首先我們要思考一個問題,什麼樣的網站才是大型網站,從網站的技術指標角度考慮這個問題人們很容易犯一個毛病就是認為網站的訪問量是衡量的指標,懂點行的人也許會認為是網站在單位時間裡的併發量的大小來作為指標,如果按這些標準那麼像hao123這樣的網站就是大型網站了,如下圖所示:
其實這種網站訪問量非常大,併發數也非常高,但是它卻能用最為簡單的web技術來實現:我們只要保持網站的充分的靜態化,多部署幾臺伺服器,那麼就算地球上所有人都用它,網站也能正常執行。
我覺得大型網站是技術和業務的結合,一個滿足某些使用者需求的網站只要技術和業務二者有一方難度很大,必然會讓企業投入更多的、更優秀的人力成本實現它,那麼這樣的網站就是所謂的大型網站了。
一個初建的網站往往使用者群都是很小的,最簡單的網站架構就能解決實際的使用者需求,當然為了保證網站的穩定性和安全性,我們會把網站的應用部署到至少兩臺機器上,後臺的儲存使用資料庫,如果經濟實力允許,資料庫使用單臺伺服器部署,由於資料是網站的生命線,因此我們常常會把部署資料庫的伺服器使用的好點,這個網站結構如下所示:
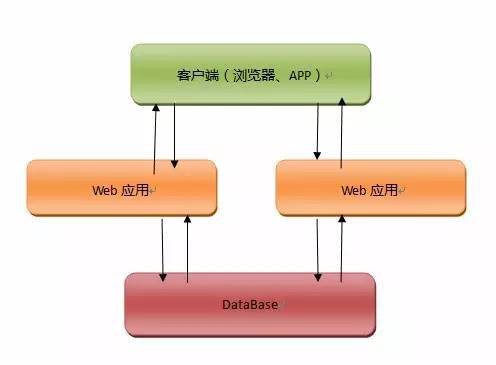
這個結構非常簡單,其實大部分初建網站開發裡往往業務邏輯沒有企業級系統那麼複雜,所以只要有個好的idea,建設一個新網站的成本是非常低的,所使用的技術手段也是非常的基本和簡單,不過該圖我們要準備三臺伺服器,而且還要租個機房放置我們的伺服器,這些成本對於草根和屌絲還是非常高的,幸運的是當下很多大公司和機構提供了雲平臺,我們可以花費很少的錢將自己的應用部署到雲平臺上,這種做法我們甚至不用去考慮把應用、資料庫分開部署的問題,更加進一步的降低了網站開發和運維的成本,但是這種做法也有一個問題,就是網站的小命被這個雲平臺捏住了,如果雲平臺掛了,俺們的網站服務也就跟著掛了。
這裡我先講講自己獨立使用伺服器部署網站的問題,如果我們要把網站服務應用使用多臺伺服器部署,這麼做的目的一般有兩個:
- 保證網站的可用性,多臺伺服器部署應用,那麼其中一些伺服器掛掉了,只要網站還有伺服器能正常運轉,那麼網站對外任然可以正常提供服務。
- 提高網站的併發量,伺服器越多那麼網站能夠服務的使用者,單位時間內能承載的請求數也就越大。
不過要做到以上兩點,並不是我們簡單將網站分開部署就可以滿足的,因為大多數網站在使用者使用時候都是要保持使用者的狀態,具體點就是網站要記住請求是歸屬到那一個客戶端,而這個狀態在網站開發裡就是透過會話session來體現的。分開部署的web應用服務要解決的一個首要問題就是要保持不同物理部署伺服器之間的session同步問題,從而達到當使用者第一次請求訪問到伺服器A,第二個請求訪問到伺服器B,網站任然知道這兩個請求是同一個人,解決方案很直接:伺服器A和伺服器B上的session資訊要時刻保持同步,那麼如何保證兩臺伺服器之間session資訊的同步呢?
