可控”,可定義為:發生異常後,系統資源仍可用,或資源狀態可恢復。
第二類情況 在捕獲異常的時候,如果需要包裝一些更有用的資訊,則引發異常。
這類異常的引發在UI層特別有用。系統引發的異常所帶的資訊往往更傾向於技術性的描述;而在UI層,面對異常的很可能是終端使用者。如果需要將異常的資訊呈現給終端使用者,更好的做法是先包裝異常,然後引發一個包含友好資訊的新異常。
第三類情況 如果底層異常在高層操作的背景關係中沒有意義,則可以考慮捕獲這些底層異常,並引發新的有意義的異常。
例如在下麵的程式碼中,如果丟擲InvalidCastException,則沒有任何意義,甚至會造成誤解,所以更好的方式是丟擲一個ArgumentException:
需要重點介紹的正確引發異常的典型例子就是捕獲底層API錯誤程式碼,並丟擲。檢視Console這個類,還會發現很多地方有類似的程式碼:

int errorCode=Marshal.GetLastWin32Error();
if(errorCode==6)
{
throw new InvalidOperationException(Environment.GetResourceString("InvalidOperation_ConsoleKeyAvailableOnFile"));
}
Console為我們封裝了呼叫Windows API傳回的錯誤程式碼,而讓程式碼引發了一個新的異常。
很顯然,當需要呼叫Windows API或第三方API提供的介面時,如果對方的異常報告機制使用的是錯誤程式碼,最好重新引發該介面提供的錯誤,因為你需要讓自己的團隊更好地理解這些錯誤。
3.重新引發異常時使用Inner Exception
當捕獲了某個異常,將其包裝或重新引發異常的時候,如果其中包含了Inner Exception,則有助於程式員分析內部資訊,方便程式碼除錯。
以一個分散式系統為例,在進行遠端通訊的時候,可能會發生的情況有:
1)網絡卡被禁用或網線斷開,此時會丟擲SocketException,訊息為:“由於標的計算機積極拒絕,無法連線。”
2)網路正常,但是要連線的標的機沒有埠沒有處在偵聽狀態,此時,會丟擲SocketException,訊息為:“由於連線方在一段時間後沒有正確答覆或連線的主機沒有反應,連線嘗試失敗。”
3)連線超時,此時需要透過程式碼實現關閉連線,並丟擲一個SocketException,訊息為:“連線超過約定的時長。”
發生以上三種情況中的任何一種情況,在傳回給終端使用者的時候,我們都需要將異常資訊包裝成為“網路連線失敗,請稍候再試”。
所以,一個分散式系統的業務處理方法,看起來應該是這樣的:

但是,在提示這條訊息的時候,我們可能需要將原始異常資訊記錄到日誌裡,以供開發者分析具體的原因(因為如果這種情況頻繁出現,這有可能是一個Bug)。那麼,在記錄日誌的時候,就非常有必要記錄導致此異常出現的內部異常或是堆疊資訊。
上文程式碼中的:就是將異常重新包裝成為一個CommucationFailureException,並將SocketException作為Inner Exception(即err)向上傳遞。
此外還有一個可以採用的技巧,如果不打算使用Inner Exception,但是仍然想要傳回一些額外資訊的話,可以使用Exception的Data屬性。如下所示:

4.避免在finally內撰寫無效程式碼
你應該始終認為finally內的程式碼會在方法return之前執行,哪怕return是在try塊中。
C#編譯器會清理那些它認為完全沒有意義的C#程式碼。