為了回答上面的問題,我們首先要理解下session的機制,session資訊在web容器裡都是儲存在記憶體裡的,web容器會給每個連線它的客戶端生成一個sessionid值,這個sessionid值會被web容器置於http協議裡的cookie域下,當響應被客戶端處理後,客戶端本地會儲存這個sessionid值,使用者以後的每個請求都會讓這個sessionid值隨cookie一起傳遞到伺服器,伺服器透過sessionid找到記憶體中儲存的該使用者的session內容,session在記憶體的資料結構是一個map的格式。那麼為了保證不同伺服器之間的session共享,那麼最直接的方案就是讓伺服器之間session不斷的傳遞和複製,例如java開發裡常用的tomcat容器就採用這種方案,以前我測試過tomcat這種session同步的效能,我發現當需要同步的web容器越多,web應用所能承載的併發數並沒有因為伺服器的增加而線性提升,當伺服器數量達到一個臨界值後,整個web應用的併發數甚至還會下降,為什麼會這樣了?
原因很簡單,不同伺服器之間session的傳遞和複製會消耗伺服器本身的系統資源,當伺服器數量越大,消耗的資源越多,當使用者請求越頻繁,系統消耗資源也會越來越大。如果我們多部署伺服器的目的只是想保證系統的穩定性,採用這種方案還是不錯的,不過web應用最好部署少點,這樣才不會影響到web應用的效能問題,如果我們還想提升網站的併發量那麼就得採取其他的方案了。
時下使用的比較多的方案就是使用獨立的快取伺服器,也就是將session的資料儲存在一臺獨立的伺服器上,如果覺得存在一臺伺服器不安全,那麼可以使用memcached這樣的分散式快取伺服器進行儲存,這樣既可以滿足了網站穩定性問題也提升了網站的併發能力。
不過早期的淘寶在這個問題解決更加巧妙,他們將session的資訊直接儲存到瀏覽器的cookie裡,每次請求cookie資訊都會隨著http一起傳遞到web伺服器,這樣就避免了web伺服器之間session資訊同步的問題,這種方案會讓很多人詬病,詬病的原因是cookie的不安全性是總所周知的,如果有人惡意擷取cookie資訊那麼網站不就不安全了嗎?這個答案還真不好說,但是我覺得我們僅僅是跟蹤使用者的狀態,把session存在cookie裡其實也沒什麼大不了的。
其實如此專業的淘寶這麼做其實還是很有深意的,還記得本文開篇提到的hao123網站,它是可以承載高併發的網站,它之所以可以做到這一點,原因很簡單它是個靜態網站,靜態網站的特點就是不需要記錄使用者的狀態,靜態網站的伺服器不需要使用寶貴的系統資源來儲存大量的session會話資訊,這樣它就有更多系統資源來處理請求,而早期淘寶將cookie存在客戶端也是為了達到這樣的目的,所以這個方案在淘寶網站架構裡還是使用了很長時間的。
在我的公司裡客戶端的請求到達web伺服器之前,會先到F5,F5是一個用來做負載均衡的硬體裝置,它的作用是將使用者請求均勻的分發到後臺的伺服器叢集,F5是硬體的負載均衡解決方案,如果我們沒那麼多錢買這樣的裝置,也有軟體的負載均衡解決方案,這個方案就是大名鼎鼎的LVS了,這些負載均衡裝置除了可以分發請求外它們還有個能力,這個能力是根據http協議的特點設計的,一個http請求從客戶端到達最終的儲存伺服器之前可能會經過很多不同的裝置,如果我們把一個請求比作高速公路上的一輛汽車,這些裝置也可以叫做這些