5.避免巢狀異常
應該允許異常在呼叫堆疊中往上傳播,不要過多使用catch,然後再throw。過多使用catch會帶來兩個問題:
- 程式碼更多了。這看上去好像你根本不知道該怎麼處理異常,所以你總在不停地catch。
- 隱藏了堆疊資訊,使你不知道真正發生異常的地方。
巢狀異常會導致 呼叫堆疊被重置了。最糟糕的情況是:如果方法捕獲的是Exception。所以也就是說,如果這個方法中還存在另外的異常,在UI層將永遠不知道真正發生錯誤的地方。
除了第3點提到的需要包裝異常的情況外,無故地巢狀異常是我們要極力避免的。當然,如果真的需要捕獲這個異常來恢復一些狀態,然後重新丟擲,程式碼看起來應該是這樣的:
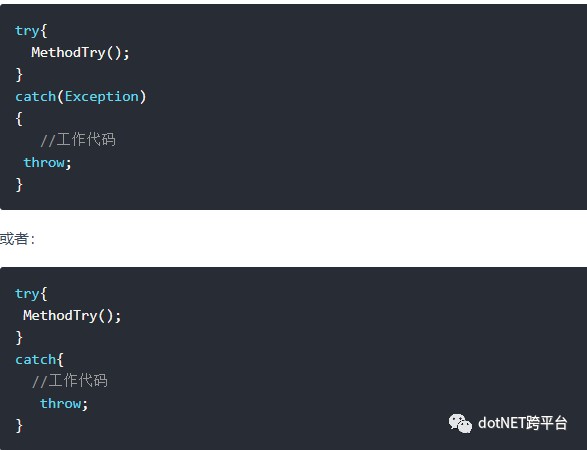
儘量避免像下麵這樣引發異常:
catch(Exception err){
throw err;
}直接throw err而不是throw將會重置堆疊資訊。
6.避免“吃掉”異常
巢狀異常是很危險的行為,一不小心就會將異常堆疊資訊,也就是真正的Bug出處隱藏起來。但這還不是最嚴重的行為,最嚴重的就是“吃掉”異常,即捕獲,然後不向上層throw丟擲。如果你不知道如何處理某個異常,那麼千萬不要“吃掉”異常,如果你一不小心“吃掉”了一個本該往上傳遞的異常,那麼,這裡可能誕生一個Bug,而且,解決它會很費周折。
避免“吃掉”異常,並不是說不應該“吃掉”異常,而是這裡面有個重要原則:該異常可被預見,並且通常情況它不能算是一個Bug。比如有些場景存在你可以預見的但不重要的Exception,這個就不算一個bug。
7.為迴圈增加Tester-Doer樣式而不是將try-catch置於迴圈內
如果需要在迴圈中引發異常,你需要特別註意,因為丟擲異常是一個相當影響效能的過程。應該儘量在迴圈當中對異常發生的一些條件進行判斷,然後根據條件進行處理。
8.總是處理未捕獲的異常
處理未捕獲的異常是每個應用程式應具備的基本功能,C#在AppDomain提供了UnhandledException事件來接收未捕獲到的異常的通知。常見的應用如下:

未捕獲的異常通常就是執行時期的Bug,我們可以在App-Domain.CurrentDomain.UnhandledException的註冊事件方法CurrentDomain_UnhandledException中,將未捕獲異常的資訊記錄在日誌中。值得註意的是,UnhandledException提供的機制並不能阻止應用程式終止,也就是說,執行CurrentDomain_UnhandledException方法後,應用程式就會被終止。
9.正確捕獲多執行緒中的異常
多執行緒的異常處理需要採用特殊的方法。以下的處理方式會存在問題:
應用程式並不會在這裡捕獲執行緒t中的異常,而是會直接退出。從.NET 2.0開始,任何執行緒上未處理的異常,都會導致應用程式的退出(先會觸發AppDomain的UnhandledException)。上面程式碼中的try-catch實際上捕獲的還是當前執行緒的異常,而t屬於新起的異常,所以,正確的做法應該是把 try-catch放在執行緒裡面

10.慎用自定義異常
除非有充分的理由,否則一般不要建立自定義異常。如果要對某類程式出錯資訊做特殊處理,那就自定義異常。需要自定義異常的理由如下:
1)方便除錯。透過丟擲一個自定義的異常型別實體,我們可以使捕獲程式碼精確地知道所發生的事情,並以合適的方式進行恢復。
2)邏輯包裝。自定義異常可包裝多個其他異常,然後丟擲一個業務異常。
3)方便呼叫者編碼。在編寫自己的類庫或者業務層程式碼的時候,自定義異常可以讓呼叫方更方便處理業務異常邏輯。例如,儲存資料失敗可以分成兩個異常“資料庫連線失敗”和“網路異常”。
4)引入新異常類。這使程式員能夠根據異常類在程式碼中採取不同的操作。
11.從System.Exception或其他常見的基本異常中派生異常
這個不說了,自定義異常一般是從System.Exception派生。。事實上,現在如果你在Visual Studio中輸入Exception,然後使用快捷鍵Tab,VS會自動建立一個自定義異常類。
12.應使用finally避免資源洩漏
前面已經提到過,除非發生讓應用程式中斷的異常,否則finally總是會先於return執行。finally的這個語言特性決定了資源釋放的最佳位置就是在finally塊中;另外,資源釋放會隨著呼叫堆疊由下往上執行(即由內到外釋放)。
13.避免在呼叫棧較低的位置記錄異常
即避免在內部深處處理記錄異常。最適合記錄異常和報告的是應用程式的最上層,這通常是UI層。
並不是所有的異常都要被記錄到日誌,一類情況是異常發生的場景需要被記錄,還有一類就是未被捕獲的異常。未被捕獲的異常通常被視為一個Bug,所以,對於它的記錄,應該被視為系統的一個重要組成部分。
如果異常在呼叫棧較低的位置被記錄或報告,並且又被包裝後丟擲;然後在呼叫棧較高位置也捕獲記錄異常。這就會讓記錄重覆出現。在呼叫棧較低的情況下,往往異常被捕獲了也不能被完整的處理。所以,綜合考慮,應用程式在設計初期,就應該為開發成員約定在何處記錄和報告異常。
朋友會在“發現-看一看”看到你“在看”的內容