節點就是高速路上的收費站,這些收費站都能根據自己的需求改變http報文的內容,所以負載均衡裝置可以記住每個sessionid值對應的後臺伺服器,當一個帶有sessionid值的請求透過負載均衡裝置時候,負載均衡裝置會根據該sessionid值直接找到指定的web伺服器,這種做法有個專有名詞就是session粘滯,這種做法也比那種session資訊在不同伺服器之間複製複製要高效,不過該做法還是比存cookie的效率低下,而且對於網站的穩定性也有一定影響即如果某臺伺服器掛掉了,那麼連線到該伺服器的使用者的會話都會失效。
解決session的問題的本質也就是解決session的儲存問題,其本質也就是解決網站的儲存問題,一個初建的網站在早期的運營期需要解決的問題基本都是由儲存導致的。上文裡我提到時下很多新建的web應用會將伺服器部署後雲平臺裡,好的雲平臺裡或許會幫助我們解決負載均衡和session同步的問題,但是雲平臺裡有個問題很難解決那就是資料庫的儲存問題,如果我們使用的雲平臺發生了重大事故,導致雲平臺儲存的資料丟失,這種會不會導致我們在雲平臺裡資料庫的資訊也會丟失了,雖然這個事情的機率不高,但是發生這種事情的機率還是有的,雖然很多雲平臺都聲稱自己多麼可靠,但是真實可靠性有多高不是局中人還真不清楚哦,因此使用雲平臺我們首要考慮的就是要做好資料備份,假如真發生了資料丟失,對於一個快速成長的網站而言可能非常致命。
寫到這裡一個嬰兒般的網站就這樣被我們創造出來了,我們希望網站能健康快速的成長,如果網站真的按我們預期成長了,那麼一定會有一天我們製造的寶寶屋已經滿足不了現實的需求,這個時候我們應該如何抉擇了?換掉,全部換掉,使用新的架構例如我們以前長提的SOA架構,分散式技術,這個方法不錯,但是SOA和分散式技術是很難的,成本是很高的,如果這時候我們透過新增幾臺伺服器就能解決問題的話,我們絕對不要去選擇什麼分散式技術,因為這個成本太高了。上面我講到幾種session共享的方案,這個方案解決了應用的水平擴充套件問題,那麼當我們網站出現瓶頸時候就多加幾臺伺服器不就行了嗎?那麼這裡就有個問題了,當網站成長很快,網站首先碰到的瓶頸到底是哪個方面的問題?
本人是做金融網站的,我們所做的網站有個特點就是當使用者訪問到我們所做的網站時候,目的都很明確就是為了付錢,使用者到了我們所做的網站時候都希望能快點,再快點完成本網站的操作,很多使用者在使用我們做的網站時候不太去關心網站的其他內容,因此我們所做的網站相對於資料庫而言就是讀寫比例其實非常的均勻,甚至很多場景寫比讀要高,這個特點是很多專業服務網站的特點,其實這樣的網站和企業開發的特點很類似:業務操作的重要度超過了業務展示的重要度,因此專業性網站吸納企業系統開發的特點比較多。但是大部分我們日常常用的網站,我們逗留時間很長的網站按資料庫角度而言往往是讀遠遠大於寫,例如大眾點評網站它的讀寫比率往往是9比1。
12306或許是中國最著名的網站之一,我記得12306早期經常出現一個問題就是使用者登入老是登不上,甚至在高峰期整個網站掛掉,頁面顯示503網站拒絕訪問的問題,這個現象很好理解就是網站併發高了,大量人去登入網站,購票,系統掛掉了,最後所有的人都不能使用網站了。當網站出現503拒絕訪問時候,那麼這個網站就出現了最致命的問題,解決大使用者訪問的確是個超級難題,但是當高併發無法避免時候,整個網站都不能使用這個只能說網站設計上發生了致命錯誤,一個好的網站設計在應對超出自己能力的併發時候我們首先應該是不讓他掛掉,因為這種結果是誰都不能使用,我們希望那些在可接受的請求下,讓在可接受請求範圍內的請求還是可以正常使用,超出的請求可以被拒絕,但是它們絕對不能影響到全網站的穩定性,現在我們看到了12306網站的峰值從未減少過,而且是越變越多,但是12306出現全站掛掉的問題是越來越少了。透過12036網站改變我們更進一步思考下網站的瓶頸問題。
排除一些不可控的因素,網站在高併發下掛掉的原因90%都是因為資料庫不堪重負所致,而應用的瓶頸往往只有在解決了儲存瓶頸後才會暴露,那麼我們要升級網站能力的第一步工作就是提升資料庫的承載能力,對於讀遠大於寫的網站我們採取的方式就是將資料庫從讀寫這個角度拆分,具體操作就是將資料庫讀寫分離,如下圖所示:
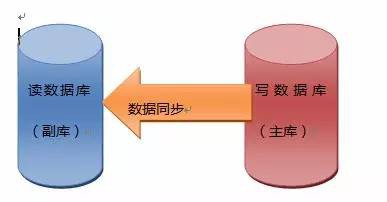
我們這時要設計兩個資料庫,一個資料庫主要負責寫操作我們稱之為主庫,一個資料庫專門負責讀操作我們稱之為副庫,副庫的資料都是從主庫匯入的,資料庫的讀寫分離可以有效的保證關鍵資料的安全性,但是有個缺點就是當使用者瀏覽資料時候,讀的資料都會有點延時,這種延時比起全站不可用那肯定是可以接受的。不過針對12306的場景,僅僅讀寫分離還是遠遠不夠的,特別是負責讀操作的副庫,在高訪問下也是很容易達到效能的瓶頸的,那麼我們就得使用新的解決方案:使用分散式快取,不過快取的缺點就是不能有效的實時更新,因此我們使用快取前首先要對讀操作的資料進行分類,對於那些經常不發生變化的資料可以事先存放到快取裡,快取的訪問效率很高,這樣會讓讀更加高效,同時也減輕了資料庫的訪問壓力。至於用於寫操作的主庫,因為大部分網站讀寫的比例是嚴重失衡,所以讓主庫達到瓶頸還是比較難的,不過主庫也有一個讀的壓力就是主庫和副庫的資料同步問題,不過同步時候資料都是批次操作,而不是像請求那樣進行少量資料讀取操作,讀取操作特別多,因此想達到瓶頸還是有一定的難度的。聽人說,美國牛逼的facebook對資料的任何操作都是事先合併為批次操作,從而達到減輕資料庫壓力的目的。
上面的方案我們可以保證在高併發下網站的穩定性,但是針對於讀,如果資料量太大了,就算網站不掛掉了,使用者能很快的在海量資料裡檢索到所需要的資訊又成為了網站的一個瓶頸,如果使用者需要很長時間才能獲得自己想要的資料,很多使用者會失去耐心從而放棄對網站的使用,那麼這個問題又該如何解決了?
解決方案就是我們經常使用的百度,谷歌哪裡得來,對於海量資料的讀我們可以採用搜索技術,我們可以將資料庫的資料匯出到檔案裡,對檔案建立索引,使用倒排索引技術來檢索資訊,我們看到了百度,谷歌有整個網際網路的資訊我們任然能很快的檢索到資料,搜尋技術是解決快速讀取資料的一個有效方案,不過這個讀取還是和資料庫的讀取有所區別的,如果使用者查詢的資料是透過資料庫的主鍵欄位,或者是透過很明確的建立了索引的欄位來檢索,那麼資料庫的查詢效率是很高的,但是使用網站的人跟喜歡使用一些模糊查詢來查詢自己的資訊,那麼這個操作在資料庫裡就是個like操作,like操作在資料庫裡效率是很低的,這個時候使用搜索技術的優勢就非常明顯了,搜尋技術非常適合於模糊查詢操作。
OK,很晚了,關於儲存的問題今天就寫在這裡,下一篇我將接著這個主題講解,解決儲存問題是很複雜的,下篇我儘量講仔細點。
來自:夏天的森林
連結:http://blog.jobbole.com/83475/